1.簡単な概要
この記事ではPythonのBeautiful Soupを使った食べログ口コミスクレイピング方法について解説していきます!
私自身🍜が大好きで昔は年間100杯以上食べ歩いてきた自称ラーメンガチ勢です。しかしながら、直近の健康診断にひっかかり、医者からドクターストップをかけられてしまいました。。。
行き場をなくしたラーメン熱を発散すべく**機械学習でラーメンレコメンド(隠れた名店をレコメンドで発掘)**に挑戦してみることにしました。
今回は、学習データを集めるためのスクレイピングです。
世の中に食べログスクレイピング記事はいくつかありましたが、
"ラーメン屋でかつ点数が高い名店のみ"
を点数順に抽出する方法が見当たらなかったのでやってみました。
私自身スクレイピング初心者ですが、簡単に食べログの口コミが取得できましたので、是非チャレンジしてみてください。
※食べログ規約にもとづき口コミに関する箇所にはモザイクをいれております。ご了承ください。
##取得する項目
・店舗名:store_name
・食べログ点数:score
・口コミ件数:review_cnt
・口コミ文章:review
##スクレイピングの流れ
今回のスクレイピングでは、下記図のようにwebページを遷移しながら必要な情報を取得していっています。
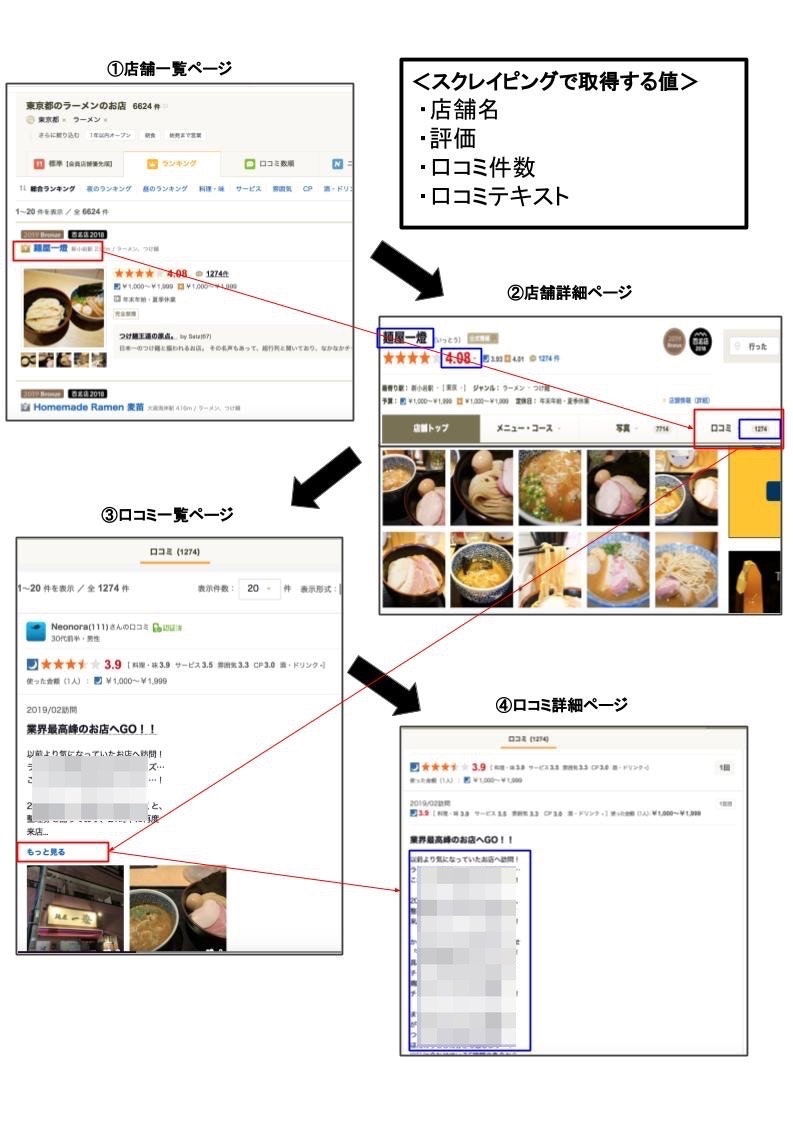
#2.「スクレイピング」とは
htmlファイル全体を取得しその中から目的のデータを抽出することです。
そもそもhtmlって何?
っていう私みたいな初学者の方のために少しだけ説明します。
試しに食べログページを別タブで開いてみましょう。
まず、画面上で右クリックをし、**「ページのソースを表示」**を押してみましょう。
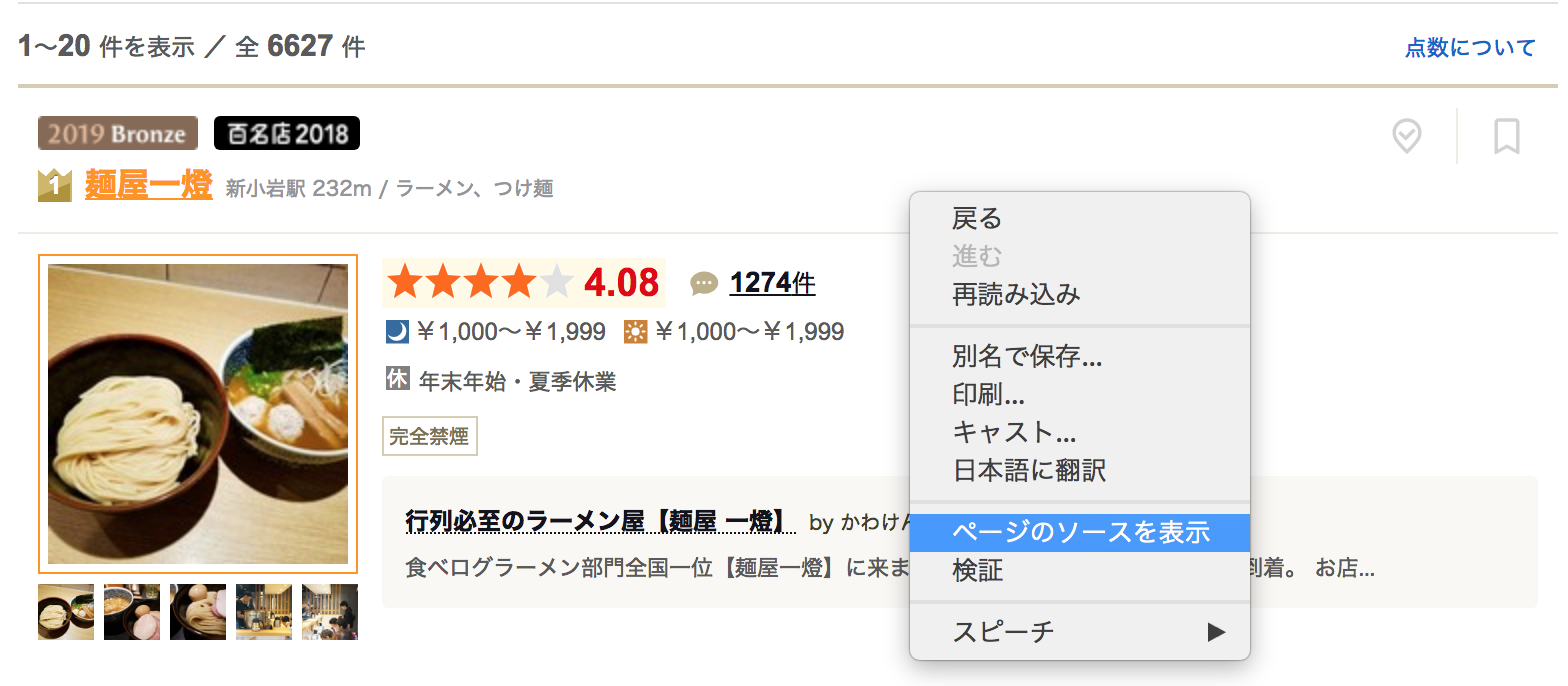
そうすると、以下のように英語がずらっと並んだ画面が表示されるかと思います。

並んでいる英語の文字は、ソースコードと呼ばれWebページ内の表示や動作を命令しています。
スクレイピングでは、このHTMLのソースコードを解析(パース)して、欲しい情報だけを取得することができます。
もう少し詳しく知りたい方は下記の記事が参考になるかと思います。
・今さら聞けない!HTMLとは【初心者向け】
・PythonとBeautiful Soupでスクレイピング
3.ソースコード
手っ取り早くスクレイピングを試したい人は、是非↓のコードをそのままコピペして実行してみてください。
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import time
class Tabelog:
"""
食べログスクレイピングクラス
test_mode=Trueで動作させると、最初のページの3店舗のデータのみを取得できる
"""
def __init__(self, base_url, test_mode=False, p_ward='東京都内', begin_page=1, end_page=30):
# 変数宣言
self.store_id = ''
self.store_id_num = 0
self.store_name = ''
self.score = 0
self.ward = p_ward
self.review_cnt = 0
self.review = ''
self.columns = ['store_id', 'store_name', 'score', 'ward', 'review_cnt', 'review']
self.df = pd.DataFrame(columns=self.columns)
self.__regexcomp = re.compile(r'\n|\s') # \nは改行、\sは空白
page_num = begin_page # 店舗一覧ページ番号
if test_mode:
list_url = base_url + str(page_num) + '/?Srt=D&SrtT=rt&sort_mode=1' #食べログの点数ランキングでソートする際に必要な処理
self.scrape_list(list_url, mode=test_mode)
else:
while True:
list_url = base_url + str(page_num) + '/?Srt=D&SrtT=rt&sort_mode=1' #食べログの点数ランキングでソートする際に必要な処理
if self.scrape_list(list_url, mode=test_mode) != True:
break
# INパラメータまでのページ数データを取得する
if page_num >= end_page:
break
page_num += 1
return
def scrape_list(self, list_url, mode):
"""
店舗一覧ページのパーシング
"""
r = requests.get(list_url)
if r.status_code != requests.codes.ok:
return False
soup = BeautifulSoup(r.content, 'html.parser')
soup_a_list = soup.find_all('a', class_='list-rst__rst-name-target') # 店名一覧
if len(soup_a_list) == 0:
return False
if mode:
for soup_a in soup_a_list[:2]:
item_url = soup_a.get('href') # 店の個別ページURLを取得
self.store_id_num += 1
self.scrape_item(item_url, mode)
else:
for soup_a in soup_a_list:
item_url = soup_a.get('href') # 店の個別ページURLを取得
self.store_id_num += 1
self.scrape_item(item_url, mode)
return True
def scrape_item(self, item_url, mode):
"""
個別店舗情報ページのパーシング
"""
start = time.time()
r = requests.get(item_url)
if r.status_code != requests.codes.ok:
print(f'error:not found{ item_url }')
return
soup = BeautifulSoup(r.content, 'html.parser')
# 店舗名称取得
# <h2 class="display-name">
# <span>
# 麺匠 竹虎 新宿店
# </span>
# </h2>
store_name_tag = soup.find('h2', class_='display-name')
store_name = store_name_tag.span.string
print('{}→店名:{}'.format(self.store_id_num, store_name.strip()), end='')
self.store_name = store_name.strip()
# ラーメン屋、つけ麺屋以外の店舗は除外
store_head = soup.find('div', class_='rdheader-subinfo') # 店舗情報のヘッダー枠データ取得
store_head_list = store_head.find_all('dl')
store_head_list = store_head_list[1].find_all('span')
#print('ターゲット:', store_head_list[0].text)
if store_head_list[0].text not in {'ラーメン', 'つけ麺'}:
print('ラーメンorつけ麺のお店ではないので処理対象外')
self.store_id_num -= 1
return
# 評価点数取得
#<b class="c-rating__val rdheader-rating__score-val" rel="v:rating">
# <span class="rdheader-rating__score-val-dtl">3.58</span>
#</b>
rating_score_tag = soup.find('b', class_='c-rating__val')
rating_score = rating_score_tag.span.string
print(' 評価点数:{}点'.format(rating_score), end='')
self.score = rating_score
# 評価点数が存在しない店舗は除外
if rating_score == '-':
print(' 評価がないため処理対象外')
self.store_id_num -= 1
return
# 評価が3.5未満店舗は除外
if float(rating_score) < 3.5:
print(' 食べログ評価が3.5未満のため処理対象外')
self.store_id_num -= 1
return
# レビュー一覧URL取得
#<a class="mainnavi" href="https://tabelog.com/tokyo/A1304/A130401/13143442/dtlrvwlst/"><span>口コミ</span><span class="rstdtl-navi__total-count"><em>60</em></span></a>
review_tag_id = soup.find('li', id="rdnavi-review")
review_tag = review_tag_id.a.get('href')
# レビュー件数取得
print(' レビュー件数:{}'.format(review_tag_id.find('span', class_='rstdtl-navi__total-count').em.string), end='')
self.review_cnt = review_tag_id.find('span', class_='rstdtl-navi__total-count').em.string
# レビュー一覧ページ番号
page_num = 1 #1ページ*20 = 20レビュー 。この数字を変えて取得するレビュー数を調整。
# レビュー一覧ページから個別レビューページを読み込み、パーシング
# 店舗の全レビューを取得すると、食べログの評価ごとにデータ件数の濃淡が発生してしまうため、
# 取得するレビュー数は1ページ分としている(件数としては1ページ*20=20レビュー)
while True:
review_url = review_tag + 'COND-0/smp1/?lc=0&rvw_part=all&PG=' + str(page_num)
#print('\t口コミ一覧リンク:{}'.format(review_url))
print(' . ' , end='') #LOG
if self.scrape_review(review_url) != True:
break
if page_num >= 1:
break
page_num += 1
process_time = time.time() - start
print(' 取得時間:{}'.format(process_time))
return
def scrape_review(self, review_url):
"""
レビュー一覧ページのパーシング
"""
r = requests.get(review_url)
if r.status_code != requests.codes.ok:
print(f'error:not found{ review_url }')
return False
# 各個人の口コミページ詳細へのリンクを取得する
#<div class="rvw-item js-rvw-item-clickable-area" data-detail-url="/tokyo/A1304/A130401/13141542/dtlrvwlst/B408082636/?use_type=0&smp=1">
#</div>
soup = BeautifulSoup(r.content, 'html.parser')
review_url_list = soup.find_all('div', class_='rvw-item') # 口コミ詳細ページURL一覧
if len(review_url_list) == 0:
return False
for url in review_url_list:
review_detail_url = 'https://tabelog.com' + url.get('data-detail-url')
#print('\t口コミURL:', review_detail_url)
# 口コミのテキストを取得
self.get_review_text(review_detail_url)
return True
def get_review_text(self, review_detail_url):
"""
口コミ詳細ページをパーシング
"""
r = requests.get(review_detail_url)
if r.status_code != requests.codes.ok:
print(f'error:not found{ review_detail_url }')
return
# 2回以上来訪してコメントしているユーザは最新の1件のみを採用
#<div class="rvw-item__rvw-comment" property="v:description">
# <p>
# <br>すごい煮干しラーメン凪 新宿ゴールデン街本館<br>スーパーゴールデン1600円(20食限定)を喰らう<br>大盛り無料です<br>スーパーゴールデンは、新宿ゴールデン街にちなんで、ココ本店だけの特別メニューだそうです<br>相方と歌舞伎町のtohoシネマズの映画館でドラゴンボール超ブロリー を観てきた<br>ブロリー 強すぎるね(^^)面白かったです<br>凪の煮干しラーメンも激ウマ<br>いったん麺ちゅるちゅる感に、レアチャーと大トロチャーシューのトロけ具合もうめえ<br>煮干しスープもさすが!と言うほど完成度が高い<br>さすが食べログラーメン百名店<br>と言うか<br>2日連チャンで、近場の食べログラーメン百名店のうちの2店舗、昨日の中華そば葉山さんと今日の凪<br>静岡では考えられん笑笑<br>ごちそうさまでした
# </p>
#</div>
soup = BeautifulSoup(r.content, 'html.parser')
review = soup.find_all('div', class_='rvw-item__rvw-comment')#reviewが含まれているタグの中身をすべて取得
if len(review) == 0:
review = ''
else:
review = review[0].p.text.strip() # strip()は改行コードを除外する関数
#print('\t\t口コミテキスト:', review)
self.review = review
# データフレームの生成
self.make_df()
return
def make_df(self):
self.store_id = str(self.store_id_num).zfill(8) #0パディング
se = pd.Series([self.store_id, self.store_name, self.score, self.ward, self.review_cnt, self.review], self.columns) # 行を作成
self.df = self.df.append(se, self.columns) # データフレームに行を追加
return
tokyo_ramen_review = Tabelog(base_url="https://tabelog.com/tokyo/rstLst/ramen/",test_mode=False, p_ward='東京都内')
#CSV保存
tokyo_ramen_review.df.to_csv("../output/tokyo_ramen_review.csv")
※csvの保存先のパスは、適宜変更してください
果たして、問題なく動作してくれるか・・・
ドキドキ。
どきどき。
頼む、通ってくれ!
実行結果
キタ━━━(゚∀゚).━━━!!! キタ ━━━ヽ(´ω`)ノ ━━━!! キタ━━(☆∀☆)━━!!!

tokyo_ramen_review = pd.read_csv('../output/tokyo_ramen_review.csv')
tokyo_ramen_review
見事いい感じに取得できました!!キタコレ

4.ライブラリの簡単な解説
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import time
requests:HTTP ライブラリです。
BeautifulSoup:スクレイピングのために作られたHTMLデータの構文を解析するためのパッケージ
re:正規表現の操作を提供するモジュール
pandas:データを扱うためのライブラリ
time:プログラムの実行時間を測るためのライブラリ
#5.適宜目的に応じて修正する箇所
def __init__(self, base_url, test_mode=False, p_ward='東京都内', begin_page=1, end_page=30):
関数の引数部分の「begin_page」と「end_page」で下記画面のページ番号のうち何ページから何ページまでめくって取得するか設定しています。
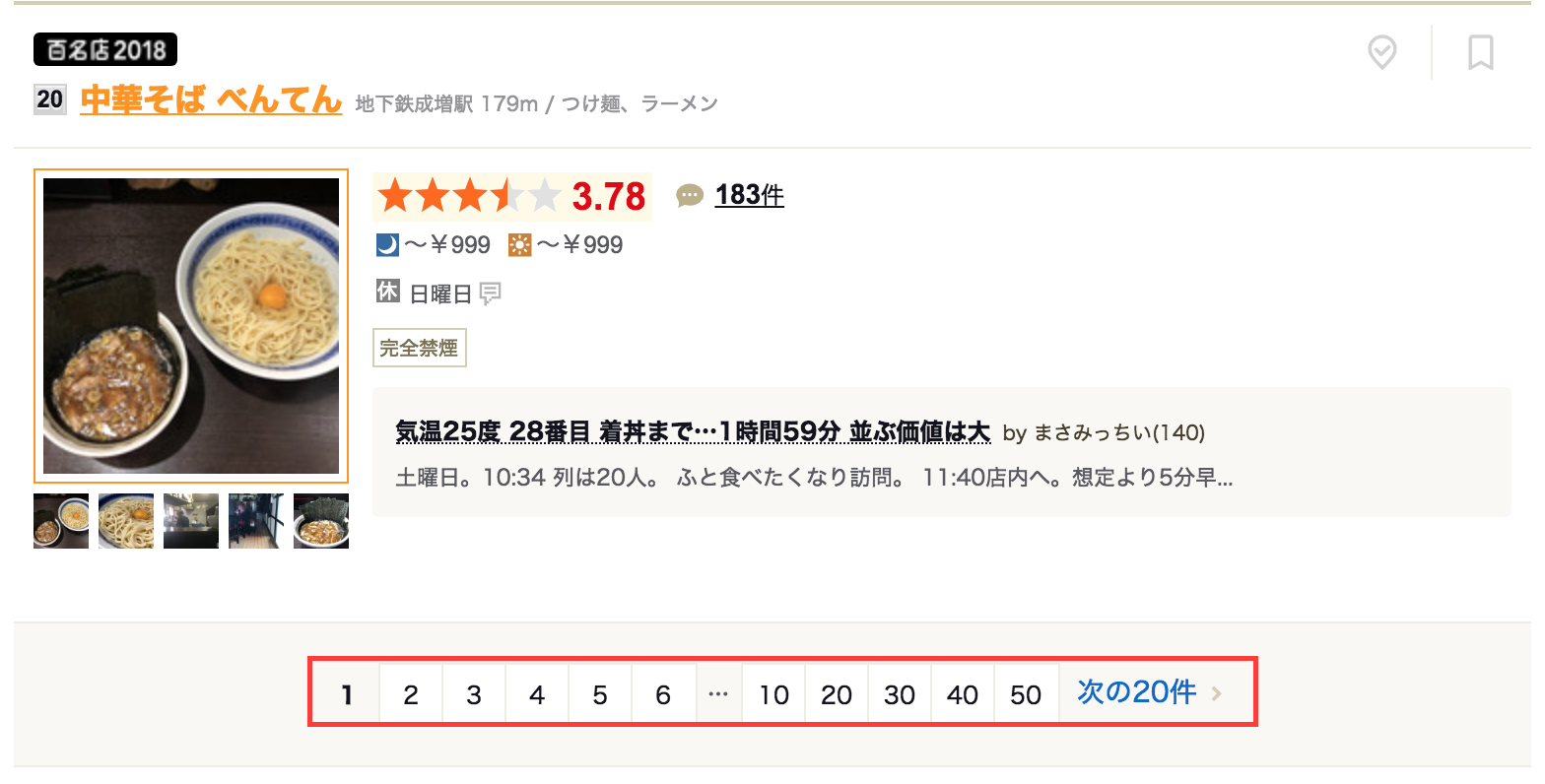
関数の引数部分のtest_mode=Falseを**test_mode=True**で動作させると、最初のページの3店舗のデータのみを取得します。
list_url = base_url + str(page_num) + '/?Srt=D&SrtT=rt&sort_mode=1'
食べログの点数ランキングでソートされたページを表示するための処理です。
ソートが不要な場合は '/?Srt=D&SrtT=rt&sort_mode=1' を削除。
if float(rating_score) < 3.5:
print('食べログ評価が3.5未満のため処理対象外')
self.store_id_num -= 1
return
データを取得する際に食べログスコアに条件をつけて、今回は3.5未満の店を除外しています。
page_num = 1
while True:
review_url = review_tag + 'COND-0/smp1/?lc=0&rvw_part=all&PG=' + str(page_num)
#print('\t口コミ一覧リンク:{}'.format(review_url))
print(' . ' , end='') #LOG
if self.scrape_review(review_url) != True:
break
if page_num >= 1:
break
page_num += 1
レビュー一覧ページから個別レビューページを読み込み、パーシングします。
店舗の全レビューを取得すると、食べログの評価ごとにデータ件数の濃淡が発生してしまう&データ量が膨大になってしまうため、取得するレビュー数は1ページ分に絞っています(件数としては1ページ×20=20レビュー)。
仮に page_num=1 を page_num=5 に変更すると100レビュー(1ページ×20レビュー)取得できます。
※2021年10月26日時点では、page_num = 1 のところの数字を変更してもレビュー数の数は変わらず、例えば、2にしたら2ページ目の口コミが反映される。
6.まとめ
Beautiful Soupを使用することで簡単にラーメン屋でかつ食べログスコアの高い名店
の口コミを取得することができました。
次回は取得できた口コミを使って自然言語処理に挑戦してみます!
Word2vecで「豚骨」+「ラーメン」+「ヤサイタワー」=「二郎」??
みたいなことをやる予定です。
第2弾:[【Python】ラーメンガチ勢によるガチ勢のためのWord2vecによる自然言語処理]
(https://qiita.com/toshiyuki_tsutsui/items/19590b464f15f845efcd)
🍜本記事が少しでも参考になりましたら是非「いいね」をお願いします!🍜
7.参考
WebサイトをPythonでスクレイピングしてみた
https://www.takapy.work/entry/2019/01/03/134720