エンジニア&リサーチインターンの佐藤(Twitter: TodayInsane)です。
ABEJA Advent Calendarの21日目を担当します。
もうすぐクリスマスですね!"Merry&Happy"!!!
軽い自己紹介
今年の4月からフロントエンドのデザイン→Vue.js実装をメインの業務とし、半年間とあるプロダクトの開発・案件受注を長期インターンとしてお手伝いさせて頂いてました。本記事と直接の関係はありませんが、このプロダクトの開発者兼ぼくのメンターさんによる思いとテックと面白さが詰まったABEJA Tech Blogも是非ご一読ください。そして9月に初案件が無事成功した話を、インターン体験記兼続編として執筆中です。
現在はエンジニア業務と同時並行で、10月から機械学習のリサーチインターンもしています。上述の人物認証を使ったプロダクトやABEJAのサービスであるInsight for Retailに有用そうな手法がないかサーベイしつつ、自身の修論のテーマとしても新しい手法を提案するのが目標です。
そして既にお気づきかもしれませんがK-POPガールズグループの__TWICE__が好きで、インターンと読書の傍らのんびりと韓国語を学んでいます。そして既にお気づきかもしれませんがこの記事でも何かにつけて"BRAND NEW GIRL"なTWICEのMVを見させようとします(我ながら本当にやりすぎたので怒られたら書き換えます)。
はじめに
Metric Learningとは
現在リサーチインターンとしてPerson Re-Identificationと呼ばれるタスクに取り組んでいます。これは画像または映像を解析し、写っている人物が既知(登録済みの人)か未知(新規データとしてデータベースに追加する)かを判定するComputer Visionの研究領域です。

(NAIST for Robotics Vision: http://rvlab.naist.jp/research-reid-ja.html より)
そしてDeep Learningモデルがベンチマークスコアをブチ上げる"ブレイクスルー"となっている近年、よく用いられる手法のひとつがMetric Learning(距離学習)です。自身の記事で恐縮ですがこちらの冒頭にて解説や参考となるリンクをまとめていますので併せてご参照ください。
Person Re-Identificationでよく挙げられる課題のひとつに、「学習データセットの人たちは推論(実世界で利用する)時には多分1人も出てこない」問題があります。いろんな人物の全身画像を判別しようと通常の分類タスクとして学習したモデルは、頑張っても推論時に使われる場所で知らない人を「知らない」クラスと判別することしかできません。
これを一般化して「観測データの確率分布が学習時(source domain)と推論時(target domain)で異なる」問題をdomain gapといい、このgapを乗り越えるために「同じ人の画像は近づけ、違う人の画像は遠ざけるような距離の取り方」を学習するMetric Learningがよく用いられます。同じクラス内において、また違うクラスのデータ間において距離をうまく取らせるように学習させ「データをどんな意味で区別しているのか」を把握したモデルを作るイメージです。
Metric Learning自体はPerson Re-Identificationに限らず、顔認識や異常検知など様々な場面で使われます。
この記事は?
プログラミングも研究も基礎理解にあたってはまず自分なりのタスクでモデルを作ってみるのが一番良いと考え、早速PyTorchを学び始めました。PyTorchにはよく用いられるようなデータセットや学習済みモデルがあらかじめ数多く用意されており、その恩恵に預かって知の高速道路をひた走れます。また公式チュートリアルをはじめ、バージョン0.4や1.0以降の使いやすくなってからの入門記事なども整備されています。
しかし「自作データセットで自作モデルを構築・学習させてみる」入門記事が意外と無く、新しいデータセットで新規手法を実験したい筆者としては慣れるまでに少し苦戦しました。
そこで今回は「オリジナルのデータをオリジナルのモデルに学習・推論させてPyTorchの入り口を"ノック"する」入門記事を意識して書いています。決してぼくの趣味に付き合っていただくわけではありません。なお実装するTriplet NetworkとTriplet Lossについては、筆者の力不足で必要最低限にギリ満たないぐらいの説明しかできていません。この機会に(?)ぜひMetric Learningまわりを学んでみてください。
そして「自分なりのタスク」とは本記事のタイトル通り、K-POPガールズグループ__TWICE__のメンバー9人を識別することです。最初は全員なんとなく同じ顔に見えるでおなじみK-POPグループですが、下の2枚(直近と1年前)で9人を区別できるでしょうか。

|

|
(TWICE公式Twitterより)
[](
TWICE
— TWICE (@JYPETWICE) September 23, 2019
THE 8TH MINI ALBUM
Feel Special
2019.09.23 MON 6PM#TWICE #트와이스 #FeelSpecial #OnlineCover pic.twitter.com/q9DgICCzz2
)TWICE
— TWICE (@JYPETWICE) October 22, 2018
THE 6TH MINI ALBUM
YES or YES
2018.11.05 6PM#TWICE #트와이스 #YESorYES pic.twitter.com/MmhygiKOjZ
ファンにとっては"Yes一択"なのですがTWICEをよく知らない方には少し難しいかもしれません。しかし9人をしっかり区別できる素敵で"FANCY"なAIを作れば全て解決です(現在もあんまりうまくいかず改良中)。
なおTriplet LossでMetric Learningを実装しているのは研究の基礎理解と簡単な仮説検証のためです。TWICEの9人を見分けるために使うメリットは万が一新しいメンバーが加入しても対応できるぐらいでしょうか。まぁ無いと言ってしまっていいでしょう。
PyTorchを使ってモデルをつくる!
ざっくりですがPyTorchを使うときには
- (train用とtest用の各)データ
- 全データから1組選んで渡してくれるDatasetクラス
- Datasetをepochごとに回していくDataLoader
- (lossを含む)モデルクラス
- 学習と推論
を用意していく流れをイメージすると実装を進めやすいです。以下順に見ていきますが、コードは抜粋のため詳しくは筆者GitHubリポジトリをご覧ください。
データを用意
最初の作業にして最重要といっても良いデータの準備から始めます。ここが一番長いです。データを準備済みの方は流し読みしてください。
まずはスクレイピングでTWICEの画像を"ブルドーザー"のように集めていきます。ここが本記事の作業で一番幸せな時間です。今回はこの記事(APIを叩かずにGoogleから画像収集をする)からスクリプトをほぼそのまま利用させていただきました。何度かエラーハンドリングには無いエラーを吐いて止まってしまったので、元のコード87行目からのrequest実行部分を以下のように華麗にスルーする仕様に変更してやり過ごしています。
try:
urllib.request.urlretrieve(url, download_path)
cprint("Success.", "green")
except urllib.error.HTTPError:
cprint("Failed. (HTTP Error)", "yellow")
download_errors.append(i + 1)
continue
except urllib.error.URLError:
cprint("Failed. (SSL Error)", "yellow")
download_errors.append(i + 1)
continue
except UnicodeEncodeError:
cprint("Failed. (Encoding Error)", "yellow")
download_errors.append(i + 1)
continue
# 以下を追加。他のエラーは全て横目に進んでいく。
except Exception as e:
print(e)
continue
検索ワードがそのままディレクトリ名になります。ナヨンから9人分実行。
検索ワードは試した中でTWICE [メンバー名(英語表記)]が一番いい画像が集まりやすかったです。
$ python google_scraping.py -t 'TWICE NAYEON' -n 500 -d './data/train'
ここで一旦推しをちゃんと取得できているか見ておきましょう。

190424 TMA
— CottonCandy (@sanacottoncandy) April 25, 2019
꿈처럼 행복해도 돼#트와이스 #TWICE #사나 #SANA#とにかく可愛い湊崎 @JYPETWICE pic.twitter.com/YpvgLgM0kC
衣装がかなりツボだった今年2019年のTHE FACT MUSIC AWARDSで筆者の一番好きなマスターさん(主に特定のグループやメンバーの写真をめちゃくちゃ撮ってアップしてる人)が撮影した最高の推し
正面を向いておらず、もともと顔が小さいのにさらに顔の領域が小さい全身の画像ですがこれも大丈夫です。
なお保存された画像を眺め過ぎるともうここで終わってもいいかなって気になってしまうので我慢します。
もちろんGoogleキーワード検索の結果を上から順番に保存しているだけなので、違う人、複数人、横顔など学習する際にノイズになりそうな画像が混じっています。例えばTWICE MOMOで取得してきた中にはジヒョとのツーショットが混じっていました。

(出典: https://mdpr.jp/k-enta/detail/1841155)
このユニットステージ死ぬほどカッコ良くてホントに好きです幕張のAブロック8列で見て泣きそうになりました3月のドームでまた見れるのかぁもうここで終わってもいいかな
こういった画像も後で顔の部分だけ切り出した際に違うメンバーだけ消せばいいので、"目を覚まして"雑念を振り払い進みましょう。
どう見ても違う人やどう見ても顔が全く写っていない画像だけを削除し、複数人が写っていたりうちわやグッズなど本人を直接撮ったものではない画像などは一旦そのままでいきます。
そしてcrop_face.pyを実行すると、かなりの精度で切り取られた顔画像がたくさんできます。今回のモデルは入力画像に64×64ピクセルを想定しているためここで合わせています。この部分はおそらくほぼ同じことを考えている方の記事(PyTorchを使って日向坂46の顔分類をしよう!)内にあるコードを使わせて頂きました。
def crop_face():
in_dir = "./train/*"
out_dir = "./face_data/"
in_jpg = glob.glob(in_dir)
in_jpg_member = []
for i in range(len(in_jpg)):
in_jpg_member.append(glob.glob(in_jpg[i]+"/*"))
in_fileName = os.listdir("./train")
for member_num in range(len(in_fileName)):
OutputPath = out_dir+"/"+in_fileName[member_num]
if not os.path.exists(OutputPath):
os.makedirs(OutputPath)
for num in range(len(in_jpg_member[member_num])):
image = cv2.imread(in_jpg_member[member_num][num])
if image is None:
print("Not open:")
continue
image_gs = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("/Users/keiju.sato/.pyenv/versions/3.6.8/lib/python3.6/site-packages/cv2/data/haarcascade_frontalface_alt.xml")
face_list = cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
count = 0
if len(face_list)>0:
for rect in face_list:
count += 1
x, y, width,height = rect
print(x, y, width,height)
image_face = image[y:y+height, x:x+width]
if image_face.shape[0] < 64:
continue
image_face = cv2.resize(image_face, (64, 64))
fileName = os.path.join(out_dir+str(in_jpg_member[member_num][num][7:-4])+"_"+str(count)+".jpg")
print(fileName)
cv2.imwrite(str(fileName), image_face)
else:
print("no face")
continue
OpenCVに入っているHaar Cascadesと呼ばれる分類器を用いて顔検出とcropを行っているのですが、Pythonではcv2.CascadeClassifierに引数としてxmlファイルへのパスを指定して使用します。findコマンドなどでhaarcascade_frontalface_alt.xmlを見つけてきて適宜パスを書き換えてください。それっぽいファイルがいくつか見つかった時は順番に試します。
そして"もう一回"各メンバーごとの写真だけを丁寧にチェックして残していきます。全く同じ複数枚の画像や違う人の画像は取り除き、手で少し隠れていたり特定色の照明がかなり強い画像などはそのまま残します。最終的に各200-300枚のなんとも幸せなディレクトリが出来上がります。
ここまできたらtrainディレクトリ内の全ての顔画像をsplit_test_from_train.pyでtrain用とtest用に分割します。書きながらメソッドを切り分けたためかなりとっ散らかってますが、「同じ構成をtestディレクトリ配下に作って一定割合数のデータを移動させる」だけです。
class DataSeparator():
def __init__(self, rate=0.15):
self.rate = rate
self.data_path = os.path.abspath('./data')
def validate_phase(self, phase):
if not phase in ['train', 'test']:
raise ValueError('Input "train" or "test" as dirname.')
def get_dir_path(self, phase):
self.validate_phase(phase)
return os.path.join(self.data_path, phase)
def get_dir_list(self, phase):
self.validate_phase(phase)
dir_path = self.get_dir_path(phase)
dir_list = os.listdir(dir_path)
for dir in dir_list:
if dir.startswith('.'):
dir_list.remove(dir)
return dir_list
def copy_directories(self):
train_dirlist = self.get_dir_list('train')
test_dirlist = self.get_dir_list('test')
test_path = self.get_dir_path('test')
for class_name in train_dirlist:
if not class_name in test_dirlist:
dir_name = os.path.join(test_path, class_name)
os.mkdir(dir_name)
def move_to_test(self):
self.copy_directories()
train_path = self.get_dir_path('train')
test_path = self.get_dir_path('test')
class_list = self.get_dir_list('train')
for class_name in class_list:
class_path = os.path.join(train_path, class_name)
data_list = os.listdir(class_path)
num_data = len(data_list)
num_test = int(num_data * self.rate)
test_idx = random.sample(range(num_data), k=num_test)
move_to = os.path.join(test_path, class_name)
for idx in test_idx:
chosen_data_path = os.path.join(class_path, data_list[idx])
shutil.move(chosen_data_path, move_to)
if __name__ == '__main__':
d = DataSeparator()
d.move_to_test()
全データを読み込んでから分割する方法(scikit-learnのsklearn.model_selection.train_test_split()など)もありますが、筆者はdata/配下にtrainとtestディレクトリを作成しそれぞれの中に各メンバーの画像を入れた個別ディレクトリを9つずつ配置しました。
Datasetクラス
Datasetはバッチごとにデータとラベルを渡してくれるクラスです。
まずは全データへのパスが入ったリストを作成します。今回は「あるクラスから2つ、異なるクラスからランダムに1つ選ぶ」特殊なやり方を実装しやすくするために名前:[データパスのリスト]を9要素持つ辞書型で作成しました。
def make_datapath_dic(phase='train'):
root_path = './data/' + phase
class_list = os.listdir(root_path)
class_list = [class_name for class_name in class_list if not class_name.startswith('.')]
datapath_dic = {}
for i, class_name in enumerate(class_list):
data_list = []
target_path = os.path.join(root_path, class_name, '*.jpg')
for path in glob.glob(target_path):
data_list.append(path)
datapath_dic[i] = data_list
return datapath_dic
そしてtrain、testそれぞれの際に「画像に対してどのような変換を行うのか」をクラスとしてまとめておくと後で別ファイルにしたりtransformの追加変更などがしやすく"HAPPY"になれます。後でインスタンス化しDatasetクラスに引数として渡します。__call__を実装して呼ばれた際にphase毎に設定したtransformをかけて返すようにします。
class ImageTransform():
def __init__(self, resize):
self.data_transform = {
'train': transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.2, 0.2, 0.2))
]),
'test': transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.2, 0.2, 0.2))
])
}
def __call__(self, img, phase='train'):
return self.data_transform[phase](img)
なお、PyTorchに画像を渡す際(に限らず全ての数値変数)はtorch.Tensor型~~(略して"TT")にして扱うためtrainでもtestでも(略して"TT")~~を入れておく必要があります。ToTensor()
またRandomHorizontalFlip()は確率で左右反転する処理で、データを水増ししたいtrainでのみ行います。
最後にDatasetクラスを作成します。今回実装するTriplet Lossはある次元で張るembedding(埋め込み)空間において、ランダムにひとつ選んだ基準データ(anchor)と同じクラスデータ(positive)をひとつ近づけ、異なるクラスデータ(negative)をひとつ遠ざけるように学習を進めます。
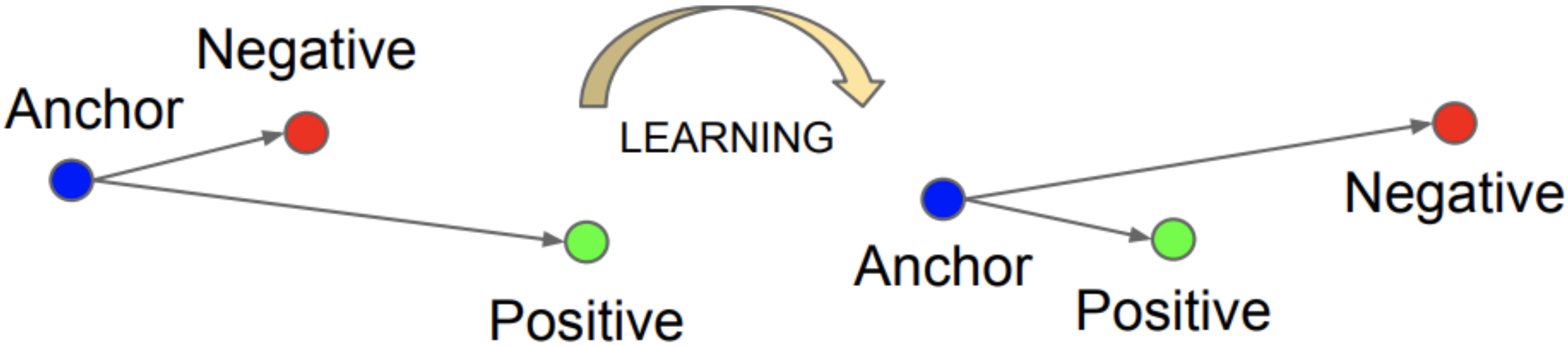
そのため今回のDatasetクラスには、あるメンバーの画像2枚(anchorとpositive)とそのクラス、そして異なるメンバーの画像(negative)1枚をまとめて渡してもらえるように実装します。
Datasetクラスはtorch.utils.dataパッケージ内のDatasetクラスを継承し、データの総数を返す__len__と、投げられるデータ番号(index: 0から__len()__-1)指定に対して返すデータ(と必要ならラベル)を定義する__getitem__をindex引数付きで記述する必要があります。
class TripletDataset(Dataset):
def __init__(self, datapath_dic, transform=None, phase='train'):
self.datapath_dic = datapath_dic
self.transform = transform
self.phase = phase
all_datapath = []
bins = [0]
for data_list in self.datapath_dic.values():
all_datapath += data_list
bins.append(bins[-1] + len(data_list))
self.all_datapath = all_datapath
self.bins = bins
def __len__(self):
return len(self.all_datapath)
def __getitem__(self, idx):
anchor_path = self.all_datapath[idx]
for i in range(len(self.bins)):
if idx < self.bins[i]:
positive_pathlist = self.all_datapath[self.bins[i-1]:self.bins[i]]
negative_pathlist = self.all_datapath[:self.bins[i-1]] + self.all_datapath[self.bins[i]:]
anchor_label = i
break
positive_path = random.choice(positive_pathlist)
negative_path = random.choice(negative_pathlist)
anchor = self.transform(Image.open(anchor_path), self.phase)
positive = self.transform(Image.open(positive_path), self.phase)
negative = self.transform(Image.open(negative_path), self.phase)
return anchor, positive, negative, anchor_label
ちなみに通常のクラス分類を行うCNNの場合は、以下のようにリスト型からパス名に含まれるメンバーの名前をラベルにその場で対応させて渡しました。
def make_datapath_list(phase='train'):
root_path = './data'
target_path = os.path.join(root_path, phase, '*/*.jpg')
path_list = []
label_list = []
for path in glob.glob(target_path):
path_list.append(path)
return path_list
class MyDataset(Dataset):
def __init__(self, file_list, transform=None, phase='train'):
self.file_list = file_list
self.transform = transform
self.phase = phase
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
img_path = self.file_list[idx]
img = Image.open(img_path)
img_transformed = self.transform(img, self.phase)
if 'NAYEON' in img_path:
label = 0
elif 'JEONGYEON' in img_path:
label = 1
elif 'MOMO' in img_path:
label = 2
elif 'SANA' in img_path:
label = 3
elif 'JIHYO' in img_path:
label = 4
elif 'MINA' in img_path:
label = 5
elif 'DAHYUN' in img_path:
label = 6
elif 'CHAEYOUNG' in img_path:
label = 7
elif 'TZUYU' in img_path:
label = 8
return img_transformed, label
ただ一度に渡す画像が1枚でいい時はtorchvision.datasetsのImageFolderクラス(公式ドキュメント)で爆速でよしなにDatasetインスタンスを作れるので要検討です。
(参考記事: PyTorchで自作のデータセットの使い方をまとめてみた)
DataLoader
学習、推論の各コード内に記述しているので後述。
データをバッチサイズにまとめて"優雅に"返してくれるクラスです。
モデル
まず機械学習でデータの質ぐらい大事なlossですが、torch.nn内に多数実装された代表的なものに加えてもちろん新しく定義して利用することも出来ます。今回は上述の通り、同じクラスのデータを空間内で近付けつつ違うクラスのデータを遠ざけるTriplet Lossクラスを自作します。
オリジナルのLossを定義するには、nn.Moduleを継承したクラスに実際にlossを計算してその値を返すforwardを実装します。
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super().__init__()
self.margin = margin
def calculate_euclidean(self, x1, x2):
return (x1 - x2).pow(2).sum(1)
def forward(self, anchor, positive, negative, size_average=True):
distance_positive = self.calculate_euclidean(anchor, positive)
distance_negative = self.calculate_euclidean(anchor, negative)
losses = F.relu(distance_positive - distance_negative + self.margin)
return losses.mean() if size_average else losses.sum()
今回、embedding空間におけるデータ間の距離は(単純ですが)ユークリッド距離としました。ちなみにlossはクラス構造である必要は必ずしも無く、関数でも正しくパラメータ更新は行われるらしいです。そうしたい時ってあるのだろうか。もしかして他もクラスじゃなくてもよかったりするのだろうか。
そしてモデルクラスを実装します。__init__内で使う層を名前をつけて用意し、順伝播時のフローをforward内に記述します。各層を流れて活性化関数をかけるイメージをかなりそのまま書けて感動しました。
今回のネットワーク(論文は後述)は、入力が(バッチサイズ, チャンネル数, 画像のwidth, 画像のheight)の4次元Tensor、出力がembedding空間の次元数になっています。途中の畳み込みとMax PoolingはCNNでおなじみで、ここを「距離の取り方」に基づいて学習させます。今回はユークリッド距離でTriplet Lossですね。
class TripletNet(nn.Module):
def __init__(self, embedding_dim=128, num_class=9):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, 5)
self.bn1 = nn.BatchNorm2d(64)
self.conv2 = nn.Conv2d(64, 128, 3)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.Conv2d(128, 256, 3)
self.bn3 = nn.BatchNorm2d(256)
self.conv4 = nn.Conv2d(256, 128, 2)
self.bn4 = nn.BatchNorm2d(128)
self.maxpool = nn.MaxPool2d(2)
self.avgpool = nn.AvgPool2d(5)
# self.dropout = nn.Dropout2d()
# self.classifier = nn.Linear(embedding_dim, num_class)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.bn1(x)
x = self.maxpool(x)
x = F.relu(self.conv2(x))
x = self.bn2(x)
x = self.maxpool(x)
x = F.relu(self.conv3(x))
x = self.bn3(x)
x = self.maxpool(x)
x = self.conv4(x)
x = self.bn4(x)
x = self.avgpool(x)
# x = self.dropout(x)
# x = x.view(-1, 128*5*5)
# x = F.relu(self.fc(x))
# x = self.classifier(x)
return x
コメントアウトしている部分は通常のクラス分類を行うCNNの実装です、ご参考までに。ArcFaceなど最新の論文ではクラス分類問題として学習しながらMetric Learningを行っており、いずれは実装したい意思が表れています。
なお、KerasのSequentialのように書く方法もあります。詳細は公式ドキュメントをご確認ください。エンジニアにとって公式ドキュメントはいつも"そばにいて"欲しい最高の資料です。
個人的にはこの2通りの書き方を使い分けたい場面にまだ遭遇していませんが、本記事で実装するような数層レベルのネットワーク構成はtorch.nn.Sequentialでも良かったと思います。一方でResNetやBERTのように同じ層やそのブロックが何回も出てくる時は以下の書き方を使うと楽に記述できそうです。
今回はTriplet Networkの原論文を参考にモデルを組みましたが、ResNetなど既存のモデルでFine-Tuningを行う場合は以下のようにすると良いです。こちらもご参考までに。forループで最終層を除いた全ての層のパラメータ更新をオフにし、付け替える全結合層のみパラメータ更新を行うようにしています。
class TripletResNet(nn.Module):
def __init__(self, metric_dim):
super().__init__()
resnet = torchvision.models.resnet18(pretrained=True)
for params in resnet.parameters():
params.requires_grad = False
self.model = nn.Sequential(
resnet.conv1,
resnet.bn1,
resnet.relu,
resnet.maxpool,
resnet.layer1,
resnet.layer2,
resnet.layer3,
resnet.layer4,
resnet.avgpool,
)
self.fc = nn.Linear(resnet.fc.in_features, metric_dim)
def forward(self, x):
x = self.model(x)
x = x.view(x.size(0), -1)
x = F.relu(self.fc(x))
return x
学習
学習処理をtrain関数として先にまとめておきます。forループ内が1epoch分の処理です。model、train用DataLoader、Loss関数(criterion)、パラメータ更新アルゴリズム(optimizer)を渡し、バッチサイズに応じて学習を行います。
def train(args, model, train_loader, criterion, optimizer, epoch):
model.train()
running_loss = 0.
for batch_idx, (anchor, positive, negative, _) in enumerate(train_loader):
optimizer.zero_grad()
anc_embedding = model(anchor)
pos_embedding = model(positive)
neg_embedding = model(negative)
loss = criterion(anc_embedding, pos_embedding, neg_embedding)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 15 == 14:
print(f'epoch{epoch}, batch{batch_idx+1} loss: {running_loss / 15}')
train_loss = running_loss / 15
running_loss = 0.
return train_loss
-
optimizer.zero_gradで勾配を初期化 -
criterionが返したクラスは.backwardで勾配を計算、.item()で値を取り出す - 勾配を計算し
optimizer.step()で重みパラメータを更新 - 得られたlossをバッチ数で割って返す
を1ループとしてこれをepoch数回行います。なんとなく15バッチ毎にlossを確認したかったので表示しています。
そしていよいよ学習を実行します。DataLoaderクラスにはDatasetインスタンス、バッチサイズを渡します。PyTorchにはGPUを認識してくれる便利なメソッドが用意されており、
device = 'cuda' if torch.cuda.is_available() else 'cpu'
と書いておくことで変数deviceを使い回せます。モデルをインスタンス化し、.to(device)でCPUまたはGPUに乗せます。
if __name__ == '__main__':
train_dic = make_datapath_dic('train')
transform = ImageTransform(64)
train_dataset = TripletDataset(train_dic, transform=transform, phase='train')
batch_size = 32
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = TripletNet().to(device)
criterion = TripletLoss()
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=0.9, weight_decay=1e-4)
# scheduler = optim.lr_scheduler.MultiStepLR(
# optimizer, milestones=[args.epochs//2, (args.epochs//4)*3], gamma=0.1
# )
summary(model, (3, 64, 64))
torch.autograd.set_detect_anomaly(True)
x_epoch_data = []
y_train_loss_data = []
for epoch in range(1, args.epochs+1):
train_loss_per_epoch = train(
args, model, train_dataloader, criterion, optimizer, epoch
)
# scheduler.step()
x_epoch_data.append(epoch)
y_train_loss_data.append(train_loss_per_epoch)
plt.plot(x_epoch_data, y_train_loss_data, color='blue', label='train_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='upper right')
plt.title('loss')
plt.show()
if args.save_model:
model_name = str(y_train_loss_data[-1]) + '.pth'
torch.save(model.state_dict(), model_name)
print(f'Saved model as {model_name}')
torch.autograd.set_detect_anomaly(True)としておくとbackward演算時TensorにNaNを検出するとエラーを吐いて止めてくれます。with torch.autograd.detect_annomaly():としてこの中で学習を回す使い方もできます。
ちなみにsummaryはPyTorchのネットワークアーキテクチャを確認できるpytorch-summaryというライブラリです。pip install torchsummaryでインストールし、モデルと入力サイズを渡しておくと実行時ターミナルに
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 60, 60] 4,864
BatchNorm2d-2 [-1, 64, 60, 60] 128
MaxPool2d-3 [-1, 64, 30, 30] 0
Conv2d-4 [-1, 128, 28, 28] 73,856
BatchNorm2d-5 [-1, 128, 28, 28] 256
MaxPool2d-6 [-1, 128, 14, 14] 0
Conv2d-7 [-1, 256, 12, 12] 295,168
BatchNorm2d-8 [-1, 256, 12, 12] 512
MaxPool2d-9 [-1, 256, 6, 6] 0
Conv2d-10 [-1, 128, 5, 5] 131,200
BatchNorm2d-11 [-1, 128, 5, 5] 256
AvgPool2d-12 [-1, 128, 1, 1] 0
================================================================
Total params: 506,240
Trainable params: 506,240
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 6.36
Params size (MB): 1.93
Estimated Total Size (MB): 8.34
----------------------------------------------------------------
このように表示してくれます。すごい。
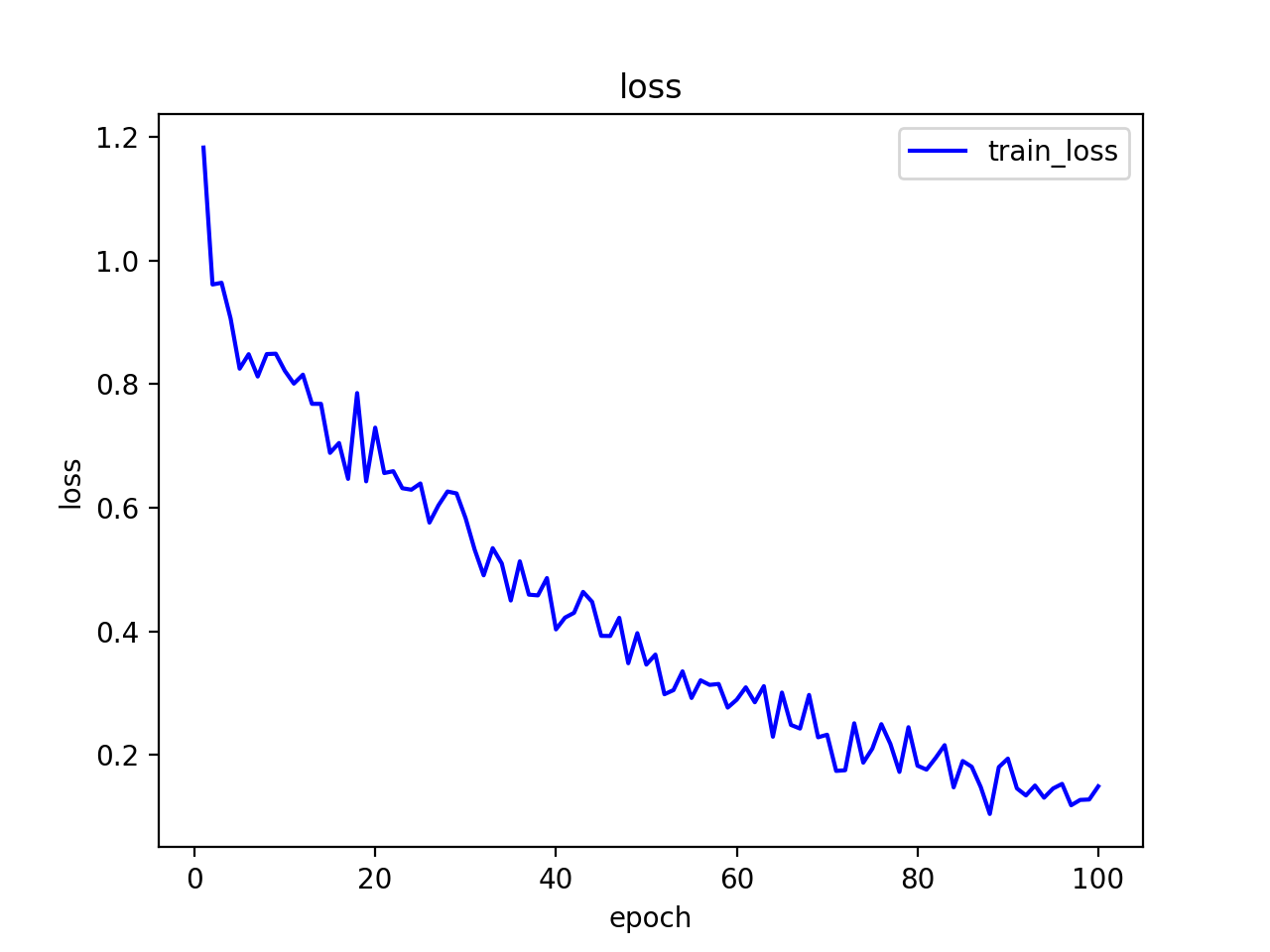
モデルの元であるTriplet Networkの原論文では学習率0.5と書かれていますが、大き過ぎる気がします。0.01で100epoch回したところlossが下がっていきました。これはモデルがうまく学習できている"シグナル"ではないでしょうか。
推論
初めて学習がうまく回った時は"夜通し踊って"しまうほど喜んだのですが、モデルがきちんと学習できているか確かめるところまで(むしろここから)が機械学習です。
今回はきちんとメンバー9人を分離できるかを可視化するため、scikit-learnに実装されているt-SNEを使用します。Kaggleなどのデータコンペでもよく使われますね。詳しい使い方はこちら。
詳細なアルゴリズムは他記事に譲るとして、ざっくり言うと高次元データをその空間的関係性を保って確率分布が近くなる次元圧縮を行い、ぱっと見で距離が分かるようにしてくれます。ざっくりしすぎて怒られそう。こちらのブログ記事などがかなり分かりやすいです。
ちなみにですがPythonのスクリプトファイルにtest.pyと名前をつけてしまうと、他の場所でimport testとした時にうまくいかないことがあります。Pythonに標準で用意されているtestモジュールが優先されてしまうためです。tests.pyなどにしておくとよいと思います。
if __name__ == '__main__':
test_dic = make_datapath_dic('test')
transform = ImageTransform(64)
test_dataset = TripletDataset(test_dic, transform=transform, phase='test')
batch_size = 32
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = TripletNet().to(device)
model.eval()
model_weights = '0.14895377705494564.pth'
model.load_state_dict(torch.load(model_weights))
summary(model, (3, 64, 64))
predicted_metrics = []
test_labels = []
with torch.no_grad():
for i, (anchor, _, _, label) in enumerate(test_dataloader):
metric = model(anchor).detach().cpu().numpy()
metric = metric.reshape(metric.shape[0], metric.shape[1])
predicted_metrics.append(metric)
test_labels.append(label.detach().numpy())
predicted_metrics = np.concatenate(predicted_metrics, 0)
test_labels = np.concatenate(test_labels, 0)
tSNE_metrics = TSNE(n_components=2, random_state=0).fit_transform(predicted_metrics)
plt.scatter(tSNE_metrics[:, 0], tSNE_metrics[:, 1], c=test_labels)
plt.colorbar()
plt.savefig(model_weights + '.png')
plt.show()
うまく学習できていれば、テストデータたちは色ごとに平面上で9つの塊に分かれるはずです。
結果がこちら。
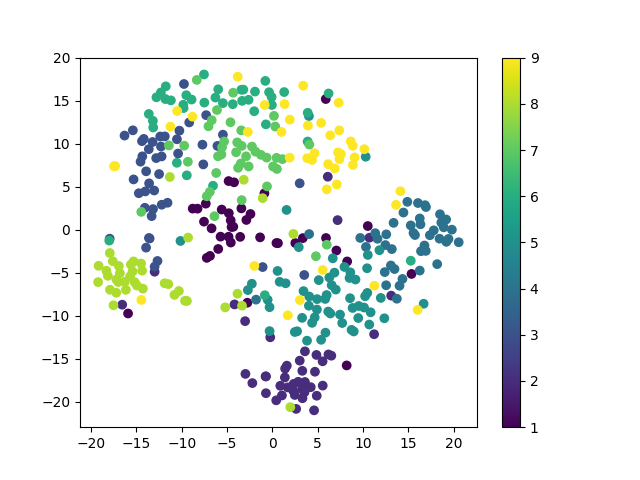
...。
学習のlossは下がったのにうまく分離できていない"飴"と鞭っぷりに面食らってしまいました。
できてないようにも見えますし、なんとなく各メンバーの画像が同じところに集まっているようにも見えますし、lossもまだ学習が終わっていないようにも見えました。
キレイに分離しきれていない(学習したモデルが良くない)原因としては
- (TWICEのお顔はとても良いけど)質のいい良いデータとは言えない
- 手、髪、マイクなどで一部が隠れている
- 撮られた時期によって化粧や髪色などがバラバラ
- そもそも学習データ数が少ない
- 学習時のデータの選び方
- Semi-hard Negativeなペアを選べば学習がより進む
- 距離の定義が最適でない
- モデルの表現力が弱い
- (例えばサナとツウィなど)写真によっては人間でも区別がかなり難しいメンバーがいる(もちろんファンは見れば分かる)
などがパッと思いつきます。"嘘と真実"が混ざっている気がしますが、今は皆さんの判断にお任せします。改善の余地しかないというオチをおゆるしください。
まとめ
Metric Learningを通してPyTorchで自作データセットを自作モデルに学習させてみました。本当に楽しく勉強できたので"今年一番やってよかったこと"だと思います。"愛とは何か"を感じました。
Triplet LossによるMetric Learningを実装した記事としては未達ですが、研究内容に関してもPyTorchについても本当に何も知らなかった2ヶ月前の自分に向けて書いたつもりです。QiitaにしかもアドカレでしかもTWICEを語ってしかも成功とは言い切れないような記事を書かせていただけるとは何と寛容なインターン先...。
そしていつもアドバイスと刺激を山ほどくれる"スペシャルな"友達とそのリポジトリに感謝...。
やはり好きなことが絡むと"元気づけ"られて勉強がめちゃめちゃ捗ります。とはいえこのままではコードも研究の理解もまだまだ過ぎますしTWICEにも顔向けできないので(?)、これからも自分で書いてみたモデルの学習がちゃんと回った時の喜びを忘れることなく精進していきます。どこか少しでも良いなと"心揺さぶられ"たら"いいね"お願いします^^
今更すぎますがTWICEは今までに出たMVがなかなかに多く、歴代全作品を入れたらとんでもないことになってしまいました。申し訳ありませんでした。
明日はHRのぱおぱおしょうろんぽうさんが記事を書く予定です。名前面白すぎる。
そして最後に。
マジで良い記事ばかりなので是非他のABEJAアドカレもチェックしてみてください!
"I WANT YOU BACK"!!