python jupter ValueError: cannot set a row with mismatched columns
解決したいこと
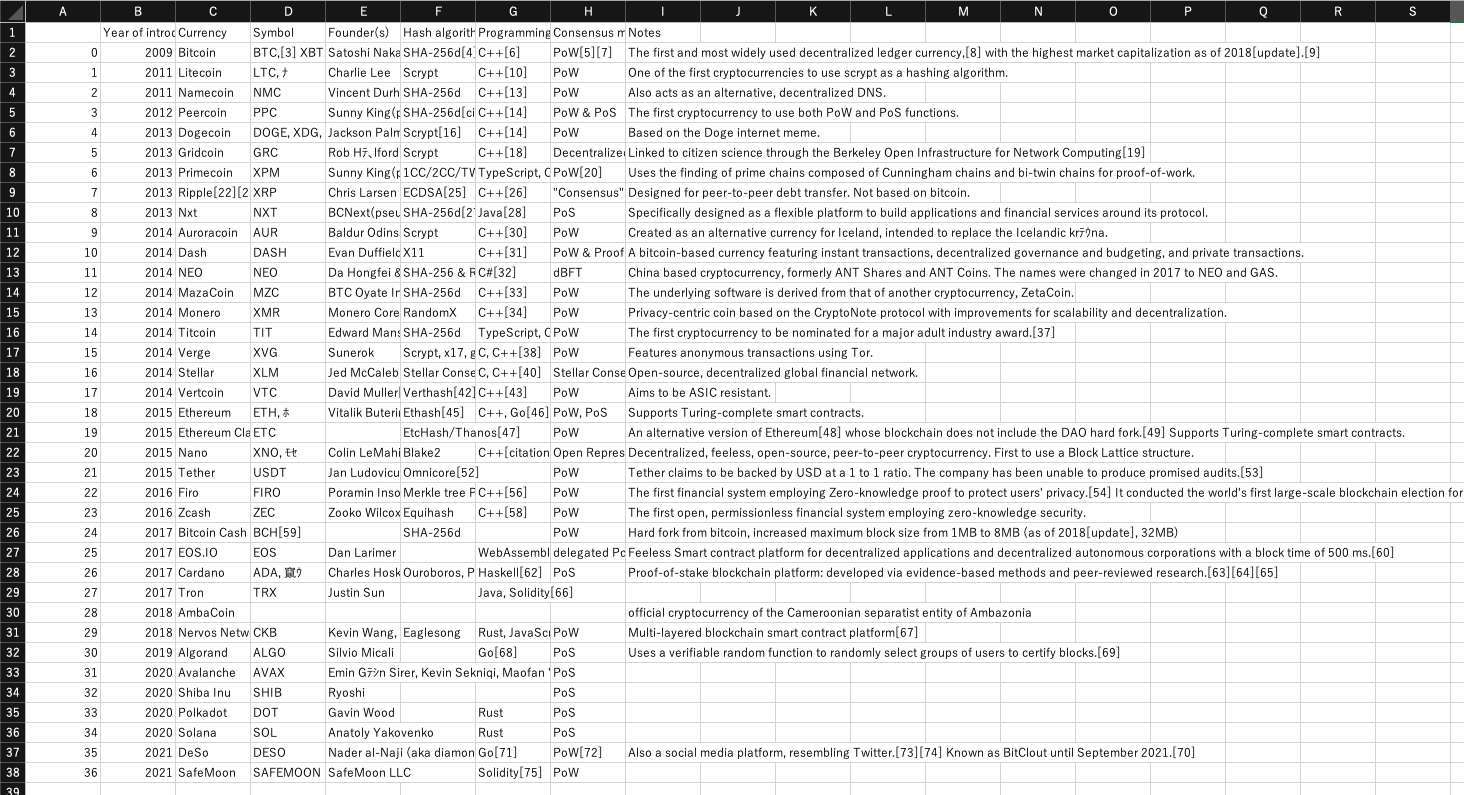
jupyterで "https://en.wikipedia.org/wiki/List_of_cryptocurrencies"のデータを取得したいので、df.loc[length] = individual_row_dataのエラー解決したい。
問題発生してるエラー
ValueError Traceback (most recent call last)
Cell In[326], line 6
3 individual_row_data = [data.text.strip() for data in row_data]
5 length = len(df)
----> 6 df.loc[length] = individual_row_data
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\core\indexing.py:911, in _LocationIndexer.__setitem__(self, key, value)
908 self._has_valid_setitem_indexer(key)
910 iloc = self if self.name == "iloc" else self.obj.iloc
--> 911 iloc._setitem_with_indexer(indexer, value, self.name)
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\core\indexing.py:1932, in _iLocIndexer._setitem_with_indexer(self, indexer, value, name)
1929 indexer, missing = convert_missing_indexer(indexer)
1931 if missing:
-> 1932 self._setitem_with_indexer_missing(indexer, value)
1933 return
1935 if name == "loc":
1936 # must come after setting of missing
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\core\indexing.py:2306, in _iLocIndexer._setitem_with_indexer_missing(self, indexer, value)
2303 if is_list_like_indexer(value):
2304 # must have conforming columns
2305 if len(value) != len(self.obj.columns):
-> 2306 raise ValueError("cannot set a row with mismatched columns")
...
2310 if not len(self.obj):
2311 # We will ignore the existing dtypes instead of using
2312 # internals.concat logic
ValueError: cannot set a row with mismatched columns
### 該当するソースコード
```言語名
python jupyter
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/List_of_cryptocurrencies"
page = requests.get(url)
soup = BeautifulSoup(page.text, "html")
print(soup)
soup.find('table', class_ = "wikitable sortable" )
table = soup.find_all('table')[1]
print(table)
world_titles = soup.find_all('th')
world_titles
world_table_titles = [title.text.strip() for title in world_titles]
print(world_table_titles)
df = pd.DataFrame(columns = world_table_titles)
df
for row in column_data[1:]:
row_data = row.find_all('td')
individual_row_data = [data.text.strip() for data in row_data]
length = len(df)
df.loc[length] = individual_row_data
df
自分で試したこと
一通り調べてエラーの改善方法をしてみました。
0 likes