背景
RAGって、データの取り込みや、チャンクサイズ、embedding modelやLLMなどを考慮しつつ、それらをPythonで書くのって結構大変。そんなときにIBMから、ノーコードで簡単に、そして自分で修正することもできるから玄人にもおすすめできる、Chat with Documentをご紹介いただいたので、簡単に記事を書いてみました。
前提
watsonx.ai、watsonx.data Milvus、IBM Cloud Object Storageが払い出し済み
手順
IBM Cloudにログイン後、「リソース・リスト」から「watsonx.ai studio」を選択し、「Launch in」の「IBM watsonx」を選択してください。(私は一回目ここで迷いました。)
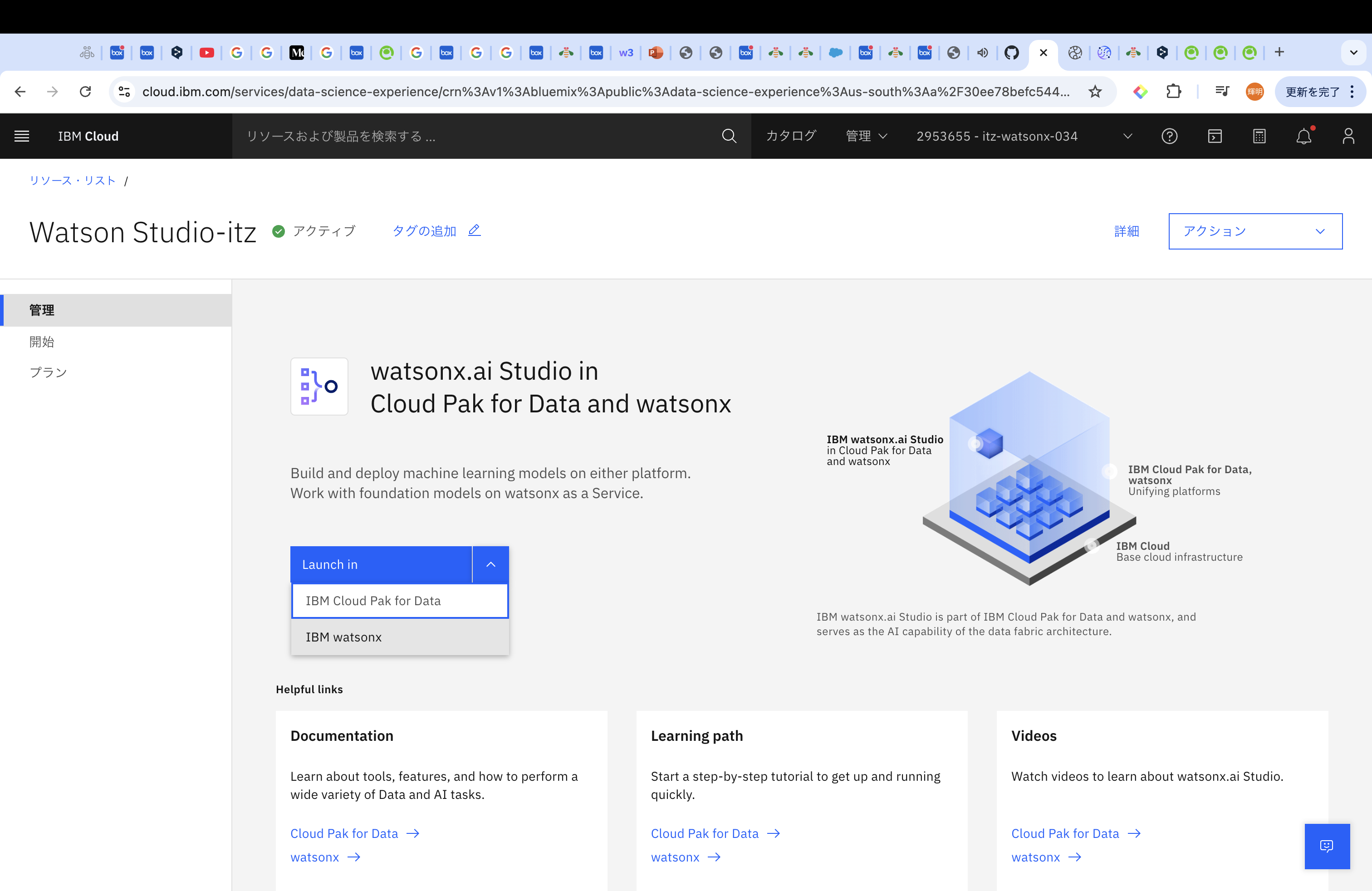
ログインすると以下のような画面になります。その後下にスクロールしていき、プロジェクトから「新規プロジェクトの作成」を選択します。
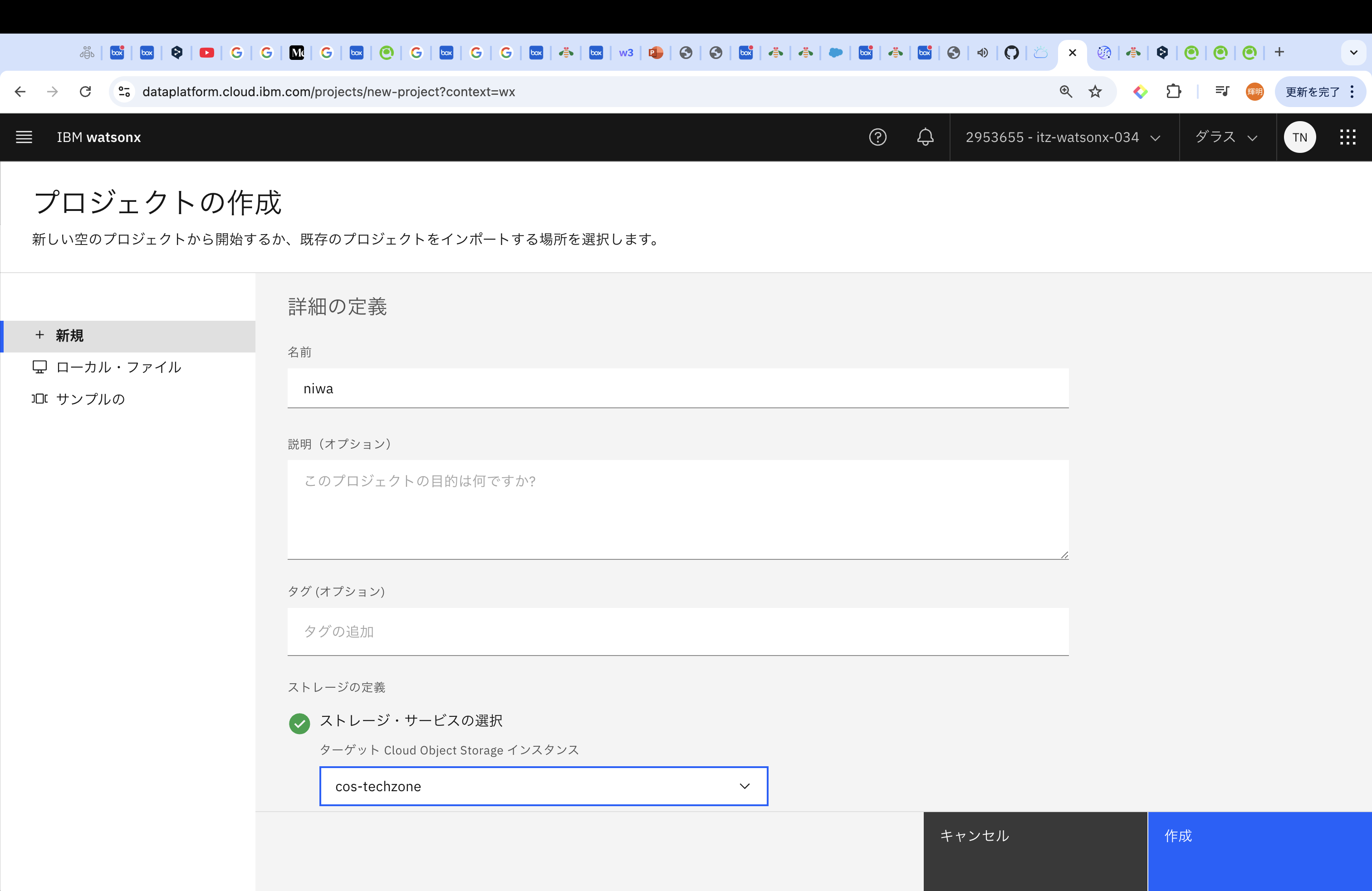
プロジェクトは、名前やストレージなどを入力する必要があります。その後作成を押してください。
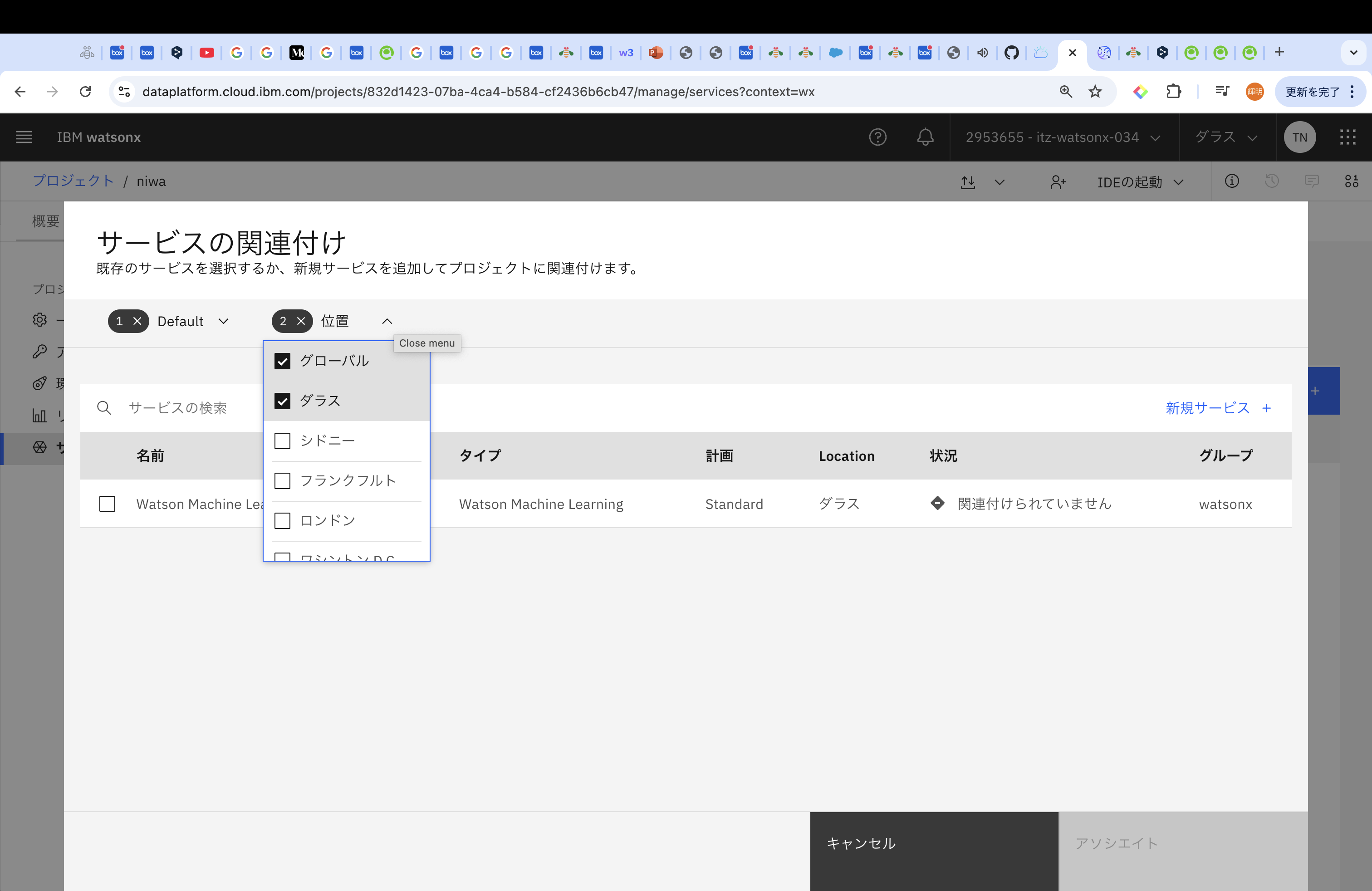
プロジェクト作成後は、「管理」タブから「サービスおよび結合」を選択し、「サービスの関連付け」でWMLを紐付けます。
IBMはプロジェクトごとにWMLを結びつけるんですね。
WMLは基本的にデフォルトで出てくるとは思いますが、出てこない場合は、「位置」でリージョンを確認してみてください。(私は一度ここで心が折れました。)
続けて、「アセット」タブから新規資産を選択して、「ベクトル化されたドキュメントを使ったAI」を選択ください。
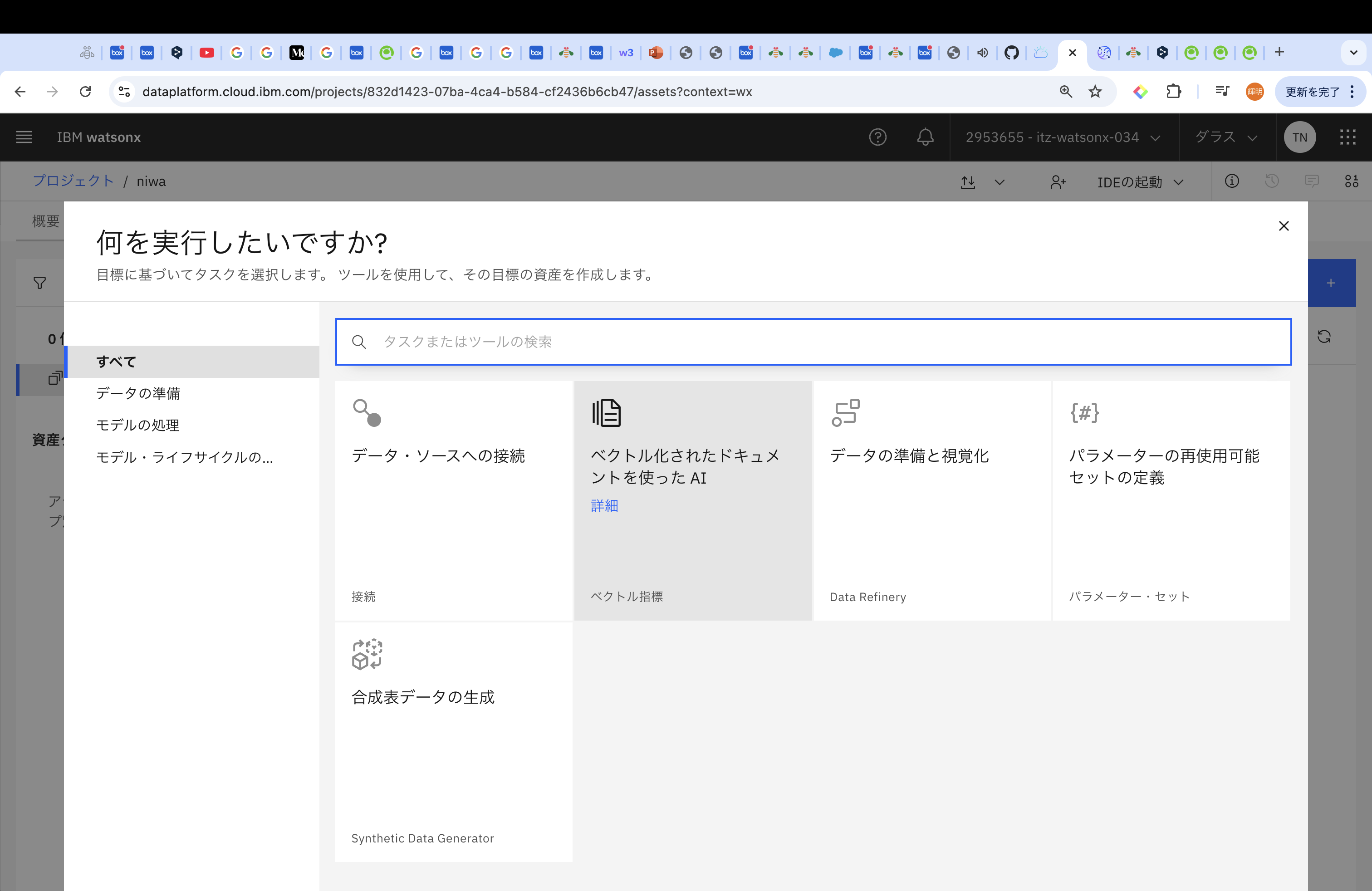
選択肢として、「メモリー内」「watsonx.data Milvus」「Elasticsearch」があります。今回は、「watsonx.data Milvus」を選択していきます。
事前に払い出してあるwatsonx.data Milvusに接続をしていきます。「接続の作成」を押します。
作成後以下のような入力画面にいきます。
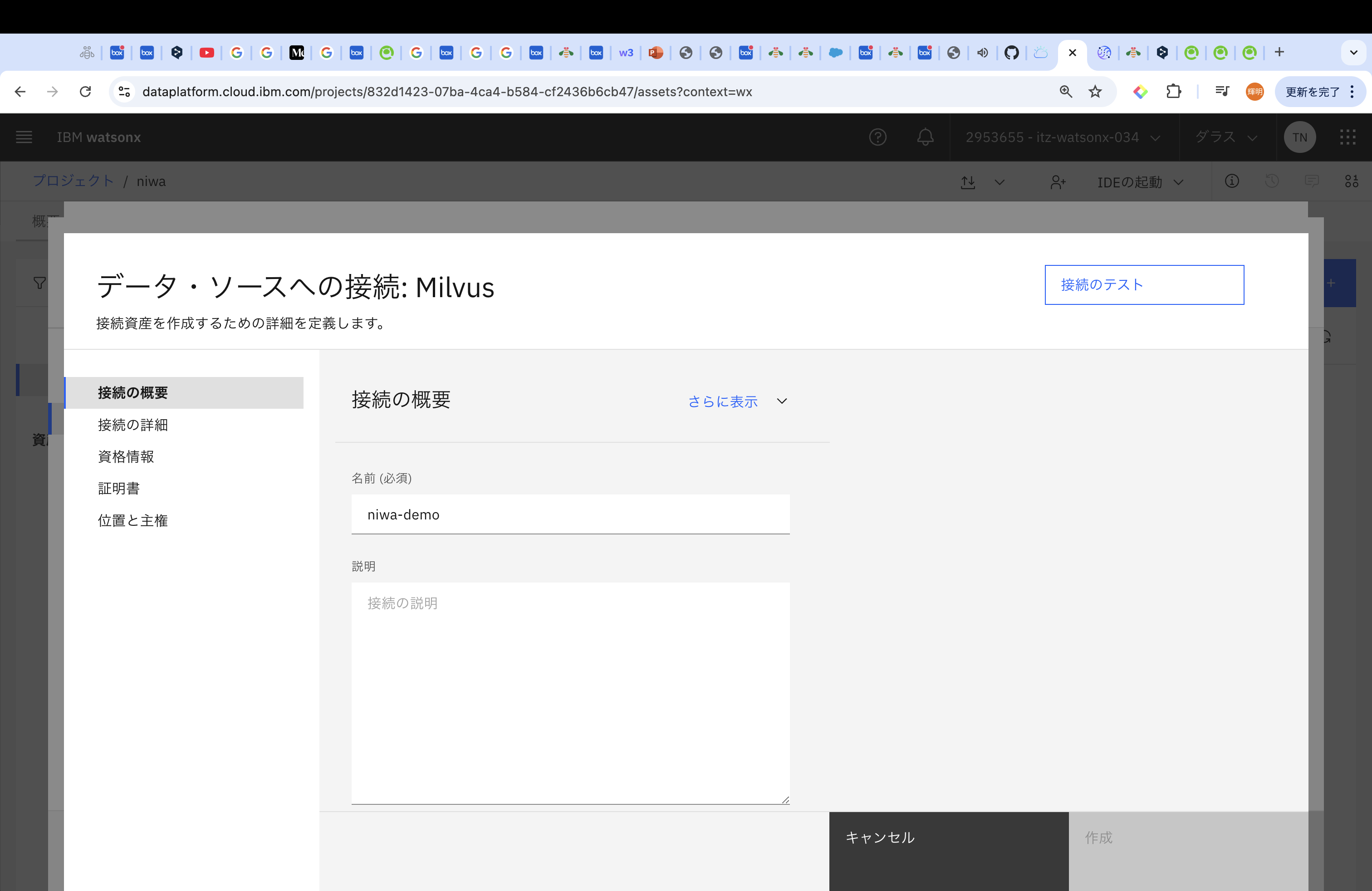
名前 (必須):適当、今回はniwa-demo
ホスト名(必須):gRPCホストのポート前まで
ポート(必須):gRPCのポート
ユーザー名(必須):ibmlhapikey
パスワード(必須):watsonx.data Milvusが払い出されているアカウントへのAPIキー
を入力してください。
gRPCホストなどの情報取得方法はこちらの参考Qiitaをぜひ!
すべての情報を入力後、「接続のテスト」で確認してから、「作成」で進めていきます。
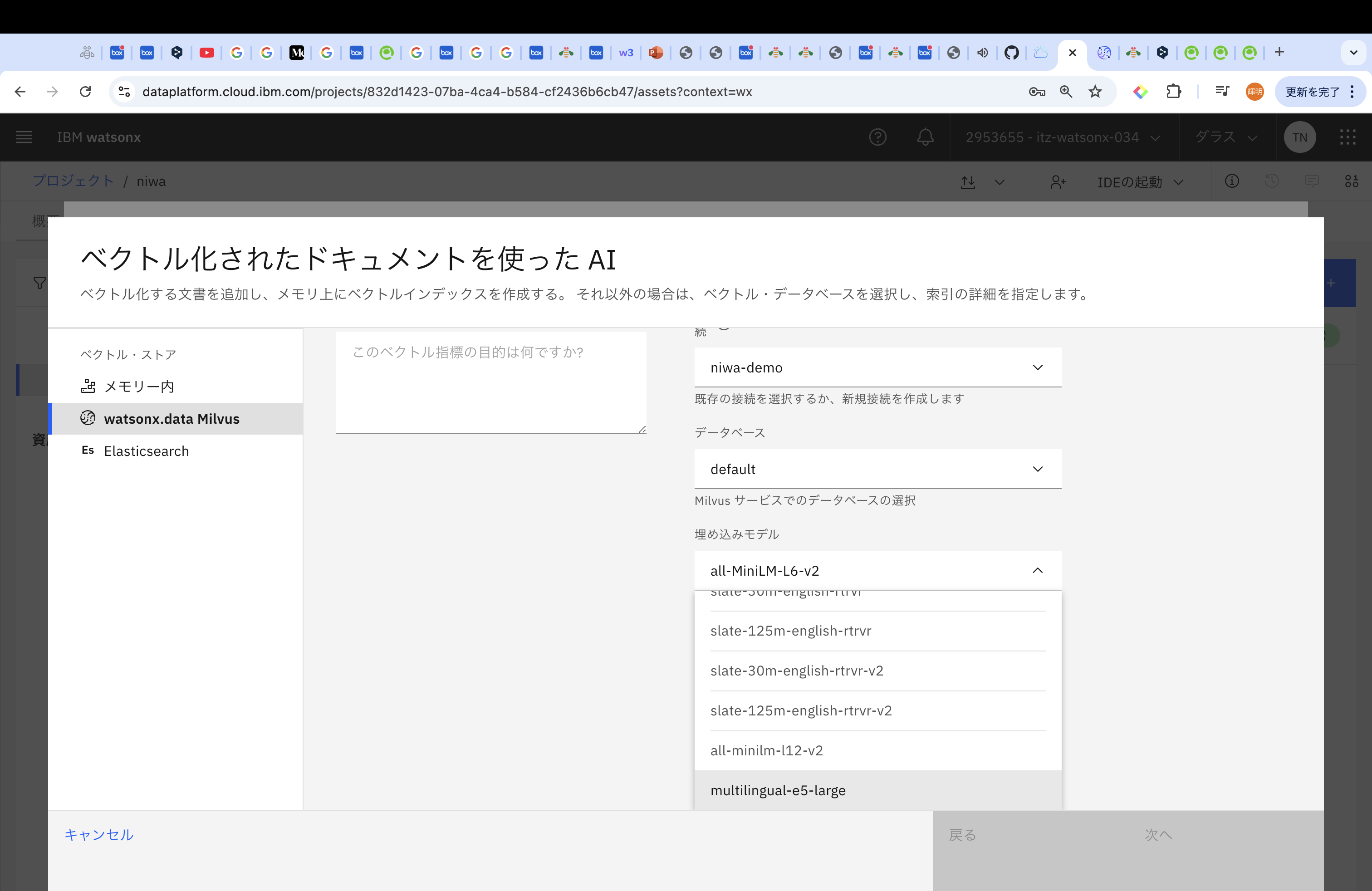
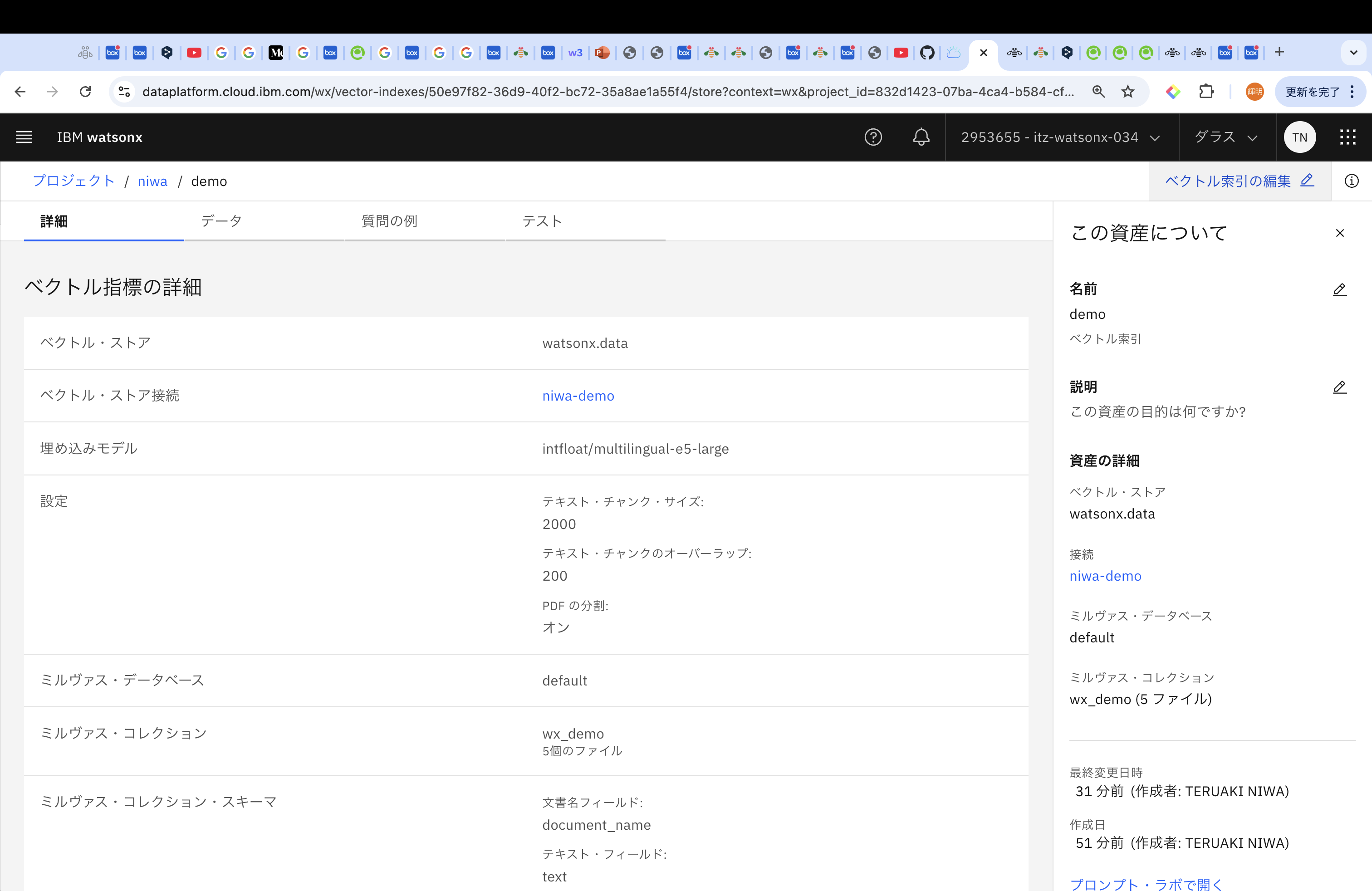
先ほどまで「接続の作成」だった箇所が、Milvusの名前に変わっています。データベースはdefaultにして、埋め込みモデルを選定します。埋め込みモデルは言語やユースケースによって異なりますが、今回は、「multilingual-e5-large」を試します。
Milvusではコレクションごとにベクトルを管理することができます。今回は「新規コレクション」を選択します。
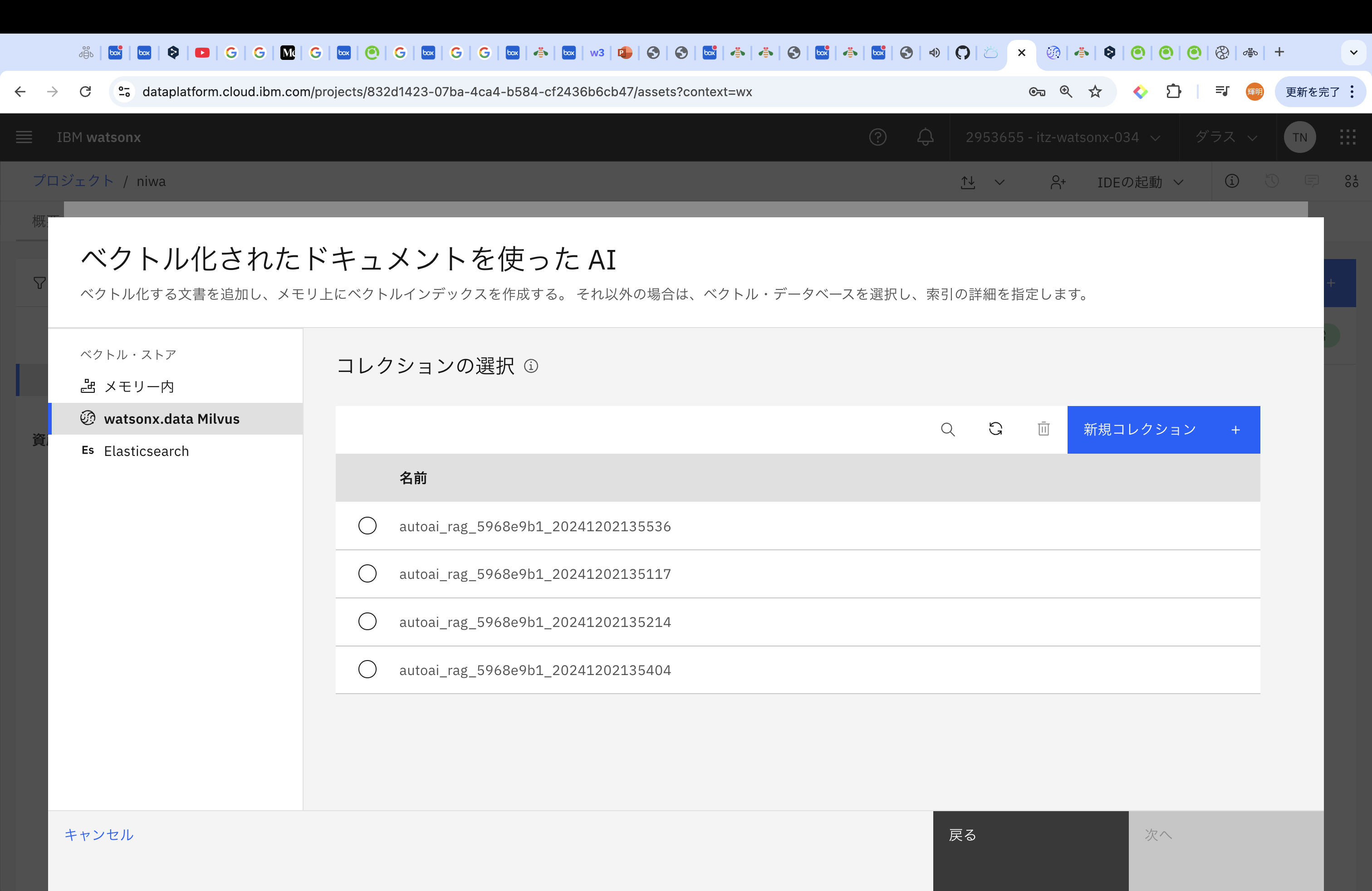
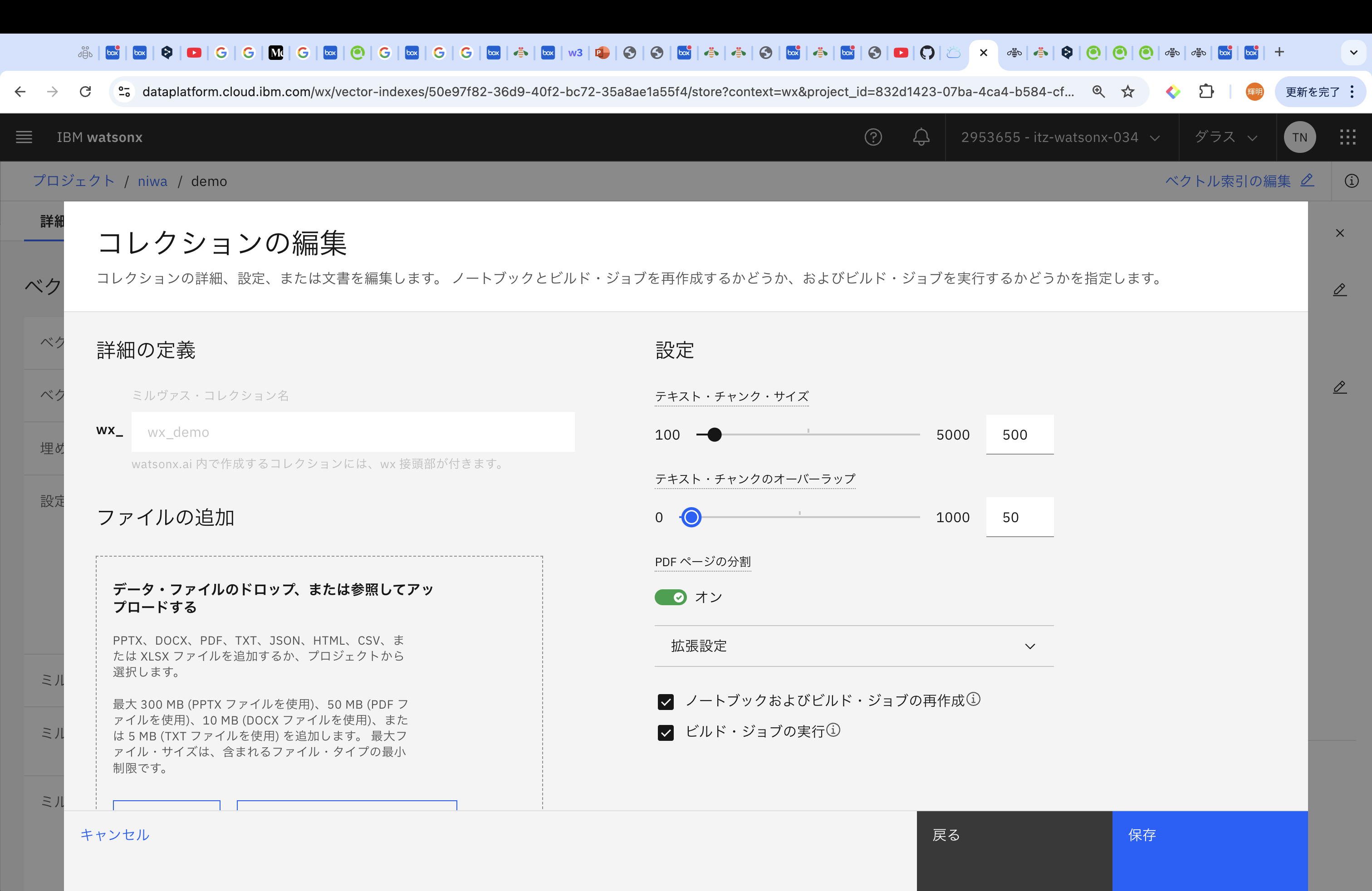
コレクションの名前をつけ、その後ファイルを追加していきます。
ファイルは、PPTX(300MBまで)、DOCX(10MBまで)、PDF(50MBまで)、TXT(5MBまで)、JSON(5MBまで)、HTML(5MBまで)、CSV(5MBまで)、XLSX(5MBまで)から参照することができます。
また、アップロードする文書に応じて、チャンクサイズやオーバーラップの値を設定してください。チャンクにより、生成AIの参考文書として適切な大きさに分けます。チャンクが小さすぎて意味が途中で切れてしまうと、生成AIは当然正しく文章を生成することはできませんし、チャンクが大きすぎると、生成AIは、参考する箇所が多すぎて関係ない情報過多になり、混乱しちゃいます。センター試験の国語を思い出しますね。
まぁ、実施した後にこのチャンクサイズなども再調整できるので、最初はデフォルトで実施します。
今回使用する資料はDb2 12.1とIBM Database Assistantの提供開始です。その後、「作成」を押してください。
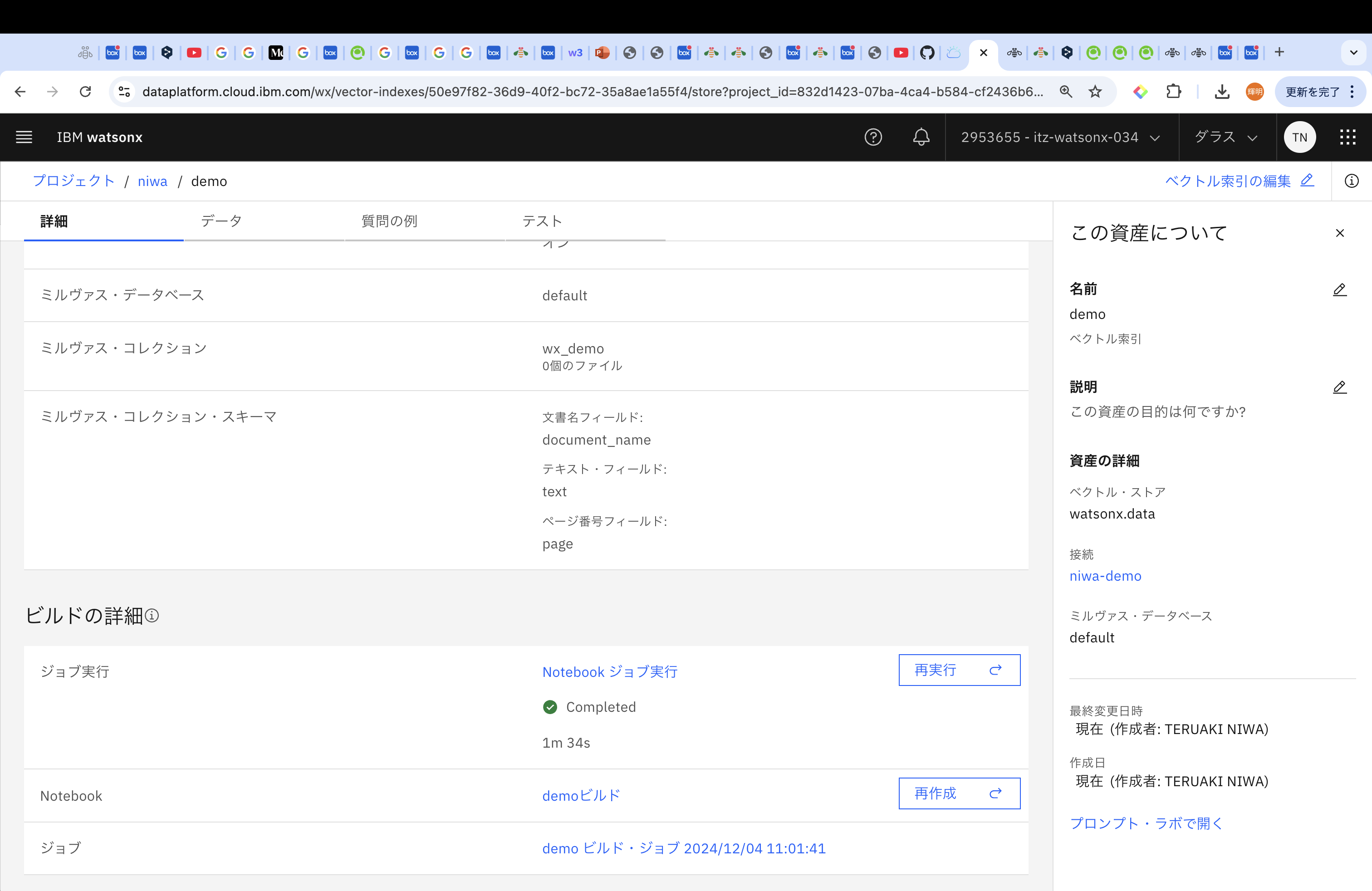
作成後、以下のような画面に変遷するので、下にスクロールしていき、ビルドの詳細→ジョブ実行がCompletedしたことを確認してください。
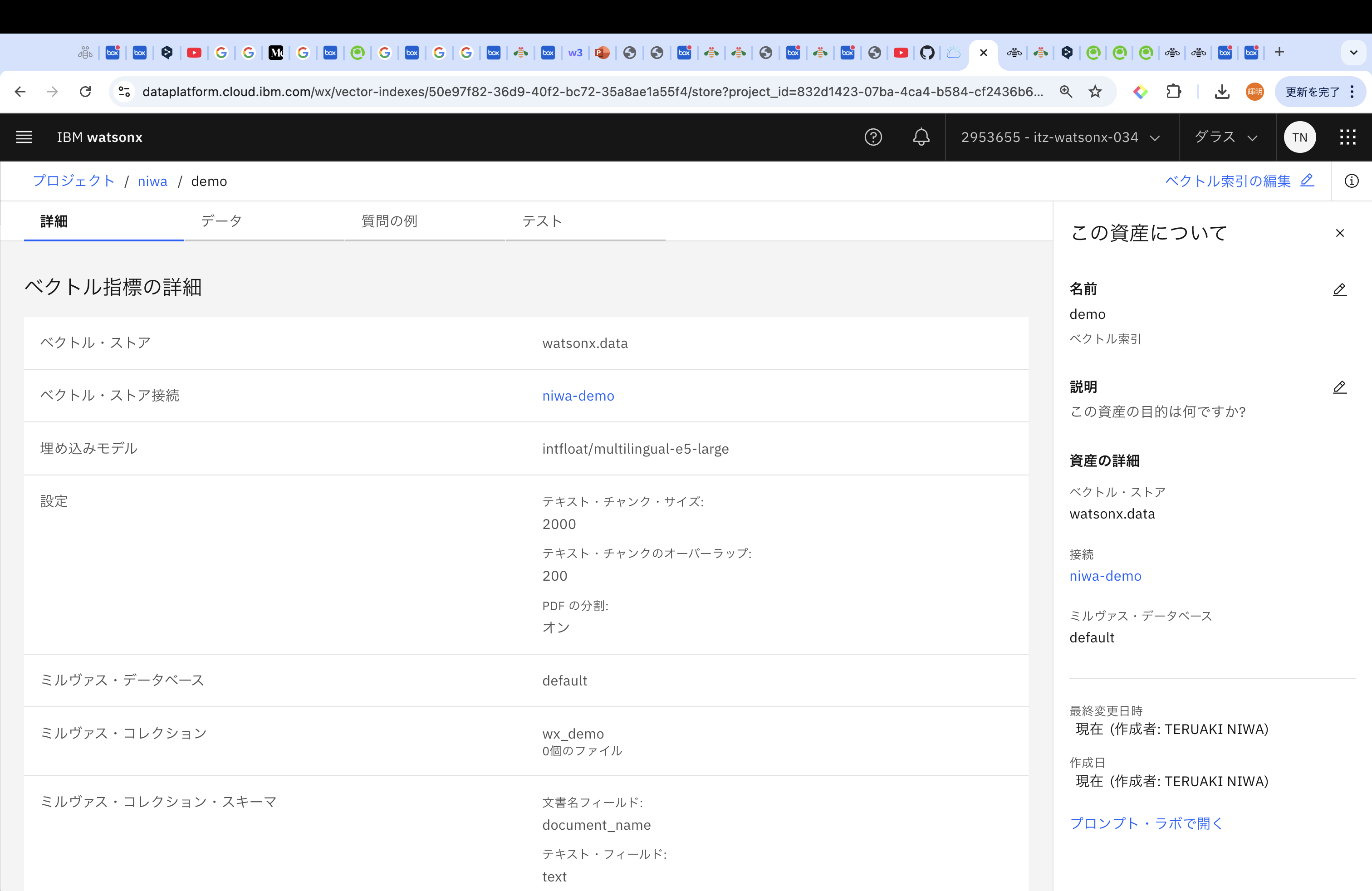
「データ」タブからはアップロードしたPDFのデータを、「質問の例」タブでは質問に対する回答を確認することができます。「質問の例」をいくつか試してみます。「サンプル質問の追加」を押して、気になる質問を記入してみてください。今回は、以下の質問で試してみます。
「新しく提供されたDb2のバージョンはいくつですか?」
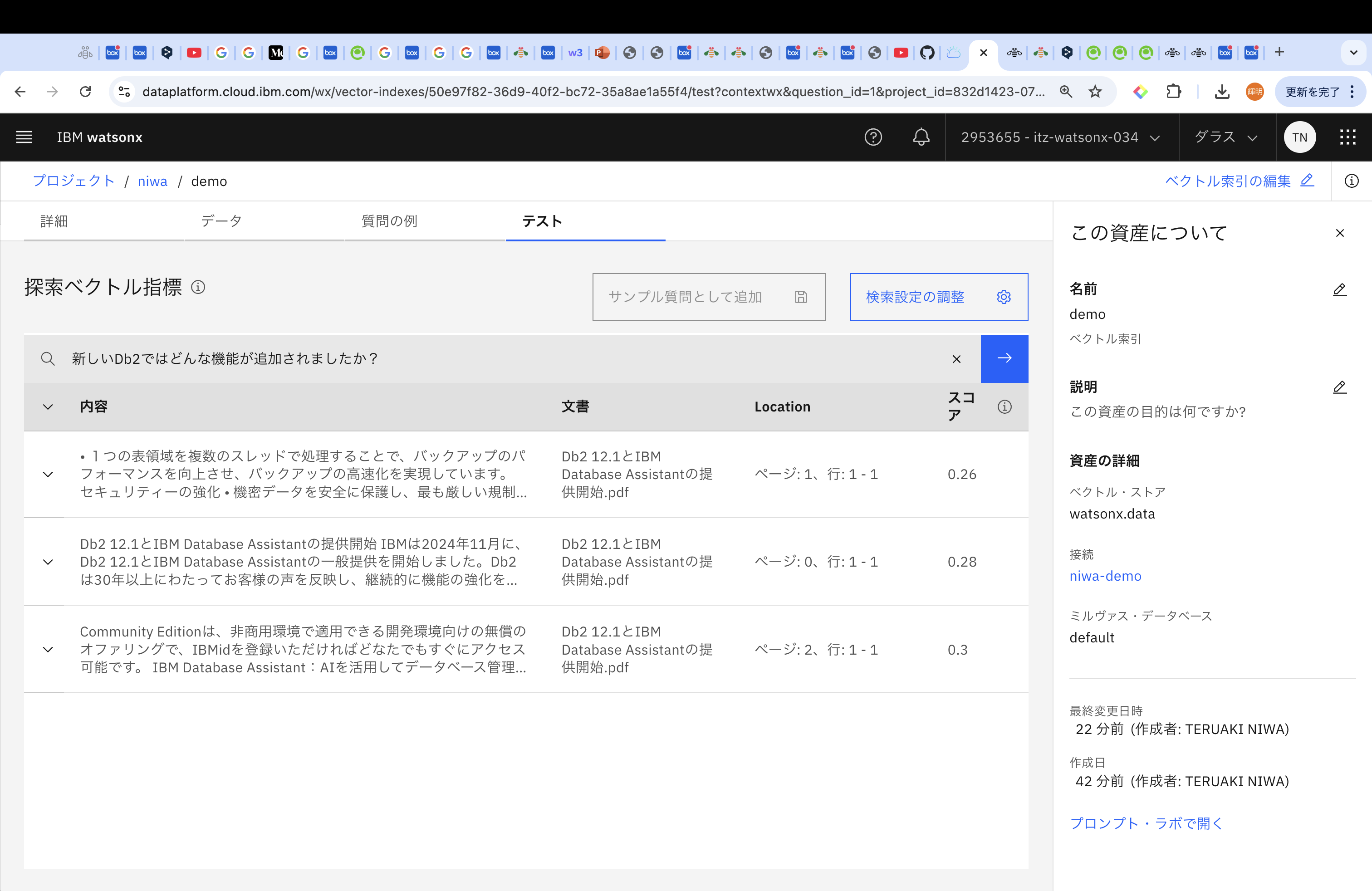
「新しいDb2ではどんな機能が追加されましたか?」
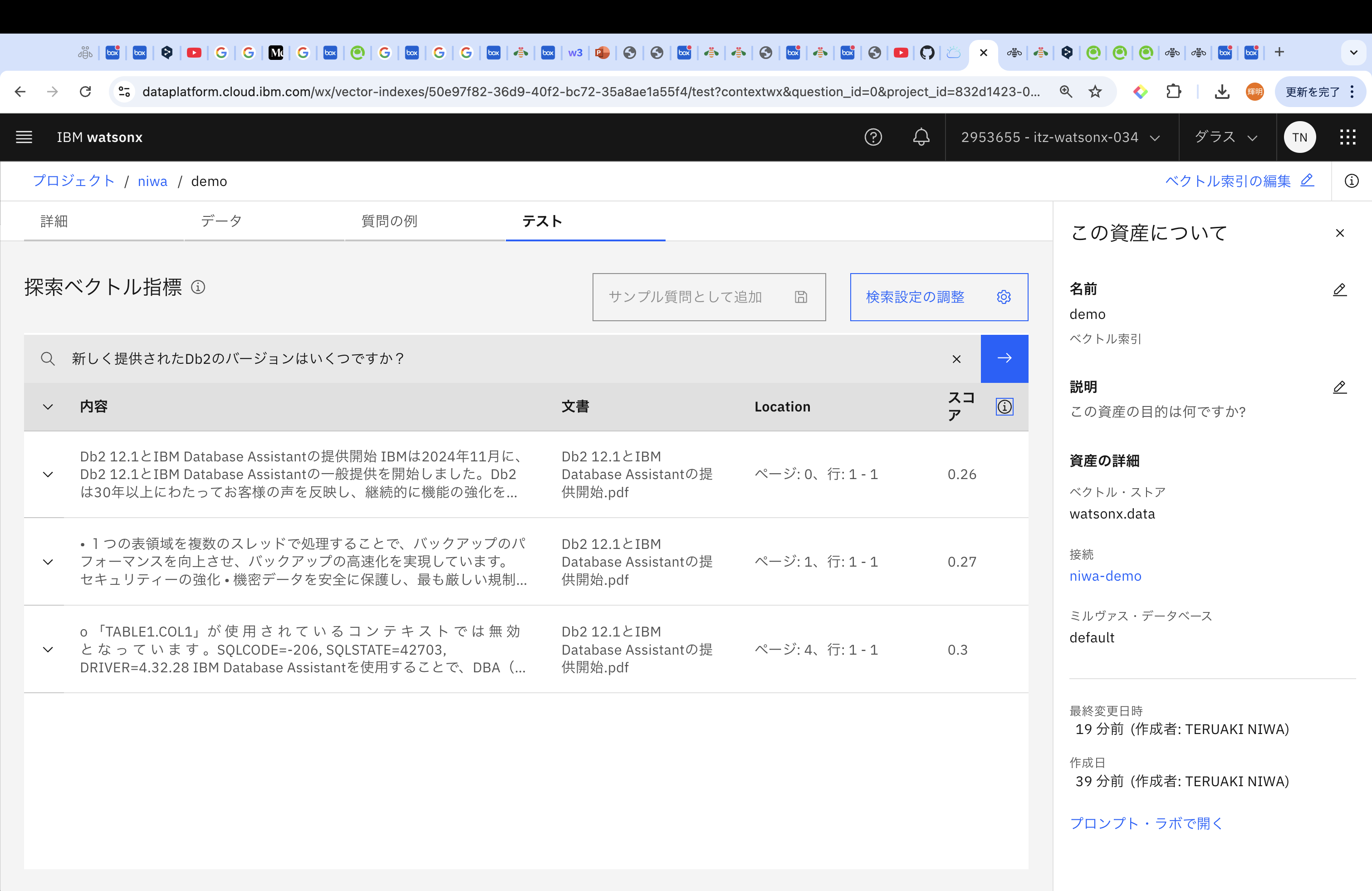
「新しく提供されたDb2のバージョンはいくつですか?」に対しての結果は以下のとおりです。
なお、スコアは、取得されたコンテンツが質問にどの程度類似しているか、を示しており、0に近いスコアは、文書コンテンツと質問の間の類似度が高いことを表します。
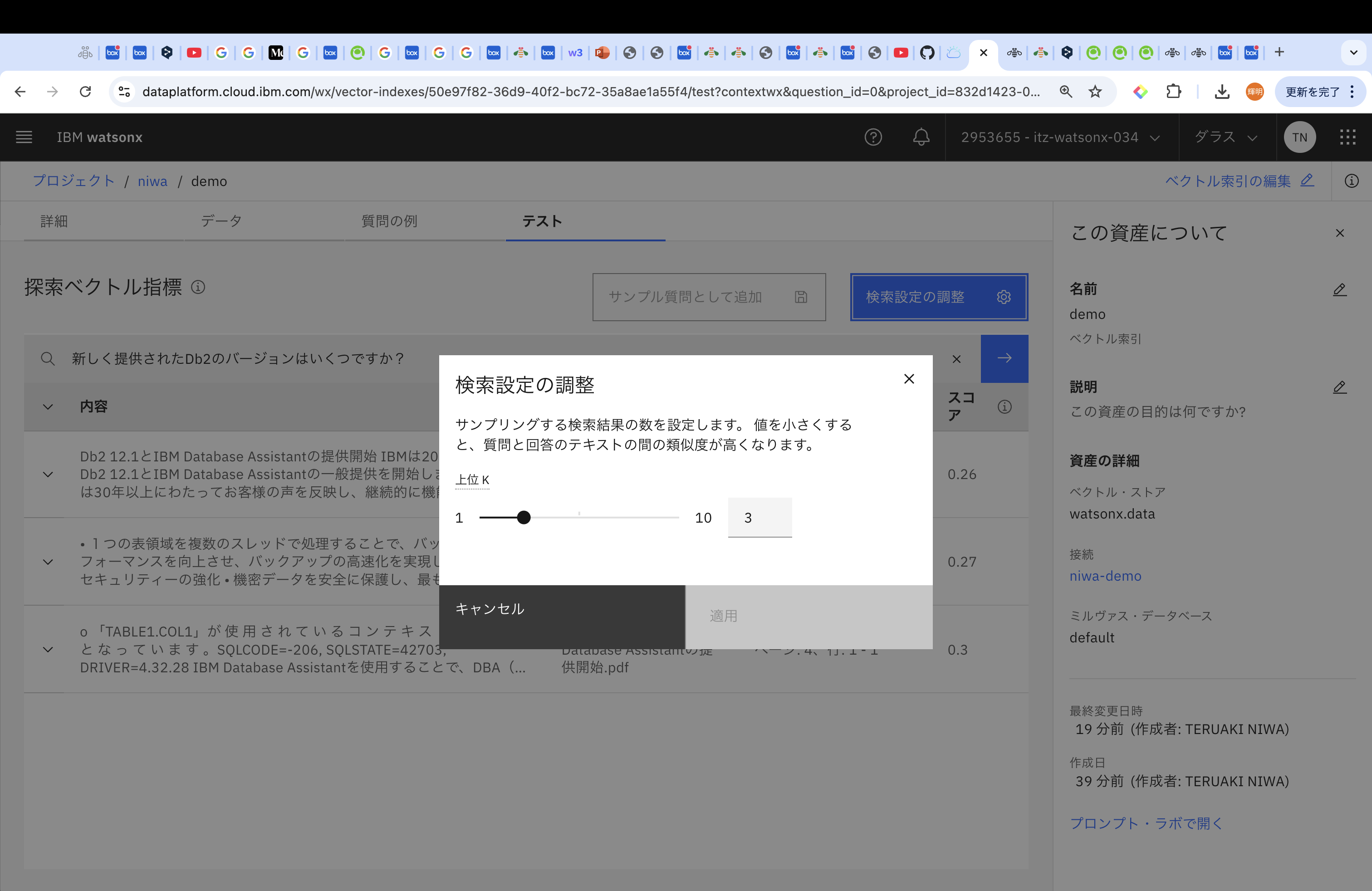
検索結果の数を調整することも可能です。
続いて、「新しいDb2ではどんな機能が追加されましたか?」を試してみます。
今回は1ページしか追加していないので、該当箇所が多くないため、上位kはデフォルトの3のままにしたいと思います。
チャンク・サイズを変えてみましょう。
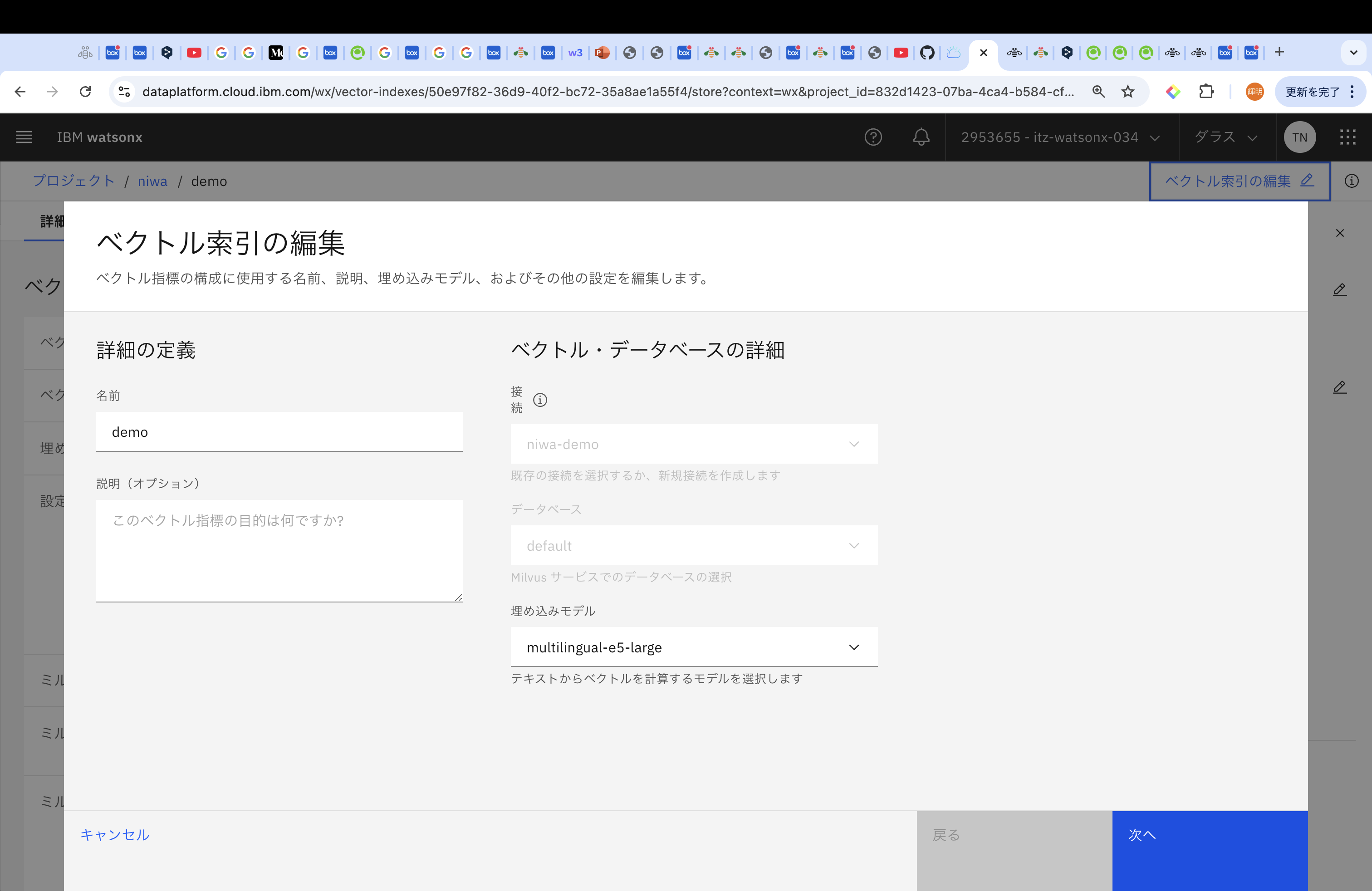
「詳細」タブの右上にある「ベクトル検索の編集」を選択し、「埋め込みモデル」の変更箇所はそのままで、「次へ」を選択し、「テキスト・チャンク・サイズ」を500、「テキスト・チャンクのオーバーラップ」を50に変更して実行してみます。
「質問の例」から「新しく提供されたDb2のバージョンはいくつですか?」についてテストを実行してみると、今回は上位3つのスコアが0.26、0.26、0.27になりました。チャンク・サイズが2000のときは、上位3つが、0.26、0.27、0.3だったので、改善されたことがわかります。
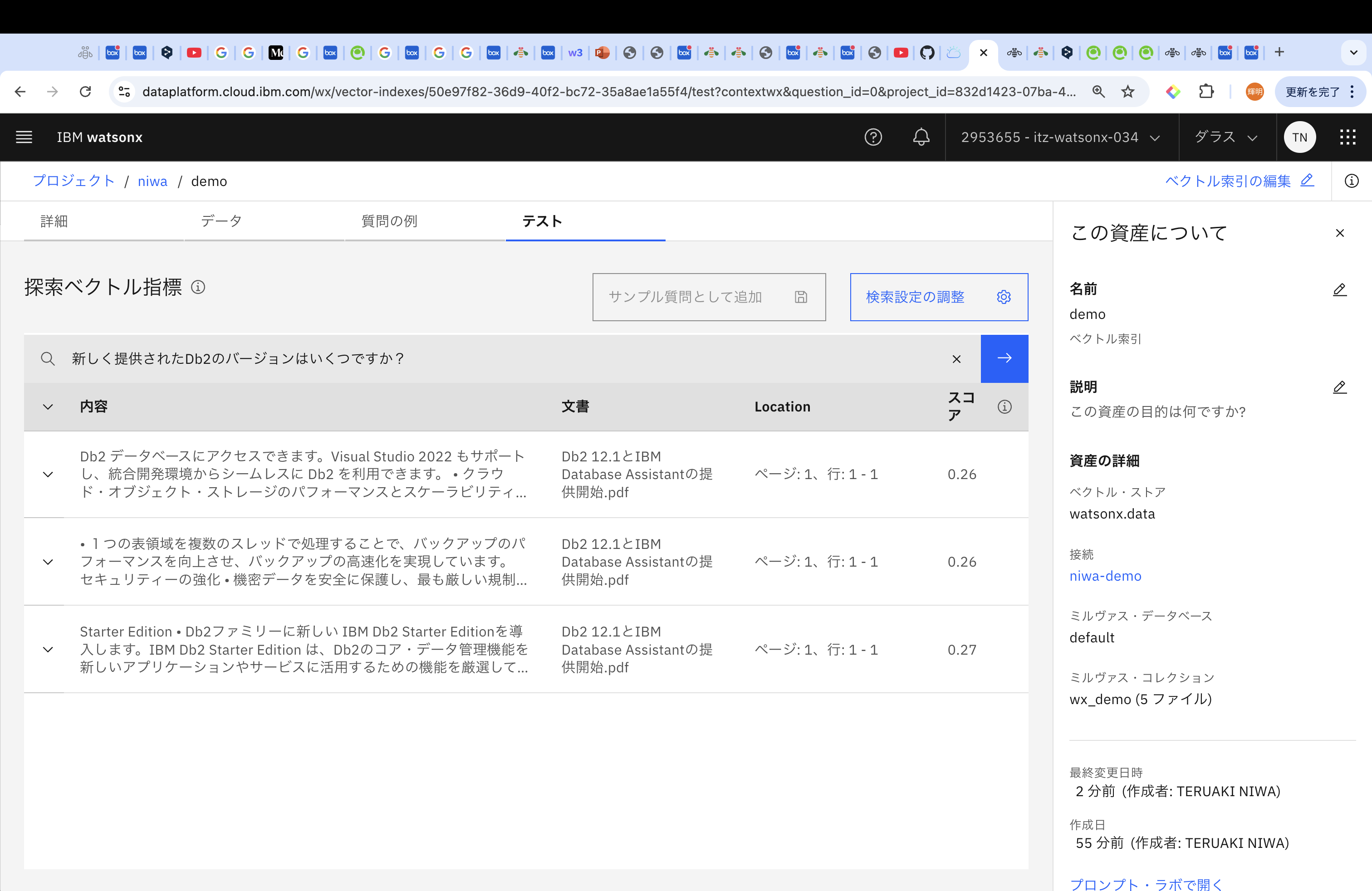
同様に、「新しいDb2ではどんな機能が追加されましたか?」についてテストを実行してみると、上位3つのスコアが、0.25、0.25、0.29となりました。チャンク・サイズが2000のときは、上位3つが、0.26、0.28、0.3だったので、改善されたことがわかります。
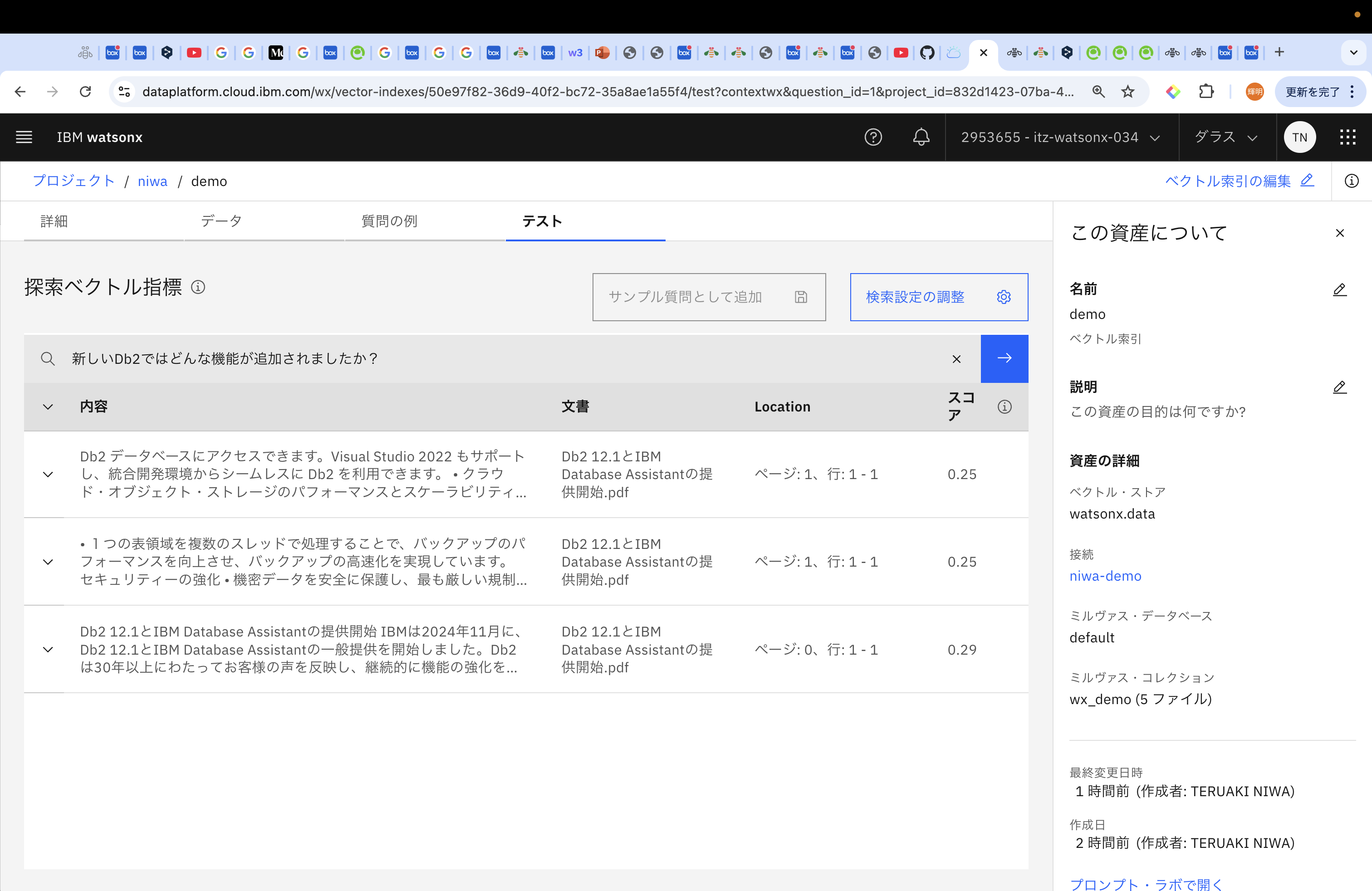
最適な結果を求めすぎると沼りそうな気がしたので、一旦こちらのチャンク・サイズ数で進めていきます。では、後半からは、実際に生成AIにこのTok3を返して文章を生成してみたいと思います。
LLMはモデルに応じて、文章の生成能力が異なるため、いくつか実際に試してみます。
では、右下の「プロンプト・ラボで開く」を選択して後半の記事に向かいましょう。
後半に続く