はじめに
初めまして、現在プログラミングスクールに在籍しているものです。
今回は成果物の1つとして、Signateのこちらのコンペに参加致しました。
このコンペの内容を簡単にお伝えしますと、説明変数(温度や曜日,メニュー名等)
から 目的変数(お弁当の売上数)を予測するものです。いわゆる教師有学習(回帰)です。
イメージとしてはscikit-learnのボストンの住宅価格予想をイメージして頂けると分かりやすいかも知れません。
初投稿故、駄文散文ご了承くださいませ。
コンセプト
今回Qiitaに挑戦した理由は下記のとおりです。
- 私のアウトプットや言語化の為。
- これからQiitaの記事を書く為のステップアップの練習。ライティングスキル向上の為。
以上、この記事を閲覧するだけで初心者の方も簡単に理解し実装して頂ける事を目標と致します。
丁寧に解説するつもりですので多少長くなります。
少しでも読みやすくと思い3つにパートを分ける予定です。
今回はデータ確認と特徴変換を中心として記入します。
開発環境
Jupyter lab ⇒少ないデータですが、今回の機械学習モデルは大幅な時間を要します。それ故google colabのように時間制限やサーバーに依存するものは推奨いたしません。
私の経験として、google colab無料版にて機械学習にかけた際に、2時間経過した後フリーズして泣きを見ました。その後Jupyter labにて一晩実行し提出しました。
- プロセッサ:Intel(R) Core(TM) i7-6600U CPU
- 実装RAM :16.0 GB
- システム :64 ビット オペレーティング システム、x64 ベース プロセッサ
- OS :Windows 11
今回使う、featuretoolsとtpotとは?
featuretools:
特徴量生成自動ツールです。使い方は②で説明致します。公式サイト
TPOT:
遺伝的プログラミングを用いて、機械学習モデルの選定やパラメータチューニングなどを自動で行ってくれる機械学習モデルです。公式サイト
実際にやってみる。
1.データのインポートと確認。
-
こちらからデータをダウンロードしてください。
ダウンロードした後は下記の手順に沿ってjupyter上で取り込み確認できるようにします。
①データインポート
import pandas as pd
train = pd.read_csv("C:/Users/user/Desktop/****/****/****/train(1).csv")
test = pd.read_csv("C:/Users/user/Desktop/****/****/****/test(2).csv")
・パスは最初から記入してください。C:~から。
・2022年現在はパスの区切りは「/」です。コピーした際、[]の場合は置き換えてください。
- データの確認。
trainとtestの相違点や情報等を確認します。説明変数(各特徴)に関しては
こちらをご参照ください。precipitationの"--"と"0"の違いがピンと来ませんが、そこまで意識するものでもございません。私見ですが。
①カラム確認。
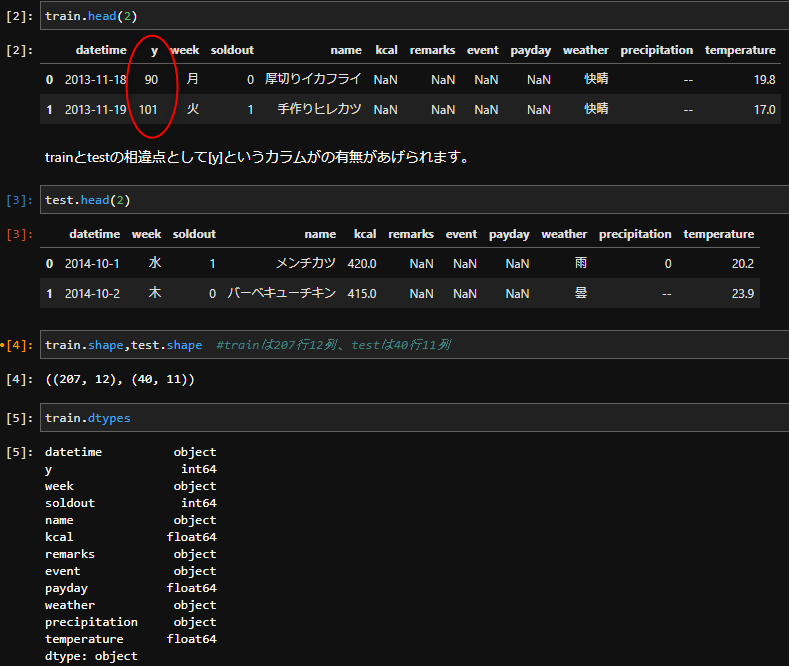
train.head(2) #trainのカラム確認
test.head(2) #testのカラム確認
train.shape,test.shape #train/testの何行何列かの確認。
train.dtypes #dfの型を確認。列情報、整数(int)なのか,objectなのか。
こちらが上記コードの情報です。
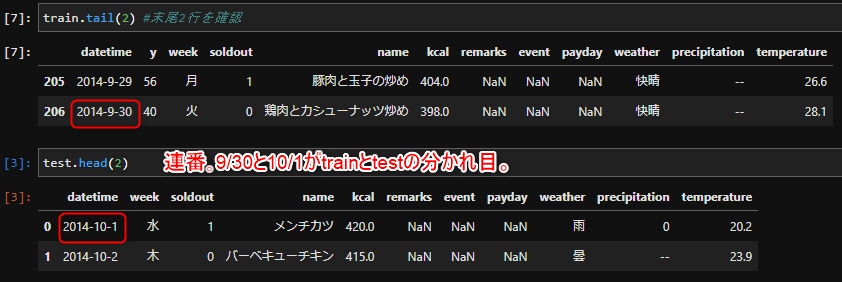
更にdatetimeに着目してみましょう。train.tail(2)を見てみたところ、testの冒頭と繋がっている事がわかります。
- データの統合
上記を踏まえ、trainとtestのデータを統合して一括処理できるようにしましょう。
データの特徴把握や、整形をする際にtrainとtestを結合して1つのデータとします。
その方が一度のコードで済みますので2度手間になりません。
勿論1行1行にtrainとtestが判別できる処理は施します。これが下記の[flg]です。
#各々の行がtrainかtestか区別するためにflgを付与します。
train['flg'] = 1 #trainデータはflg 1。
test['flg'] = 0 #testデータはflg 0。
# trainデータとtestデータを結合
datas = pd.concat([train,test], axis=0, sort=False)
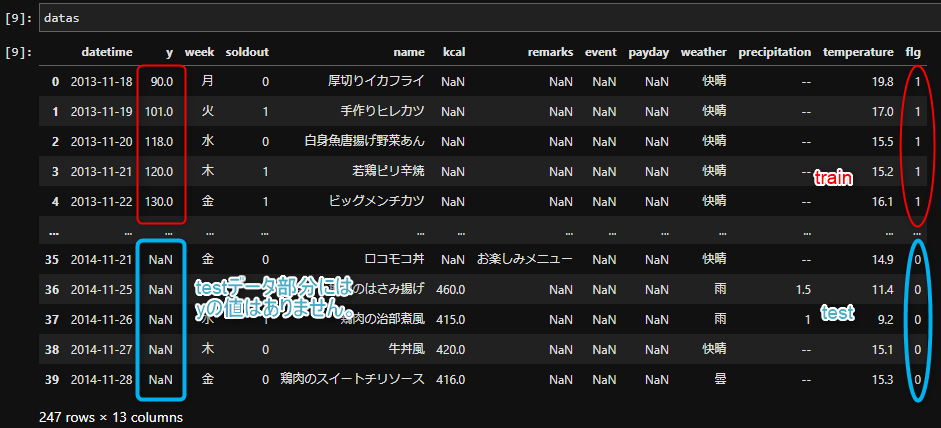
これでtrainとtestが合体したデータフレーム、dataが完成しました。確認してみましょう。
前半のflg=1 がtrain部分で、後半のflg =0 がtest部分です。
②トレンドの確認と対処
以上を鑑みてこの図のようにyの値を予測しましょう。
まずはデータを確認します。
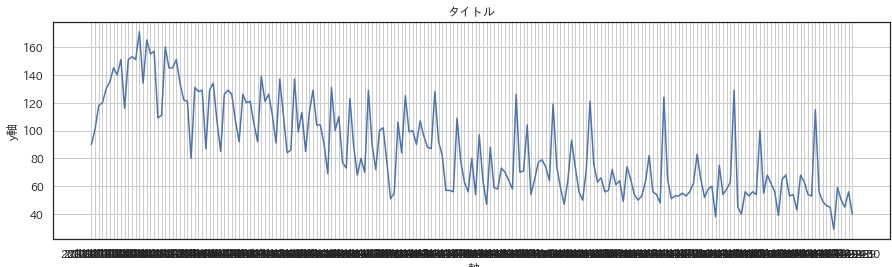
ここで着目して頂きたいポイントとして、前半と後半では傾向が異なるという点です。
私の場合、思い切って前半をまるっとカットしまいました。
カットする際の塩梅ですが、私の場合は2014年の4月一杯までの部分をカットしました。根拠は目視で5月から傾向が変わっていると感じたので。
datas = datas.loc[106:,]
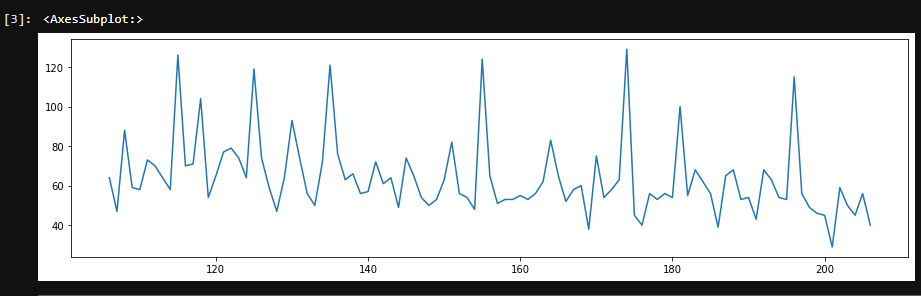
これがその結果です。
- ①のまとめ
import pandas as pd
train = pd.read_csv("C:/Users/user/Desktop/****/****/****/train (1).csv")
test = pd.read_csv("C:/Users/user/Desktop/Jupyter/lab/成果物/test (2).csv")
# フラグを立てる⇒trainとtestの区別。
train['flg'] = 1
test['flg'] = 0
# trainデータとtestデータを結合
datas = pd.concat([train,test], axis=0, sort=False)
datas = datas.loc[106:,]
2.データ前処理
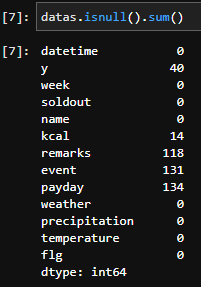
まずは前処理するデータの確認。最初のステップとして欠損値を確認します。
datas.isnull().sum() #データの欠損値を確認。
いくつか欠損地が見当たりますね。まずはこの欠損値を埋めましょう。
①欠損値穴埋め
- まずはpaydayの要素を確認してみましょう。
datas["payday"].value_counts()
# 結果
# 1.0 7
# Name: payday, dtype: int64
なるほど、1.0が7つあり他はNaNみたいですね。
そもそも1.0は何を表すのでしょうか?確認してみましょう。
再度カラム説明で確認しますと、
payday | boolean | 給料日フラグ(1:給料日)
どうやら1.0は給料日のようです。それならば、対になるように給料日ではない日、つまりNanを[0]
で埋めましょう。
- eventはいかがでしょうか。
datas["event"].value_counts()
#ママの会 5
#キャリアアップ支援セミナー 5
#Name: event, dtype: int64
どうやらイベントがある日にそのイベント名が入力されているみたいです。
それならば、NaNはイベント無しと考えて良さそうです。イベント無しなのでそのまま「なし」で埋めましょう。
- remarksも同様に確認します。
datas["remarks"].value_counts()
#結果
#お楽しみメニュー 13
#料理長のこだわりメニュー 7
#手作りの味 1
#スペシャルメニュー(800円) 1
#近隣に飲食店複合ビルオープン 1
Name: remarks, dtype: int64
eventと同じ記載方法のようです。それならば同様に「なし」で補完します。
datas.info() #データの型やカラム数、欠損値を確認。
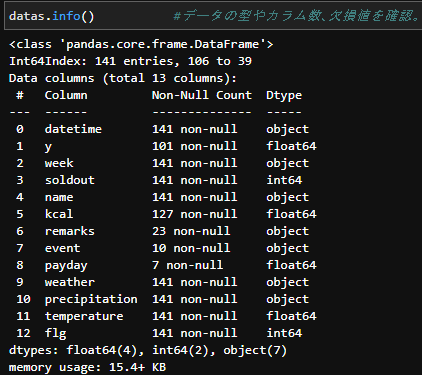
上記を踏まえたうえで欠損地をこのように補います。
#給料
datas['payday'] = datas['payday'].fillna(0) #欠損値を0で埋めます。
#イベント
datas['event'] = datas['event'].fillna('なし') #欠損値をなしで埋めます。
#remarks
datas["remarks"] = datas["remarks"].fillna('なし') #欠損値をなしで埋めます。
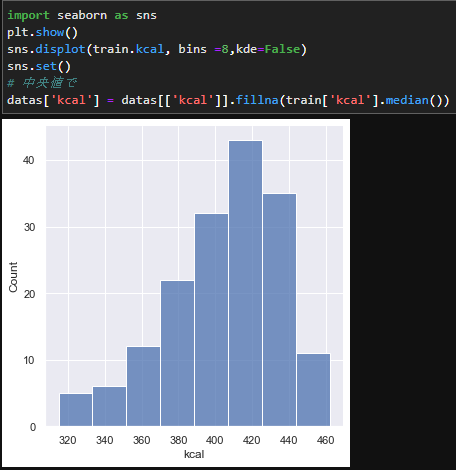
kcalの欠損値補完については平均値や中央値を用いましょう。
今回はグラフで可視化した際に、少し頂点が右にズレているので中央値で補完します。
# kcalの欠損値補完について
import seaborn as sns
plt.show()
sns.displot(train.kcal, bins =8,kde=False)
sns.set()
train['kcal'] = train[['kcal']].fillna(train['kcal'].median())
イメージはこちら。
- それではこれで、すべての欠損値が補完できたはずです。確認してみましょう。
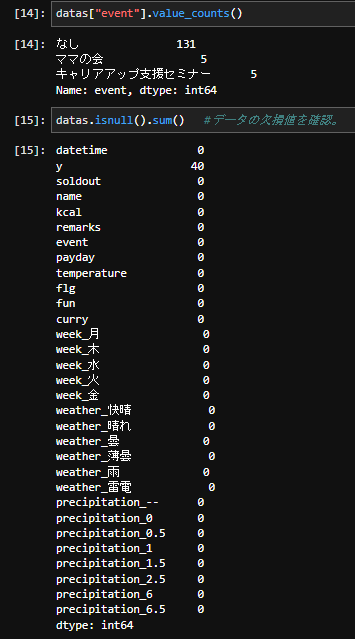
eventには「なし」というカテゴリが追加され…、他欠損値もtestのy(40)以外埋まってますね。
因みにこれはこの値を予測するのが目標ですので、そのままNaNで問題ありません。むしろ前処理で補完したらいけません。
②特徴量生成
- remarksの要素内容を確認してみましょう。
datas["remarks"].value_counts()
<a id="anchor1"></a>
'''
結果
お楽しみメニュー 13
料理長のこだわりメニュー 7
手作りの味 1
スペシャルメニュー(800円) 1
近隣に飲食店複合ビルオープン 1
Name: remarks, dtype: int64
'''
remarksの中にも様々な項目がある事がわかりますね。それぞれの項目の違いについてみてみましょう。
まずは必要なmodule import。これにより日本語で表示することができます。
!pip install japanize-matplotlib #日本語モジュールインポート
import japanize_matplotlib #そのモジュールをセット。
import matplotlib.pyplot as plt
import seaborn as sns
それぞれの項目を箱ひげ図にて確認しましょう。
- 欠損値処理されたもの かつ,yの値のあるものからデータを見てみましょう。
つまり、欠損値処理が済んだtrainデータのことです。
df_train = datas[datas['flg']==1]
このように抽出することができます。datasのflgが1の部分を抜き出して df_trainという変数に格納しています。
fig, ax = plt.subplots(2,2,figsize=(12,7))
sns.boxplot(x="week",y="y", data =df_train,ax=ax[0][0])
sns.boxplot(x="weather",y="y", data =df_train,ax=ax[0][1])
sns.boxplot(x="remarks",y="y", data =df_train,ax=ax[1][0])
sns.boxplot(x="event",y="y", data =df_train,ax=ax[1][1])
plt.tight_layout()
意味としては、data =df_trainで適用するdataを指定します。今回はdf_trainです。
df_trainの中から、xとyを指定します。一番下の例ですと、
sns.boxplot(x="event",y="y", data =df_train,ax=ax[1][1])
x⇒df_trainの"event"。y⇒df_trainの"event"という意味です。
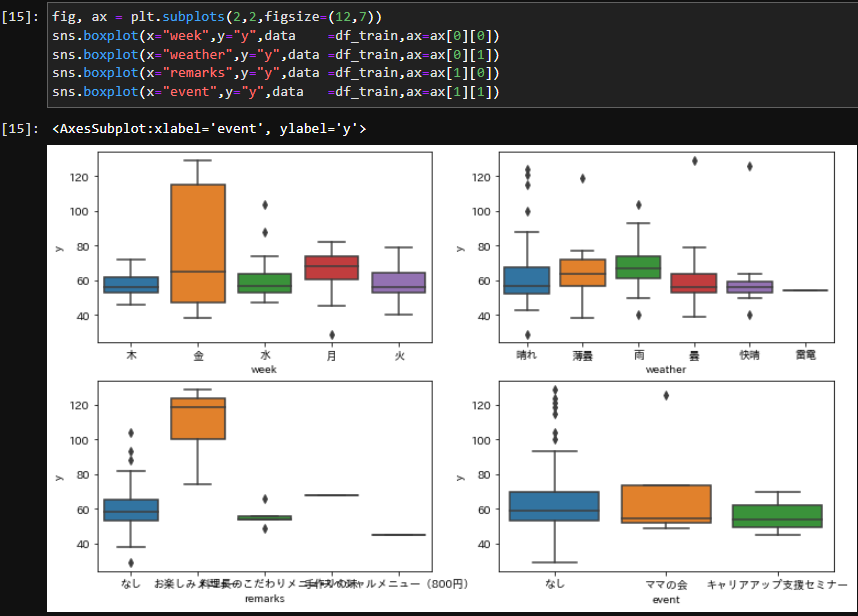
分かったこと。
- お楽しみメニューの際に売上数が多い。
なのでお楽しみメニューの時は1、そうでないときは0のカラムを作成しましょう。
datas['fun'] = datas['remarks'].apply(lambda x : 1 if x.find("fun") >=0 else 0)
lambda式の復習です。
・1行づつremarksの要素がxに格納され、その度に「お楽しみメニュー」かそうでないかを場合分けしています。「お楽しみメニュー」であれば1,そうでなければ0と。
その内容を新しいカラム名["fun"]に格納しています。
-
eventは特に意味はない。
-
"name"の中からも何か特徴量を作成できないか検討してみましょう。
同じように"name"の情報を見てみます。それでは上記通り、箱ひげ図で確認しますと、
sns.boxplot(x="name",y="y", data =df_train)
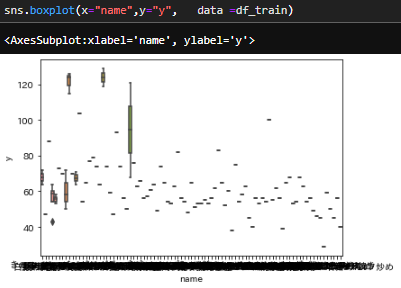
このように文字が潰れて確認できません。この場合では下記のような箱ひげ図で確認してください。
詳しい説明は省きますが、jupyterとgoogle colabではコピペして頂けると表示されます。
import plotly
import plotly.graph_objs as go
# Google Colab. やJupyter Lab.でプロットするためには,以下を実行する.
import plotly.io as pio
pio.renderers.default = "colab"
plotly.__version__
import plotly.offline as offline
layout = go.Layout(
autosize=False,
width=950,
height=500,
margin=go.layout.Margin(
l=80,
r=50,
b=50,
t=10,
pad=4),
xaxis=dict(
title='menu',
titlefont=dict(
size=14,
),
showticklabels=True,
tickangle=0,
tickfont=dict(
size=12,
),
),
yaxis=dict(
title='販売数(y)',
titlefont=dict(
size=14,
),
showticklabels=True,
tickfont=dict(
size=10,
),
))
data = [go.Box( x=df_train['name'], y=df_train['y'] )]
fig = go.Figure(data=data, layout=layout)
offline.iplot(fig, filename='example', show_link=False,
config={"displaylogo":False, "modeBarButtonsToRemove":["sendDataToCloud"]})
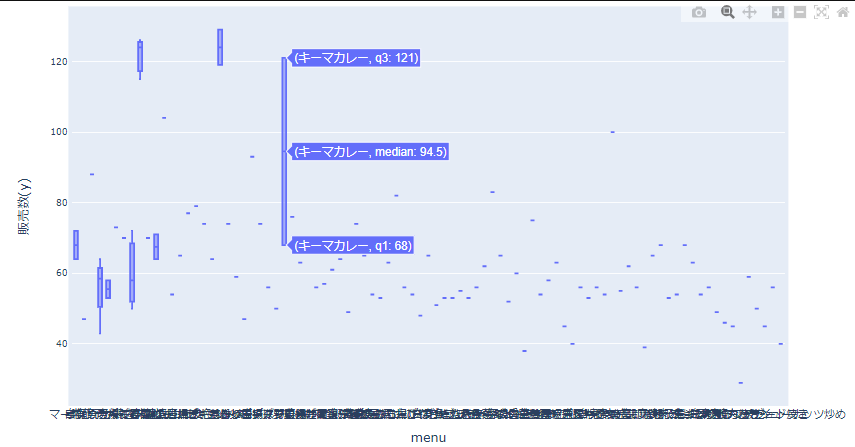
このようにメニュー名とyの相関関係を見てみると、カレーが人気メニューのように見えます。
カレーの日は売上が伸びるのですね。なのでメニューに「カレー」が含まれる場合に1、そうでないときは0のカラムを作成しましょう。
datas['curry'] = datas['name'].apply(lambda x : 1 if x.find("カレー") >=0 else 0)
カラム["fun"]と基本的構造は同じで、["name"]からの要素を1行づつ、取り出し、「カレー」という文字列が含まれているかどうかを確認しています。
③One-Hot Encoding
one_hot_columns = ['week','weather',"precipitation"]#encordingしたい要素達。
datas = pd.get_dummies(datas, dummy_na=False, columns=one_hot_columns)
- One-Hot Encoding
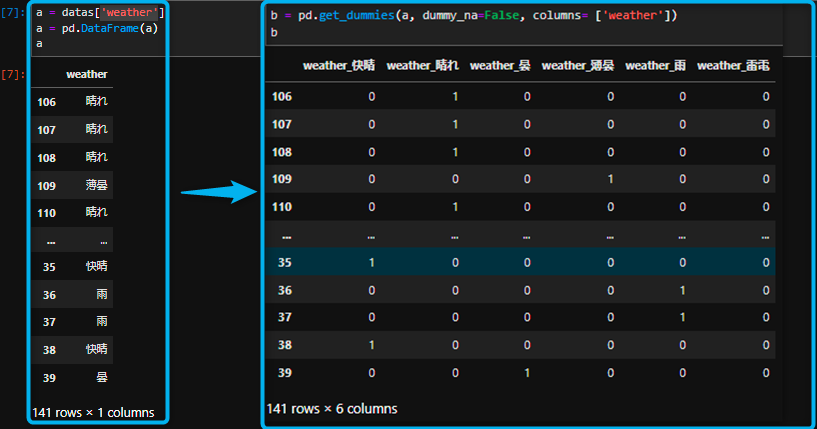
各変数に対して該当するカテゴリかどうかを0,1で表現したベクトルに変換する処理のことです。
例えば天気が「晴れ、曇り、雨」という3つのカテゴリをもつ変数があるとすれば、
その変数に対してOne-hot encodingを行うと晴れ?曇り?雨?という3つの特徴量が作成され、 該当部分に1がつき、その他は0になります。図で可視化するとより理解して頂けると思います。
- ②のまとめ
#給料
datas['payday'] = datas['payday'].fillna(0)
#イベント
datas['event'] = datas['event'].fillna('なし')
#remarks
datas["remarks"] = datas["remarks"].fillna('なし')
datas['fun'] = datas['remarks'].apply(lambda x : 1 if x.find("fun") >=0 else 0)
datas['curry'] = datas['name'].apply(lambda x : 1 if x.find("カレー") >=0 else 0)
one_hot_columns = ['week','weather',"precipitation"]#encordingしたい要素達。
datas = pd.get_dummies(datas, dummy_na=False, columns=one_hot_columns)

いかがでしょうか?次回はfeaturetoolsを用いてさらに特徴量を増やしていきたいと思います。
ここまで確認できましたら、次のステップに行きましょう。