この頃増えているMLP系構造の画像認識向けネットワークで、とうとう空間方向にConvもAttentionもMLPもしない論文が出てきたので、まとめる。
追記(2022/10/4):
気付いてないだけで、MLP系以外でもシフトはいろいろと合った・・・。
そもそもConvの時代に、ResNetのConvをシフトでやれば軽いという最初の論文
Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions(2018 CVPR)
とはいえ、シフトで動かしまくるとmemory footprintがやばいってのから、派生して
TSM: Temporal Shift Module for Efficient Video Understanding(2019 ICCV)
どれだけどこにシフトするかも学習させちゃえ(active shift)って派生
Constructing Fast Network through Deconstruction of Convolution(2019 NeurIPS)
シフトするのは、全チャンネルじゃなくてちょっとで良い(Sprse shift)という派生
All You Need is a Few Shifts: Designing Efficient Convolutional Neural Networks for Image Classification(2019 CVPR)
で、こっちの流れからViTにシフトをいれたやつ
When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism(2022 arXiv)
なんなら昔バズったLocal Binary CNNも、この一部
Filterの方は、LBP encodingと言ってセンターが‐1で、それ以外が0と1のみの学習をしないConvフィルターを使い、その後で普通の1x1Conv
Local binary convolutional neural networks(2017 CVPR)
つかそもそも、フィルターは1か‐1でランダムで良くね? って、ことで同じ人たちが、学習なしbinaryフィルターを全体にかけて、その後で普通の1x1Conv
Perturbative neural networks(2018 CVPR)
そもそも、Weightを1と‐1にしたいのは、入力のピクセルが$x_i$で、そのWeightが$b_i=\{1, -1\}$の場合
- $A= \sum_{b_i = 1} x_i$
- $N = \sum_{i} x_i$
- $\sum_{i} b_i x_i = 2A-N$
が使えて、ANDとシフトオペレーションで済むから。
更に言うと、この方法を使えば、入力$x_i$に対して、フィルターの値が$y_i$なら、以下のbinary approximation手法が使える
- $y_i = s^1 b_i^1 + d_i$ 全体を$s$でスケールする
- $y_i = (\sum_j^n s^j b_i^j) + d_i^n$ 大きい値からスケールすることで、あまりの$d$が小さくなる
- $\sum_{i} b_i x_i = (\sum_j^n s^j (\sum_i b_i^j x_i)) + \sum_i d_i^n x_i$
MLP系ネットワークってなんぞという人は、こちらから。
画像向けMLP系初期ネットワーク構造まとめ
2021年の6月と7月の基本同時期、Arxivに、以下の3本の論文が中国から出ている。
- S2-MLP: Spatial-Shift MLP Architecture for Vision
- AS-MLP: An Axial Shifted MLP Architecture for Vision
- CycleMLP: A MLP-like Architecture for Dense Prediction
今までの(と、言っても2021年5月に始まったばっかだけど)MLP系は、TokenとChannelをバラバラに混ぜていたけれど、ここでは、Tokenは混ぜない。Channelで混ぜるときに、Channelごとに同じTokenを混ぜるのではなく、ちょっとずらして混ぜる。Tokenを混ぜるときに、ちょっとずらす(Shiftする)だけでOKというのが基本的なアイディア。
S2-MLPについて
一応(ほぼほぼ同時期だけど)、一番最初に出たBaiduの論文。
図が一目瞭然でわかりやすい!
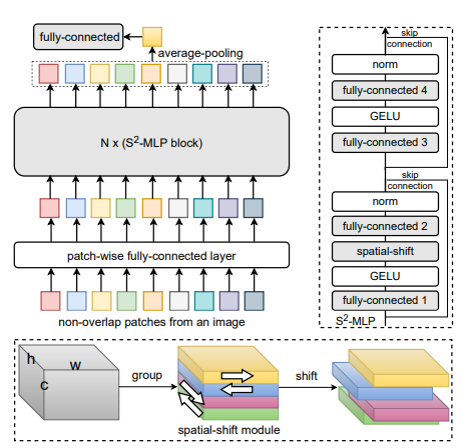
基本的にMLP-mixerの形状をしているが、fully-connectedは全てChannelの方向で行う。
spatial-shiftは、下の図にあるように、チャンネル方向に4つのグループに分けして1 token違う方向にShiftするだけ。動かさないってのはないらしい。考え方としては、Depthwise Convで一つの方向から1を取り、残りが0というKernelを使うのと同義で、空間方向ではConvと同じで、全ての場所で同じLocalな(小さい)Kernelが使われる。
Channel方向では、MLP-mixerは、全て同じ空間カーネルが使われ、Depthwise Convは全て違う空間カーネルが使われるが、S2-MLPではグループごとに同じShiftになる。
こんな感じで、パーツごとに何が重要かを分類し、別のMLP系のネットワークを構築し、同じチームが2週間後にArxivに乗せている。その名も
Rethinking Token-Mixing MLP for MLP-based Vision Backbone
いろいろと速い・・・。
こっちでは、 Circulant Channel-Specific(CCS)というのを提案していて、MLP-mixer系、Depthwise Conv系、上のS2と比較したのが、以下。

CCSの方は、Token MixingをChannel方向に回転させて、計算をFFTで行う。とはいえ、パッチの数が小さいときは、速さの恩恵は受けられないとのこと。
S2-MLPの方に戻って、こっちは空間方向の計算がないので、軽い! これで、他のMLP系と比較すると同規模でImageNet-1Kの精度が上がっている。
Shiftの方向に関しては、ImageNet100でAblation studyをしている。
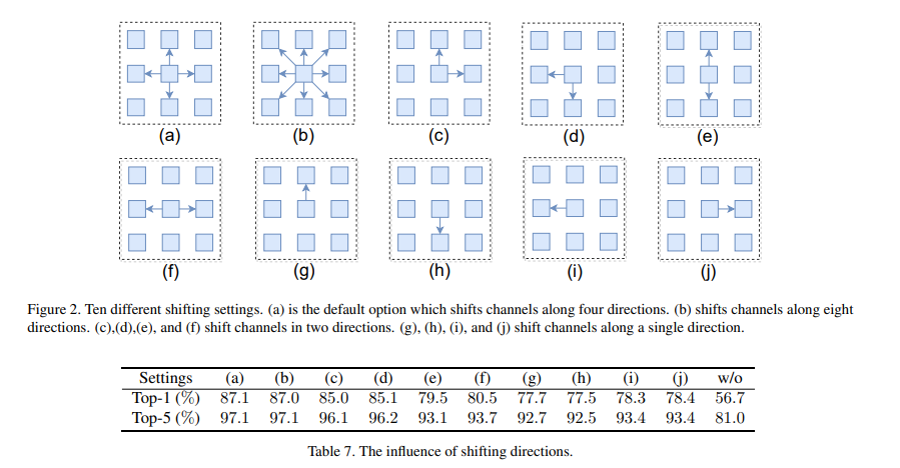
ということで、左右と上下のみがちょうど良さそう。
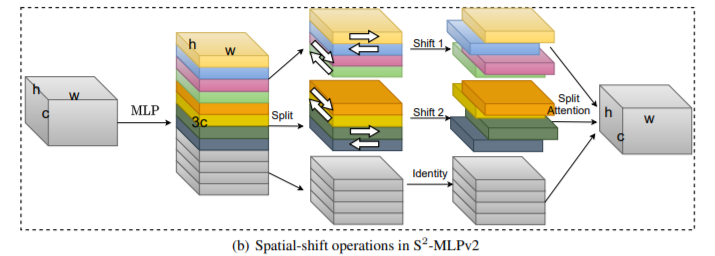
こいつ、8月には、Version 2が出てまして、
S2-MLPv2: Improved Spatial-Shift MLP Architecture for Vision
以下二つにあるようなピラミッドとsplit attentionぽくすると(以下図)self-attentionなしでSOTAとのこと。
AS-MLPについて
基本的には、上の構造と同じだが、Shiftをまとめてやらずに、縦Shiftと横Shiftにわけて組み合わせる。
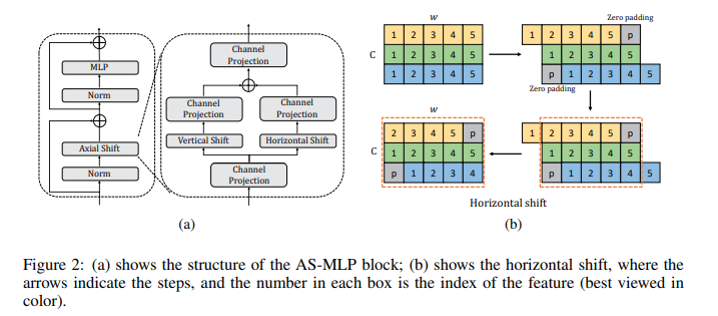
どうも、バラバラにやって足し合わせる方が、順番にやって行くより精度が良かったらしい。
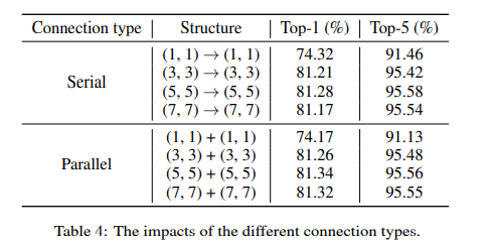
こちらは、以下のように縦横Shiftのみだが、いろいろなサイズや、穴あき版(Dilation)なども調べている。
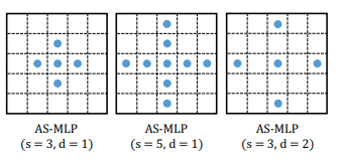
Shift size (1, 1)というのは、Channel-mixingのみと同じになる。
また、Shiftすることで出来る空間のPaddingもいろいろと試している。
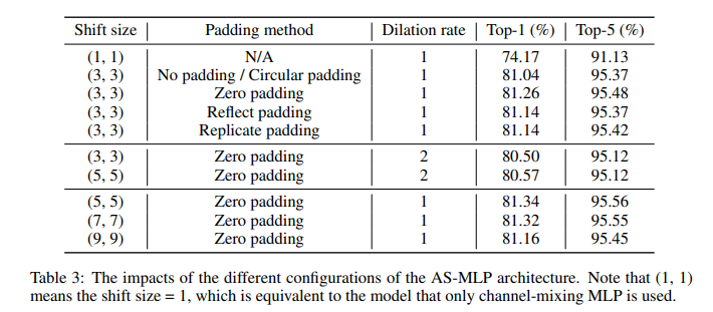
S2-MLPと同じように、1 tokenシフトするだけで、十分良い結果が出ている。
AS-MLPでは、オリジナルのMLP系と違い、ピラミッド構造を使用していろいろな絵のサイズに対応できるようにしてある。ImageNet-1Kにおいては、同規模で、他のMLP系より良く、Transformer系と同程度になった。また、ピラミッド構造により、COCOのObject detectionや、ADE20KのSemantic segmentationにも対応できるようなり、Transformer系と同程度の精度が出せるようになった。
CycleMLPについて
S2-MLPとほぼ同じ構造で、AS-MLPと同じようにピラミッドが入っている。AS-MLPの3日後にArxivに入っていて、結果はImageNetで同等、COCOとADE20Kで、AS-MLPかな。ともあれ、MLP系でもObject detectionとSemantic segmentationに適用可ということが示され、また新たな戦いがここから始まる。
というか、この競争の激しさは、いったい何なのかと。
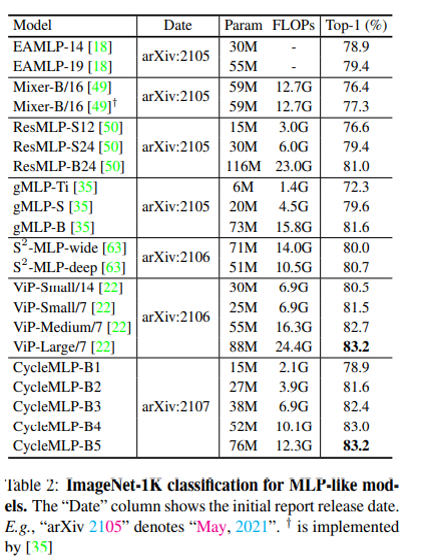
とうとう、出版月まで書き始めているのに、すでに3日提出が遅れて負けるという・・・。
まとめ
ということで、あれだけ重要だと思われていた空間上の計算もシフトすればOKという衝撃的な内容が同時期に3本。
組み込み系では、ゲームチェンジャーになるかもしれないし、組み込まない人には割とどうでも良い結果かもしれない。