画像認識分野は、あれだけブイブイ言わせていたTransformerも、いつの間にやらMLP系に食われ気味で、諸行無常を1年間で感じられる恐ろしさ。
さて、そのMLP系ですが、同時期に3本出たので、その構造をまとめてみたい。
全部、2021年の5月にArxivに入っているというのが、人類の発展は同時進行的なんだろなという感じ。
- MLP-Mixer: An all-MLP Architecture for Vision
GoogleのViTチーム
- gMLP: Pay Attention to MLPs
Googleの別チーム。NLPにフォーカス。
- ResMLP: Feedforward networks for image classification with data-efficient training
ViTに良いRegularizationを入れることで学習が進み、disttilationも出来るようにしたDeiTを出したFAIRのチーム
同じく2021年5月に同じ現象を発見して、報告するメモも出ている。
- Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
ViT構造のおさらい
Transformerを画像認識に導入して人気が出た構造を確認。
1年くらい画像認識分野から離れていて、あれ、Convどうした? って人は、以下の記事でも見てください。
画像認識向けTransformerを振り返る
Transformerで、画像のTokenを混ぜる部分。

Channelを混ぜる部分。

Drop OutとDrop Pathは省略。
Linear(c)は、Channel方向にするLinear operation。2回続くとMLPと良く言われる。ViT界隈ではFFNとも呼ばれる。
2回続ける場合は、間を大きくするので、その量を調整するハイパーパラメータがいる。
Tokenを混ぜる方のLinear(c)はAttention構造で言うところのV, Q, Kを作っているところ。
MLP-Mixerの構造
元々ViTから来ているチームなので、ストレートにTokenを混ぜる部分のみ変更。

Linear(t)は、Token方向にするLinear operation。2回続いているので、MLP。
いたってシンプルながら、大きいNetworkで大きいDataを使えば、良いRegularizationでSOTAに遜色ない。
このネットワークのすごいところは、全てLinearの計算なので、ただの行列の掛け算になり、計算手法はいたって簡単!
ResMLPの構造
このチームは、学習のRegularizationを良くするDeiTと、ネットワークをスケールするためのCaiTを出してくれたところで、
Gitに全ての実装をPyTorchで公開してくれている。
CaiTの方の論文「Going deeper with Image Transformers」で導入したLayerScaleを更に一般化し、ElementごとにrescaleしてshiftするAffine Transformationのみで、とうとうNormalizationフリーを達成している。以下の図ではAffで表している。
ResMLPで画像のTokenを混ぜる部分。

NormalizationがAffに変わり、Channelの方向に混ぜる部分がない。
Channelを混ぜる部分。

元のと、Normalizationが変わったのみ。
こっちは、ImageNetのみで学習して、ずいぶん良い結果になっている。ただし、学習手法は、最新手法必須。昔のResNetの学習手法からDeiTの学習手法に変えただけで7.4%精度が良くなった。
また、この論文では、いろんなablation studyをやっていておもしろい。
Normalizationフリーって言ってるわけで、それの実験結果。
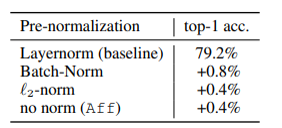
当然ながら、Affine Transformが一番簡単なので、実際の実験では、Affを用いている。
Tokenを混ぜている部分を別のConvなどに変えてみた結果。

depthwise-separableは3x3 depth-wiseと1x1 Convの組み合わせ。
オリジナルよりConvの方が良いけれど、計算量が大きい。
MLP-mixerと同じように、Token方向にもGELUをはさんだLinearを2回やるMLPも試している。中間は4倍。この論文では、シンプルなResMLPの方がaccuracy/performanceのtrade-offが良いと結論付けている。
さらに、NLPの方でもseq2seq Transformerとcompetitiveな精度が出ているらしい。
gMLPの構造
こちらは、メインがNLP向けで、Transformer並にうまく行くタスクも多いと言っている。
Vision Transformerが良く出来ていた理由はself-attentionの構造とは関係ないのではないか? とのことで、なんとも寂しい限り。
ViTのTokenを混ぜるところにシレっとChannelを混ぜる部分が入っているように、gMLPでは、TokenとChannelを分けることをしない。
Attnの部分をGELUとSGUというパーツにする。

SGUはToken方向にLinearで混ぜたあと、ResMLPのAffine Transformのバイアス項と同じモノを足し、更に元の値とElementwiseにかける。ここで重要なのは、初期値でLinear(t)のWeightは0、バイアス項は1にして、Identityにしておくことだそう。

ImageNetの学習でDeiTとCompetitiveだけど、ConvとかHybridには負ける。
まとめ
次から次へと出てくる新形態で、どんどん構造は簡単になっているようで、学習手法はえらく難しくなっているのに注意。semi-supervisedで使われているようなかっこいいaugmentationとか、RegularizationやらNormalizationの手法はどんどん良くなっているので、きちんと比較しないと何が効いているのかわからない。そもそも、新しい構造は、こういう学習手法を使わないと学習はできないために使われているが、Convはそんなのなくても学習できた。そんなわけで、逆に、新学習手法をConvに入れれば精度が上がるという報告も増えている。
さらに、そもそもViT系は、学習に空間方向の情報を全部入れたいためにパッチを導入したが、そのパッチが効いてるんじゃないかという報告も出てきた。
Patches Are All You Need?🤷
というわけで、まだまだいろいろと謎が謎呼ぶ感じですが、上記3本の論文から、いろいろと面白いMLP系の論文も増えているので、要注目。