概要
この頃、自然言語屋さんが良く使うTransformerが画像認識の方にまでやって来ているので、このAttention構造だけ理解すりゃあ良いのだろうと思っていたけど、Transformerをそのまま使う人も増えてきた。Transformerの人気が出たのが2017年なので、きっとTransformerに特化した速い実装とかが転がってるんじゃないかと勝手に想像。
そんなわけで、
画像認識屋さんのための「初めてのAttention」
の続きで、Transformerがなんなのか画像認識屋さん向けに説明してみる。
画像認識屋さんの方から、Attention構造を使うっていうのは
画像認識でもConvolutionの代わりにAttentionが使われ始めたので、論文まとめ
こんな感じで、ピクセルごとをTokenと考えて、全部のピクセルをバラバラに入れると計算量が増えて無理だから、見る範囲を絞って計算量を落とそうと考える。Convolutionの考え方に似ているから自然な感じがする。
逆にTransformer使いの人から画像認識の問題を見ると、ある程度のピクセルをまとめてTokenとして、その塊をTransformerに入れれば全てのデータを一気に扱えるので自然な考え方っぽい。この場合、Attentionするカーネルサイズは全ピクセルということになる。ピクセルをまとめる方法は多々ありそうだけど、Convをかけとけば特徴量抽出後にまとめることもできる。
実際に、どうやってTransformerが使われているか、以下の論文を例にみてみる。
Image recognitionをTransformerのEncoderをそのまま使ってやる論文
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (多分Google、2020年9月)
細かい日本語の解説
画像認識の大革命。AI界で話題爆発中の「Vision Transformer」を解説!
Object DetectionをTransformerをそのまま使ってやる論文
End-to-End Object Detection with Transformers (Facebook、2020年5月)
細かい日本語の解説
Transformer を物体検出に採用!話題のDETRを詳細解説!
Transformerとは
まず、Transformerの構造をオリジナルの論文からひっぱてくる。
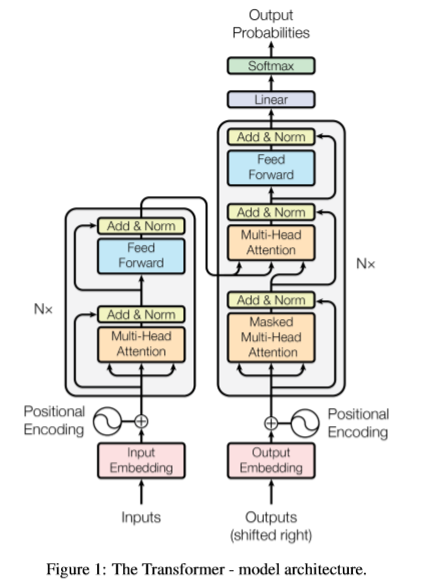
見ての通り、エンコーダー・ディコーダーの形になっている。左のエンコーダー部分をN回繰り返し、右のディコーダー部分もN回繰り返す。エンコーダー部分で入力の特徴をつかめば、翻訳なんかで順次ディコードしていくことができる。この時、Outputsの部分は、今のところ翻訳終了している単語が入ってくる。
一つずづのパーツは、
- Input Embedding/Output Embedding: Tokenを特徴量ベクトルに変換している
- Positional Encoding: Token同士の位置を表す入力。オリジナルでは、三角関数を使っている
- Add & Norm: ResNetと同じスキップコネクションとNormalization
- Feed Forward: 1x1 Conv+ReLUを2層
- Multi-Head Attention: 普通のAttention
- Masked Multi-Head Attention: 出力の方を、Attentionしたくても、途中で全部はないので、ない部分を-infでMaskしてSoftMax後に0になるようにしたAttention
Image recognitionでのTransformerの使われ方
Image recognitionの場合、解は一つで、ディコードする必要はないので、エンコードパーツのみを使う。
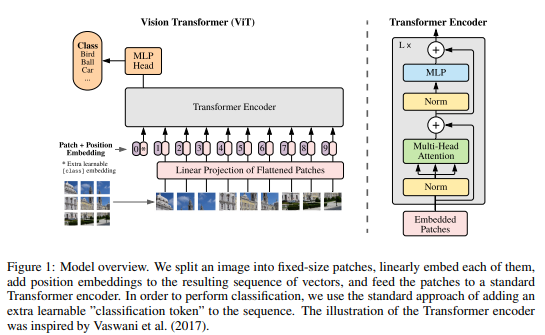
このMLPは、1x1のConvなのか、Full Connectなのか、ちょっとわからないが、Transformerと同じって意味では1x1のConvなんじゃないかと思う。
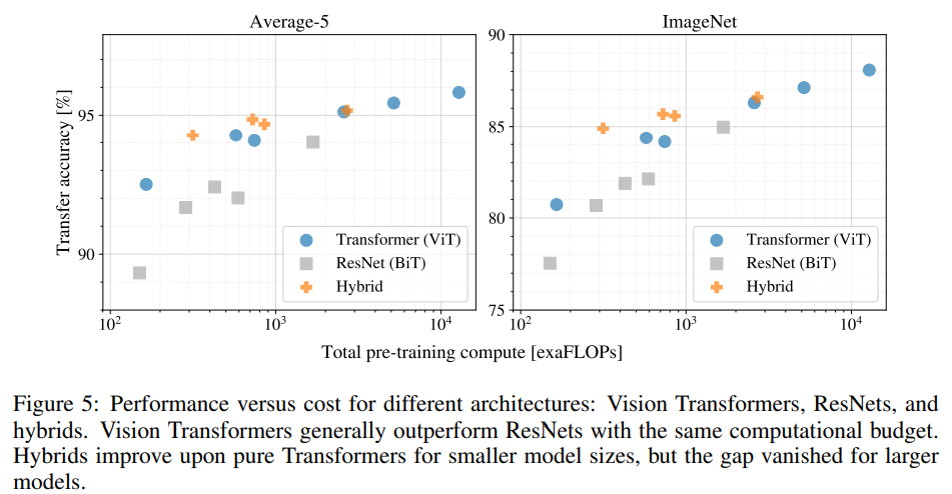
入力の部分をある範囲でまとめてTokenとして、全ていれる。Convで言うところのカーネルサイズは全域となる。この時、ピクセルをそのまま使わずにResNetである程度特徴量を取り出してから行うHybrids方式もある。計算量が少ない場合は、Hybrids方式の方が精度は良くなるようだけど、計算量が増えれば差はなくなるらしい。
Positional Encodingもオリジナルとは違い、いろいろと試しているが、単にraster順に数字を与えれば十分そう。また、入力に、クラスを意味するTokenを入れることで、最終層では、このTokenからClassificationは行われる。
今回のTransformerとオリジナルとの違いは、基本的には、入出力のみ。Normの位置とかActivation関数とかの実装面の違いはあっても、それにより何が変わるのかは不明。
Object DetectionでのTransformerの使われ方
Object Detectionの場合は、Transformerのディコーダーパーツを用い、N個のObjectを見つける。
全体の流れとしては、Image recognitionのHybrids型のように、まずはCNNを用いて特徴量を取り出し、それと位置情報を組み合わせてからエンコーダーに入れ、この結果と、N個のObjectをディコーダーに入れる。N個のObjectが出力されるので、そこからReLUを使った3層のperceptron(FFN)に入れて、バウンディングボックスの座標とクラスを出す。
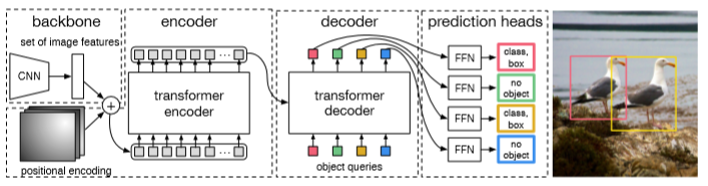
アンカーボックスとかはなしで、いきなりバウンディングボックスが出てくるあたりは最初の頃のYOLOに考え方は似ている。とはいえ、YOLOにもいろいろあった閾値のハイパーパラメータは出てこない。Facebookのブログでは、R-CNNと比べてどれだけシンプルか比較していて、わかりやすい。
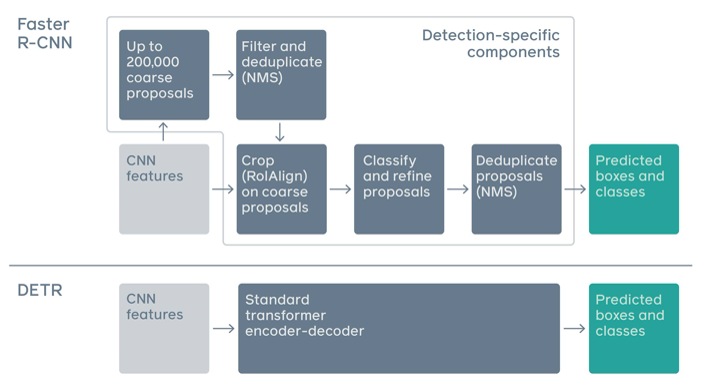
このTransformerを使うにあたって難しいのは、学習の際のLossの設定。「no object」という概念を入れることで、十分な数のObject queriesと、人間がタグ付けしたObjectを同数でマッチングでき、Lossを計算することができるようになった。この時に使われるTransformerを細かく図示したのが以下。
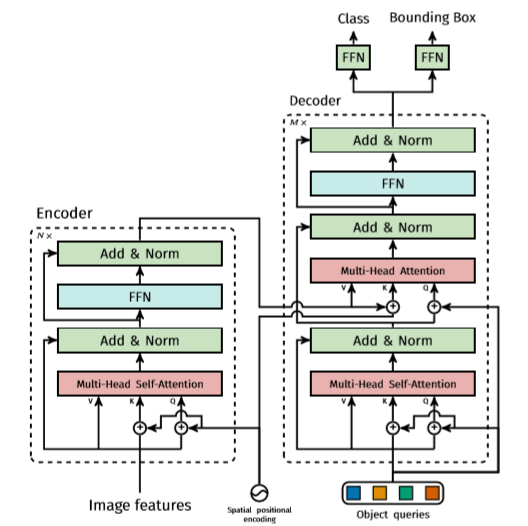
この時のFFNは1x1Convで、ないと精度が落ちるらしい。
基本的に、オリジナルのTransformerと変わらないが、ディコーダー部分で、順次Object queriesが来るわけではないので、今回はまとめて並列で処理できる。最初、0ベクトルを入れてそれがエンコーダーの結果を用いて学習されていくので、この時のMulti-Head Self-Attentionの方は、マスクする必要がない。
まとめ
画像認識の方でAttention構造を使う流れは止まりそうにない。すでに自然言語の方でTransformerなどの技術の蓄積があるので、それを利用しない手はないのだろう。