概要
この頃、流行っているAttention構造ってなんだろう? ということで、調べてみたら、解説が自然言語知ってて当然だよねってのばっかりで、画像認識しか知らない自分には、とっても大変だったので、画像認識の人向けに最低限必要な内容はこのぐらい、ってのをまとめてみた。
自然言語もGANもお友達じゃないので、間違っていたら、指摘していただけると、大変助かります。
おススメ解説はこれ!
https://www.youtube.com/watch?v=yGTUuEx3GkA
まず、自然言語の用語説明
単語がいっぱい並んで文を作っているので、単語をTokenという単位でわける。このTokenの特徴量をベクトルで持つ。画像で言うところの、ピクセルにおいて、チャンネル方向に特徴量のベクトルが入るような感じ。
上のYoutubeにある解説の例を取ると
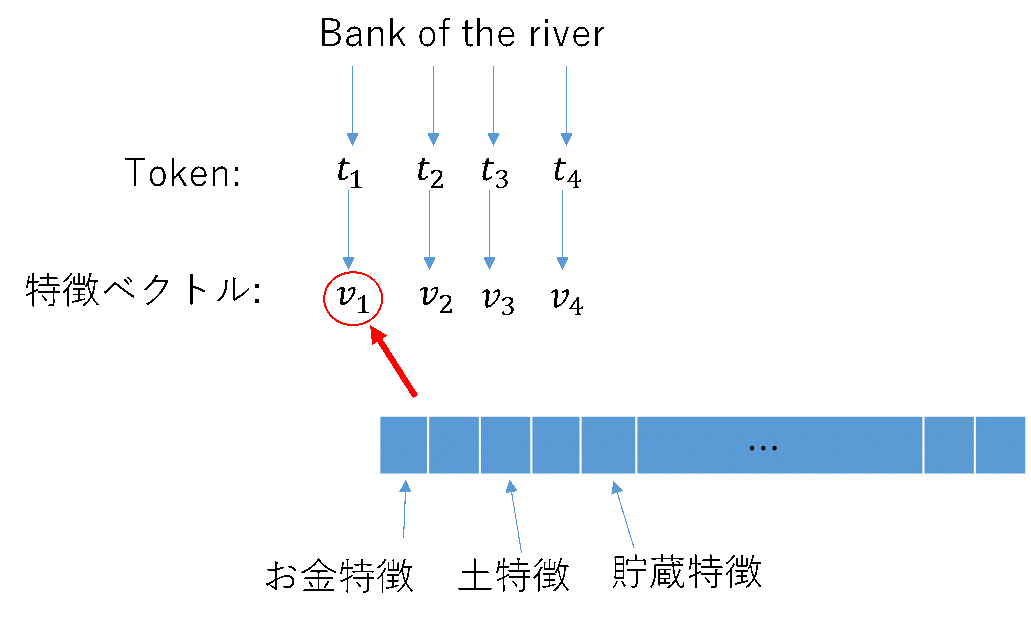
最初のBankは銀行という意味ではなく、土手という意味だが、それは、$v_4$のriverによって決定される。
単語そのものだけでは、意味は決定できなく、意味は周りの単語に依存する。そのため、ベクトル同士の関係性を見る必要がある。
普通にtime series dataであれば、あるデータは周りのデータとの関係性が深いため、ガウシアンフィルタなんかをかけて、周りのデータからエラーを吸収することができる。
この考え方を拡張すると、上の特徴ベクトル$v_1$、$v_2$、$v_3$、$v_4$の$v_3$は、あるWeight $[w_1 、w_2 、w_3]$を使って、以下のように変換して、出力$y_3$を作ることができる。
$$y_3= w_1 v_2+w_2 v_3+w_3 v_4$$
自然言語の場合、time series dataとは違い、近くにあるから関係性が深いとは限らないが、関係性が深いかどうかWeightを用いて表すと、同じことができる。
ここで、self-attentionという考え方を導入。
特徴ベクトルの関係性を相関で見ると考え、$v_3$とその他を内積する($v_3^T v_i$)。これで、比較するベクトルの数だけ関係性が出てくることになる。これをWeightとしてしまうと、スケールがベクトルのスケールによって変わるので、Weightのスケールを揃えるために、Normalize(良く使うのはSoftMax)する。これで、Weightができたので、さっきと同じ方法で、出力を計算。全体の流れは、以下。
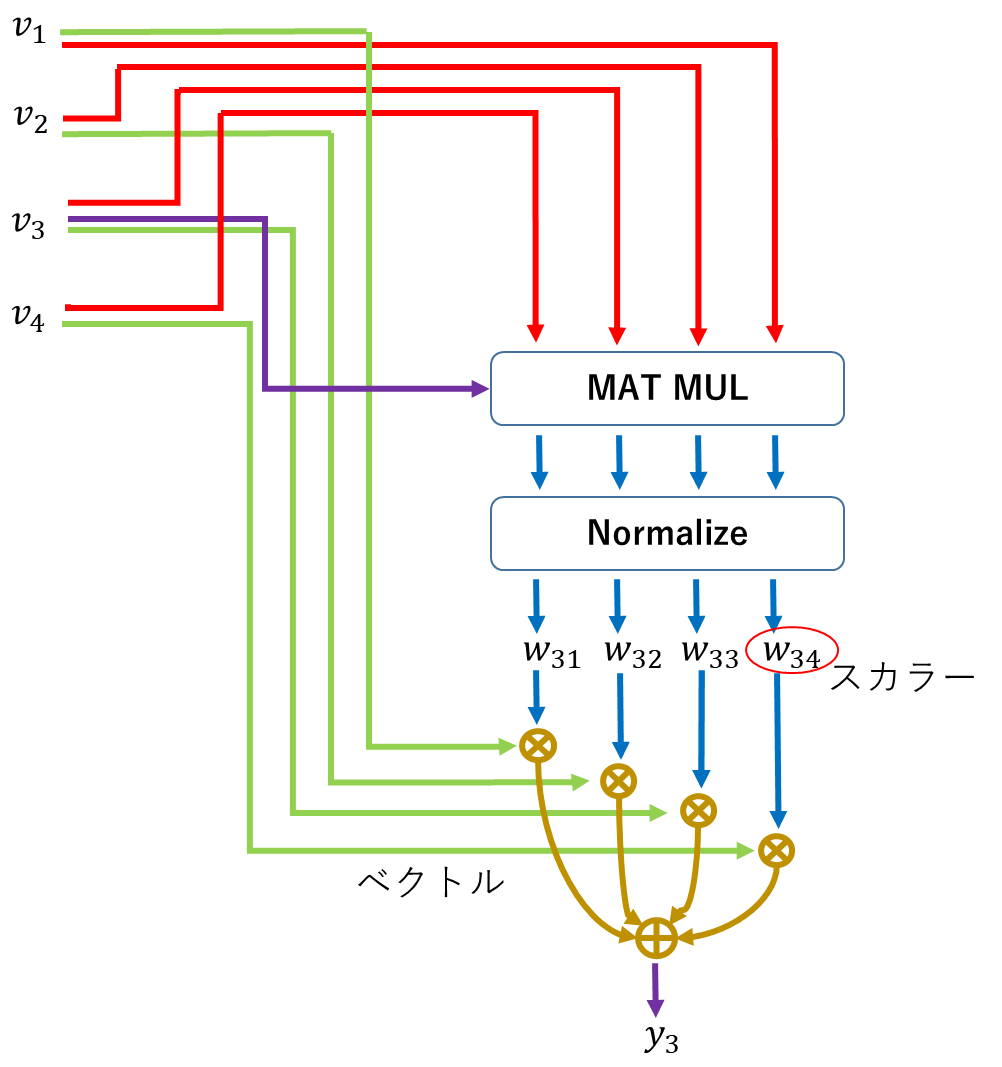
このWeightに学習は入っていない。
なんで、Self-Attentionって言うかっていうと、自然言語の人は、メモリっていう辞書みたいなモノを使っていたかららしい。画像で最初の方のエッジ検出にガボールフィルターを決め打ちで使うようなイメージ? まあ、これは入力が自分自身だけなので、Self-Attention。
ここから、じゃあ、学習も含めようってことで、入力に学習で作るLinear変換を入れる。
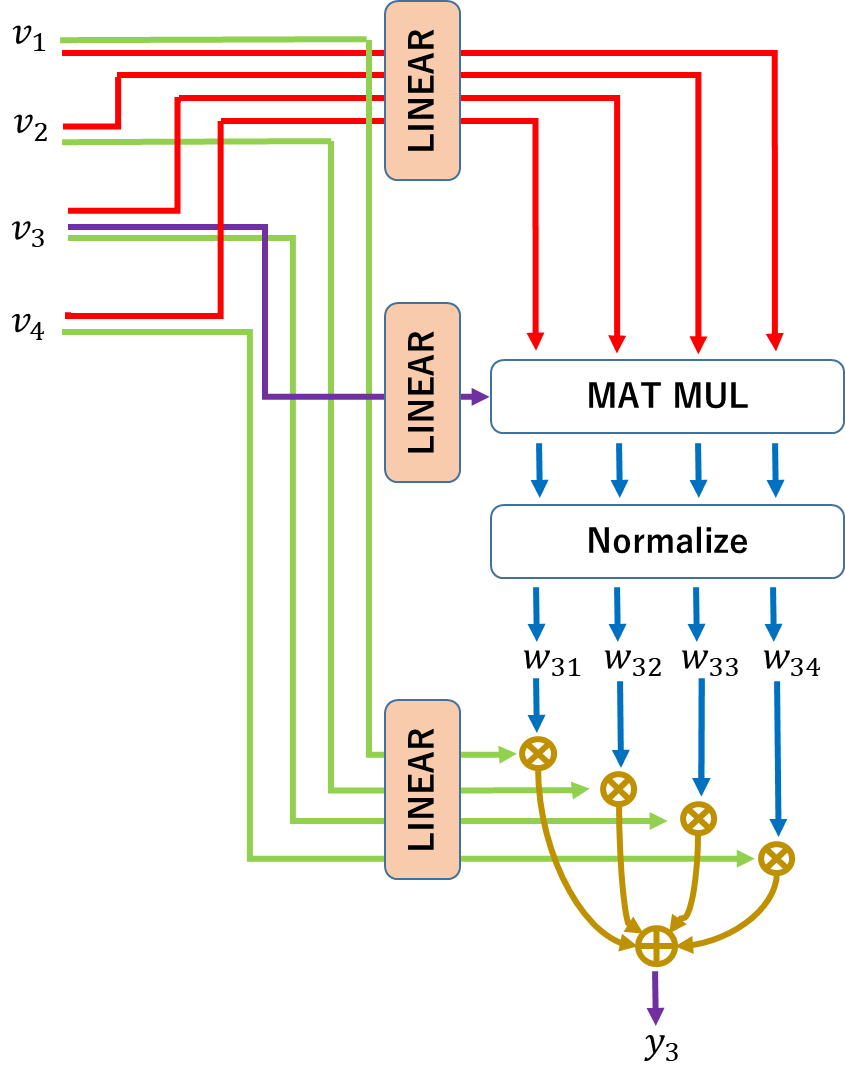
この時、他のベクトルと関係性を確認している$v_3$は、辞書と比較しているように見えるので、データベースの用語を引っ張ってきて、以下のようにLinear変換後の値を名付ける。
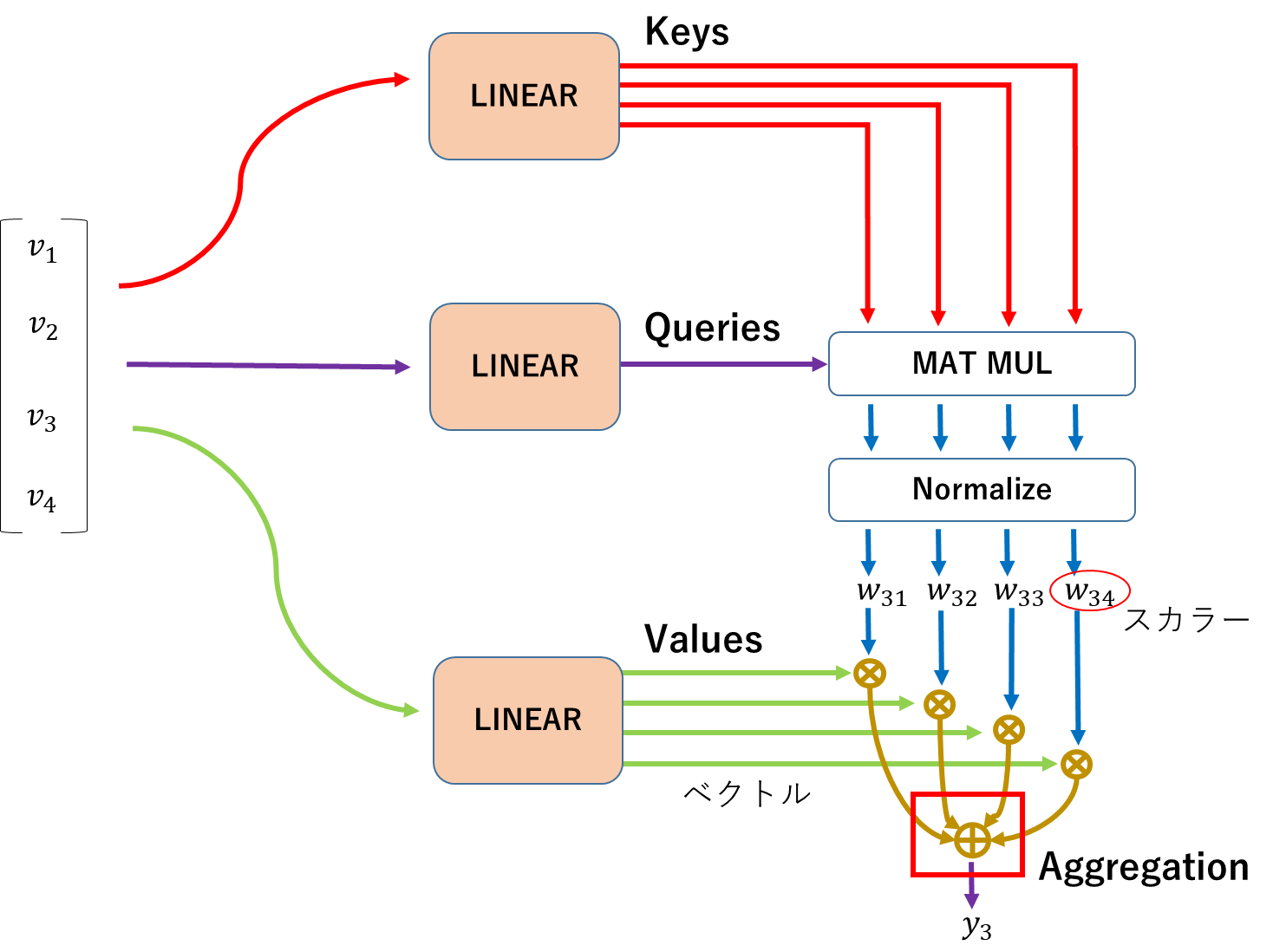
最終的に、全てのデータを集めるところは、Aggregationと呼ばれる。
ここで、学習されるLinear変換が一つであるということは、Weightも1種類しかできないということになるが、関係性というのは一つに絞れる訳でもないので、Linear変換をいくつか作った方が良い。これをMulti head attentionと呼ぶ。出てきた結果は全てConcatenateしてDimensionはDense Layerで調整する。
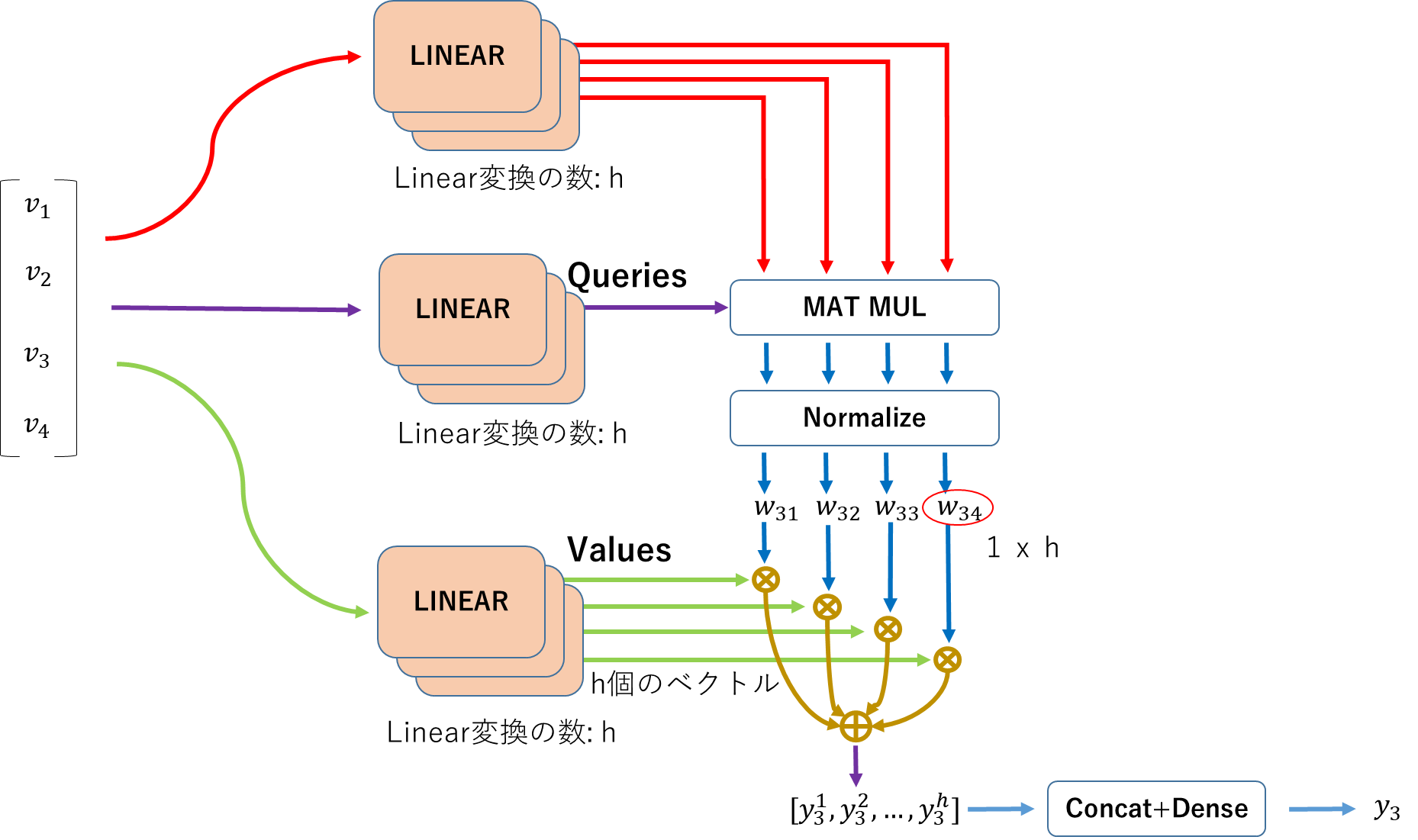
全ての特徴ベクトルにこのOperationをするのがAttention Layerということなる。
まとめ
自然言語の方の用語を一度忘れて図を見てみると、画像のある点においてチャンネル方向に特徴ベクトル$v_i$があるのと変わらない。画像で、Convolutionをする場合、Weightは、Forward中、変わることはないが、Attention構造では、入力に合わせて毎回作られることになる。
TransformerモデルとかのAttentionでは、さらにPosition Encodingと言って、Tokenがどこにあるかという情報も入れることで、単語の並びにより意味が変わる文にも対応する。画像でも同じように、位置情報は重要になるので、この考え方も継承されている。