画像向けTransformerとMLP系の派生論文によるカンブリア紀も落ち着いてきた今日この頃。
計算量が大きいやら、データがいっぱいないと学習できないとか、いろいろとConv派に言われていたものの、着実に改善されて特段問題もなくなり、Convもシレっと一緒に使われるようになって道具の一つとして定着したと言ってよさそう。学習方法を改善する論文がカンブリアってるので、その辺がこれからの流れなのだろう。
まずは、Convなしネットワークの計算量の話
計算量の観点では、MLP系の論文にTransformer系の論文は、食われたんじゃなかろうか。
未だにMLP系で同じ構造を使ってTransformer系に勝ったという論文は見ないものの、ネットワークの規模的には、いけそうだし。
MLP系をさらに軽くする方法として、Transformerでおススメされた見る範囲を絞る系(参考)とMLP自体を軽くする系が出てきている。
MLPを軽くする方法として、画像空間方向に全部見るのは、やりすぎ系はずいぶんと増えている感じ。
・ 画像空間方向に計算は何もしないで、1ピクセル縦横左右にシフトするだけの方法がいくつか
画像の空間方向にConvもAttentionもMLPもしないでShiftするだけの論文まとめ
・ 画像空間方向に2x2のAverage Poolingをするだけの論文に関しては、以下2本の記事がわかりやすい。
プーリング層だけでも充分!?衝撃の画像認識モデルMetaFormerを解説!
ViT時代の終焉?MetaFormerの論文紹介と実証実験
逆に周波数領域でやれば、まとめて全部見れるけど軽くて便利だよ系も出てきているので、今回はそれをまとめようと思う。
毎度、新しいアイディアは同じ時期に別のところから出てくる。今回はこの2本。
- GFN: Global Filter Networks for Image Classification(NeurIPS2021:精華大学と仲間たち論文)
- AFNO: Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers(ICLR2022:NVIDIAとCaltechとstanfordの論文)
一般化すると、ICLR2021のこれになるのだけれども、この論文は重い。
FNO: Fourier Neural Operator for Parametric Partial Differential Equations
PDEで表される物理現象だって、人間がぼんやり見てると続きとか、間とか埋められるから、DNNで学習させれば良いんじゃね? というところから、物理現象を表すPDEをモデル丸ごと学習させてしまえというアイディアを成功させた論文で、超解像度系の似たような論文(NeRF: Representing Scenes as Neural Radiance Fields for View Synthesisとか)がいっぱいあるようだけれども、フォローしきれていなくてわからない。
ちなみに、これまた毎度ながら、自然言語の方では、似たようなのが随分前にGoogleから出ている。
FNet: Mixing Tokens with Fourier Transforms
軽くするというのではなく、周波数領域繋がりで、実験量が半端ないSOTA大会系のもついでに紹介。
An Image Patch is a Wave: Phase-Aware Vision MLP
これは、上のと違い画像方向ではなく、Tokenを周波数領域に持って行く。画像方向はMLP系と同じように計算するが、Channel方向が周波数領域になっているという新しいアイディア。入力データにより周波数域が動的に変化するらしい。
本題、画像を周波数領域で見る
画像を見るんなら、周波数領域だろって言う、過去の常識を振りかざしてみたいけれど、知らない人は、まずここから。
大妻女子大学の授業ノート
絵で使っているデータを波の情報をピクセルの位置でサンプリングしたと考えるとわかりやすい。
で、これを利用して、画像の情報を周波数領域で学習するってのもありじゃね? というのが、今回の話。
いくつか派生が出ていて、それをうまいことAFNOの論文がまとめてくれているのが以下の図。
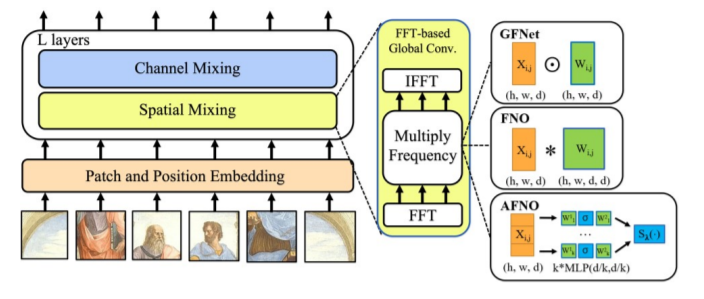
基本的には、MLP-mixerと同じ構造を取り、Token Mixing(図ではSpatial Mixingと表記)を新しい計算手法に変える。
このFFTして、何らかのOperationをしてIFFTする部分のOperationをアダマール積にすれば、単なるConvolutionのことなわけで、そこまで急に新しいことを言い出したわけではない。
周波数領域で見ることで連続なglobal convと考えるというのも、超解像系やPDE解析系では、良くあるらしい。
これで、何が良いかと言うと、端的に計算が軽くなるというのもあるが、細かく見れるので、Segmentationとかに強くなり、Robustになるらしい。AFNOはSemantic segmentationでSOTAだと言っている。他のタスクでも計算量落としていても、精度に問題はない。
実際の計算量は上と同じくAFNOの論文から

と、良いことだらけ。
ちょっと細かく見ていく。
GFNの方のOperationの図は、GFNの論文から以下
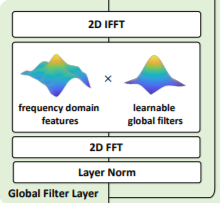
わかりやすく、Depthwise Global Convになっているが、FFTを用いるために計算量は大きく削減できている。
GFNもいろいろと試して、うまく行ってるというのを示しているけど、まあそんなことより面白いのが、学習済みのフィルター。

周波数領域だと、なんか意味ありそうなのが、これを画像にもどすと良くわからないという。
やっぱり、画像なんだから、周波数で見ようよと言った感じ。
GFNは、画像空間だけを周波数領域に持って行ったけれど、これをチャンネル方向も全てやってしまおうというのが、一般的なFNO。ただ、これだと大きすぎるので、画像向けに手を加えたのがAFNO。画像方向にだけ周波数領域に持って行くのと違って感覚的にわかりにくい。
[](簡単に流れをみると- self-attentionってkernel integrationの一部じゃん。
- kernel integrationの特別なケースがglobal convじゃん。
- global convって言ったらFFTでしょ。FNO考えた。
- 言うてもWeight大きすぎるからAttentionのMulti-headみたいにBlock Diagonalにした。
- 一つ一つのTokenを2層のパーセプトロンで、変換するけど、その時使うWeightとbiasはSharingする。
- この変換したTokenと元のTokenを使ってnonlinear LASSO TibshiraniでWeightを作ることで、SparsifyするWeightを生成する。)
全体の流れは、以下

これまた、いっぱい実験をして、良い結果が出ている。特に細かいところを見ないといけないSegmentationには、良さそう。
他の分野でも周波数領域でやるのは増えているので、画像系でも増えてくるのではなかろうか。