はじめに
この記事は顔学2020アドベントカレンダーの5日目の記事です.
今日はFaceNetを手軽に試せるようにラップしてくれているPythonのライブラリであるkeras-facenetの使い方をまとめようと思います.顔学会には工学に詳しくない方も多いので,なるべく込み入った内容には触れずに,ただコードを実行すれば再現できるように進めていくつもりです.
FaceNetとは
FaceNetはGoogleが開発した顔認証のための顔認識モデルです.Inception ResNet V1というモデルの出力にL2ノルムを取った結果を顔の特徴量ベクトルと考えるモデルです.深層学習による顔空間の構築とも言えるかもしれません.
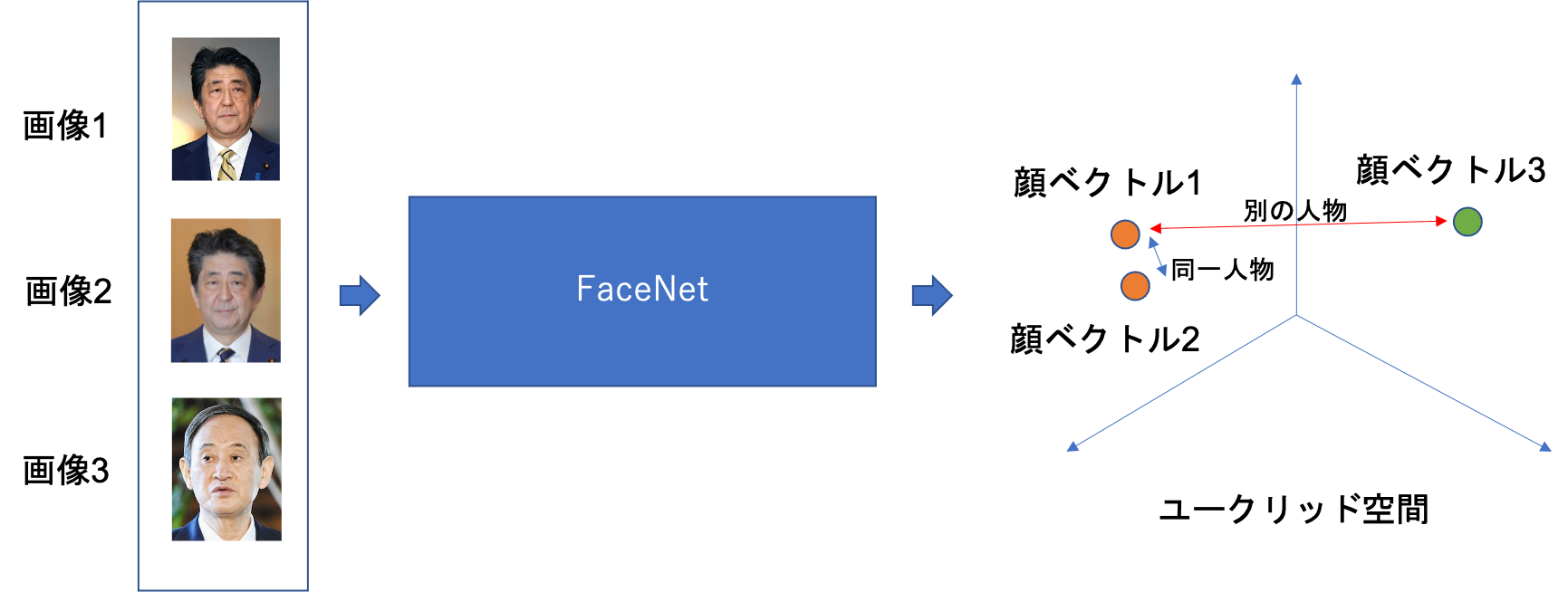
顔認証の流れとしては,
- FaceNetに顔画像を入力して顔ベクトルを取得する
- 顔ベクトル同士のユークリッド距離を計算する
- 距離が閾値以下なら同一人物とみなす
以上の三つだけです.この工程を順番にコードを見ながら追っていきます.
データセット
まず,今回使用する顔画像については安倍前首相・菅現首相の顔画像をそれぞれ5枚を用意しました.Google Driveで公開していますので,ダウンロード可能です.
> wget "https://drive.google.com/uc?export=download&id=1toQim1h0fX_IkRAnCpNZYXsrBmqba1QS" -O images.zip
> unzip images.zip
FaceNetを使った顔認証
Google Colabで実装したコードと実行結果を載せていきます.
ライブラリのインストール
今回はkeras-facenetを使って簡単にFaceNetを利用します.miraはMTCNNという顔領域検出モデルを利用するためにインストールしています.
> !pip install mira keras-facenet
顔画像から顔ベクトルを取得する
安倍さんと菅さんの顔画像をMTCNNという顔領域検出モデルを用いて切り抜き,FaceNetに通して顔ベクトルに変換します.その時に使った顔領域画像も後ほど使うので取っておきます.
from mira.detectors import MTCNN
from keras_facenet import FaceNet
from PIL import Image
import numpy as np
import cv2
import matplotlib.pyplot as plt
import os
dirs = ["images/abe", "images/suga"]
embeddings = [] # 顔ベクトル(顔特徴量)
imgs = [] # 顔領域を切り取ったもの
detector = MTCNN() # 顔領域の検出器
embedder = FaceNet() # FaceNetモデル
for dir in dirs:
files = os.listdir(dir) # ディレクトリ のファイルリストを取得
for file in files:
file_path = os.path.join(dir, file)
print(file_path)
img = cv2.imread(file_path) # 画像読み込み
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB形式に変換
faces = detector.detect(img_rgb) # 顔領域を検出.画像中に複数の顔が検出されることも想定する
embedding = embedder.embeddings([face.selection.extract(img_rgb) for face in faces]) # 潜在変数表現に変換
embeddings.append(embedding[0])
imgs.append(faces[0].selection.extract(img_rgb)) # 顔領域を保存しておく
顔ベクトルの様子を見る
ひとまず顔ベクトルがどんな具合に取れているか確認してみます.とはいえFaceNetで展開される顔空間は512次元なので,ひとまず主成分分析(PCA)で2次元まで次元削減して可視化します.また,圧縮前の特徴量にK-meansというクラスタリング手法を適用して10件のサンプルを2クラスに分類してプロットします.正しく顔ベクトルが取れているならただしく分類された結果がプロットされるはずです.
クラスタリングとPCA
from sklearn.cluster import KMeans
K = 2 # クラスタ数
kmeans = KMeans(n_clusters=K).fit(embeddings) # 圧縮前にクラスタリングしておく
pred_label = kmeans.predict(embeddings)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(embeddings)
reduced_embeddings = pca.fit_transform(embeddings)
可視化
import matplotlib.pyplot as plt
%matplotlib inline
# 結果をプロット
x = reduced_embeddings[:, 0]
y = reduced_embeddings[:, 1]
plt.scatter(x, y)
plt.show()

プロットされた座標をみてみるとしっかり左右に分離できていました.主に横軸になっている第一主成分だけで安倍さんと菅さんの違いは認識できているようですね.
顔画像を使って可視化
もう少し視覚的にわかりやすくするために,こちらの記事で使われていた関数を少し書き換えて顔画像で散布図を作成します.
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
def imscatter(x, y, imgs, ax=None, zoom=1):
if ax is None:
ax = plt.gca()
artists = []
for x0, y0, img in zip(x, y, imgs):
im = OffsetImage(img, zoom=zoom)
ab = AnnotationBbox(im, (x0, y0), xycoords='data', frameon=False)
artists.append(ax.add_artist(ab))
return artists
x = reduced_embeddings[:, 0]
y = reduced_embeddings[:, 1]
fig, ax = plt.subplots()
imscatter(x, y, imgs, ax=ax, zoom=0.2)
ax.plot(x, y, 'ko',alpha=0)
ax.autoscale()
plt.show()
入力画像サイズを統一していなかったので若干みづらいですが,顔空間の概要を掴みやすくなりました.

ユークリッド距離の計算
顔ベクトル同士のユークリッド距離を計算し,その得られた距離が大きいかどうかで同一人物かどうかを判定します.scipyで簡単に計算することができます.
ここでは,まず同一人物の時とそうでない時でユークリッド距離にどれほどの差が出るのかを総当たりで計算します.
import scipy
from scipy import spatial
# ユークリッド距離を計算
def calc_euclid_distance(a, b):
return scipy.spatial.distance.euclidean(a, b)
abes = embeddings[:5]
sugas = embeddings[5:10]
# 違う人物の場合のユークリッド距離
negatives = []
for abe in abes:
for suga in sugas:
negatives.append(calc_euclid_distance(abe, suga))
# 同一人物の場合のユークリッド距離
positives = []
for i in range(5):
for j in range(5 - (i + 1)):
positives.append(calc_euclid_distance(abe[i], abe[i + j + 1]))
positives.append(calc_euclid_distance(suga[i], suga[i + j + 1]))
print(np.average(positives)) # 0.04065310596488416
print(np.average(negatives)) # 1.0330342292785644
同一人物の場合は平均で0.04の距離であり,逆に違う人物の場合は1.03程度の距離があることがわかりました.なので,閾値は0.5程度で設定すれば間違いないでしょうか.
実際に論文を読んでみると公式には1.1の閾値を使用していましたが,今回はそれでは判別できませんね.おそらくデータセットには日本人のデータが少なかったのでしょう.日本人という雑なカテゴリで分類されていたりして,距離が近くなりやすいんだと思います.用途によって個別に設定する必要があるみたいですね.
それにしても,日本人でもそこそこちゃんと分離できているのはすごいですね.
さいごに
今日は顔認証モデルのFaceNetをお手軽に試せるライブラリであるkeras-facenetを紹介しました.アドベントカレンダーの言い出しっぺなので結構頑張って記事を書いていますが,そろそろ修論が本格的にやばいのでしばらく記事のほうはお休みさせていただきます.もしみなさんも顔に関する知識や経験がありましたら,アドベントカレンダーに登録をお願いします.
コードはこちらで公開しているので是非試してみてください.
https://colab.research.google.com/drive/1SnBvOmDVa_KN6SqbhJJK90yvMddASZmp?usp=sharing
それでは.
追記
FaceNetを使った面白そうな研究を発見したので共有.
FaceNetに対するAdversarial Exampleによる意図的誤認識
FaceNetのモデルに対してAdversarial Exampleを入力して誤作動を起こさせた結果をまとめた論文.
Adversarial Exampleは正しく認識できていた画像に対して,勾配上昇するようにノイズをのせてネットワークに誤認識を起こさせる攻撃手法です.人間が見たらほぼ同じ画像ですが,ネットワークの判断を大幅に誤らせることができます.

Explaining and Harnessing Adversarial Examples