皆様は正規表現をお使いでしょうか?
コードを書くことを生業にしている方なら常日頃とは言わずとも、幾度も相手にしたことがあると思います。
私は結構よく使います。ただし、コードに書き込むのではなくテキストエディタで。
これが割と便利です。練習にもちょうどいい。
何かそれっぽい名前の変数や関数を適当なあたりをつけてgrepする際に、大文字、小文字、キャメルケースにスネークケース、よくあるタイプミスなんかもうまく書けば緩衝して一発で探してきてくれます。
うまく書けば。
しかし、その正規表現は使い捨て。
たまにコーディングする時も結構単純なもの。目的に適うものを書き上げるのが当然の目的であって正規表現にこだわる必要すらない。
せいぜい半角数字を捕まえる時に [0-9] と書くのをやめて \d と書いてみて変わったことをした気分になる程度という体たらく。
書くたびにそれっぽいものをググって拾って魔改造、という感じ。
UnicodeプロパティだとかPOSIX文字クラスだとかいう連中がいることは知ってはいるが使ったことはあっただろうか?
そこで、せっかくの機会なのでいくらか調べてここに書き留めておくことにしました。
rubyでの正規表現を想定しています。
rubularは便利ですね。
日本語相手の正規表現
先ほど少し書いたように、数字にマッチさせたい場合 [0-9] という文字クラスを指定することがよくあるかと思います。
また、同様にアルファベットにマッチさせたい場合 [a-zA-Z] などと指定したりするかもしれません。
一般的な英数字、または記号程度ならこの書き方で正直事足りるような気がします。
しかし、このような文字クラスでの指定は日本語の場合少し癖のあるものになりがちです。
例えば「正規表現 ひらがな」なんかで検索すると [ぁ-ん] と表記するといいよ。と書いてあることがままあります。(小さい"あ"から始まります)
実際にUnicodeを確認してみたところ、小さい"ぁ"は普通の"あ"の前にあります。なので小さい"あ"から指定を始める必要があるようですね。

ちなみにこの画像をみてもわかるようによくネット上で見かける[ぁ-ん]という文字クラスの指定では"ゔ"以降のひらがなを捉えられません。

それよりもこれを調べていて痺れたのは"ん"以降のひらがなですね。
"ゝ"や"ゞ"なんかはまだ見たことはありますが U+309F の彼は一体何者なのでしょうか、そもそもお前は本当にひらがななのか?なんと打てば出てくるのかすら全くわかりません。
wikipediaによると ゟ←これ はよりと読む。
「片仮名版も存在するが現状ではコードポイントを設定していないため、PCのテキスト上に表示できない。」ということらしいが・・・。
手紙の最後に「〜ゟ」と記名したり、「ロシアゟ愛を込めて」なんて具合に使うのだろうか。
合略仮名という分類の文字らしいです。
打ち方がわからないでいうと"ゕ"と"ゖ"もなかなか謎です。"lka"とか"xka"とか打っても"ヵ"としか出てきません。挙句、変換を行うとmacは異なる注釈をつけて同じ文字を3回紹介してくれます。

と、ただひらがなを正規表現で捕まえようというだけで早くも苦労に塗れてきました。
Unicode プロパティ
少し話がそれ気味だったような気がしますが、ここでやっと Unicode プロパティが登場します。
ruby(というかonigmo正規表現ライブラリ)では\p{property-name}と記述します。
rubyではonigmoで使えるプロパティが使えます。
カタカナ\p{Katakana}とか、漢字\p{Han}とか、タガログ語タガログ文字\p{Tagalog}とか。
上記リンク参照
かな
このUnicode プロパティを使ってひらがなを補足したかったら\p{Hiragana}と書くだけで、先述の問題も全て解消して、現代の日本人は見たことも無いようなひらがなまで捕まえてくれます。

ここで\p{Hiragana}に含まれている文字はどんなものがあるのか気になります。
どうも\p{}は以下のページに記載のプロパティを使用できて、\p{Hiragana}UnicodeのScriptsを参照するらしいです。
http://www.unicode.org/Public/UNIDATA/Scripts.txt
これによるとHiraganaの中身はこんな感じ。
3041..3096 ; Hiragana # Lo [86] HIRAGANA LETTER SMALL A..HIRAGANA LETTER SMALL KE
309D..309E ; Hiragana # Lm [2] HIRAGANA ITERATION MARK..HIRAGANA VOICED ITERATION MARK
309F ; Hiragana # Lo HIRAGANA DIGRAPH YORI
1B001..1B11E ; Hiragana # Lo [286] HIRAGANA LETTER ARCHAIC YE..HENTAIGANA LETTER N-MU-MO-2
1B150..1B152 ; Hiragana # Lo [3] HIRAGANA LETTER SMALL WI..HIRAGANA LETTER SMALL WO
1F200 ; Hiragana # So SQUARE HIRAGANA HOKA
# Total code points: 379
一番上の行を例に、左から
・3041..3096 : Unicode 文字コード範囲
・Hiragana : プロパティ名(\p{}の中身)
・Lo : Unicode一般カテゴリ(詳しくはUNICODE CHARACTER DATABASEのGeneral Category Valuesの項を参照)
・[86] : 包含文字数(読んで字のごとく、86文字)
・HIRAGANA LETTER SMALL A..HIRAGANA LETTER SMALL KE : プロパティ説明(これも読んで字のごとく、小さい"あ"から小さい"け"まで)
そのほかにも複数のグループが含まれていて合計379もの文字がHiraganaプロパティには含まれているようです。
50音順とはなんだったのか。
ちなみに先ほどの結果を見てお気付きの方もいらっしゃるかもしれませんが、このHiraganaプロパティ、長音記号は含まれていません。
意図したものなのか否か。何れにせよ伸ばし棒も捕まえたければちゃんと[\p{Hiragana}ー]と文字クラスに含めておきましょう。
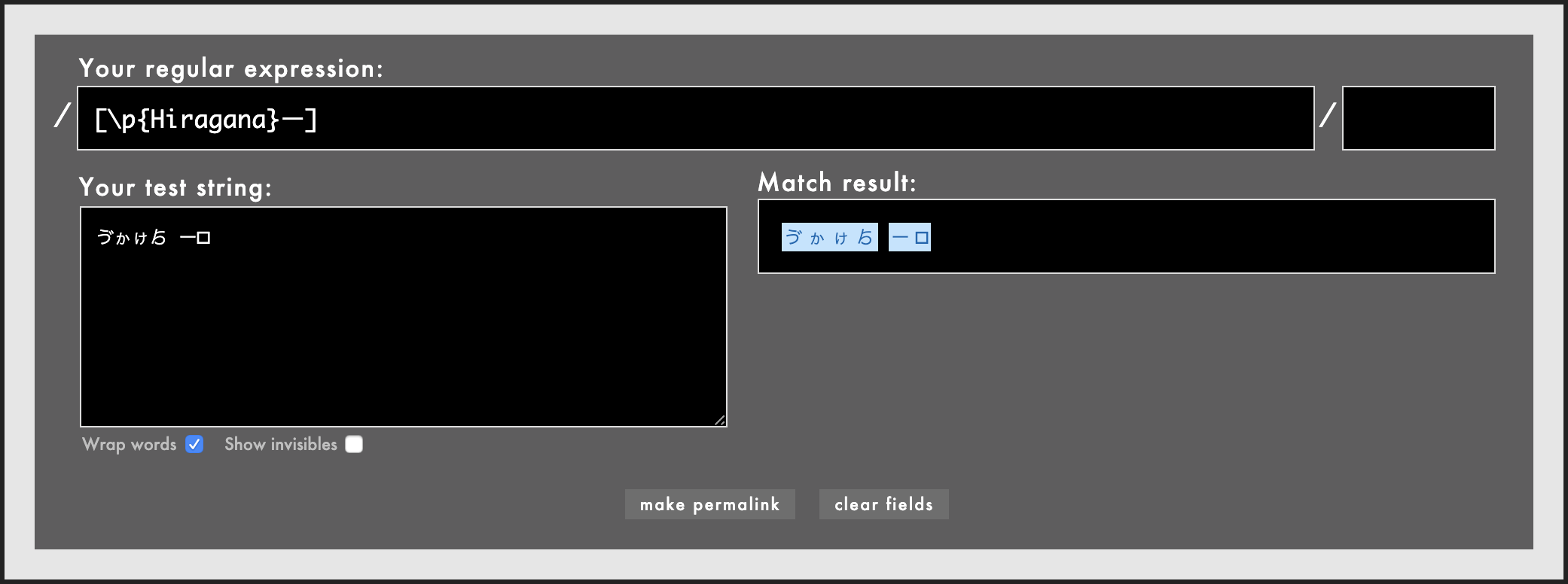 ~~ただ、長音記号には似たような形のものがいっぱいあるので、純粋な長音記号しか許可しないようにしているとハイフンを入力しながら「伸ばし棒が通らない!」と怒られるかも。~~
~~ただ、長音記号には似たような形のものがいっぱいあるので、純粋な長音記号しか許可しないようにしているとハイフンを入力しながら「伸ばし棒が通らない!」と怒られるかも。~~
\p{Katakana}も同様に長音記号は含まれていません。
追記:
コメントでも指摘を頂いてしまったのでちゃんと書きますが、上記の通り長音符号はそもそも 「かな」 に含まれていません。
長音符号の情報はこんな感じ
30FC ; Common # Lm KATAKANA-HIRAGANA PROLONGED SOUND MARK
script プロパティ は Common
一般カテゴリは Lm
というわけで、全角長音記号は \p{Common} や \p{Lm} などでマッチングします。
ただし、[ぁ-ん]これにはこれで魅力があると思っています。
ひらがなにマッチする正規表現を書こうとした時、頭に思い浮かべたのが50音順+濁点・半濁点程度の一般的なひらがな達にとどまるなら\p{Hiragana}は過剰でしょう。
見たことのない記号のような文字などが通過してきてしまいます。
こういう時には[ぁ-ん]を使っていくのが良いのではないでしょうか。
漢字
漢字を捉える正規表現は[一-龠]とか[一-龥]などをネットでは見かけたりします。(これはUnicodeの話でありShift_JISでは違う表記になります。)
まぁ、常用する漢字ならこの範囲で十分カバーしており、これより先は言語学者でもなければ使わないだろうと言う腹ですね。
当然これに収まらない漢字もありますが、ここで\p{Han}と書くとこれが解決。
約9万字にのぼるあらゆる漢字を拾ってくれます。
さらにこの\p{Han}拾うのは日本語の漢字に止まりません。
中国語の簡体字や繁体字、韓国語の漢字にもマッチしてくれて、ベトナム語の漢字(があることを今回初めて知った。)にもマッチするそうです。
最近話題になった"令"を例にしてみましょう。新元号「令和」の令です。
この漢字は、韓国語にも同じ形の漢字があり、別のコードが与えられているということで少し前にちょっと一部界隈で話題になりました。
qiitaにもいくつか記事があります。
s = "令令"
puts s.codepoints.collect {|cp| sprintf("U+%04X", cp) }.join(", ")
# => U+4EE4, U+F9A8
# 下記ページ参照
# https://ref.xaio.jp/ruby/classes/string/codepoints
これを正規表現に与えます。

こちらはダメ

こちらはうまく両方を取ってくれました。
その他
当然、言語関連以外にも算術記号\p{Sm}その他記号\p{P}アンダースコア\p{Pc}
ハイフンやダッシュなど長音記号っぽい者達にマッチする\p{Pd}という子もいますが、これはあらゆるハイフンやダッシュの親戚もマッチしてしまうので ⸚ ←こんな見たこともない子もマッチしちゃうかも。
ちなみに、\p{P*}というプロパティたちは全て\p{P}の部分集合です。
PはPunctuationの略で句読点のほか、約物なんて訳されたりします。
記号全般っぽいですが算術記号\p{Sm}は見ての通り約物に含まれていません。こちらはSymbolカテゴリに含まれています。
ここのGeneral Category Valuesや
ここなどでP*に含まれているものが何者か注意しておくと良いかもしれません。
POSIX 文字クラス
似たようなものでPOSIXブラケットと言うものもあります。こちらはonigmoに限らず、Shift_JISだとかEUCだとかUnicodeでなくとも使えたりするようです。
こちらはruby正規表現ドキュメントに使用できるクラス名とその内容が列挙されています。
[:alnum:] 英数字 (Letter | Mark | Decimal_Number)
[:alpha:] 英字 (Letter | Mark)
[:ascii:] ASCIIに含まれる文字 (0000 - 007F)
[:blank:] スペースとタブ (Space_Separator | 0009)
[:cntrl:] 制御文字 (Control | Format | Unassigned | Private_Use | Surrogate)
[:digit:] 数字 (Decimal_Number)
[:graph:] 空白以外の表示可能な文字(つまり空白文字、制御文字、以外) ([[:^space:]] && ^Control && ^Unassigned && ^Surrogate)
[:lower:] 小文字 (Lowercase_Letter)
[:print:] 表示可能な文字(空白を含む) ([[:graph:]] | Space_Separator)
[:punct:] 句読点 (Connector_Punctuation | Dash_Punctuation | Close_Punctuation | Final_Punctuation | Initial_Punctuation | Other_Punctuation | Open_Punctuation)
[:space:] 空白、改行、復帰 (Space_Separator | Line_Separator | Paragraph_Separator | 0009 | 000A | 000B | 000C | 000D | 0085)
[:upper:] 大文字 (Uppercase_Letter)
[:xdigit:] 16進表記で使える文字 (0030 - 0039 | 0041 - 0046 | 0061 - 0066)
[:word:] 単語構成文字 (Letter | Mark | Decimal_Number | Connector_Punctuation)
ドキュメントにも'エンコーディングによってこれらの POSIX 文字クラスの挙動が 異なります。'と記載されている通り、Unicode以外のエンコーディングではマッチする文字が異なるようなので、onigmoのドキュメントを参照する必要があります。
個人的にUnicode プロパティが使えるならこちらを殊更使う必要は生じないと考えています。
何よりこのドキュメントがかなりの誤解を招く。こちらの記事のコメントでも白熱しております。
上記記事でわかるのは[[:alpha:]]や[[:alnum:]]はかな漢字にマッチすると言うことです。
先ほどのドキュメントによると一見、英数字や英字にしかマッチしないように見えるのに。

ここでちゃんと onigmoのドキュメント を見てみましょう。
POSIXブラケットの項目には Unicode以外の場合、 Unicodeの場合 と分けてマッチする文字が記載されています。
Unicode以外の場合は
alnum 英数字
alpha 英字
そしてUnicode場合は
alnum Letter | Mark | Decimal_Number |
alpha Letter | Mark |
と書いてあります。
つまり、Unicodeはアルファベットを Letter | Mark の2カテゴリだと認識していると言うことだと考えられます。
ということは、ABCDEもあいうえおも白發中もLetterカテゴリなのでalphaだし、
ြこんな奴も[[:alpha:]] [[:alnum:]]は我々の直感に反して見事拾ってきます。

最後に
マッチする文字がどのようなものかを正確に認識した上で利用するならば[[:alpha:]]も便利ではあるのでしょう。
ただ、コーディングする場合は当然、いずれ他人の目に触れることになるでしょう。
その時、そのコードをみた人は「/[[:alpha:]]/だから言語を問わず単語を構成する文字がかかるんだな。」と認識できるでしょうか。
少なくともこの記事を書く前の私なら絶対に思わないでしょう。きっと[A-Za-z]と同等だと認識したはずです。そして、この認識が間違っていることに気がつくのも非常に困難だと思います。
そんなことを気にするくらいなら迷わず[A-Za-z]を使います。
POSIX文字クラスに関しては、「この程度なら普通に正規表現を書けばいいじゃん。」です。
Unicode プロパティも前述の通り微妙に直感に反してきたりしますが、POSIX文字クラスに比べると有用性が高い印象です。
積極的に使っていきたいですね。
追記:
コメントで
POSIX ブラケットの中で,
[:space:]だけはよく使いますね。
という意見をいただきましたが、先日私もついに[:space:]を利用しました。
テキスト中にある空白の類を削除する必要にかられて、当初は String#strip を使って削除を試みたのですが、これが タブや改ページ、垂直タブなどに対応する一方で全角スペースに対応できない。(ついでに今回は問題にはならなかったのだが、文頭 or 文末の空白のみを削除する。)
puts ' ←半角スペース'.strip #←半角スペース
puts ' ←全角スペース'.strip # ←全角スペース
というわけでこうした
puts ' ←半角スペース'.gsub(/[[:space:]]/, '') #←半角スペース
puts ' ←全角スペース'.gsub(/[[:space:]]/, '') #←全角スペース
満足。
これだと文中の空白も削除するため、不都合な場合は正規表現を調整して文頭 or 文末の [:space:] にのみマッチするようにすると良いだろう。