はじめに
以前連載していたUnicode文字プロパティの連載(関連)を半端なままにしてしまっていたので、再構成して再開します。お題は「Unicode 文字プロパティ」です。
基本的に自分のために書いているものであり、仕様やWikipediaとまったく同じことを書いてもしょうがないので、それらを補完する形で書きます。
書きながら調べているので、ツッコミどころがありましたらコメント欄にどうぞ。
気まぐれに書きますので公開日は一定しませんが、リクエストが多ければピッチ上げます。
連載目次
- 第1回 -- 概要
- 第2回 -- 数字表現
文字集合について
自分の中では、Unicodeの全文字集合を「大雑把には」以下のように分類しています。
- 文字(alphabets)
- 数字(numbers)
- 約物(punctuations) -- ざっくり言うと、文章を補助する記号(句読点やかっこなど)
- 記号(symbols) -- ざっくり言うと、約物以外の記号
もう少し詳しく分けると、以下のようなものも追加されます。
- 制御文字(controls)
- 顔文字(emoticons)
上はあくまで自分の認識であり、実際の分類と同じではありませんのでご注意ください。たとえば顔文字は実際には記号(symbols)に分類されます。
alphabetsには漢字やひらがなも含まれる
ここでご注意いただきたいのは、ここで言う**文字(alphabets)**に含まれるのは[a-zA-Z]だけではないということです。`日本語のひらがなやカタカナ、漢字はもちろん、キリル文字、ハングル、トンバ文字など多くの言語の文字もalphabetsに含まれるのです。
上のように大きい集合から説明すると何も不思議なことはないように思えます。
しかし、一部で話題になったように、[[:alnum:]]というPOSIXブラケットをその字面から「英数字だけにマッチする」と思って使ったら日本語にもマッチしてしまった、ということがしばしば起きます。
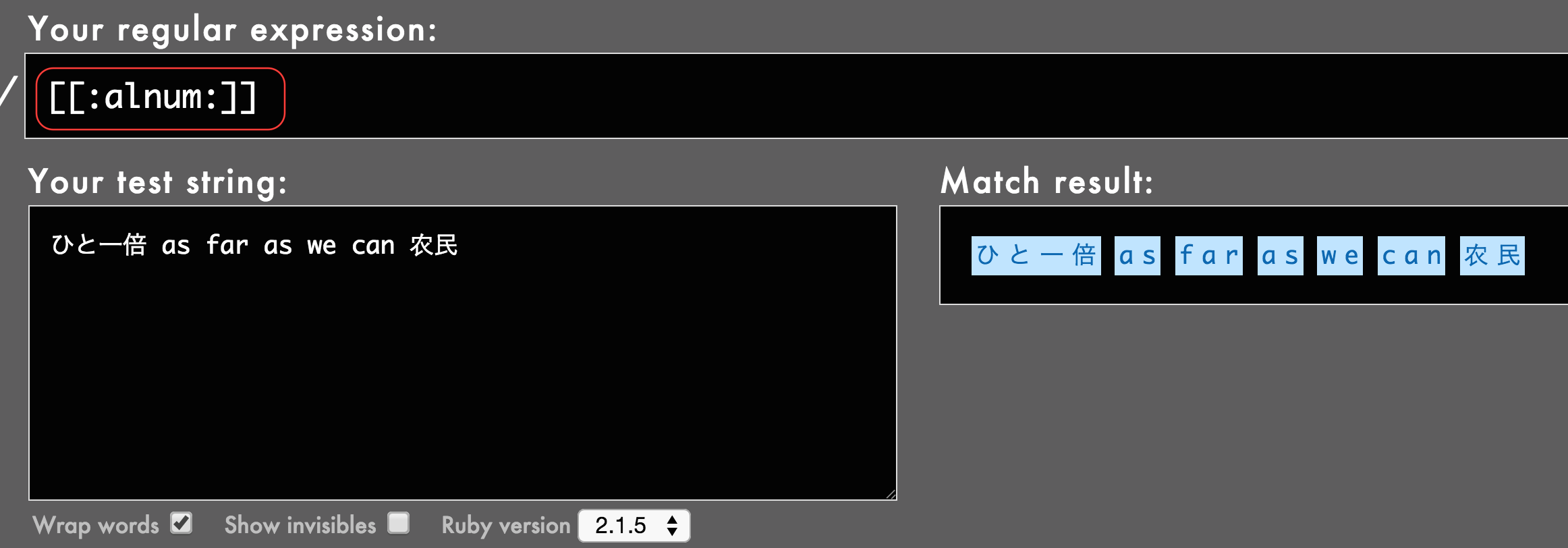
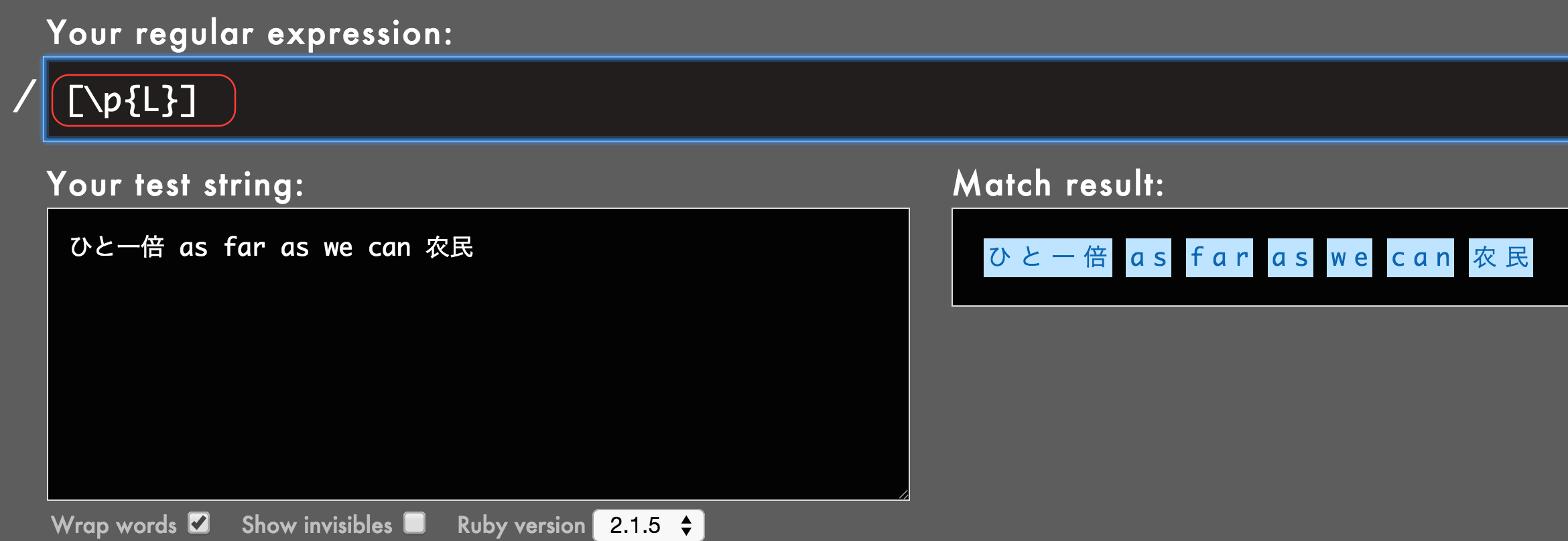
(↑いつの間にかRubularで直リンできるようになっていたのでリンクを貼りました)
見てのとおり、どちらを使っても文字にことごとくマッチしています。
こう考えるとよいと思います。「alphabetsとは、文字として機能するもののなかで、数字でもなく記号でもないものすべて」だと。集合論っぽく書くと以下のようになるでしょう(わざと「大雑把な分類」で書いてます)。
全文字集合 = 文字 ∪ 数字 ∪ 約物 ∪ 記号
日本語の場合、この文字に「漢字」「ひらがな」「カタカナ」「英文字」が含まれることになります(英文字を使わずに現代日本語を書くことはもはや不可能に近いでしょう)。
この辺りは今後もう少し掘り下げます。
そもそもUnicodeとUTF-8ってどう違う?
自分もこの違いをそれほど気にしないまま長らくやってましたが、改めてまとめると以下のようになります。
Unicode: 文字コードの規格であり、この中に符号化文字集合や文字符号化方式などの規格が含まれている。その文字符号化方式のひとつがUTF-8である。
というわけでUTF-8は明らかにUnicodeという規格の部分集合でしかないわけですが、圧倒的に多く使われていることもあって同一視されることが多いようです。
文字符号化方式の特徴をざっくり述べます(スキームの説明は省略):
UTF-8
- ASCIIの完全上位互換なので、特に多言語混じりのソースコードを表記するうえで圧倒的に有利
- その分漢字などのマルチバイト文字がややかさばる
UTF-16
- メジャーな言語の文字(基本多言語面)が「16ビット符号なし整数の符号単位列」なので、プログラミングでの分岐がUTF-8よりもやや少なくて済む
- Windows では内部表現がBOMなし、ファイル名はBOMありとわざわざオーバーヘッドと不揃いを仕込んでくれている、さすが
UTF-32
- 文字長が固定なので、文字列の長さを調べるだけで文字数がわかる(上の2つは可変長なのでフルスキャンしないと数えられない)
- ASCII文字も32ビットになってしまうので相当かさばると思われる
次回
数字表現について書いてみようと思います。