立て続けに第2回です。
連載目次
- 第1回 -- 概要
- 第2回 -- 数字表現
数字の扱い
Unicode 文字プロパティで数字を表すカテゴリには以下の3つがあります:
-
Number, Decimal unit: いわゆる数字。
Ndで表す。 -
Number, Letter: ローマ数字(Ⅷとか)など。
Nlで表す。 -
Number, other: その他の数字(⅔など)。いわゆる機種依存文字(⓴など)の多くもここに掃き寄せられている。
Noで表す。
文字プロパティでは大文字と小文字を区別しますのでご注意ください(NlとNLは違います)。処理系によっては動くこともあるようですが、将来改定される可能性もあるので区別しておくことをお勧めします。
今更ですが、正規表現の中で使用する際は[\p{Nd}]のように文字クラスを表す[]で囲みます。[]で囲まなくても動作する言語もあったりしますが、将来改定される可能性もあるので、極力囲んでおくことをお勧めします。
3つのカテゴリすべてを指定するには、[\p{Nd}\p{Nl}\p{No}]としてもよいですが、等価表現である[\p{N}]と書くのが簡潔です。
漢数字は数字か
Unicode文字プロパティでは漢数字は数字として扱われるのでしょうか、漢字として扱われるのでしょうか。
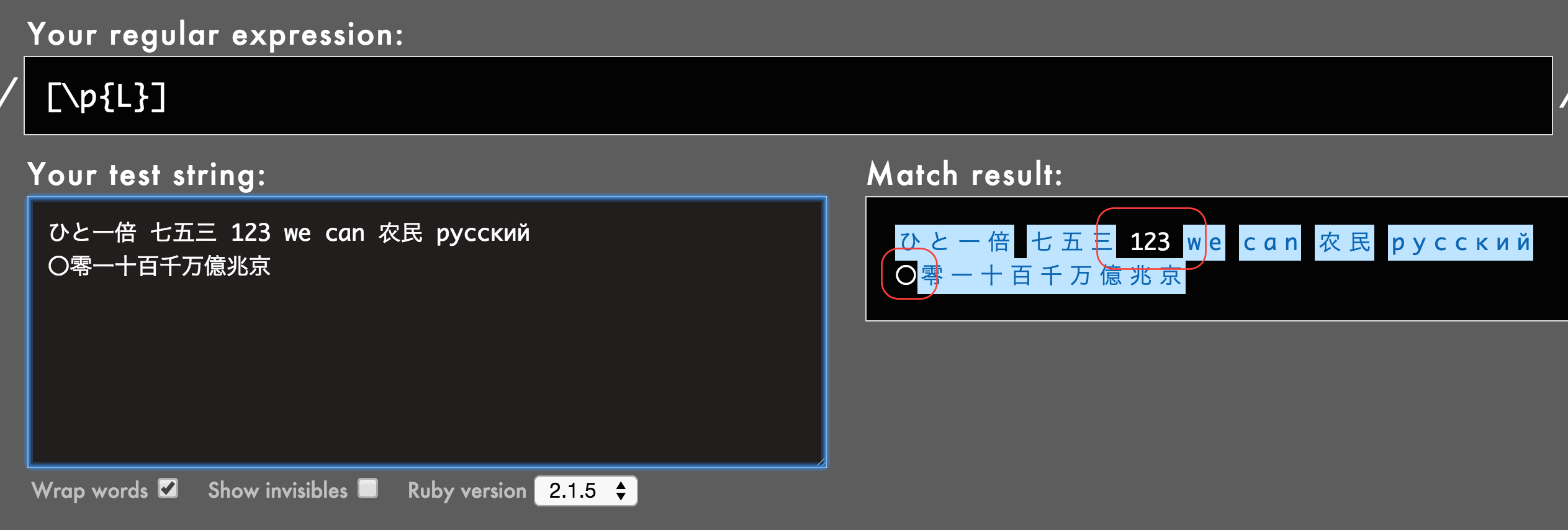
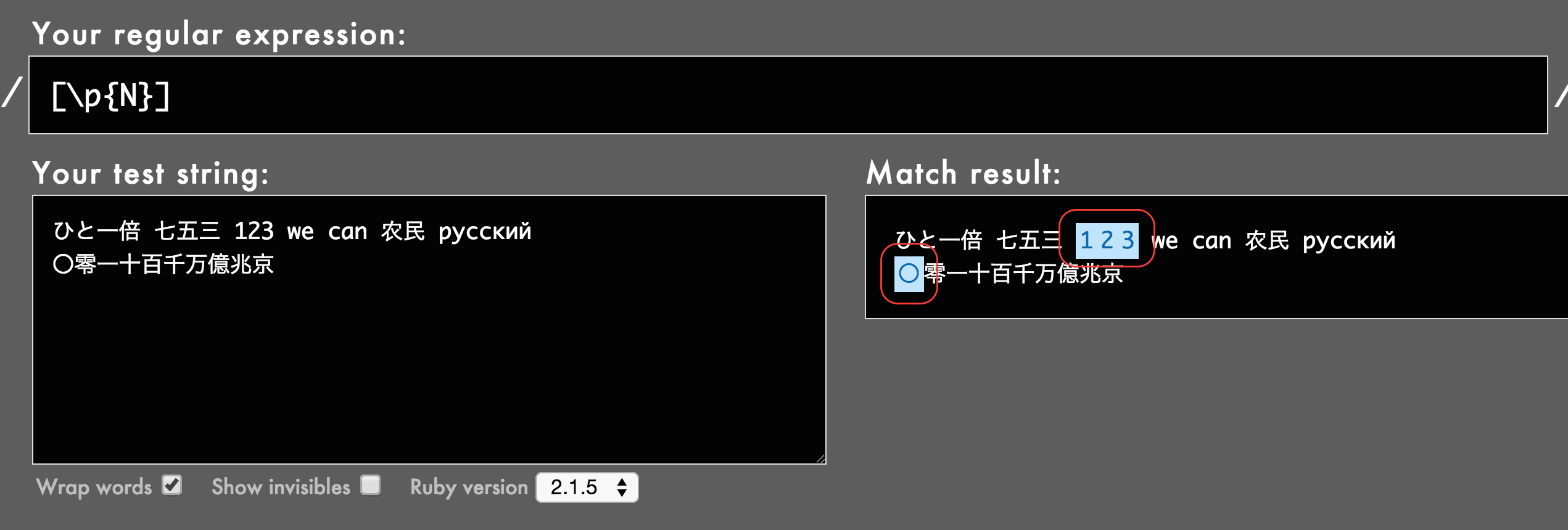
やってみると、漢数字は「文字」を表す[\p{L}]にマッチし、「数字」を表す[\p{N}]にはマッチしていません。普通に考えてこうするしかないでしょうね。
が、見てお分かりのとおり、ゼロを表す〇だけは数字として認識されています。要注意です。そもそも〇は漢字なのか数字なのかということが微妙ですが。
意外なものが数字として扱われる
冒頭のリンクをクリックしてNd、Nl、Noの文字の実例を見てビビビッと嫌な予感がした方もいらっしゃると思います。
そのとおり、日本人が日本のお客さんに頼まれて作るコードで使用する正規表現であれば、数字の表現はいつもの[0-9]とか[0123456789]みたいなのにしておくのがよいでしょう。数字とマッチする表現に[\p{N}]を使うと、マッチ範囲が恐ろしく広いので思わぬ動作をする可能性が高いです。
つまり、[0-9]と[\p{N}]は目的がまったく違うと考えるのがよろしいと思います。
(\dとかはどのぐらい普遍性があるのか知らないので、自分は[0-9]にしています。)
Ndだけでもアラビア数字(いわゆる[0-9]ではなく本当にアラビア語で使われている数字、微妙に形が違う)を始めとする世界のさまざまな言語の数字が含まれています。
さらに、数学で特別な意味に使うドイツ式数字「𝟘𝟙𝟚𝟛𝟜𝟝𝟞𝟟𝟠𝟡」やボールド、サンセリフなどの数字までわざわざコードとして用意されています。
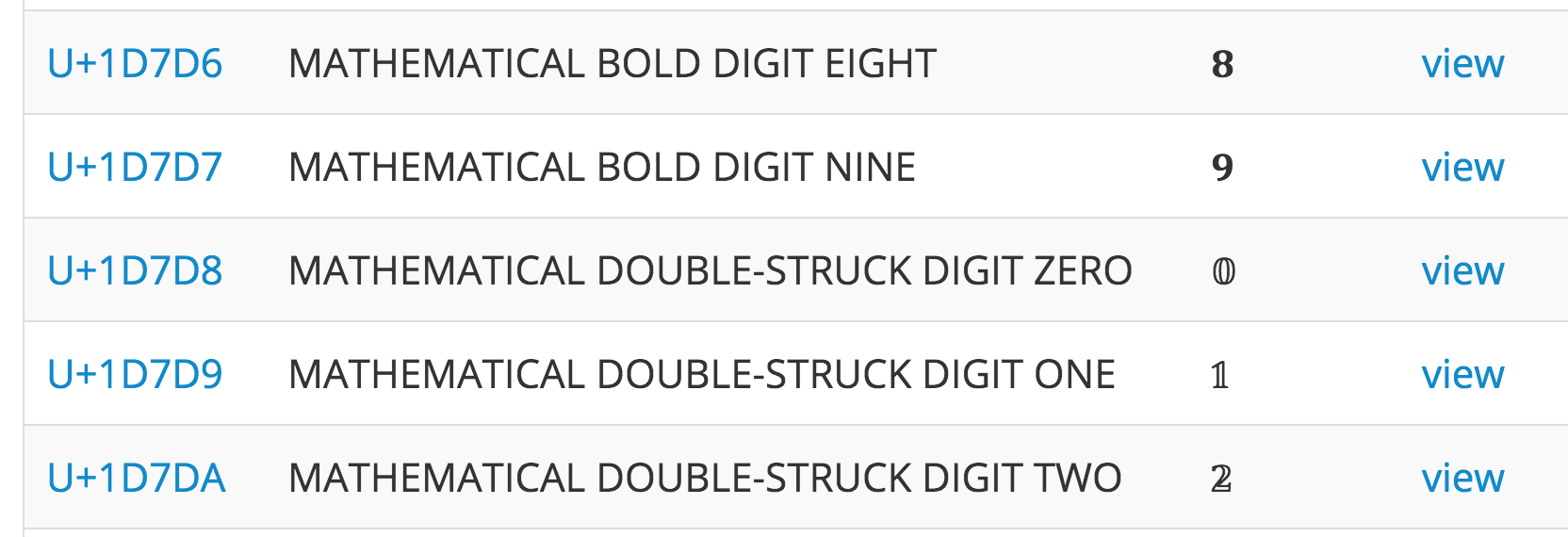
こういうのはレイアウト/レンダリング側で対応すべきことであって、文字コード体系側でやることではない気がして仕方がないのですが、何か事情があるのかもしれません。
続くNlにしても、数字なのか文字なのか、ネーミングからして怪しさが漂います。
ローマ数字の10や100や1000を表すⅭやⅮやⅯにわざわざコードを割り当てています。
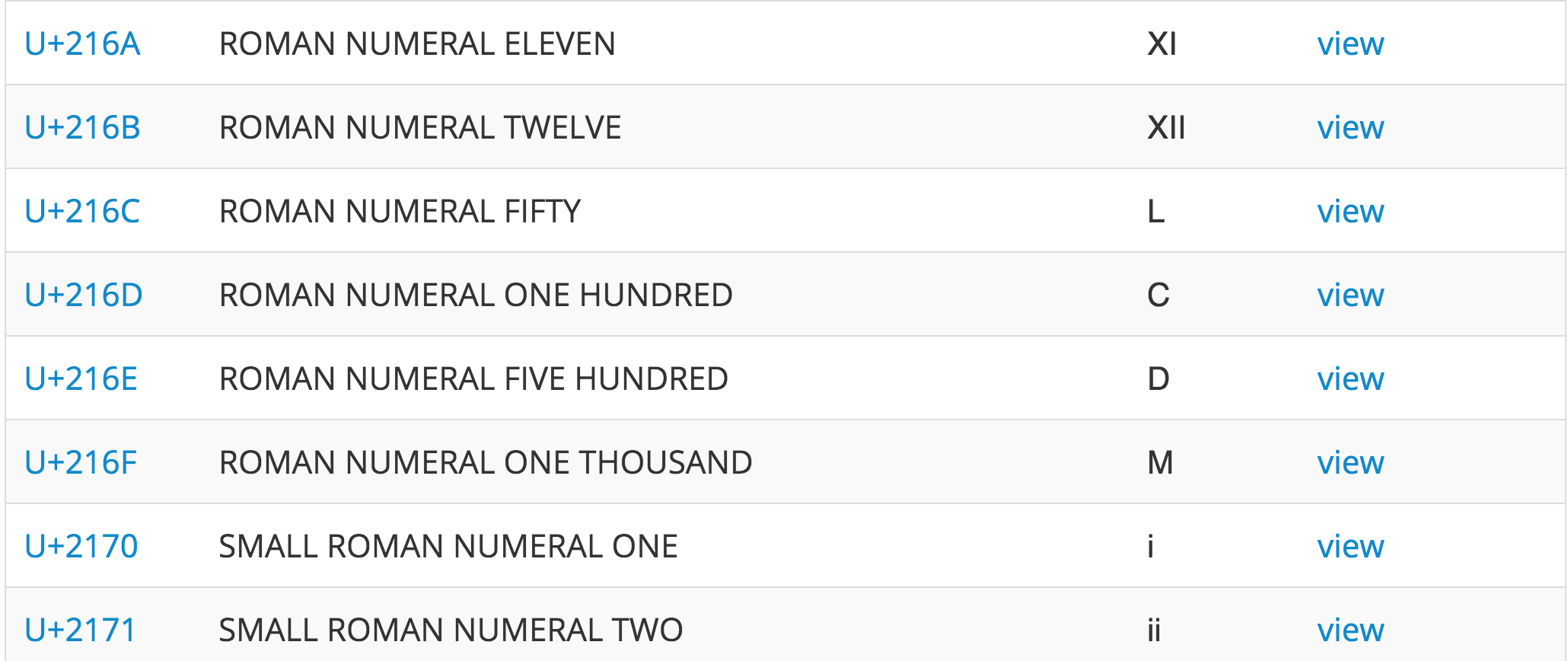
文字で数字の代用にするというのは古代ギリシャからローマにかけてずっとやってきたことなのである程度仕方がないとはいえ、わざわざコードをこしらえる意義がよくわかりません。
もっとも逆も真なりで、CJK統合漢字で中国・朝鮮・日本の漢字を一部で同一視したことで議論が巻き起こったりしています。詳しくは知りませんが。
それなら、漢字の「十百千万億兆」をNlにも含めて欲しいような気もします。しかし簡単な話ではなさそうです。
カテゴリはひとつのコードにひとつ
仕様をちゃんと探していませんが、これまで見た限りではUnicode文字コード体系で使用されているカテゴリは、1つのコードにつきひとつしか与えられていないようです。マルチカテゴリのコードは今のところ見当たりません。きっとそうであろうと仮定してひとまずメモします。
ひとつは、複数のカテゴリに属するコードを作らないことで、正規表現で利用しやすくする意図があるのだと思います。正規表現の中でUnicode文字プロパティのカテゴリを使用する場合、当然ながらなるべく余分なものは混入しないで欲しいはずです。「文字だけが欲しい」ときに「数字も文字だから」とマッチされては困ります。
もうひとつは、マルチカテゴリ化を行うとなるとカテゴリの割り当て作業が膨大になってしまうからではないでしょうか。作業のためには全言語でのチェックが必要になりますが、これはエンジニアだけで行える作業ではありません。国連の職員並に、きわめて多くの自然言語に精通した人物が必要です。
もしかすると水面下で進行中なのかもしれませんが、マルチカテゴリに変わったら変わったで非常に大きな影響が生じます。たぶん今更変えられない気がしてきました。既存のカテゴリを変更するのは無理でも、新しくカテゴリを追加するならいけるかもです。
追記
[0-9]は半角数字にマッチしますが、全角数字「0123456789」にはマッチしません。少なくともRuby + Onigmo では。http://rubular.com/r/YAfmbxtkmB
当然、否定形[^0-9]は全角数字にマッチします。
しかしたまたま知ったのですが、NSPredicate では否定の[^0-9]が全角数字にマッチしないのだそうです。ということはNSPredicateでは肯定の[0-9]は全角数字にマッチしてしまうのでしょう。自分で動かしてないのでわかりませんが。