##概要
・パーティションテーブルのうち、「分割テーブル」を作成
・DDLの「CREATE TABLE」ステートメントを使用し、「PARTITION BY」句で分割カラムを指定する方法で作成
##分割テーブルとは
BigQueryでは、大規模テーブルを小さなセグメント(まとまり)に分割して管理できます。
テーブルとしては1つでも、内部的に分割しておくと、クエリで読み込むバイト数を減らし、コストを削減できます。
分割する方法は以下の3つ。
・日付別テーブル
・取り込み時間で分割されたテーブル
・分割テーブル
(違いはこちらの記事に詳しい。)
今回は、このうち「分割テーブル」を作成します。
3つのうち最も新しい機能で、
TIMESTAMP型もしくはDATE型のカラム(の内容)でパーティショニングを行います。
(参考→公式ドキュメント)
##今回のゴール
こちらのテーブルを作成することを目標とします。
日別キャンペーンへの参加状況
| id | cp | date |
|---|---|---|
| AAAA | 5%OFF | 2019-01-01 |
| BBBB | ポイント5倍 | 2019-01-01 |
| CCCC | 5%OFF | 2019-01-01 |
| AAAA | ポイント5倍 | 2019-02-28 |
| BBBB | 5%OFF | 2019-02-28 |
| CCCC | ポイント5倍 | 2019-02-28 |
「date」列をもとにパーティションを作成します。
→キャンペーンごとに参加者の一覧を追加更新しても、日付で分割して保持されるはずです。
##作成方法
大きく3つのフェーズで作成します。
① データを入れるハコ(空のテーブル)を作成
② データセットをアップロード
③ ②のデータセットを①のハコに入れる
https://cloud.google.com/bigquery/docs/creating-column-partitions?hl=ja
####① テーブル作成
CREATE TABLE ステートメントを使い、テーブルを作成します。
(参考→公式ドキュメント)
CREATE TABLE
hoghoge-bq.hogehoge-prj.t_cp_list
(
id,
cp,
date
)
PARTITION BY cp_start
;
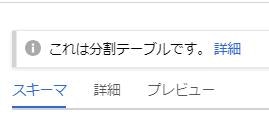
できたテーブルにはこのように注釈が付きます。
####② データセットをアップロード
今回は、下記の手順で行います。
- データセット(CSVファイル)をGoogle Storageに格納
- BigQueryにアップロード
(「wk_cp_list」と命名)
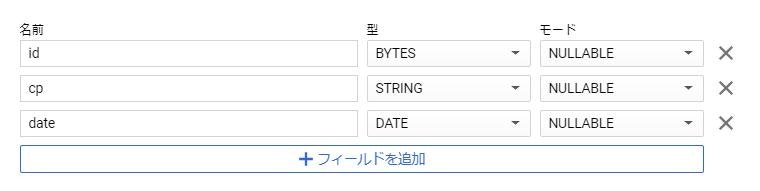
2.の際、自動で取り込むと「id」列がSTRING型ではなくBYTES型になってしまい
抵抗を試みたのですが、ダメでした。次のステップで型変換することにします。
####③ ②のデータセットを①のハコに入れる
INSERT文を使って格納します。ついでに「id」列をSTRING型に変換します。
INSERT into `hoghoge-bq.hogehoge-prj.t_cp_list` (id, cp, date)
select
TO_BASE64(id),
cp,
date
FROM `hoghoge-bq.hogehoge-prj.wk_cp_list`
これで、分割テーブルに中身が入りました。
更新作業は、②と③を繰り返すのみです。