こんにちは、Takaです。
今回は、簡単な自然言語処理を使って、ツイートから「いらすとや」さんの画像を表示させるアプリを作りました。
仕組みとしては
1.ツイートを収集
2.ツイートを形態素解析する
3.最も多かった単語で検索をする
4.検索した項目の一番初めの画像を表示する
感じです。
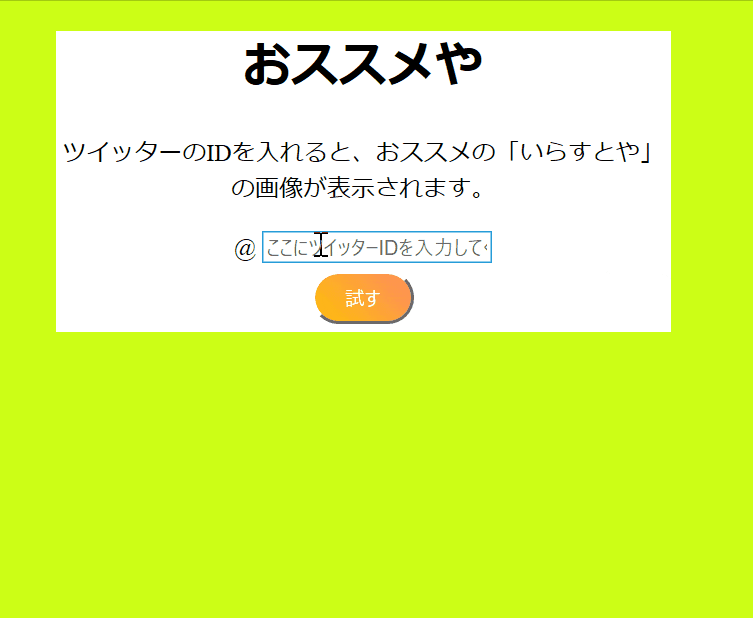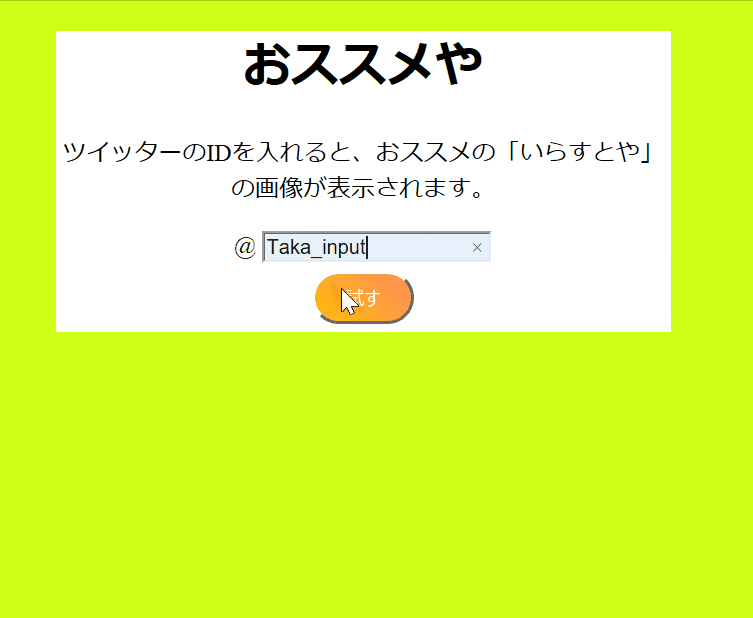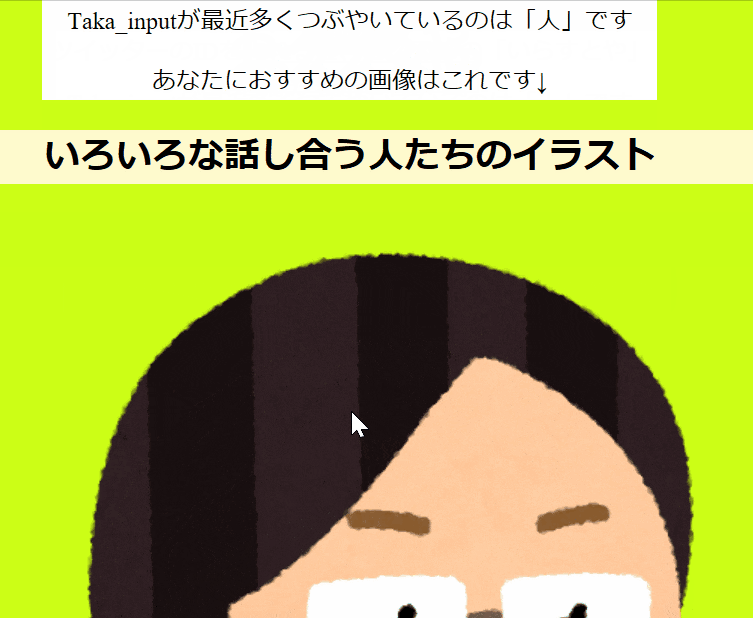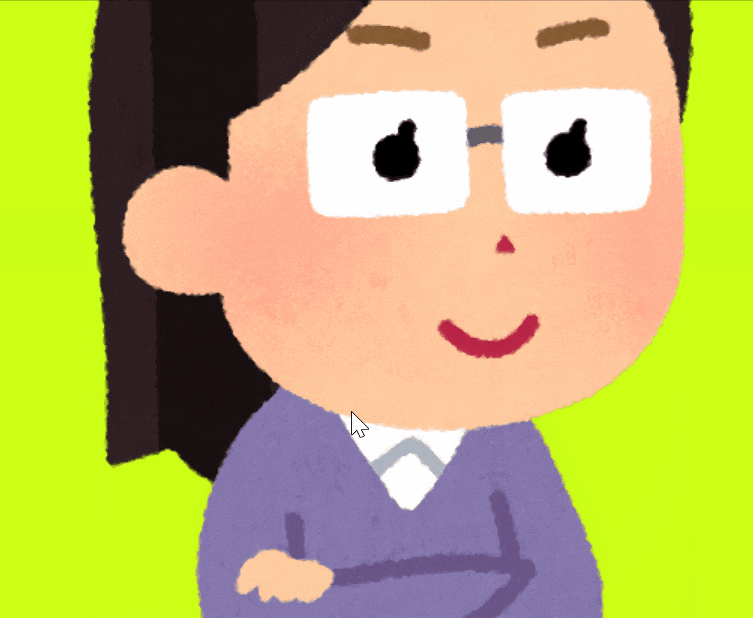
完成したアプリはこのようになります![]()
0.環境
Windows10
python 3.7.2
jupyter notebook 1.0.0
atom(Flask用エディター)
janome 0.3.7(自然言語処理用ライブラリ)
Flask 0.12.2 (アプリ作成)
1.ツイート収集
Twitterの情報を扱うにはTwitterAPIの認証をしなければいけません。
また、APIを扱うには以下の4つが必要になります。
・Consumer API key
・API Secret key
・Access token
・Access token secret
詳しい認証方法は以下のサイトを参照にしてください。
【2019年1月最新版】新しくなったTwitterのAPIの登録方法と使い方。Developer登録をしてAPI keyを取得するまでの手順を公開!RailsもPythonも対応可能!
(APIの取得方法は不定期で変わるので最新版を調べることをお勧めします)
また、パラメータ(コード上では__params__)の引数を変えることで、取得するツイートの数、ユーザーの指定など細かい設定を行うことが可能です。
詳しくはこちらを参照してください。
Twitter 開発者 ドキュメント日本語訳
以下のコードで最新20件のツイートを取得します。
from requests_oauthlib import OAuth1Session
import json
# TwitterAPIの認証情報
consumer_key = ""
consumer_secret = ""
access_token = ""
access_token_secret = ""
# APIの認証
twitter = OAuth1Session(consumer_key, consumer_secret, access_token, access_token_secret)
# 最新のタイムラインを取得する
url = "https://api.twitter.com/1.1/statuses/user_timeline.json"
# 取得するツイートの数:20,Rtは除く
params = {"screen_name":"適用するユーザーのID","count":20,"include_rts":False}
req = twitter.get(url, params=params)
if req.status_code == 200:
timeline = json.loads(req.text)
#格納用リスト
tweets = []
for tweet in timeline:
#リストに追加
tweets.append(tweet["text"])
else:
print("ERROR: %d" % req.status_code)
2.前処理
自然言語処理をするにあたって前処理が必要です。
ツイートにはノイズ(URL,記号,etc...)が存在します。これらは形態素解析する際に邪魔になるので削除したいです。
また、ストップワード(頻繁に出てくる言葉)も削除したいです。今回は名詞のみを取り出すコードにしたので、助詞などのストップワードは含まれないつもりでした。しかし、出力結果を見ると助詞らしきものが名詞と判断されているものもあったので、ここでは見つけたものを自分でリストにして削除しました。
そして、ツイートはカジュアルなものが多いのです。例えば、
「ー」を使って喜びを表しているつもりかもしれませんが、形態素解析をする上では邪魔以外の何物でもありません。 そこで、**NEologdnライブラリ**を用います。このライブラリは**文字の正規化**を行ってくれます。 上のツイートで試してみましょう。後期フル単 やったーーーーーーーーー!! わーーーーーーーーーい!!🙌2019年2月28日
import neologdn
tweet = neologdn.normalize("後期フル単\nやったーーーーーーーーー!!\nわーーーーーーーーーい!!🙌")
print(tweet)
後期フル単
やったー!!
わーい!!🙌
こんな感じになります。喜びがさっきより感じられなくなりましたね。
以上を踏まえて、前処理をする関数は以下のようにしました。
import re
import neologdn
def format_text(text):
text=re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text)#URL
text=re.sub(r'[!-~]', "", text)#半角記号,数字,英字
text=re.sub(r'[︰-@]', "", text)#全角記号
#文字を正規化
text = neologdn.normalize(text)
#大文字を小文字に変換
text = text.lower()
#ひらがなのストップワードリスト
hira_stop = ["の","こと","ん","さ","そ","これ","こ","ろ"]
for x in hira_stop:
text = re.sub(x,"",text)
return text
3.形態素解析
いよいよ自然言語処理に入ります。使ったライブラリはjanomeです。
まず、先ほど取り出したツイートを1つの文字列データにし、前処理を行います。
後に、janomeに備わっているCount機能を使い、名詞だけを取り出してトップ5まで取り出すことにします。
janomeのCount機能に関しては開発者さんが詳しく説明しているので以下のURLを参照にしてみてください。
[janome 開発日誌] 速くなってワードカウント機能が追加された janome 0.3.5 をリリースしました
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.tokenfilter import *
string = "\n".join(tweets) #1つの文字列データにする
# 前処理実行
normalized_string = format_text(string)
# POSKeepFilter - 引数に指定した品詞を取り出す
# tokenCountFiletr - トークンの出現回数をカウントする
token_filters = [POSKeepFilter('名詞'), TokenCountFilter()]
# Analyzerオブジェクトを生成
a = Analyzer(token_filters=token_filters)
# カウントを実行
words = list(a.analyze(normalized_string))
# top5を取り出す
top_pair = sorted(words, key = lambda x:x[1], reverse=True)[:5] #dict
# 名詞のみ取り出す
top_words = list(map(lambda x:x[0], top_pairs))
4.スクレイピング
次に取り出した名詞を使って「いらすとや」の検索をかけ、一番上にあるリンクの画像を表示させます。
このコードを作るにあたってこちらの記事を大変参考にさせていただきました。
ありがとうございます![]()
「いらすとや」の画像をスクレイピングで自動収集してみた
from bs4 import BeautifulSoup
import requests
# 出現頻度が最も高い単語
top_word = top_words[0]
linkData = []
url = "https://www.irasutoya.com/search?q="
# top_wordで検索
response = requests.get(url+top_word)
soup = BeautifulSoup(response.text, "lxml")
links = soup.select("a")
for link in links:
#aタグにある全てのhref
href = link.get("href")
#取得したリンクが画像リンクかどうか
if re.search('irasutoya.*blog-post.*html$',href):
#取得したリンクがlinkData[]にないか確認
if not href in linkData:
linkData.append(href)
# 画像リンクを取得
imageLinks = []
for link in linkData:
res = requests.get(link)
soup = BeautifulSoup(res.text, "lxml")
links = soup.select(".separator > a")
for a in links:
imageLink = a.get('href')
imageLinks.append(imageLink)
# 一番初めの画像を取り出す
img_1 = imageLinks[0]
5.Flaskで書く
以上のコードをFlaskを使って実行できるように修正します。
今までのコードはJupyter Notebookを使っていたのですが、Flaskを使うと正常に作動しなかったため、ここではテキストエディタのAtomを使いました。
FlaskについてはAI AcademyさんのサイトとDaiさんのNoteを参考にしました。
・AI Academy:Webアプリケーション開発編
・Flaskチュートリアル - Pythonでツイッターの分析ツールを作ってディプロイしよう!(動画つき!)-
初めに、Flask用にFlask_appというディレクトリを作り、そこにファイルを保存していくことにします。
最終的なディレクトリはこのようになっています。
flask_app
├ main.py
├ config.py
└ templates
└ index.html
config.pyはAPIのKeyを保存したものです。
CONFIG = {
"CONSUMER_KEY":"",
"CONSUMER_SECRET":"",
"ACCESS_TOKEN":"",
"ACCESS_TOKEN_SECRET":""
}
次に、templatesディレクトリですが、ここにはhtmlファイルを保存します。
Flaskのrender_template関数を使うとtemplatesディレクトリに入っているhtmlファイルをアプリとして表示させ、またそのファイルに値を入れることができます。
ここで重要なのはrender_templateはtemplatesという名前のディレクトリでないとエラーになることです。あと、templatesのsを忘れないようにしてください!
templatesディレクトリのidex.htmlはこのようになっています。
※HTMLは勉強不足なのでかなり適当です※
<!DOCTYPE html>
<html lang="ja">
<head>
<title>おススメや</title>
<meta charset="utf-8">
<style type="text/css">
body{background-color:#CCFF16;
height: 200px;
}
.container{
text-align: center;
padding: 5px, 15px;
background-color: #fff;
margin: 0 auto;
width: 410px;
}
.btn{
margin:5px;
display: inline-block;
padding: 7px 20px;
border-radius: 25px;
text-decoration: none;
color: #FFF;
background-image: linear-gradient(45deg, #FFC107 0%, #ff8b5f 100%);
transition: .4s;
}
.btn:hover{
background-image: linear-gradient(45deg, #FFC107 0%, #f76a35 100%);
}
.image{
text-align: center;
}
.image h2{
background-color: #FFFACD;
padding: 5px, 15px;
}
</style>
</head>
<html>
<body>
<div class = "container">
<div class="row">
<div class=col-md-12>
<h1>おススメや</h1>
<p>ツイッターのIDを入れると、おススメの「いらすとや」の画像が表示されます。</p>
<form class="form-inline" method="post">
<div class="form-group">
<span class="input-group-addon">@</span>
<input id="user_id" name="user_id" placeholder="ここにツイッターIDを入力してください" type=text class="form-control">
{% if message %}
<p>{{message}}</p>
{% endif %}
</div>
</div>
<button type="submit" class="btn">試す</button>
</form>
{% if top_1 %}
<p>{{user_id}}が最近多くつぶやいているのは「{{top_1}}」です</p>
{% endif %}
{% if imageLink %}
<p>あなたにおすすめの画像はこれです↓</p>
{% endif %}
</div>
</div>
</div>
<div class=image>
{% if imageLink %}
<h2>{{title}}</h2>
<img src="{{imageLink}}"></img>
{% endif %}
</div>
</body>
</html>
次にFlaskの基本的な書き方ですが、先ほど述べた参考サイトに載っているので今回は省略します。
それでは、main.pyのコードをお見せします。
# Flaskのライブラリ
from flask import Flask, render_template, request
# API情報があるフォルダのimport
from config import CONFIG
# 自然言語処理用のライブラリ
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.tokenfilter import *
from requests_oauthlib import OAuth1Session
import json
import re
import neologdn
# スクレイピング用のライブラリ
from bs4 import BeautifulSoup
import requests
consumer_key = CONFIG["CONSUMER_KEY"]
consumer_secret = CONFIG["CONSUMER_SECRET"]
access_token = CONFIG["ACCESS_TOKEN"]
access_token_secret = CONFIG["ACCESS_TOKEN_SECRET"]
twitter = OAuth1Session(consumer_key, consumer_secret, access_token, access_token_secret)
url = "https://api.twitter.com/1.1/statuses/user_timeline.json"
# インスタンス作成
app = Flask(__name__)
# ルーティング
@app.route("/", methods=["GET", "POST"])
def index():
mg=[]
if request.method=="POST":
user_id = request.form["user_id"]
print("user_id: ",user_id)
twts = tweet(user_id)
#存在しないアカウント
if twts == 404:
message = "このアカウントは存在しません"
return render_template("index.html",message=message)
#鍵垢
elif twts == 401:
message = "アカウントの鍵を外してから試してください"
return render_template("index.html",message=message)
#IDの入れ忘れ
elif not user_id or " " in user_id :
message = "IDが入力されていません"
return render_template("index.html",message=message)
else:
t_words = nlp(twts)
n = 0
most_word = t_words[n]
lnkData = scraping(most_word)
imglnk = img(lnkData)
ttl = title(lnkData)
while len(imglnk) == 7:
n += 1
most_word = t_words[n]
lnkData = scraping(most_word)
imglnk = img(lnkData)
ttl = title(lnkData)
message = ""
return render_template("index.html",imageLink=imglnk[0],top_1=most_word,message=message,user_id=user_id,title=ttl[0])
else:
mg.append("入力内容が間違っています")
return render_template("index.html")
# user_idを取得しツイートを取得
def tweet(user_id):
tweets=[]
params = {"screen_name":user_id,"count":30,"include_rts":False}
req = twitter.get(url, params=params)
if tweets:
tweets = []
else:
tweets = []
if req.status_code == 200:
timeline = json.loads(req.text)
for tweet in timeline:
tweets.append(tweet["text"])
return tweets
else:
print("ERROR: %d" % req.status_code)
return req.status_code
# 自然言語処理
def nlp(tweets):
string = "\n".join(tweets)
def format_text(text):
text=re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text)
text=re.sub(r'[!-~]', "", text)
text=re.sub(r'[︰-@]', "", text)
text = neologdn.normalize(text)
text = text.lower()
hira_stop = ["の","こと","ん","さ","そ","これ","こ","ろ"]
for x in hira_stop:
text = re.sub(x,"",text)
return text
normalized_string = format_text(string)
token_filters = [POSKeepFilter('名詞'), TokenCountFilter()]
a = Analyzer(token_filters=token_filters)
words = list(a.analyze(normalized_string))
top_pairs = sorted(words,key=lambda x:x[1], reverse=True)[:5]
top_words = list(map(lambda x:x[0], top_pairs))
return top_words
# tp_wordを受け取りサイトのリンクデータを格納する関数
def scraping(tp_word):
linkData = []
url = "https://www.irasutoya.com/search?q="
response = requests.get(url+tp_word)
soup = BeautifulSoup(response.text, "lxml")
links = soup.select("a")
for link in links:
href = link.get("href")
if re.search('irasutoya.*blog-post.*html$',href):
if not href in linkData:
linkData.append(href)
return linkData
# 画像のリンクをリストで返す
def img(linkData):
imageLinks = []
for link in linkData:
res = requests.get(link)
soup = BeautifulSoup(res.text, "lxml")
links = soup.select(".separator > a")
for a in links:
imageLink = a.get('href')
imageLinks.append(imageLink)
return imageLinks
# 画像のタイトルをリストで返す
def title(linkData):
titles = []
for link in linkData:
res = requests.get(link)
soup = BeautifulSoup(res.text, "lxml")
h2_links = soup.select("#post > div.title > h2")
for link in h2_links:
title = link.text
title = re.sub("\n", "", title)
titles.append(title)
return titles
app.run(port=12344, debug=False)
一つ一つの関数の内容自体に大きな変化はないのですが、細かいところをFlaskで作動させるために変えています。
まず、tweet関数ですが、HTML上で入力されたuser_idを受け取って、そのユーザーのツイートリスト(tweets)、またはステータスーコードを返します。
# @use_idのツイートをリストで返す
def tweet(user_id):
tweets=[]
params = {"screen_name":user_id,"count":30,"include_rts":False}
req = twitter.get(url, params=params)
#1
if tweets:
tweets = []
else:
tweets = []
if req.status_code == 200:
timeline = json.loads(req.text)
for tweet in timeline:
tweets.append(tweet["text"])
return tweets
#2
else:
print("ERROR: %d" % req.status_code)
return req.status_code
#1の部分ですが、ここではtweetsを初期化しています。これによって2回目にuser_idを入力した際にtweetsが空リストに更新されます。
#2の部分でステータスーコードを返しているのは、次に説明する関数でステータスーコードごとに表示させるメッセージを変えるためです。
次にindex関数をみてみましょう。
def index():
title=[]
if request.method=="POST":
user_id = request.form["user_id"] #1
twts = tweet(user_id)
#2
if twts == 404:
message = "このアカウントは存在しません"
return render_template("index.html",message=message)
elif twts == 401:
message = "アカウントの鍵を外してから試してください"
return render_template("index.html",message=message)
elif not user_id or " " in user_id:
message = "IDが入力されていません"
return render_template("index.html",message=message)
#3
else:
t_words = nlp(twts)
n = 0
most_word = t_words[n]
lnkData = scraping(most_word)
imglnk = img(lnkData)
ttl = title(lnkData)
while len(lnkData) == 7:
n += 1
most_word = t_words[n]
lnkData = scraping(most_word)
imglnk = img(lnkData)
ttl = title(lnkData)
message = ""
return render_template("index.html",imageLink=lnkData[0],top_1=most_word,message=message,title=ttl[0])
else:
title.append("入力内容が間違っています")
return render_template("index.html")
#1では、HTMLファイル上のform内にあるname=user_idを取得しています。
これによってHTMLファイル上でユーザーが入力された値を、Flask上で扱うことができます。
#2では、先ほどのtweet関数で返されたステータスコードごとにエラーメッセージを表示させるようにしています。また、user_idに何も入力されなかった場合の処理もしました。
#3は上から順に説明していきます。
関数__nlp()__は、先ほど 3.形態素解析 で説明したものを関数化したものです。
この関数ではツイートを形態素解析した後、その中のトップ5をリストにして返します。
t_words = nlp(twts)
次に、一番多かった単語をリストから取り出し、scraping関数に渡します。
scraping関数は 4.スクレイピング で説明したものの一部で、画像が表示されるサイトのリンクをリストで返します。
次にimg関数はそのサイトから画像リンクをリストで返し、title関数はその画像のタイトルを返します。
n = 0
most_word = t_words[n]
lnkData = scraping(most_word)
imglnk = img(lnkData)
ttl = title(lnkData)
最後に、検索した画像が「いらすとや」さんになかった時の処理を行います。
今回、その場合には次に多い単語で検索をするようにしました。
検索した画像が存在しないとき、必ず同じ画像リンクが7個リストの中に入っていることが分かったので、それを利用してwhileで処理しました。
while len(imglnk) == 7:
n += 1
most_word = t_words[n]
lnkData = scraping(most_word)
imglnk = img(lnkData)
ttl = title(lnkData)
message = ""
return render_template("index.html",imageLink=imglnk[0],top_1=most_word,message=message,user_id=user_id,title=ttl[0])
他の関数は、前述したものと全く同じなので説明は省きます。
まとめ
今回初めてローカルではありますが、アプリケーションを作成できました![]()
次はherokuなどでデプロイまでできたらいいなと思います!
その他参考文献
Pythonでサクッと簡単にTwitterAPIを叩いてみる
Pythonで画像スクレイピングをしよう
いらすとや
--書籍--
Pythonによるテキストマイニング入門
Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎