はじめに
過学習防止効果があるとされるLabel Smoothingだが、これに改良を加えたというOnline Label Smoothingの論文を見つけたので、tf.kerasで実装して評価して見た。
Online Label Smoothingとは
まず、Label Smoothingについて簡単に説明する。
画像分類のタスクにおいては、正解のラベルとしてOne Hotのベクトルを使用する。これは正解のクラスに対応する値だけが1.0でその他は0.0となったもの。
これは当然の様に思えるが、このまま学習させると「過学習を招く」、及び「モデルが自信を持ちすぎてしまう」といった問題があるとして、Inceptionモデルの論文で提案されたのが、Label Smoothingである。
具体的には、学習時のラベルとして「正解のクラスの値は少し割り引いて、減らした値は全てのクラスに均等に分割して加える」ということにする。割引の率は普通は0.1が使われる。差を均等に加えてあるので、正解と不正解のクラスの間の距離も全て均等になる。
TensorFlow/Kerasなら、CategoricalCrossentropyに引数として指定すれば、適用されるようになっている。
ここで、今回の記事のOnline Label Smoothingの説明に移る。
元論文は以下。
Delving Deep into Label Smoothing
論文の内容を(筆者の理解で)直感的に説明すると、以下の様になる。
- 正解と不正解のクラスの間の距離は均等ではなく、差をつけた方が合理的
- 正解と不正解の間の距離はクラスの類似度に応じて調整したい
- 学習中のPredictの結果を見れば、各クラスの類似度がわかる
学習中の結果をみて適応的に変更していくので"Online"が頭につく。
以下、論文中の説明図。
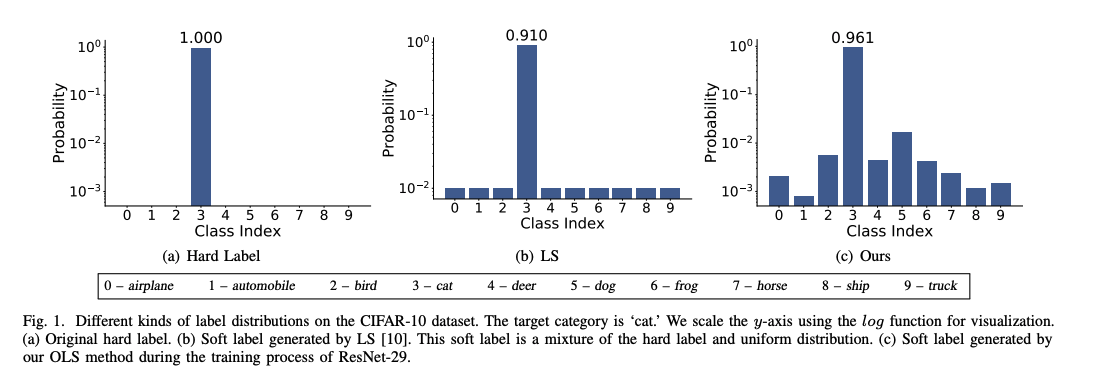
CIFAR10の"cat"に対応するラベルであるが、(c)のOnline Label Smoothingではその他の各ラベルで差がついている。この場合は、不正解のうちでも"dog"が最も近く、"automobile"が最も遠いものとして学習させる事になるが、これは人間の直感にも比較的沿うものになっていると思われる。
以下の図は実際に学習させたモデルでの最後から二番目のレイヤーの出力を視覚化したもの。
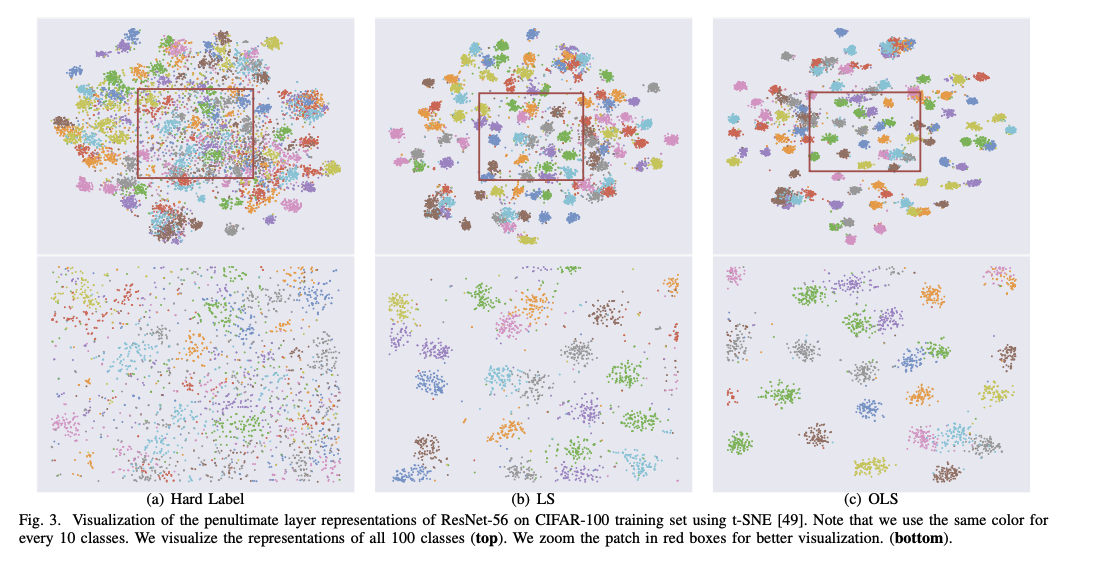
Label Smoothingを使うと各クラスでの境界がはっきりし、Online化でさらに明確になっている。直感的には分類のタスクにおいて好影響が期待できそうに見える。
Label SmoohingはKnowledge Distillationでは悪影響があると言う論文もあるが、この辺はクラスの類似度考慮したOnlineでは緩和されている可能性もあるかもしれない。
実装
記事作成時には公式の実装は公開されていないが、下記サイトで予定されているようだ。
https://github.com/zhangchbin/OnlineLabelSmooth
pytorchの非公式実装はここで紹介されているが、初期化等で若干論文とは違いがあるように思う。
この記事ではtf.kerasで筆者が実装したものを紹介する。状態を保存する処理は実装していないので、あくまで実験用のコードとして見てもらいたい。
Onlineと言うことで、ラベルの重みを徐々に学習していくような形になるが、実態としては以下のようにする。
- あるクラスの分類に正解した場合、その出力(softmax)全てを順次加算して保存していく。
- 1エポックごとに、保存&加算した値を正規化し、次のエポックではそのクラスのラベルとする。
- 加算してきたものはエポックごとにリセットし、ラベルが随時更新されていく。
以上だけでは、最初のエポックでラベルをつけられない事になるので、最初は"1/クラス数"の値で均等に初期化しておく。さらに、これでは正解不正解で差がないため学習の進みが遅いので、Hard Label(つまりOne Hot)とブレンド(論文では0.5が推奨されている)して差が必ずつくようにしている。
文章ではわかりづらいかもしれないので、実際のコードで確認してもらいたい。
class ols_categorical_crossentropy(tf.keras.losses.Loss):
def __init__(self, num_classes, steps_per_epoch, alpha=0.5, name="ols_categorical_crossentropy"):
super().__init__(name=name)
self.num_classes = num_classes
self.steps_per_epoch = steps_per_epoch
self.alpha = alpha
self.steps = tf.Variable(0, dtype=tf.int32, name="stepcounter")
self.training = tf.Variable(True, dtype=tf.bool, name="training")
self.S = tf.Variable(
tf.zeros(shape=tf.TensorShape([num_classes,num_classes]), dtype=tf.float32),
shape=tf.TensorShape([num_classes,num_classes]), dtype=tf.float32, name="S")
self.hard_label = tf.eye(num_classes, dtype=tf.float32)
self.soft_label = tf.Variable(
np.ones((num_classes, num_classes),dtype='float32')/num_classes,
shape=tf.TensorShape([num_classes,num_classes]), dtype=tf.float32, name="softlabel")
def set_training_phase(self, flag):
self.training.assign( flag )
def call(self, y_true, y_pred, **kwargs):
indices_pred = tf.math.argmax(y_pred,axis=1)
indices_true = tf.math.argmax(y_true,axis=1)
softlabel = self.alpha*self.hard_label + (1.0-self.alpha)*self.soft_label
y_true_soft = tf.gather(softlabel, indices_true)
y_true_soft = tf.squeeze(y_true_soft)
loss = tf.keras.losses.categorical_crossentropy(y_true_soft, y_pred)
def noop():
pass
def online():
def update():
# update steps
self.steps.assign_add(1)
# update S
correct_indices = tf.where( tf.math.equal(indices_pred, indices_true) )
correct_labels = tf.gather(indices_pred, correct_indices)
correct_p = tf.gather(y_pred, correct_indices)
correct_p = tf.squeeze( correct_p, axis=1)
S = tf.tensor_scatter_nd_add( self.S, correct_labels, correct_p )
self.S.assign(S)
def update_and_reset():
update()
# update softlabel
S = tf.distribute.get_replica_context().all_reduce('sum', self.S) # for TPU
norm = tf.math.reduce_sum( S, axis=1)
soft_label = tf.where(norm>0, tf.transpose(S)/norm, tf.transpose(self.soft_label))
self.soft_label.assign(tf.transpose(soft_label))
# reset
self.S.assign_sub(self.S)
self.steps.assign(0)
tf.cond(self.steps == self.steps_per_epoch, update_and_reset, update)
tf.cond(self.training==True, online, noop)
return loss
class OLSModel(tf.keras.models.Model):
def __init__(self, model, num_classes, steps_per_epoch, **kwargs):
self.lossobj = ols_categorical_crossentropy(num_classes, steps_per_epoch)
in_shape = model.input_shape[1:]
inputs = tf.keras.layers.Input(shape=in_shape)
super().__init__( inputs=inputs, outputs=model(inputs) , **kwargs)
def train_step(self, data):
self.lossobj.set_training_phase(True)
return super().train_step(data)
def test_step(self, data):
self.lossobj.set_training_phase(False)
return super().test_step(data)
def predict_step(self, data):
self.lossobj.set_training_phase(False)
return super().predict_step(data)
ラベル生成のための内部更新はtraining時のみにする必要があるので、Modelに内蔵する形で実装した。(別の実装方法もあるだろう)
エポックごとにラベルの重みを確定したいので、最初にエポックあたりのステップ数を渡す必要がある。
処理分岐の為にtf.condを使っているが、TPUだと分岐する場合は分岐後の処理を丸ごと呼び出す形にしないとエラーが出て実行できない様だ。
get_replica_context().all_reduceを使っているが、これをしないとTPUごとに違う値になってしまうため。
評価
WideResNet22-8でCIFAR10をTPUで学習させて評価した。
200エポックで3回実施した結果を小さい順に掲載。(太字は他と比較した最高成績)
Hard Label(HL) / Label Smoothing(LS) / Online Label Smoothing(OLS)の他に、他の手法との比較のため、Dropoutを最終層の直前に入れたものと、CutMixでデータ拡張したものも追加した。
| Label | Augmentation | Dropout | Result(Low/Median/High) |
|:-:|:-:|:-:|:-:|:-:|:-:|
| HL | Cutout | 0.0 | 96.70/96.85/96.93 |
| LS | Cutout | 0.0 | 96.76/96.90/96.96 |
| OLS | Cutout | 0.0 | 96.93/96.94/96.97 |
| HL | Cutout | 0.25 | 96.91/96.96/97.03 |
| LS | Cutout | 0.25 | 96.81/96.84/96.92 |
| HL | Cutmix | 0.0 | 96.76/96.80/97.02 |
以下所見。
- 僅差ではあるが、 OLS>LS>HLという成績となった。
- Dropoutを入れただけの場合もOLSとほぼ同等かそれ以上の結果が得られた。
- こうなると、敢えてOLSを使用する必要があるかは微妙に見える。
- Dropoutではレートを適切に設定しなければならないので、その辺の調整が不要と言う点では利点はあるかもしれない。
- LSとDropoutを同時に適用すると、Dropout単体よりも成績が悪かった。
まとめ
Label Smoothingを使うと成績が若干上がることが実験でも確認できた。Online Label Smoothingを使うとさらに性能が上がったが、単純にLossを入れ替えればいいだけでは済まないので、その辺の手間を考えるとわざわざ使わなくてもよいのではないか、と言うのが正直なところ。PyTorchの場合はtf.kerasよりも自然に組み込めるはずなので、採用を検討しても良いかもしれない。