はじめに
2020年に発表された最適化手法であるSAMに注目している人はそれなりに多いはずだが、まだQiitaには使用レポート的な記事はないようなので、評価を行い記事にする。評価には自作のtf.keras移植版を使うので、そちらのコードも掲載し、簡単な説明も加える。
SAMとはなにか
発表論文はこちら。
Sharpness-Aware Minimization for Efficiently Improving Generalization
下記記事に詳しい解説あり。
SoTAを総なめ!衝撃のオプティマイザー「SAM」爆誕&解説!
簡単に手順を解説すると以下の通り。
- 勾配を計算
- 勾配のノルムを計算(全レイヤーまとめてスカラー値にする)
- 勾配の逆方向に重みをずらす(ずらす量は2で計算したスカラー値に反比例させる)
- ずらした重みで勾配を再計算
- ずらした重みを元に戻す
- 4で計算した勾配を使って、Optimizer(アルゴリズムはなんでもいい)を使って、重みを決定
これは論文内では下記の図で説明されている。
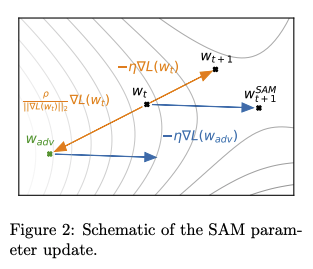
普通なら$W_{t}$での最初の勾配計算の後に$W_{t+1}$へ行くところを、逆方向の$W_{adv}$に移動して2回目の勾配計算を行い、$W_{t}$に戻してから2回目の勾配に従って$W_{t+1}^{SAM}$を更新値とする。
こうすることによって局所最適解を回避しながら重みを更新していく趣旨のようだ。
$W_{adv}$への移動量はハイパーパラメータ$\rho$として設定できる。論文では$\rho=0.05$が主に使われているが、別の数値が使われている記載もあるので、状況に応じてチューニングの余地があるようだ。
実装
Officialの実装はここ。これはJAXで実装されている。
Unofficialの実装として、Pytorch版とTensorFlow版がそれぞれ別の作者によって公開されている。
TensorFlow版はKerasでも一応使えるといえば使えるのだが、勾配計算を2度行うという特殊事情から、学習のループはTensorFlowの枠組みになっており、fitが使えない。
筆者は紹介記事を読んで即「面白そうだから実装してみよう」などと安易に思ったのだが、ここがネックで15分で諦めた。そのうち誰かうまいこと実装してくれるだろう、と傍観していたのだが、下記の記事を読んで比較的簡単に実装できることに気づいた。
TensorFlowでカスタム訓練ループをfitに組み込むための便利な書き方
記事ではGANでの実装例となっているが、カスタム訓練ループが必要と言う事情は同じである。
探したらTensorFlowのチュートリアルもあった。
結論から言うと、Optimizerとして実装するのではなく、train_stepを自前で実装した派生Modelクラスを作成する手法をとる。
と言うわけで、実装してみた物がこちら。
class SAMModel(tf.keras.models.Model):
def __init__(self, *args, rho=0.05, **kwargs):
super().__init__( *args, **kwargs)
self.rho = tf.constant(rho, dtype=tf.float32)
def train_step(self,data):
x, y = data
# 1st step
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
norm = tf.linalg.global_norm(gradients)
scale = self.rho / (norm + 1e-12)
e_w_list = []
for v, grad in zip(trainable_vars, gradients):
e_w = grad * scale
v.assign_add(e_w)
e_w_list.append(e_w)
# 2nd step
with tf.GradientTape() as tape:
y_pred_adv = self(x, training=True)
loss_adv = self.compiled_loss(y, y_pred_adv, regularization_losses=self.losses)
gradients_adv = tape.gradient(loss_adv, trainable_vars)
for v, e_w in zip(trainable_vars, e_w_list):
v.assign_sub(e_w)
# optimize
self.optimizer.apply_gradients(zip(gradients_adv, trainable_vars))
self.compiled_metrics.update_state(y, y_pred)
return {m.name: m.result() for m in self.metrics}
ノルムの計算部分はOfficialコードだと以下のようになっている。
gradient_norm = jnp.sqrt(sum(
[jnp.sum(jnp.square(e)) for e in jax.tree_util.tree_leaves(y)]))
ここのgradient_normの計算は、tensorflowだとtf.linalg.global_normを使えば同じ計算になるようなので、置き換えてある。
'self(x, training=True)'を2回よび出しているのでBatchNormalizarionの内部パラメーターが2回更新されてしまう気がするのだが、公式実装でも同じようなのであまり気にしないでもいいのだろう。この辺の影響はBatchNormalizationのmomentumである程度調節できるとも思われる。
使用法は簡単で、以下のようにModel作成時に派生クラスを使うようにする。
if rho==0.0:
model = tf.keras.models.Model(inputs,x)
else:
model = SAMModel(inputs,x, rho=rho)
あるいは、こんな感じでも使える。
inputs = tf.keras.layers.Input(shape=(32,32,3))
model = SAMModel(inputs, base_model(inputs), rho=0.05)
評価
WideResNetのCIFAR10認識率で評価を行った。
各種設定は論文と極力合わせるように努力した。パラメータの詳細についてはコードを参照してもらえればわかるので省略。
論文ではWRN-28-10だが、時短のためここではWRN-22-8で行う。一概にWideResNetといっても色々実装の仕方があるようだが、公式実装のモデルをできるだけ再現するようにしてある。
論文に掲載されているエラー率の結果はこちら。
| Model | Augmentation | SAM | SGD |
|---|---|---|---|
| WRN-28-10 | Basic | 2.7 | 3.5 |
| WRN-28-10 | Cutout | 2.3 | 2.6 |
SAMはSGDと組み合わせて使用。SGDのパラメータは同じ。
これは200エポックでの結果だが、論文ではSAMが2回勾配を計算することを考慮して、200エポックと400エポックでの訓練を両方行い、良い方を結果として使っているようだ。
同様の実験を、今回自作した実装でGoogleColabのTPUを使って実験した結果がこちら。
| Model | Augmentation | SAM(200) | SGD(200) | SGD(400) |
|---|---|---|---|---|
| WRN-22-8 | Basic | 2.87 | 3.86 | 3.70 |
| WRN-22-8 | Cutout | 2.66 | 3.23 | 3.47 |
ここではSGDに関しては200と400エポックの両方の結果を掲載している。
公式実装ではNesterovを使っているようだが、実験では使用していない。
Basicの場合のSAMとSGDの学習推移を比較したグラフがこちら。
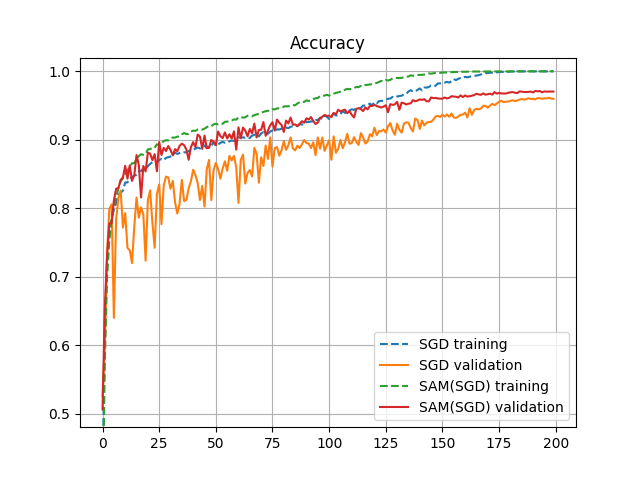
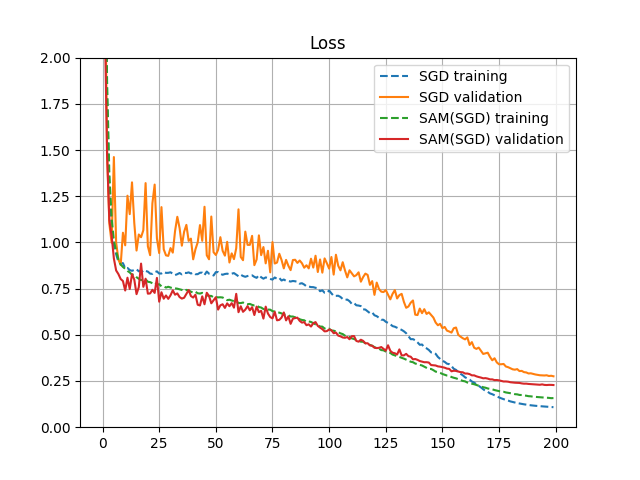
以下、所見。
- SAMを使用すると普通のSGDに比べエラー率が下がる。
- AugmentionがBasicの場合の方が性能が大きく向上する。
- AugmentionがCutoutとBasic間でSAMの結果を比較すると、Cutoutしてもあまり向上がみられない。SAMが優秀な過学習抑制の効果を持っているため、Cutoutの効果を発揮する余地が比較的小さくなった結果と考えられる。
- SAMを使用した方がグラフの変動幅が小さく、安定して学習が進んでいるように見える。
- 学習曲線だけ見るとSAMの方が速く学習が進んでいるが、勾配計算が2回入るため、時間的に必ずしも速いわけではない。
- 今回の実験では、SAMを使うとトータルで約1.5倍に学習時間が増えた。この倍率はトレーニングのデータ数とテストのデータ数の割合などで変わってくるので、一概にどの程度とは言えない。
実験用のコードは以下にある。
Google Colab Notebook
まとめ
- SAMをtf.kerasで使用できる実装を行った
- Modelでのtrain_step実装という手法なので、既存のコードへの組み込みも容易
- Basic Augmentationの方が性能の伸び幅としては大きい
- なんらかの事情でデータ拡張が困難なタスクの方が、大きな恩恵が得られる可能性がある。
- 概ね論文で主張されているものに沿うような性能向上がみられたが、更なる検証は必要
- 実装の動作確認の意味もあったため、論文と同じような設定で実験したので、好結果は当然かもしれない。
追記:改良版とされるAdaptiveSAMの実装と実験の記事は以下のリンク。