はじめに
Sharpness-Aware Minimization(SAM)の派生版であるAdaptive Sharpness-Aware Minimization(ASAM)が発表されていることを知ったので、実装して評価してみる。
筆者によるSAMの記事の続編という意味合いがあるので、読者がSAMに関する基本的な情報を知っていること前提とした記事とする。
ASAMとは
発表論文はこちら。
公式実装(PyTorch実装)も公開されている。
論文による説明によると、SAMでは以下のような式のところを、
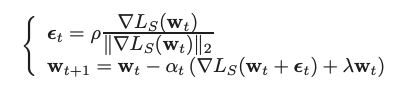
ASAMでは、以下のようにする。
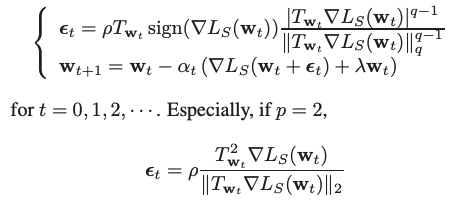
ここで、$ T_{w_t} $は以下のようになっている。
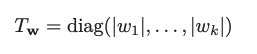
筆者の直観的な理解としては、SAMではパラメータは全て平等に扱うが、ASAMではパラメータの大きさで重み付けして、第一ステップにおいて「パラメータが大きい場合は大きく、小さい場合は小さく移動する」というところで"Adaptive"なのだと思われる。
効果を示すものとして、論文には以下の図がある。
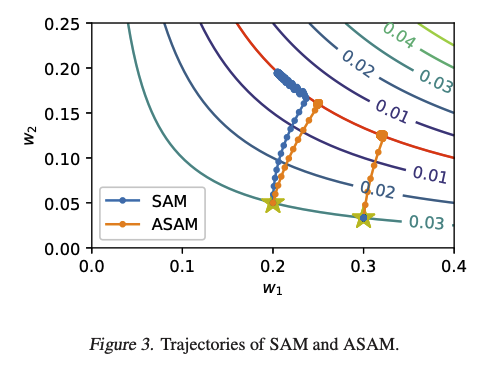
星印を開始点として赤線の位置に遷移する様子がプロットされている。$w_1$の方が$w_2$よりも大きい値の状態から開始する条件で、SAMよりもうまく収束する場合がある、ということを示しているようだ。
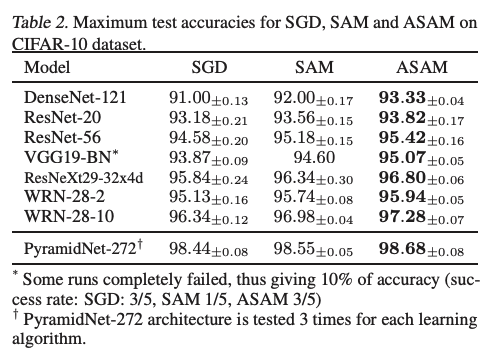
論文内でのCIFAR10の実験結果は以下の通りで、SAMに比べて性能向上できたとしている。
実装
PyTorch派の人は公式実装を確認すれば良いだろう。
筆者はtf.keras派なので、以下のようなコードで実装した。
class SAMModel(tf.keras.models.Model):
def __init__(self, *args, adaptive=False, rho=0.05, epsilon=1e-12, eta=0.01, **kwargs):
super().__init__( *args, **kwargs)
print( f'SAMModel adaptive={adaptive}, rho={rho}, epsilon={epsilon}, eta={eta}')
self.rho = tf.constant(rho, dtype=tf.float32)
self.eta = tf.constant(eta, dtype=tf.float32)
self.epsilon = tf.constant(epsilon, dtype=tf.float32)
self.adaptive = adaptive
def train_step(self,data):
x, y = data
# 1st step
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
t_w_list = [1.0] * len(gradients)
if self.adaptive: # for Adaptive SAM
for i in range(len(gradients)):
t_w = tf.math.abs(trainable_vars[i])+self.eta
t_w_list[i] = t_w
gradients[i] *= t_w
norm = tf.linalg.global_norm(gradients)
norm = tf.distribute.get_replica_context().all_reduce('MEAN', norm)
scale = self.rho / (norm + self.epsilon)
e_w_list = []
for v, grad, t_w in zip(trainable_vars, gradients, t_w_list):
e_w = grad * scale * t_w
v.assign_add(e_w)
e_w_list.append(e_w)
# 2nd step
with tf.GradientTape() as tape:
y_pred_adv = self(x, training=True)
loss_adv = self.compiled_loss(y, y_pred_adv, regularization_losses=self.losses)
gradients_adv = tape.gradient(loss_adv, trainable_vars)
for v, e_w in zip(trainable_vars, e_w_list):
v.assign_sub(e_w)
# optimize
self.optimizer.apply_gradients(zip(gradients_adv, trainable_vars))
self.compiled_metrics.update_state(y, y_pred)
return {m.name: m.result() for m in self.metrics}
SAMとASAMは'adaptive'で切り替えられる。
SAMではrho($\rho$)は0.05が推奨値だが、ASAMでは0.5や1.0あたりが推奨値のようだ。
eta($\eta$)というパラメータがあり、これを大きくすると重み付けの効果が低減する。ASAMをそのまま使うと安定性が損なわれる可能性があるのでバランスを取るためのパラメータのようだ。公式実装を参考にして、eta=0.01をデフォルトとした。
計算量が増えてはいるが、実際の学習時間はSAMとほとんど同じなので、気にする必要はないだろう。
実験
論文同様CIFAR10で実験した。
論文と全く同じ設定では面白くないので、 WRN-22-8のモデルを使い、データ拡張としてCutoutを加え、OptimizerはDecoupled Weight DecayであるSGDWを使っている。
etaの効果確認のため、0.01と0.0で両方実施してみた。
環境はGoogleColab上でTPU使用。
実験用コード
実験結果はこちら。(200エポックで3回実施)
| Optimizer | rho | eta | Accuracy(%) |
|---|---|---|---|
| SGDW | NA | NA | $96.99_{\pm0.08}$ |
| SAM(SGDW) | 0.05 | NA | $97.45_{\pm0.04}$ |
| ASAM(SGDW) | 0.5 | 0.01 | $97.54_{\pm0.01}$ |
| ASAM(SGDW) | 0.5 | 0.0 | $97.59_{\pm0.07}$ |
ASAMの方がSAMよりも認識率が若干良くなった。eta=0とするとさらに結果は良くなるが、ばらつきが大きくなる。最高成績はASAM(eta=0.0)時の97.66だった。
SAMとASAM(eta=0.01)のLossとAccuracyのグラフを載せる。
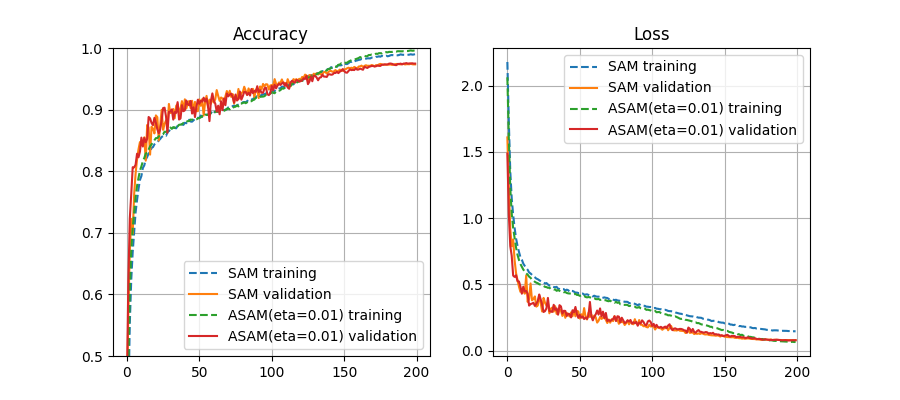
Accuracyのグラフはほとんど見分けがつかないが、Lossに関してはtrainingの値に差が見られ、ASAMでは終盤でかなり下がる。Lossが下がる分には良いようにも思われるが、validationの方は同様には下がらないので、場合によっては過学習を招く可能性があるように思われる。
以下、etaの効果を確認するグラフ。
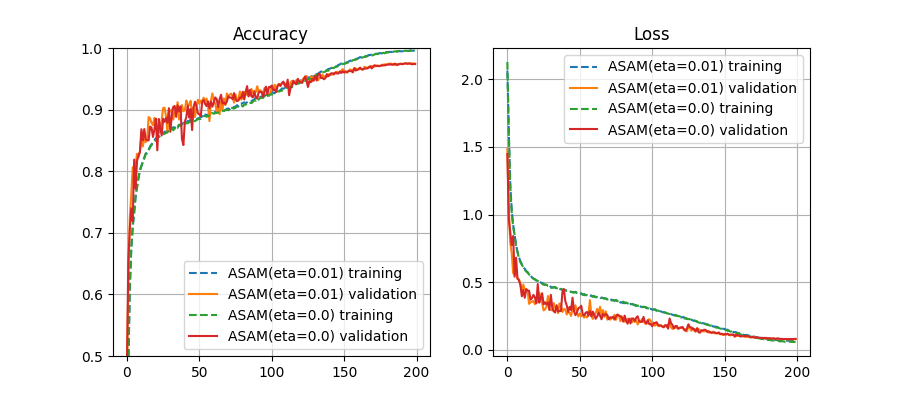
ほとんど違いがないように見えるが、eta=0.0の方がvalidationの振幅が激しく、やや安定性が低くなっているようだ。
まとめ
ASAMを実装して性能向上を確認した。
調整すべきパラメータが増え、安定性や過学習への不安がマイナス材料ではあるが、うまくいくとSAM以上の性能が出るので検討の価値はあるだろう。
ちなみに、SAM系では Efficient Sharpness Aware Minimization (ESAM)というのも発表されているので、気になる方は確認されるといいだろう。こちらは時間短縮がされている上に同等以上の認識率が出ると主張されているようだ。