はじめに
最近流行りのChatGPTについて学習する中で、何やらLangChainという便利なライブラリがあることを知り、ネット記事や書籍を参考に勉強がてらチャットボットアプリを開発してみました。
※OpenAI, GitHub, Streamlitの登録が必要です。登録方法は各ネット記事等をご参照下さい。
具体的な内容
まず成果物と全体のコードを記載します。
成果物
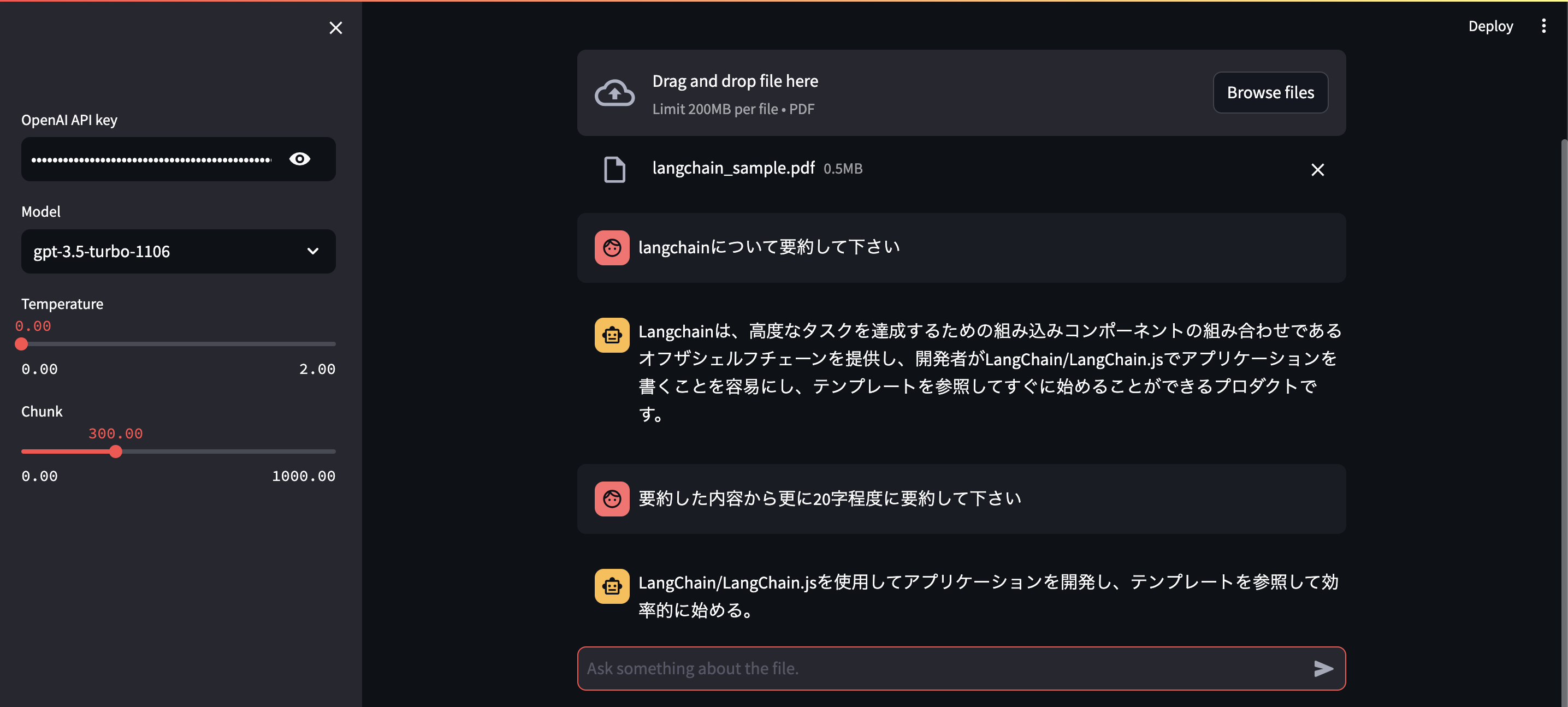
全体のコード
app.py
import os
import tempfile # PDFアップロードの際に必要
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
# from langchain.callbacks.base import BaseCallbackHandler
import streamlit as st
folder_name = "./.data"
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# ストリーム表示
# class StreamCallbackHandler(BaseCallbackHandler):
# def __init__(self):
# self.tokens_area = st.empty()
# self.tokens_stream = ""
# def on_llm_new_token(self, token, **kwargs):
# self.tokens_stream += token
# self.tokens_area.markdown(self.tokens_stream)
# UI周り
st.title("QA")
uploaded_file = st.file_uploader("Upload a file after paste OpenAI API key", type="pdf")
with st.sidebar:
user_api_key = st.text_input(
label="OpenAI API key",
placeholder="Paste your openAI API key",
type="password"
)
os.environ['OPENAI_API_KEY'] = user_api_key
select_model = st.selectbox("Model", ["gpt-3.5-turbo-1106", "gpt-4-1106-preview",])
select_temperature = st.slider("Temperature", min_value=0.0, max_value=2.0, value=0.0, step=0.1,)
select_chunk_size = st.slider("Chunk", min_value=0.0, max_value=1000.0, value=300.0, step=10.0,)
if uploaded_file:
# 一時ファイルにPDFを書き込みバスを取得
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_file_path = tmp_file.name
loader = PyMuPDFLoader(file_path=tmp_file_path)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = select_chunk_size,
chunk_overlap = 100,
length_function = len,
)
data = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002",
)
database = Chroma(
persist_directory="./.data",
embedding_function=embeddings,
)
database.add_documents(data)
chat = ChatOpenAI(
model=select_model,
temperature=select_temperature,
# streaming=True,
)
# retrieverに変換(検索、プロンプトの構築)
retriever = database.as_retriever()
# 会話履歴を初期化
if "memory" not in st.session_state:
st.session_state.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
)
memory = st.session_state.memory
chain = ConversationalRetrievalChain.from_llm(
llm=chat,
retriever=retriever,
memory=memory,
)
# UI用の会話履歴を初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# UI用の会話履歴を表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# UI周り
prompt = st.chat_input("Ask something about the file.")
if prompt:
# UI用の会話履歴に追加
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = chain(
{"question": prompt},
# callbacks=[StreamCallbackHandler()], # ストリーム表示
)
st.markdown(response["answer"])
# UI用の会話履歴に追加
st.session_state.messages.append({"role": "assistant", "content": response["answer"]})
# メモリの内容をターミナルで確認
print(memory)
次にコードの中身です。気になった点や苦労した点を中心に記載します。
必要なライブラリのインストール
- openai==1.5.0, langchain==0.0.350, PyMuPDF==1.23.7, tiktoken==0.5.2, chromadb==0.4.20, streamlit==1.29.0で動作確認しました。
- pymupdf, tiktoken, chromadbを使用しました。他のLoaderやベクトルDBに入れ替えも可能かと思います。
pip install openai langchain pymupdf tiktoken chromadb streamlit
UI周り
- UIの大半の実装はこれだけです。凄いです。サイドバーでOpenAI APIキー, Model, Temperature, Chunkの設定を可能にします。
- 「st.file_uploader」を「with st.sidebar:」内に記載するとPDFアップロードボタンをサイドバーに配置することも出来ます。
app.py
# UI周り
st.title("QA")
uploaded_file = st.file_uploader("Upload a file after paste OpenAI API key", type="pdf")
with st.sidebar:
user_api_key = st.text_input(
label="OpenAI API key",
placeholder="Paste your openAI API key",
type="password"
)
os.environ['OPENAI_API_KEY'] = user_api_key
select_model = st.selectbox("Model", ["gpt-3.5-turbo-1106", "gpt-4-1106-preview",])
select_temperature = st.slider("Temperature", min_value=0.0, max_value=2.0, value=0.0, step=0.1,)
select_chunk_size = st.slider("Chunk", min_value=0.0, max_value=1000.0, value=300.0, step=10.0,)
PDFの読み取り
- PDFを読み取る前にtempfileに入れてパスを取得します。この辺りは色々なやり方がありそうです。
app.py
# 一時ファイルにPDFを書き込みバスを取得
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_file_path = tmp_file.name
loader = PyMuPDFLoader(file_path=tmp_file_path)
documents = loader.load()
会話履歴の初期化
- 会話履歴を保持するために「ConversationBufferMemory」と「ConversationalRetrievalChain」を使います。似たような機能で「RetrievalQA」がありますが、こちらでは会話履歴を保持することが出来ません。
app.py
# 会話履歴を初期化
if "memory" not in st.session_state:
st.session_state.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
)
memory = st.session_state.memory
chain = ConversationalRetrievalChain.from_llm(
llm=chat,
retriever=retriever,
memory=memory,
)
- 会話履歴はHumanMessageとAIMessageのタイトルでリストの中に辞書のような形式で保存されます(コード最下部のprint文でメモリの内容をターミナルに表示しています)。

UI用の会話履歴の初期化
- これらはUI用に会話履歴を保持するための実装となり、「ConversationBufferMemory」や「ConversationalRetrievalChain」とは関係がないので注意です。
app.py
# UI用の会話履歴を初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# UI用の会話履歴を表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# --------------------------------------------------------------------------
# UI用の会話履歴に追加
st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.messages.append({"role": "assistant", "content": response["answer"]})
ストリーム表示(今後のTODO)
- 回答をストリーム表示するためにCallbacksを使いました。しかし、回答に質問が含まれる現象が起きるため、やむなくコメントアウトをしています。全ての実装でここが一番苦労しており、本質的ではないのですが、解決に至っておりません(CallbacksのCallbackManagerやConversationalRetrievalChainのcondence_question_llm等試しましたが上手くいかず、、)。どなたか解決方法がわかる方がいらっしゃいましたらアドバイスをいただけますと幸いです・・・!!
app.py
# from langchain.callbacks.base import BaseCallbackHandler
# --------------------------------------------------------------------------
# ストリーム表示
# class StreamCallbackHandler(BaseCallbackHandler):
# def __init__(self):
# self.tokens_area = st.empty()
# self.tokens_stream = ""
# def on_llm_new_token(self, token, **kwargs):
# self.tokens_stream += token
# self.tokens_area.markdown(self.tokens_stream)
# --------------------------------------------------------------------------
chat = ChatOpenAI(
model=select_model,
temperature=select_temperature,
# streaming=True,
)
# --------------------------------------------------------------------------
response = chain(
{"question": prompt},
# callbacks=[StreamCallbackHandler()], # ストリーム表示
)
- 以下のように回答に質問が含まれてしまいます。なお、次の質問を入力すると解消されます(謎)。

ローカルでの実行
streamlit run app.py
Streamlitへデプロイ
- こちらの記事を参考にさせていただきました。【Python】Streamlit Sharingで簡単・爆速でWebページをデプロイする!
- また、Streamlitはテキストファイルを読み込んで必要なパッケージを自動でインストールするため、事前にインストールしたパッケージを「requirements.txt」に出力しておく必要があります。
requirements.txt
pip freeze > requirements.txt
まとめ
実装してみてどうだったか
- PDFの読み取りに苦労した
- 会話履歴の保持に苦労した
- ストリーム表示に苦労している(現在進行形)
- Streamlit最高!!フロントはほぼ実装要らずすごい
今後やってみたいこと
- 回答のストリーム表示
- PDFの読み取り方法のリファクタリング
- 会話履歴の削除や要約により長い会話履歴に対応する
- Agentsにより外部検索を取り入れる等、より柔軟な実装が可能か確認する
あとがき
最後までご覧いただきありがとうございました!!
少しでも良いと感じていただけましたらLGTMポチッとしていただけますと幸いです。
いつもQiitaを参考にしております、皆様良質な記事をありがとうございます!!
参考記事
ネット記事
- PDFアップロード等全体的な実装方法
- 会話履歴(メモリ機能)の実装方法
- ストリーム表示の実装方法
- Streamlitのデプロイ方法
- 公式Docs
- その他(Qiita記事の書き方)