概要
- 目的:数GB分の複数ファイルをS3から取得、Lambdaで1つのzipファイルにまとめる
- 環境:AWS Lambda, S3, Java8(どの言語でもできますが、サンプルの都合でJavaを使います)
- 実現方法:無圧縮zip, S3マルチパートアップロード機能
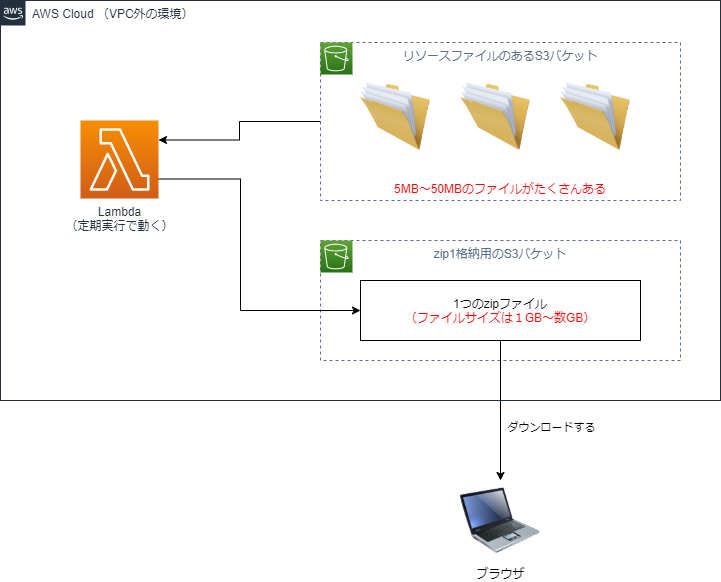
構成の概要

実現すること
こんな要件があったとします。
- 数GB分のファイルがS3に配置されていて、それを1つのzipファイルにまとめたい。
- 既存機能の都合でVPCやECSは使えないため、LambdaとS3だけで実現したい。
一見すると単純ですが、(普通は)実現できない構成です。
参考:要件の構成をSAMのYAMLファイルにしたもの(クリックで開きます)
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: SAM
Resources:
S3Bucket:
Type: "AWS::S3::Bucket"
Properties:
BucketName: !Sub "zip-lambda-create-${AWS::StackName}"
JavaLambdaFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: build/distributions/zip_s3_create.zip
Handler: zip_s3_create.Handler
Runtime: java8
Description: Java function
MemorySize: 512
Timeout: 900
Environment:
Variables:
S3_BUCKET: !Ref S3Bucket
Policies:
- S3CrudPolicy:
BucketName: !Ref S3Bucket
難しい理由
難しい理由は2つあります。
・ファイルが大きすぎること
→ Lambdaのストレージ(/tmpディレクトリ)には512MBの制限があります。
→ 数GBのzipを作ろうとすれば容量不足になります。
・LambdaがVPC外にあること
→ EFS(Lambdaのストレージを増やすサービス)を使えば、512MBの制限を超えるファイル操作ができます。
→ EFSを使うには条件があり、LambdaがVPCの中にあることが必要です。
ですので、このLambdaで数GBのzipファイルを作ることはできません。
それならどうするのか
Lambdaの中で作ることができないので、S3のマルチパートアップロード機能を使って、S3に無圧縮zipファイルを作らせます。
マルチパートアップロードって何?
複数のファイルをアップロードすることで、S3がそれぞれのファイルを結合して、一つのファイルを作る機能です。
「Hello,」と書いたテキストファイルと、「World」と書いたテキストファイルをそれぞれアップロードすると、S3に「Hello,World」と書いたテキストファイルが1つ保存されるようなイメージです。
どの言語でも実装できる機能ですが、AWSの公式ではJavaのサンプルが充実しています。
【マルチパートアップロードのコピー】
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/CopyingObjctsMPUapi.html
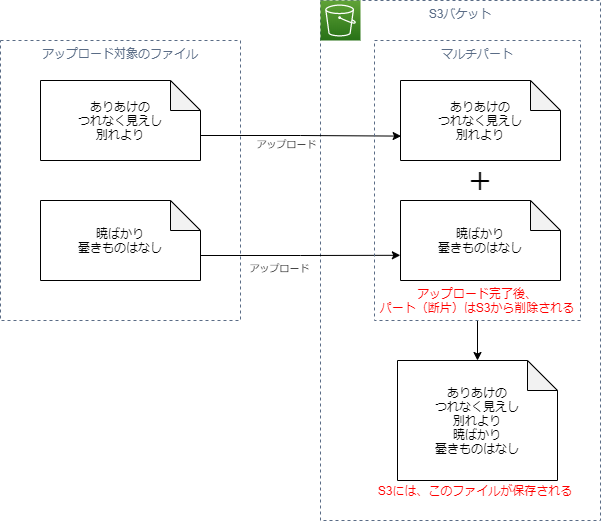
※「最後のパートを除いて、送信する一つのパートは5MB以上であること」の制限があるため、実際には「Hello,」ほど小さなファイルは送れません。
無圧縮zipって何?
圧縮をかけないzip形式は単純な構造をしていて、まとめる前のデータをそのまま並べたようなバイナリになります。
ただ、そのまま並べると展開した後のファイル名などがわからないので、「ローカルファイルヘッダ」として格納しています。
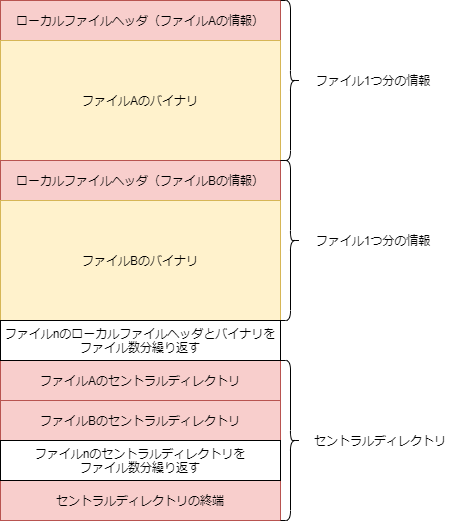
ローカルファイルヘッダには、いくつかの定数と、ファイルパス、ファイルの日時、CRC32、ファイルサイズを書き込みます。
セントラルディレクトリに書き込む情報は、ローカルファイルヘッダとほとんど同じです。
つまり、以下のような実装にすれば、S3のマルチパートアップロードで無圧縮zipを作ることができます。
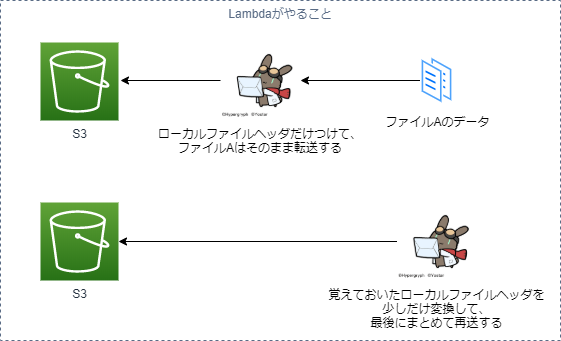
詳細なzipの仕様はここでは省略します。ソースコードにあるJavaのソースと、こちらをご参照ください。
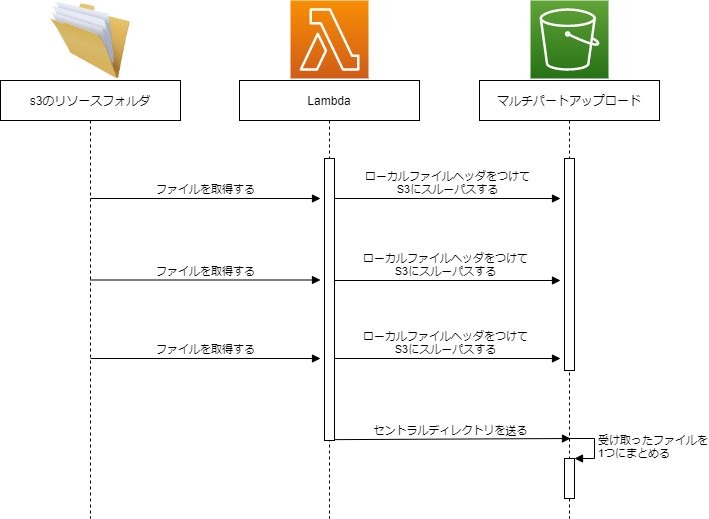
シーケンス
Lambdaの実装は、S3からファイルを取ってきて、少しだけ情報を足して、S3へのスルーパスを繰り返す形になります。
例えば3つのファイルを圧縮してzipにする処理をシーケンスとしてまとめ直すと、以下のようになります。
ソースコード
ソースコードはこちらです。※右向き三角をクリックすると開きます
CRC32はLambda内でも計算できるのですが、データ全体を読み込む必要があるため時間がかかります。
今回はあらかじめS3にアップロードする時点で計算しておいて、CRCをMetadataとして登録しています。
Lambdaのソースコード:実際の処理ロジック:Handler.java
public class Handler implements RequestHandler<Map<String, String>, String> {
// マルチパートアップロードの仕様で、(最後のパートを除いて)5MB未満のパートのアップロードはできない
private static long FILE_SIZE_5MB = 5L * 1024 * 1024;
// メタデータにCRC32の値を設定しておく(アップロード時に指定しておく)
private static String USER_METADATA_CRC32 = "crc32";
/**
* Lambdaのエントリポイント
*/
public String handleRequest(Map<String, String> event, Context context) {
// 出力するzipファイル名
String outputFileName = "export.zip";
// 並行処理するスレッド数(大きいほどメモリ量が大きくなるのでLambdaの設定に合わせる)
int pararelThreadCount = 5;
// 接続するバケット名
String s3BucketName = System.getenv("S3_BUCKET");
// リソースファイルのあるS3内のフォルダ名
String resourceFolderName = "resources";
try {
// 処理を実行する
execute(s3BucketName, resourceFolderName, outputFileName, pararelThreadCount);
// 処理成功をレスポンスとして返す
return new String("200 OK");
} catch (RuntimeException ex) {
// 例外をログ出力
ex.printStackTrace();
// サーバエラーをレスポンスとして返す
return new String("500 ERROR");
}
}
/**
* zip化処理の実行
*
* @param s3BucketName 接続するバケット名
* @param resourceFolderName 処理対象のフォルダパス
* @param outputFileName 出力するzipファイル名
* @param pararelThreadCount 並行処理するスレッド数
*/
public void execute(String s3BucketName, String resourceFolderName, String outputFileName, int pararelThreadCount) {
try {
// 並列実行のスレッドを管理する
ExecutorService executor = Executors.newFixedThreadPool(pararelThreadCount);
// S3への接続クライアントを取得(ローカルなら.awsの設定, クラウドならロール)から取得する
AmazonS3 client = AmazonS3ClientBuilder.defaultClient();
// アップロードするファイルにContent-Type : application/zipを設定する
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentType("application/zip");
// マルチパートアップロードを初期化
InitiateMultipartUploadRequest initRequest = new InitiateMultipartUploadRequest(s3BucketName,
outputFileName).withObjectMetadata(metadata);
InitiateMultipartUploadResult initResult = client.initiateMultipartUpload(initRequest);
// etagの一覧を格納する配列(マルチスレッドで格納するのでsynchronizedにしておく)
List<PartETag> etagList = Collections.synchronizedList(new ArrayList<>());
// S3にある対象ファイルを一覧で取得する
ListObjectsV2Result targetFileList = client.listObjectsV2(s3BucketName, resourceFolderName);
List<Future<Optional<ZipHeader>>> uploadResultList = targetFileList.getObjectSummaries().stream()
// 5MBに満たないファイルはzip格納の対象外とする
.filter(targetFile -> targetFile.getSize() >= FILE_SIZE_5MB)
// 5MB以上の全ての対象ファイルに対して、マルチスレッドでzip格納処理を適用する
.map(targetFile -> {
return executor.submit(() -> {
// 非同期処理の実行結果
ZipHeader header = null;
// 読み込みストリームを開く
S3Object object = client.getObject(targetFile.getBucketName(), targetFile.getKey());
// メタデータを参照する
ObjectMetadata meta = client.getObjectMetadata(targetFile.getBucketName(),
targetFile.getKey());
try (S3ObjectInputStream input = object.getObjectContent()) {
// オンメモリに書き込みストリームを用意する
try (ByteArrayOutputStream headerBytes = new ByteArrayOutputStream()) {
// ファイルヘッダを出力
header = new ZipHeader(targetFile.getKey(),
BigInteger.valueOf(targetFile.getSize()),
// メタデータからCRC32を参照する(アップロード時に設定しておく)
Long.valueOf(meta.getUserMetaDataOf(USER_METADATA_CRC32)));
BigInteger headerSize = header.writeLocalFileHeaderToBuffer(headerBytes);
// ファイルヘッダの大きさを登録
header.setChunkSizeFromFileSize(headerSize);
// 書き込みストリームを読み込みストリームに変換、ファイルデータを後ろにつける
try (SequenceInputStream writeStream = new SequenceInputStream(
headerBytes.toInputStream(), input)) {
// パート番号を取得する
int partNumber = targetFileList.getObjectSummaries().indexOf(targetFile) + 1;
// 書き込みを実行、実行結果はetagの一覧として格納する
etagList.add(client.uploadPart(new UploadPartRequest()
// バケットを指定
.withBucketName(s3BucketName)
// ファイル名を指定
.withKey(outputFileName)
// ファイルサイズを指定
.withPartSize(header.getChunkSize().longValue())
// アップロードファイルの書き込みストリームを指定
.withInputStream(writeStream)
// マルチパートアップロード:アップロードIDを指定
.withUploadId(initResult.getUploadId())
// マルチパートアップロード:パートに連番をつける
.withPartNumber(partNumber)).getPartETag());
}
}
} catch (Exception e) {
// 例外をログ出力
e.printStackTrace();
// 処理に失敗したのであればOptional.nullを返す
header = null;
}
// 非同期処理の実行結果を返す
return Optional.ofNullable(header);
});
})
// 実行中のマルチスレッド処理を配列に変換する
.collect(Collectors.toList());
// マルチスレッドへの格納を終了する
executor.shutdown();
// 成功した処理だけを格納する
List<ZipHeader> zipHeaders = new ArrayList<ZipHeader>();
for (Future<Optional<ZipHeader>> future : uploadResultList) {
future.get().ifPresent(header -> {
zipHeaders.add(header);
});
}
// 最後の処理を追加、書き込みストリームを用意する
try (ByteArrayOutputStream headerBytes = new ByteArrayOutputStream()) {
// 各ファイルのセントラルディレクトリ情報を出力
MutableInt offset = new MutableInt();
MutableInt centralDirectorySize = new MutableInt();
zipHeaders.forEach(header -> {
// 各ファイルのセントラルディレクトリヘッダを出力
BigInteger centralHeaderSize = header.writeCentralDirectoryHeaderToBuffer(headerBytes,
offset.getValue());
centralDirectorySize.add(centralHeaderSize);
offset.add(header.getChunkSize());
});
// 終端にあるセントラルディレクトリ情報を出力
zipHeaders.get(0).writeEndOfCentralDirectoryHeaerToBuffer(headerBytes, centralDirectorySize.getValue(),
offset.getValue(), BigInteger.valueOf(zipHeaders.size()));
// パート番号を取得する
int partNumber = targetFileList.getObjectSummaries().size() + 1;
// 書き込みを実行、実行結果はetagの一覧として格納する
etagList.add(client.uploadPart(new UploadPartRequest()
// バケットを指定
.withBucketName(s3BucketName)
// ファイル名を指定
.withKey(outputFileName)
// ファイルサイズを指定
.withPartSize(headerBytes.size())
// アップロードファイルの書き込みストリームを指定
.withInputStream(headerBytes.toInputStream())
// マルチパートアップロード:アップロードIDを指定
.withUploadId(initResult.getUploadId())
// マルチパートアップロード:パートに連番をつける
.withPartNumber(partNumber)).getPartETag());
// 完了通知を送信
client.completeMultipartUpload(new CompleteMultipartUploadRequest(s3BucketName, outputFileName,
initResult.getUploadId(), etagList));
}
} catch (Exception e) {
// 処理中の例外はランタイム例外に変換して投げる
throw new RuntimeException(e);
}
}
}
Lambdaのソースコード:zipのヘッダを作るクラス:ZipHeader.java
public class ZipHeader {
// ローカルファイルヘッダ
private static String LOCAL_FILE_HEADER_SIGNATURE = "50,4B,03,04";
// セントラルディレクトリヘッダ
private static String CENTRAL_FILE_HEADER_SIGNATURE = "50,4B,01,02";
// 終端セントラルディレクトリヘッダ
private static String END_OF_CENTRAL_FILE_HEADER_SIGNATURE = "50,4B,05,06";
// 作成情報(Windows, Zip Version 1.0)
private static String CREATE_INFO = "0A,00";
// Zip Version 1.0
private static String ZIP_VERSION = "0A,00";
// 圧縮オプション
private static String OPTION = "00,08";
// 圧縮アルゴリズム(無圧縮)
private static String ALGORITHM = "00,00";
// エクストラフィールド長
private static String EXTRA_FIELD_LENGTH = "00,00";
// コメント長
private static String COMMENT_LENGTH = "00,00";
// ディスク分割
private static String NO_DISK_SEPARATE = "00,00";
// ファイルタイプ
private static String FILE_TYPE = "00,00";
// ファイル権限情報
private static String FILE_PERMISSION = "00,00,00,00";
private String mFileName;
private BigInteger mFileSize;
private long mCrc;
private LocalDateTime mDate;
private BigInteger mChunkSize;
public ZipHeader(String fileName, BigInteger fileSize, long crc) {
mFileName = fileName;
mFileSize = fileSize;
mCrc = crc;
mDate = LocalDateTime.now();
}
public void setChunkSizeFromFileSize(BigInteger headerSize) {
mChunkSize = mFileSize.add(headerSize);
}
public BigInteger getChunkSize() {
return mChunkSize;
}
private String integerToBinaryString(long value, int length) {
return String.format(String.format("%%%ds", length), Long.toBinaryString(value)).replace(" ", "0");
}
private void writeBinaryString(OutputStream stream, String binaryString, MutableInt length) throws Exception {
int bytes = binaryString.length() / 8;
for (int i = (bytes - 1); i >= 0; i--) {
String oneByte = binaryString.substring(i * 8, (i + 1) * 8);
stream.write(Integer.parseUnsignedInt(oneByte, 2));
}
length.add(bytes);
}
private void appendLastModeFileDateTime(OutputStream stream, MutableInt length) throws Exception {
LocalDateTime date = mDate;
// 時分秒
String hour = integerToBinaryString(date.getHour(), 5);
String minute = integerToBinaryString(date.getMinute(), 6);
String second = integerToBinaryString(date.getSecond() / 2, 5);
writeBinaryString(stream, hour + minute + second, length);
// 年月日
String year = integerToBinaryString(date.getYear() - 1980, 7);
String month = integerToBinaryString(date.getMonthValue(), 4);
String day = integerToBinaryString(date.getDayOfMonth(), 5);
writeBinaryString(stream, year + month + day, length);
}
private void appendCRC32(OutputStream stream, MutableInt length) throws Exception {
String binary = integerToBinaryString(mCrc, 32);
writeBinaryString(stream, binary, length);
}
private void appendBytesFromString(OutputStream stream, String data, MutableInt length) {
Arrays.asList(data.split(",")).forEach((hex) -> {
try {
stream.write(Hex.decodeHex(hex));
length.add(1);
} catch (DecoderException | IOException e) {
}
});
}
private void appendFileSize(OutputStream stream, MutableInt length) throws Exception {
String binary = integerToBinaryString(mFileSize.longValue(), 32);
writeBinaryString(stream, binary, length);
writeBinaryString(stream, binary, length);
}
private void appendFileName(OutputStream stream, MutableInt length) throws Exception {
String fileNameLength = integerToBinaryString(mFileName.length(), 16);
writeBinaryString(stream, fileNameLength, length);
}
private void appendBuffer(OutputStream stream, byte[] buffer, MutableInt length) throws Exception {
stream.write(buffer);
length.add(buffer.length);
}
/**
* ファイルヘッダを出力する
*
* @param stream 出力先ストリーム
*/
public BigInteger writeLocalFileHeaderToBuffer(OutputStream stream) {
try {
MutableInt lengthBuffer = new MutableInt();
// ローカルファイルヘッダを登録
this.appendBytesFromString(stream, LOCAL_FILE_HEADER_SIGNATURE, lengthBuffer);
// Versionを登録
this.appendBytesFromString(stream, ZIP_VERSION, lengthBuffer);
// 圧縮オプションを登録
this.appendBytesFromString(stream, OPTION, lengthBuffer);
// 無圧縮アルゴリズムを登録
this.appendBytesFromString(stream, ALGORITHM, lengthBuffer);
// 最終更新日時を登録
this.appendLastModeFileDateTime(stream, lengthBuffer);
// CRCを登録
this.appendCRC32(stream, lengthBuffer);
// 圧縮後サイズを登録
this.appendFileSize(stream, lengthBuffer);
// ファイル名の長さを登録
this.appendFileName(stream, lengthBuffer);
// エクストラフィールド長を登録
this.appendBytesFromString(stream, EXTRA_FIELD_LENGTH, lengthBuffer);
// ファイル名を登録
this.appendBuffer(stream, mFileName.getBytes(), lengthBuffer);
// データ長を返却
return lengthBuffer.getValue();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
/**
* セントラルディレクトリヘッダを出力する
*
* @param stream 出力先ストリーム
* @param fileOffset ファイルのオフセット位置
*/
public BigInteger writeCentralDirectoryHeaderToBuffer(OutputStream stream, BigInteger fileOffset) {
try {
MutableInt lengthBuffer = new MutableInt();
// セントラルディレクトリヘッダを登録
this.appendBytesFromString(stream, CENTRAL_FILE_HEADER_SIGNATURE, lengthBuffer);
// 作成情報を登録
this.appendBytesFromString(stream, CREATE_INFO, lengthBuffer);
// Versionを登録
this.appendBytesFromString(stream, ZIP_VERSION, lengthBuffer);
// 圧縮オプションを登録
this.appendBytesFromString(stream, OPTION, lengthBuffer);
// 無圧縮アルゴリズムを登録
this.appendBytesFromString(stream, ALGORITHM, lengthBuffer);
// 最終更新日時を登録
this.appendLastModeFileDateTime(stream, lengthBuffer);
// CRCを登録
this.appendCRC32(stream, lengthBuffer);
// 圧縮後サイズを登録
this.appendFileSize(stream, lengthBuffer);
// ファイル名の長さを登録
this.appendFileName(stream, lengthBuffer);
// エクストラフィールド長を登録
this.appendBytesFromString(stream, EXTRA_FIELD_LENGTH, lengthBuffer);
// コメント長を登録
this.appendBytesFromString(stream, COMMENT_LENGTH, lengthBuffer);
// ファイルは分割しない
this.appendBytesFromString(stream, NO_DISK_SEPARATE, lengthBuffer);
// ファイルタイプを指定
this.appendBytesFromString(stream, FILE_TYPE, lengthBuffer);
// 権限情報を登録
this.appendBytesFromString(stream, FILE_PERMISSION, lengthBuffer);
// ファイルのオフセット位置を登録
String fileOffsetBinary = integerToBinaryString(fileOffset.longValue(), 32);
this.writeBinaryString(stream, fileOffsetBinary, lengthBuffer);
// ファイル名を登録
this.appendBuffer(stream, mFileName.getBytes(), lengthBuffer);
// データ長を返却
return lengthBuffer.getValue();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
/**
* ファイル終端のセントラルディレクトリ情報を返却する
*
* @param stream 出力先ストリーム
* @param centralSize セントラルディレクトリヘッダの合計サイズ
* @param fileOffset ファイルのオフセット位置
* @param fileCounts zipに格納したファイルの総数
*/
public BigInteger writeEndOfCentralDirectoryHeaerToBuffer(OutputStream stream, BigInteger centralSize,
BigInteger fileOffset, BigInteger fileCounts) {
try {
MutableInt lengthBuffer = new MutableInt();
// 終端セントラルファイルヘッダを登録
this.appendBytesFromString(stream, END_OF_CENTRAL_FILE_HEADER_SIGNATURE, lengthBuffer);
// ファイル分割はしない
this.appendBytesFromString(stream, NO_DISK_SEPARATE, lengthBuffer);
// ファイル分割はしない
this.appendBytesFromString(stream, NO_DISK_SEPARATE, lengthBuffer);
// ファイル数
String fileCountsBinary = integerToBinaryString(fileCounts.longValue(), 16);
this.writeBinaryString(stream, fileCountsBinary, lengthBuffer);
this.writeBinaryString(stream, fileCountsBinary, lengthBuffer);
// セントラルディレクトリサイズを登録
String centralSizeBinary = integerToBinaryString(centralSize.longValue(), 32);
this.writeBinaryString(stream, centralSizeBinary, lengthBuffer);
// ファイルのオフセット位置を登録
String fileOffsetBinary = integerToBinaryString(fileOffset.longValue(), 32);
this.writeBinaryString(stream, fileOffsetBinary, lengthBuffer);
// コメント長を登録
this.appendBytesFromString(stream, COMMENT_LENGTH, lengthBuffer);
// データ長を返却
return lengthBuffer.getValue();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
}
Lambdaのソースコード:そのほかのクラス:MutableInt .java
public class MutableInt {
private BigInteger mValue;
public MutableInt() {
mValue = BigInteger.valueOf(0);
}
public void add(int value) {
mValue = mValue.add(BigInteger.valueOf(value));
}
public void add(BigInteger value) {
mValue = mValue.add(value);
}
public BigInteger getValue() {
return mValue;
}
}
build.gradle
/*
* This file was generated by the Gradle 'init' task.
*
* This generated file contains a sample Java Library project to get you started.
* For more details take a look at the Java Libraries chapter in the Gradle
* User Manual available at https://docs.gradle.org/6.3/userguide/java_library_plugin.html
*/
plugins {
// Apply the java-library plugin to add support for Java Library
id 'java-library'
}
repositories {
// Use jcenter for resolving dependencies.
// You can declare any Maven/Ivy/file repository here.
jcenter()
}
dependencies {
// This dependency is exported to consumers, that is to say found on their compile classpath.
api 'org.apache.commons:commons-math3:3.6.1'
// This dependency is used internally, and not exposed to consumers on their own compile classpath.
implementation 'com.google.guava:guava:28.2-jre'
// https://mvnrepository.com/artifact/commons-io/commons-io
implementation group: 'commons-io', name: 'commons-io', version: '2.8.0'
// https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-s3
implementation group: 'com.amazonaws', name: 'aws-java-sdk-s3', version: '1.11.1005'
implementation 'com.amazonaws:aws-lambda-java-core:1.2.1'
implementation 'com.amazonaws:aws-lambda-java-events:3.1.0'
runtimeOnly 'com.amazonaws:aws-lambda-java-log4j2:1.2.0'
// Use JUnit test framework
testImplementation 'junit:junit:4.12'
}
// Task for building the zip file for upload
task buildZip(type: Zip) {
from compileJava
from processResources
into('lib') {
from configurations.runtimeClasspath
}
}
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
build.dependsOn buildZip
S3にCRC32のついたファイルをアップロードするスクリプト
import binascii
import boto3
from pathlib import Path
from argparse import ArgumentParser
import io
# 実行引数を読み取る
parser = ArgumentParser()
parser.add_argument("--folder", type=str, required=True)
parser.add_argument("--bucket", type=str, required=True)
args = parser.parse_args()
def get_crc_from_file(file_path):
"""
ファイルからCRC32を取得する
Parameters
------------
file_path : Path
対象のファイルパス
Return
------------
CRC32 : str
文字列型のCRC32
"""
with open(file_path, mode = "rb") as fp:
return str(binascii.crc32(fp.read()))
def main(args):
"""
ファイルをアップロードする
Parameters
------------
args : ArgumentParser
* folder 対象ファイルの配置先フォルダ(相対パス)
* bucket アップロード先のバケット名
"""
# クライアントを作成する
s3_client = boto3.client('s3')
# フォルダ以下のファイルを一覧で取得する
for file_name in Path(args.folder).glob("*"):
# CRCを取得する
crc = get_crc_from_file(file_name)
# OS依存のパスをS3のパス形式に変換する
s3_key_name = "/".join(file_name.parts)
# アップロードする
s3_client.upload_file(
str(file_name),
args.bucket,
s3_key_name,
ExtraArgs={
"Metadata": {
"crc32": crc
}
})
if __name__ == "__main__":
main(args)
実際に動かしたところ
S3に、jpgやビットマップファイルを置いています。
39ファイル、合計サイズ1.0GBのファイルを対象にします。
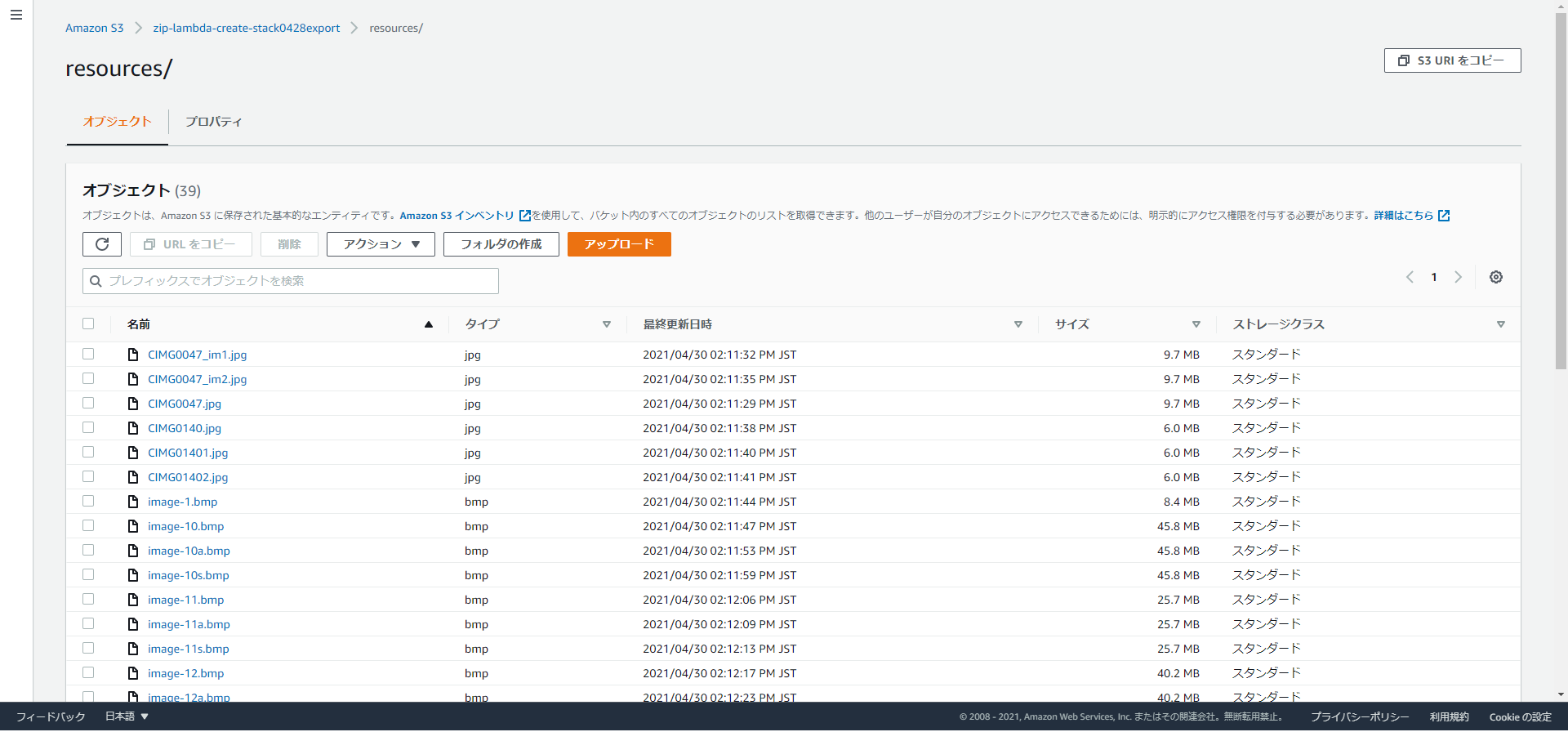
処理完了後、S3にファイルが配置されました
もちろんzipファイルをダウンロードして、問題なく展開することができます
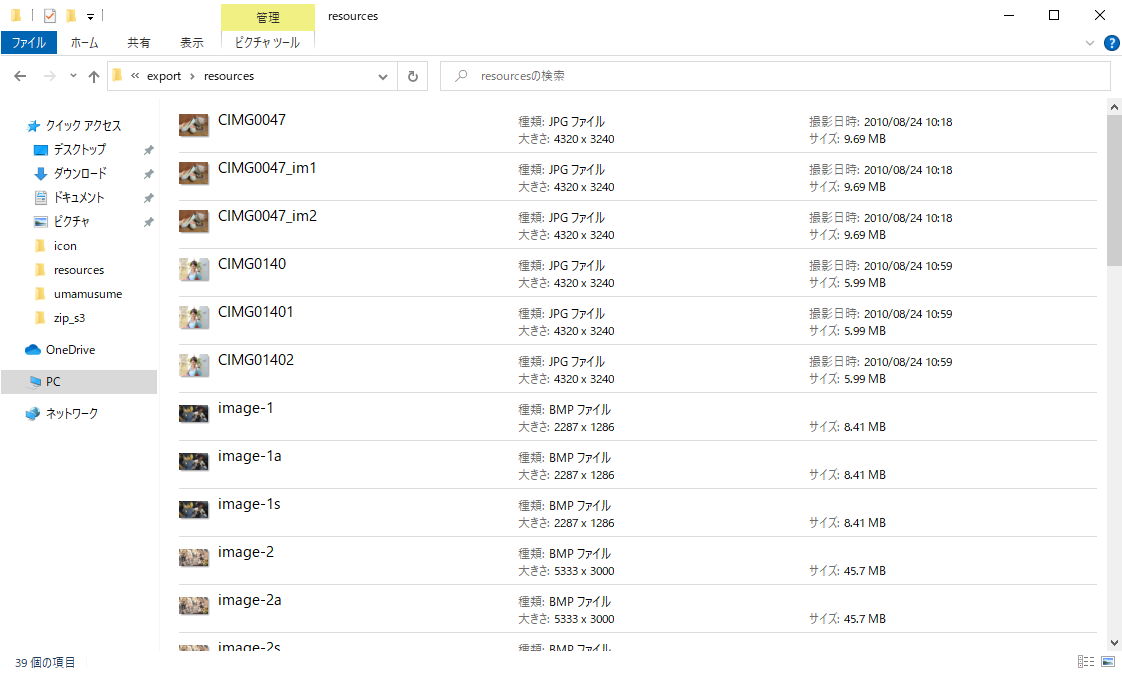
Lambdaの実行情報
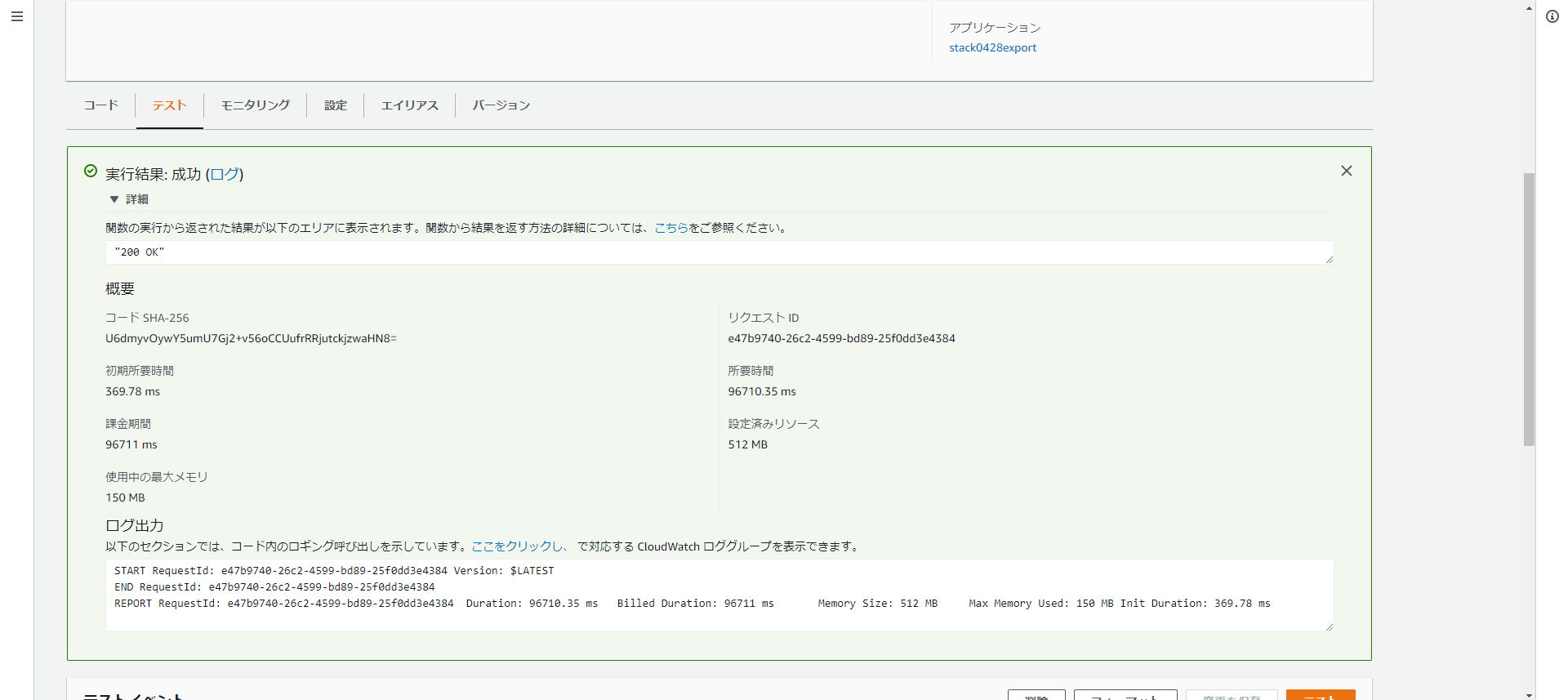
96秒で処理を完了、実行中に使用した最大メモリは150MB、/tmpディレクトリの使用はありません。
5スレッドで動かしていますが、スレッド数を増やすほどメモリ使用量は大きく、処理時間を短くすることができます。
まとめ
実際にS3の機能だけでzipを作成できることの確認と、処理速度の計測をしました。
ZIP64への対応は必要になりますが、10GBくらいの大きさのzipファイルであれば、S3+Lambdaだけで作ることができそうです。