はじめに
この記事では、TensorFlow (2.13.0) を使った CNN (Convolutional Neural Network) の構築の例を紹介します。jpeg などの一般的な写真データを用いた例はネット上にごまんと存在しますが、天文解析等で基本的取り扱われる Numpy Array での画像認識の実装例はほとんどヒットしません。参考になりましたら幸いです。
使用するデータの準備
とは言っても、ここに投稿する例として適切な天文データは存在しないので、jpeg などの一般的な写真データを無理矢理 Numpy Array に変換したものを仕方なく使います。今回は、最もポピュラー?な、「ねこ-いぬ」の二値分類問題を解く CNN モデルを TensorFlow を用いて構築します。CNN や TensorFlow の詳細については各自 google 検索してください。環境は Google Colabolatory (2023年9月末現在) を想定しています。ストレージは 2GB ほど使用します。
このページから、Kaggle用のデータセット (jpeg) を wget を用いて Google Drive にダウンロードします。このリンクが切れている場合には各自検索してみてください。
まずは Google Colabolatory でノートブックを新規作成します。 そして「ランタイム」から「ランタイムのタイプを変更」でGPU (T4 GPU) を選択します。ただし、無課金では利用制限があります。利用制限に引っかかってしまった場合は、課金するか、再び使えるようになるまで待ちましょう。 ちなみに、利用制限に関する詳細は非公開になっています。
最初に Google Drive をマウントします。
from google.colab import drive
drive.mount('/content/drive/')
また、今回使うモジュール等をここでまとめて import しておきます。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, Conv3D, Flatten, Dropout, MaxPooling2D, MaxPooling3D, AveragePooling2D, AveragePooling3D, concatenate, BatchNormalization
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import plot_model, to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpoint
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import regularizers
from sklearn.model_selection import train_test_split
from sklearn import metrics
import math
from glob import glob
import pandas as pd
import time
import os, copy
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import pickle
from PIL import Image
GPU が available かどうかは以下で判断します。出力に Tesla T4 (Google Colabolatoryでなければ GeForce など) と表示されていれば大丈夫です。
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
カレントディレクトリを確認します。
!pwd
# /content
ディレクトリを生成します。drive/MyDrive/ 以下で生成すると、一度実行するだけであとは読み込むだけなのですが、ファイルのやり取りが異様に遅い場合があるので、直下に作ることにします。
!mkdir -p cats_and_dogs
wget します。リンクが変わっている場合には適宜変更してください。
!wget --no-check-certificate https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip -P cats_and_dogs/
解凍します。
!unzip -q cats_and_dogs/kagglecatsanddogs_5340.zip -d cats_and_dogs/
ディレクトリを生成します。
!mkdir -p cats_and_dogs/PetImages_numpy
!mkdir -p cats_and_dogs/PetImages_numpy/cats
!mkdir -p cats_and_dogs/PetImages_numpy/dogs
適当なものを見てみます。
im = Image.open("cats_and_dogs/PetImages/Cat/8552.jpg")
plt.imshow(im)

ダウンロードした画像はサイズがバラバラなので、リサイズして全て揃えます。画像サイズは適当に定義します。アスペクト比が変わりますが、ここではただの猫なので気にしません。(ただし、天文データを取り扱う際には気にしなくてはなりません。)
WIDTH, HEIGHT = 201, 171
im_resized = im.resize((WIDTH, HEIGHT))
plt.imshow(im_resized)
2次元の Numpy Array にしたいので、グレースケールに変換します。
img_gray = im_resized.convert('L')
plt.imshow(img_gray, cmap="Greys_r")
print(np.array(img_gray).shape)
まとめて変換するために関数を用意します。
def resize_and_jpg_to_npy(filepath, savedir):
im = Image.open(filepath)
im_resized = im.resize((WIDTH, HEIGHT))
img_gray = im_resized.convert('L')
npy = np.array(img_gray)
np.save(os.path.join(savedir, os.path.splitext(os.path.basename(filepath))[0]+".npy"), npy)
return
画像の path の list を作ります。
cats_jpg_list = glob("cats_and_dogs/PetImages/Cat/*.jpg")
dogs_jpg_list = glob("cats_and_dogs/PetImages/Dog/*.jpg")
print(len(cats_jpg_list), len(dogs_jpg_list))
# 12500 12500
先程生成したディレクトリを指定して、関数を回します。空のファイルが混じっているので、try で弾きます。(また、すごく時間がかかることがあるので multi process を組んだ方が良いかもしれません。)
cats_npy_dir = "cats_and_dogs/PetImages_numpy/cats"
dogs_npy_dir = "cats_and_dogs/PetImages_numpy/dogs"
for cats_jpg in tqdm(cats_jpg_list):
try:
resize_and_jpg_to_npy(cats_jpg, cats_npy_dir)
except:
pass
for dogs_jpg in tqdm(dogs_jpg_list):
try:
resize_and_jpg_to_npy(dogs_jpg, dogs_npy_dir)
except:
pass
これでようやくデータの下準備は完了です。
CNN の構築
データセット
Numpy Array の path の list を作ります。
cats_npy_list = glob("cats_and_dogs/PetImages_numpy/cats/*.npy")
dogs_npy_list = glob("cats_and_dogs/PetImages_numpy/dogs/*.npy")
print(len(cats_npy_list), len(dogs_npy_list))
# 12499 12499
データを確認します。
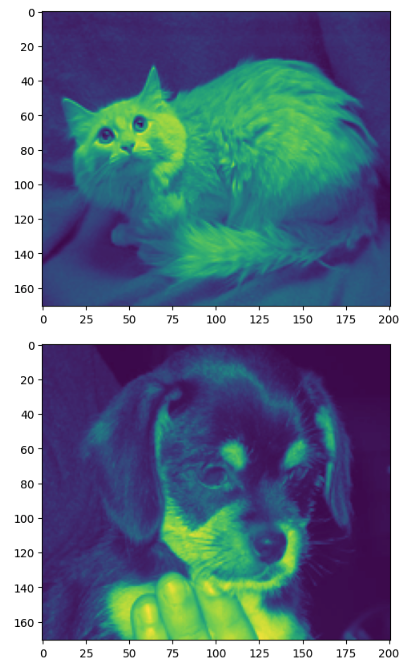
plt.imshow(np.load("cats_and_dogs/PetImages_numpy/cats/8552.npy"))
plt.show()
plt.imshow(np.load("cats_and_dogs/PetImages_numpy/dogs/8552.npy"))
plt.show()
データを、トレーニング用と検証用に分けます。ここでは、4:1 に分けます。さらに言えば、クロスバリデーションを見越して5グループに分けます。
def split_n(list_inp, n):
res = {}
for i in range(int(n)-1):
list_inp, g_tempo = train_test_split(list_inp, test_size=1.0/(n-i))
res["g%s"%str(i)] = g_tempo
res["g%s"%str(int(n)-1)] = list_inp
return res
cats_groups = split_n(cats_npy_list, 5)
dogs_groups = split_n(dogs_npy_list, 5)
以下のクラスを定義します。batch_size は適当です。適宜変更してください。
class Mydatasets(tf.keras.utils.Sequence):
def __init__(self, x, y, batch_size=128):
self.x = x
self.y = y
self.batch_size = batch_size
def __len__(self):
return math.ceil(len(self.x) / self.batch_size)
def __getitem__(self, idx):
low = idx * self.batch_size
high = min(low + self.batch_size, len(self.x))
batch_x = self.x[low:high]
batch_y = self.y[low:high]
return np.array(batch_x), np.array(batch_y)
とりあえずメモリに乗っけて、データセットを定義します。
cats_train = cats_groups["g1"]+cats_groups["g2"]+cats_groups["g3"]+cats_groups["g4"]
dogs_train = dogs_groups["g1"]+dogs_groups["g2"]+dogs_groups["g3"]+dogs_groups["g4"]
cv_0 = {"X_train": [np.load(_)/255.0 for _ in tqdm(cats_train+dogs_train)],
"X_val": [np.load(_)/255.0 for _ in tqdm(cats_groups["g0"]+dogs_groups["g0"])],
"Y_train": [1]*len(cats_train) + [0]*len(dogs_train), # 1=cats, 0=dogs
"Y_val": [1]*len(cats_groups["g0"]) + [0]*len(dogs_groups["g0"]), # 1=cats, 0=dogs
}
ds_train_0 = Mydatasets(cv_0["X_train"], cv_0["Y_train"])
ds_val_0 = Mydatasets(cv_0["X_val"], cv_0["Y_val"])
model の学習 (トレーニング)
ここで、CNN のモデルは、Functional API を用います。これは、tf.keras.Sequential API よりも柔軟なモデルの作成が可能です (今回の例では実質的に Sequential と等価です)。例えば x1 と x2 を作って concat したりできます。詳しくは各自検索してみてください。
色々やっていますが、基本的には畳み込みしてプーリングして結合して、画像データを 1 つの数字に落とし込んでいます。今回は ねこ-いぬ の 2 クラスなので、 1 つの数字で十分です。各層の詳細については、各自検索してみてください。また、EarlyStopping や ReduceLROnPlateau も入れています。こちらに関しても、各自検索してみてください。
WIDTH, HEIGHT = 201, 171
def save_model_history(ds_train, ds_val, EPOCHS=500):
input_ = Input(shape=(HEIGHT, WIDTH,1))
x = Conv2D(8, (5, 5), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(input_)
#x = Conv2D(16, (5, 5), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = Conv2D(16, (5, 5), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization()(x)
x = MaxPooling2D((4, 4))(x)
#x = Dropout(0.3)(x)
x = Conv2D(16, (5, 5), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = Conv2D(32, (5, 5), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = Conv2D(32, (5, 5), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = BatchNormalization()(x)
x = MaxPooling2D((4, 4))(x)
#x = Dropout(0.3)(x)
x = Conv2D(32, (3, 3), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = Conv2D(64, (3, 3), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = Conv2D(64, (3, 3), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = AveragePooling2D((2, 2))(x)
#x = Dropout(0.3)(x)
#x = Conv2D(128, (3, 3), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = Conv2D(128, (3, 3), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
#x = Conv2D(128, (3, 3), padding='valid', activation='relu', kernel_regularizer=regularizers.l2(0.001))(x)
x = Flatten()(x)
x = Dropout(0.3)(x)
#x = Dropout(0.2)(x)
main_output = Dense(1, activation='sigmoid', kernel_regularizer=regularizers.l2(0.001))(x)
model = Model(inputs=input_, outputs=main_output)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
print(model.summary())
es_cb = EarlyStopping(monitor='val_loss', min_delta=0.001, patience=30, verbose=1, mode='auto')
rd_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.7, patience=10, verbose=1, min_lr=0.00001, mode='auto')
#mc_cb = ModelCheckpoint(args["filepath"], monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=False, mode='auto', period=1)
cbks = [es_cb, rd_cb]
#cbks = [es_cb, rd_cb, mc_cb]
history = model.fit(x=ds_train,
epochs=EPOCHS,
verbose=1,
shuffle=True,
validation_data=ds_val,
callbacks=[cbks])
#best_model = tf.keras.models.load_model(args["filepath"])
#best_loss, best_acc = best_model.evaluate(X_test[:,:,:, None], Y_test)
#print("best_loss, best_acc =", best_loss, best_acc)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
return model, history.history
以下で学習を実行します。ログが出力されます。
model_history_0 = save_model_history(ds_train_0, ds_val_0)
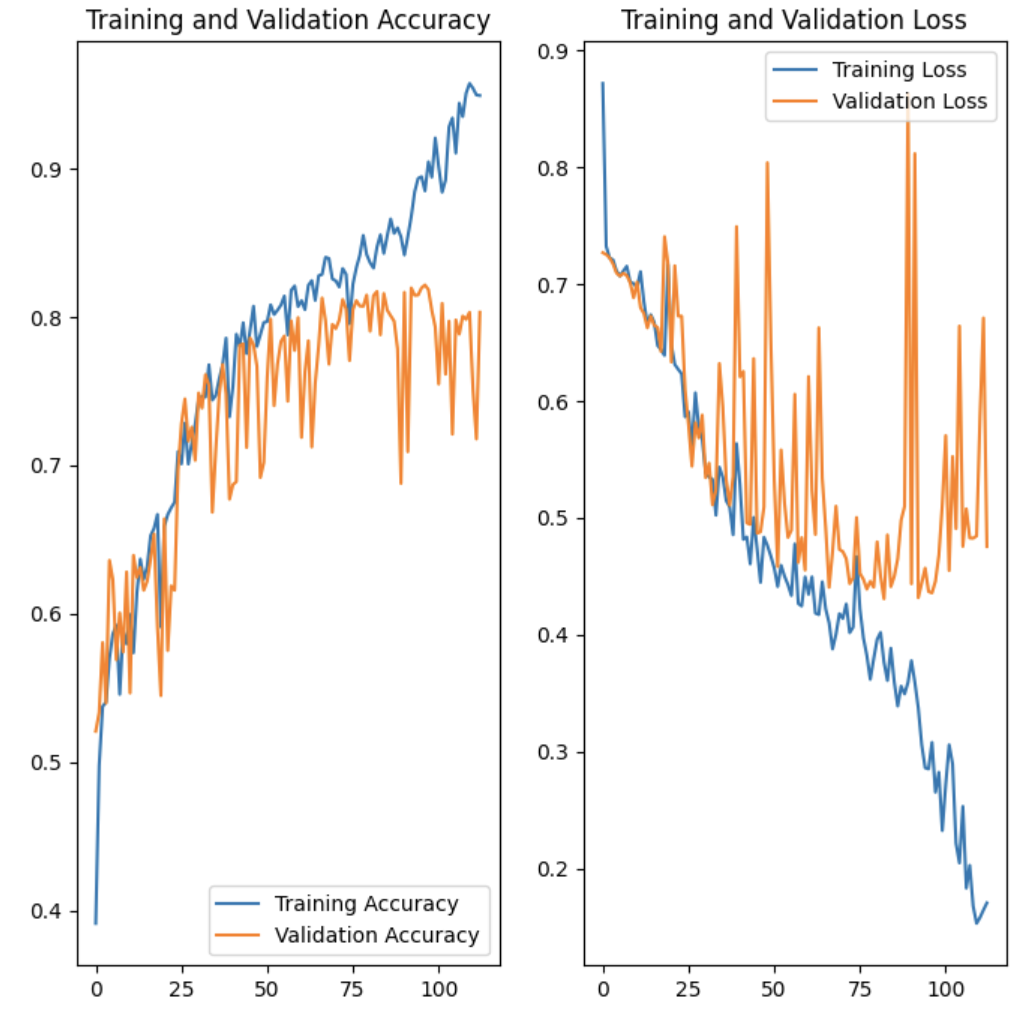
ほとんど何も考えずに適当に作ったモデルですが、80%くらいの正解率にはいきました。
モデルの save と load
以下のようにモデル全体を保存します。model_history_0 には、[0] には model を入れており、[1] には history を入れています。weight だけ保存する場合などはこちらなどを参照してください。
model_history_0[0].save("my_model")
model_history_0[0].save("drive/MyDrive/my_model")
以下のようにロードします。
model = tf.keras.models.load_model("my_model")
自前のデータでテスト
トレーニングに含まれていないデータを読み込ませて predict させてみます。
im = Image.open("drive/MyDrive/hogehoge.png")
plt.imshow(im)
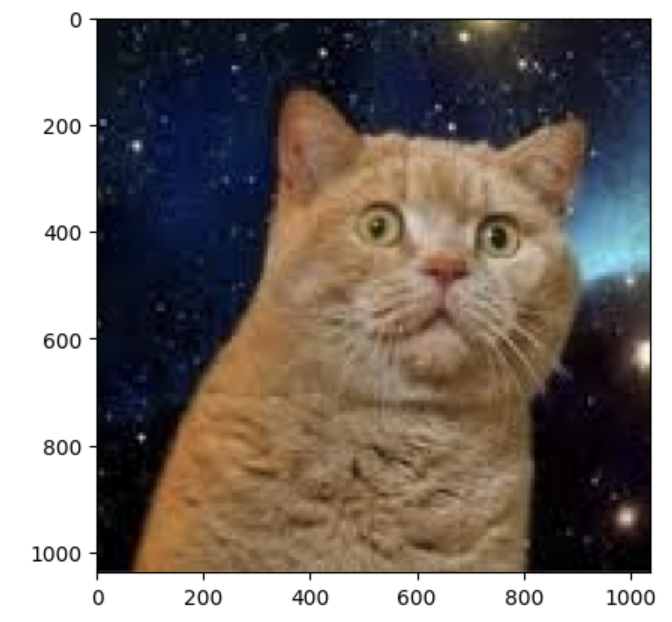
im_resized = im.resize((WIDTH, HEIGHT))
img_gray = im_resized.convert('L')
npy_test = np.array(img_gray)/255.0
model.predict(npy_test.reshape(1, 171,201,1))
# 1/1 [==============================] - 0s 73ms/step
# array([[0.67559844]], dtype=float32)
0.67559844 が返ってきました。1 に近いほど ねこ を表し、0 に近いほど いぬ を表すので、「そこそこ ねこ」といったくらいの結果です。
次に、「犬小屋に入ってだらけているねこ」という多少トリッキーな画像で試してみます。
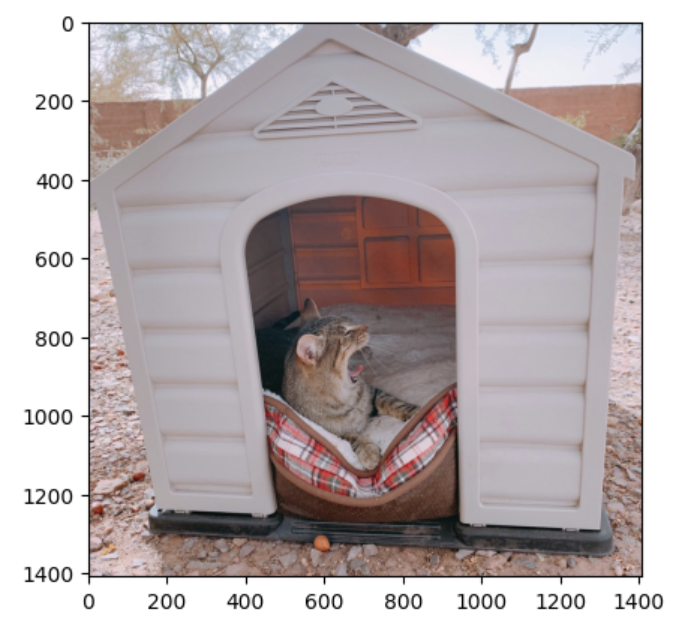
model.predict(npy_test.reshape(1, 171,201,1))
# 1/1 [==============================] - 0s 35ms/step
# array([[0.10139316]], dtype=float32)
0.10139316 なので、「かなりの確率で いぬ」という結果になりました。いぬの学習データに犬小屋が含まれていて、それも学習している可能性が考えられます。
最後に
今回は世に出回っているデータセットで試したため、比較的簡単に下準備できましたが、実際の天文データではなかなか苦戦することもあるかと思います。また、マシンリソースも、最近は Google Colabolatory が厳しくなってきているため用意するのも困難です (自前でマシンを用意するにはお金と環境構築作業が必要で、これが思ったよりも大変)。
本記事ではモデルの構築するところまでしか記述していませんが、実際に天文で深層学習を道具として使って何かを調査する際には、出てきた結果を慎重に吟味する必要があります。例えば、どういったデータでは間違えやすいか、などです。研究者が目で見て判断することも (少なくとも現代の技術では) 重要だと個人的には考えています。
本記事が部分的にでも参考になれば幸いです。
以上です。
リンク
目次