はじめに
Livebook Launch Week 2 を自分でやってみるシリーズ
- Day1: Smart Cell からのリモート接続
- Day2: Whisper による音声認識の新機能
- Day3: ファイルをドラッグ&ドロップすると、扱うためのコードを自動生成する <- ここ
- Day4:
- Day5: Vim と Emacs のキーバインド
Day 3 は Livebook のファイル統合です
Livebook にファイルをドラッグ&ドロップすると、そのファイルを使うときのコードを勝手に生成してくれるようになる神機能です
実際に使ってみましょう
Livebook のはじめ方はこちら
CSV ファイルの追加
ファイル参照の追加
Livebook で新しいノートブックを開きます
左メニューのディレクトリーアイコン(Files)をクリックしましょう

FILES メニューが表示されます
- Add file ボタンをクリックします

Add file モーダルが開きます

今回は Web 上から CSV を取得してみます
From URL タブをクリックします
From URL タブをクリックしてもタブの色が変化しないのはバグだと思いますが、そのうち修正されるでしょう
URL を入力すると、自動的に Name にファイル名が入力されます(変更可能です)
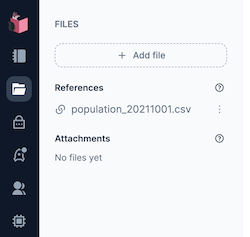
今回は私の GitHub リポジトリーから都道府県別人口構成の CSV ファイルを指定しました

Add ボタンをクリックすると、 References にファイルが追加されました
CSV ファイルからのコード自動生成
追加されたファイルをノートブック上のセルの前後にドラッグ&ドロップしてみましょう

Suggested actions というモーダルが開き、 CSV の場合、以下の選択肢が表示されます
- Create a dataframe
- Read file content
Create a dataframe を選択すると、追加の依存モジュールとして kino_explorer をインストールして再起動するよう求められます
- Add and restart をクリックすると、以下のように CSV を読み込んでデータフレームにする処理が追加されます
df =
Kino.FS.file_path("population_20211001.csv")
|> Explorer.DataFrame.from_csv!()
また、セットアップセルには以下のコードが追加され、インストールが実行されます
Mix.install([
{:kino, "~> 0.11.0"},
{:kino_explorer, "~> 0.1.11"}
])
インストールの完了後、 CSV 読み込みのセルを実行すると、データフレームが作成され、結果がテーブル形式で表示されます

通常は自分で Web からダウンロードする処理などをコードで記述しないといけません
しかし、 FILES メニューを使うことで、コード上はファイル名を指定するだけで CSV ファイルが読み込まれています
内部的には References で URL の参照だけを保持しており、セルの実行時、 Livebook が裏でデータをダウンロードしてくれています
ノートブックの保存
この状態でノートブックを保存してみましょう
ノーブックの右下フロッピーアイコン(今の時代伝わるか不安)をクリックします

適当なディレクトリーを選択し、適当な名前を付けて保存します

保存された .livemd ファイルは以下のような内容になっています
<!-- livebook:{"file_entries":[{"name":"population_20211001.csv","type":"url","url":"https://github.com/RyoWakabayashi/elixir-learning/raw/main/livebooks/explorer/population_20211001.csv"}]} -->
# Untitled notebook
...
FILE メニューの References の内容がコメントで保持されており、 Livebook が内部的にここを参照して処理していることが分かります
参照情報ごと管理されるので、このファイルを共有すれば他の人も同じファイルを参照可能です
ファイル添付
References にあるファイルの右ドロップダウンから Move to attachments をクリックします

ファイルが Attachments の方に移動しました

この状態でノートブックを保存すると、 .livemd の内容は以下のように変化します
<!-- livebook:{"file_entries":[{"name":"population_20211001.csv","type":"attachment"}]} -->
# Untitled notebook
"type":"attachment" で添付ファイル状態になっています
そして、 .livemd ファイルと同じディレクリー配下に files ディレクトリーが作成され、その中に population_20211001.csv が保存されました
.
├── sample.livemd
└── files
└── population_20211001.csv
Attachments にすることで、使用するファイル自体をダウンロードして保存することができます
ファイル自体を Git 管理下に置きたい場合などはファイル添付を使用しましょう
音声ファイルの添付
今度は .wav の音声ファイルを追加し、ノートブックに投げてみます
すると、以下のようなモーダルが表示されます
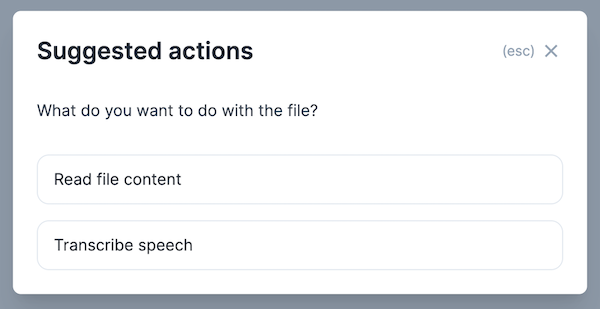
選択肢は以下の二つです
- Read file content
- Transcribe speech
勘の良い方はお気付きですね
下の Transcribe speech をクリックすると、以下のようなモーダルが表示され、 kino_bumblebee の追加と再起動を要求されます

- Add and restart をクリックすると、以下のコードが追加されます
# To explore more models, see "+ Smart" > "Neural Network task"
{:ok, model_info} = Bumblebee.load_model({:hf, "openai/whisper-tiny"})
{:ok, featurizer} = Bumblebee.load_featurizer({:hf, "openai/whisper-tiny"})
{:ok, tokenizer} = Bumblebee.load_tokenizer({:hf, "openai/whisper-tiny"})
{:ok, generation_config} = Bumblebee.load_generation_config({:hf, "openai/whisper-tiny"})
generation_config = Bumblebee.configure(generation_config, max_new_tokens: 100)
serving =
Bumblebee.Audio.speech_to_text_whisper(model_info, featurizer, tokenizer, generation_config,
chunk_num_seconds: 30,
timestamps: :segments,
stream: true,
compile: [batch_size: 4],
defn_options: [compiler: EXLA]
)
path = Kino.FS.file_path("run.wav")
Kino.render(Kino.Text.new("(Start of transcription)", chunk: true))
for chunk <- Nx.Serving.run(serving, {:file, path}) do
[start_mark, end_mark] =
for seconds <- [chunk.start_timestamp_seconds, chunk.end_timestamp_seconds] do
seconds
|> round()
|> Time.from_seconds_after_midnight()
|> Time.to_string()
end
text = "\n#{start_mark}-#{end_mark}: #{chunk.text}"
Kino.render(Kino.Text.new(text, chunk: true))
end
Kino.render(Kino.Text.new("\n(End of transcription)", chunk: true))
:ok
これは前回やった Whisper のコードです
セットアップセルは以下のようになります
Mix.install(
[
{:kino, "~> 0.11.0"},
{:kino_explorer, "~> 0.1.11"},
{:kino_bumblebee, "~> 0.4.0"},
{:exla, ">= 0.0.0"}
],
config: [nx: [default_backend: EXLA.Backend]]
)
依存モジュールに kino_bumblebee と exla が追加され、 EXLA を使用するための設定も追加されています
SQLite データベースファイルを追加する
SQLite は軽量なデータベース管理システムです
データはデータベースファイル (.db) の中に保存されます
このデータベースファイルをノートブックに追加することができます
サンプルデータベースの取得
公式チュートリアルにあるサンプルデータベースをダウンロードします
ダウンロードした chinook.zip を展開すると、 chinook.db が取得できます
ノートブックへのデータベースファイルの追加
FILES メニューから chinook.db を追加し、ノートブックに投げてみます
すると、以下のようなモーダルが表示されます

選択肢は以下の二つです
- Describe SQLite database
- Read file content
Describe SQLite database をクリックすると、 kino_db の追加と再起動を要求されます
- Add and restart をクリックすると、以下のコードが追加されます
database_path = Kino.FS.file_path("chinook.db")
{:ok, conn} = Kino.start_child({Exqlite, database: database_path})
Exqlite.query!(conn, "PRAGMA table_list", [])
また、セットアップセルには kino_db と exqlite が追加されます
データベース読込のセルを実行すると、以下のようにテーブル一覧が表示されます

Parquet ファイルの追加
Parquet は効率的にデータを保存、検索するためのファイル形式です
Parquet ファイルの準備
先程 CSV ファイルを読み込んだ結果のテーブルから、データを Parquet 形式で出力しましょう
テーブル左上のエクスポートアイコンをクリックすると、出力形式がドロップダウンで表示されるので、 Parquet をクリックします

テーブルの内容が DataFrame-1699236727025.parquet というようなファイル名で出力されます
Parquet ファイルの遅延読込
準備した .parquet ファイルを FILES メニューから追加し、ノートブックに投げてみます
すると、 CSV の場合と同じ選択肢が表示されます
- Create a dataframe
- Read file content

Create a dataframe をクリックすると、以下のコードが追加されます
df =
Kino.FS.file_spec("population_20211001.parquet")
|> Explorer.DataFrame.from_parquet!(lazy: true)
実行結果は以下のようになり、 CSV と同様、データが一覧表示されます
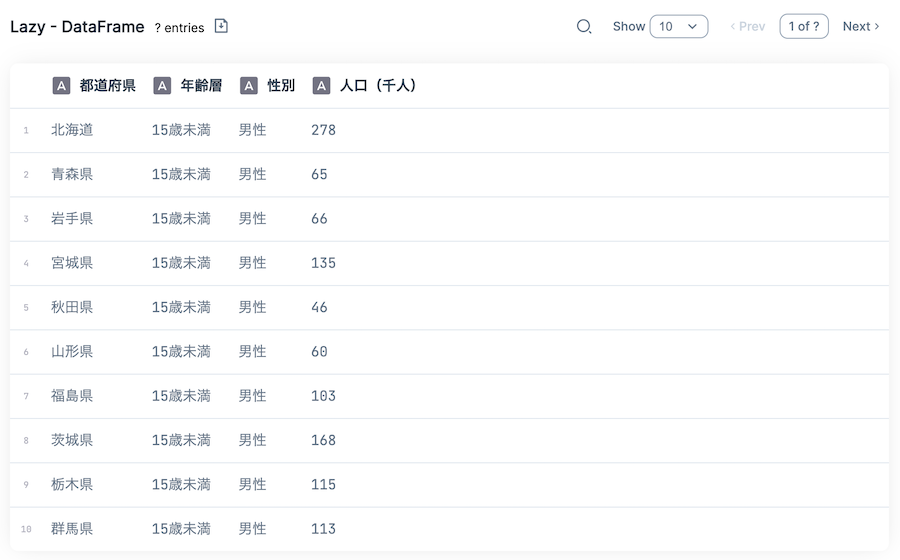
しかし、左上をよく見ると、 Lazy - DataFrame となっており、コードでも lazy: true を指定しています
これは遅延読込の指定です
巨大なデータの場合、最初から全量を読み込むのはメモリを圧迫して非効率です
条件による絞り込みや項目の選択を指定した後、必要な分だけを読み込めば良いはずです
Parquet 形式の場合、そのような遅延読込が可能なため、デフォルトで lazy: true が指定されています
Parquet ファイルから読み込んだデータの変換
Data transform の Smart Cell を追加します

すると、以下のようなフォームが表示されます

以下のように入力してください
- Filter by: 都道府県(string)
- Operation: equal
- Value: 大分県
Evaluate をクリックすると、都道府県が大分県であるデータのみを抽出できます

このとき、遅延読込を指定していない場合、一旦 Parquet ファイルから全量読み込んでから、 Livebook 内で絞り込みを行います
遅延読込をしている場合、 Parquet から都道府県が大分県であるデータのみを読み込みます
後者の方がメモリを節約できることが分かるでしょう
まとめ
Livebook の FILES メニューからファイルを追加することで、以下のようなメリットを得られます
- 拡張子毎にコードの提案を受けられる
- 遅延読込などの便利なオプションもデフォルトで提案してくれる
- ノートブックを共有するとき、一緒にファイルも共有できる
初心者でもすぐにデータ処理や AI モデルの実行ができるため、非常に便利な機能ですね