近年、ITエンジニアの中でもデータエンジニアという職種が注目を集めつつあるように思います。下記の記事をそのまま読むと、データエンジニアは需要が緩やかに伸びていくと思われる期待の職種で、社内のエンジニアからの育成・転身もしやすいそうです。
私はデータエンジニアを自称していますが、この職種の具体的な内容についての理解はまだまだ充実していないように感じるので、私が捉えているデータエンジニアの仕事内容についての理解を紹介してみます。あくまでも私の考えですので、正しさは保証できません。理解の助けになりそうなキーワードを太字で書いています。
データエンジニアの主戦場
まず、データエンジニアの主戦場は、一般的なアプリケーションエンジニアやDBエンジニアの主戦場とは少し異なっていると思います。企業システムは開発目的により、**業務システム(SoR, SoE)と分析システム(SoI)**に分ける考え方が最近ではあります(下図)。データエンジニアの主戦場は、この分け方で考えると後者の分析システム(SoI)になると思います。
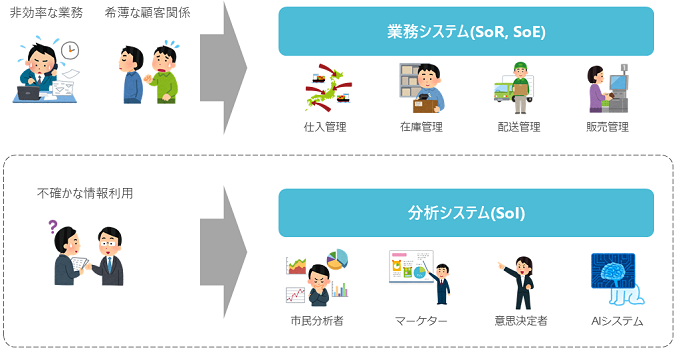
業務改善や顧客関係性の向上を目指すのが業務システム(SoR, SoE)で、これらの業務で発生するデータ活用を目指すのが分析システム(SoI)です。これらのシステムの一般的な考え方の違いを、比較表に書いてみます。
| 比較項目 | 業務システム(SoR, System of Records) | 業務システム(SoE, System of Engagement) | 分析システム(SoI, System of Insight) |
|---|---|---|---|
| システム導入の目的 | 業務の効率化 | 顧客関係性の強化 | 判断の質や速度の向上 |
| システムの主要ユーザ | 業務の従事者 | サービス利用者 | 分析者、意思決定者 |
| 課題分析の主要観点 | 業務観点 | 関係性の観点 | データ観点 |
| 導入による投資対効果(ROI) | 算出しやすい | 算出しにくい | 算出しにくい |
| 開発プロセス | ウォーターフォール | アジャイル | どちらも |
| システム開発の案件数 | 比較的多い | 比較的少ない(今後増加?) | 比較的少ない(今後増加?) |
この記事では、業務システム(SoR, SoR)ではなく分析システム(SoI)を前提とした内容についてもう一歩踏み込んで書いてきます。ここまで読んで、もし業務システムの方にしか興味がなければ、この先はまた興味が出てきたら読んでみてください。
分析システム(SoI)の3層構造
分析システム(SoI)でのデータエンジニアの主な仕事は、システム利用者がデータをすぐに適切な状態で取得することができるデータ基盤を設計することです。このデータ基盤は、大きく1.データ活用層(BI層)、2.データ蓄積層(DWH層)、**3.データ連携層(ETL層)**の3層構造に分割して考えることができます(下図)。
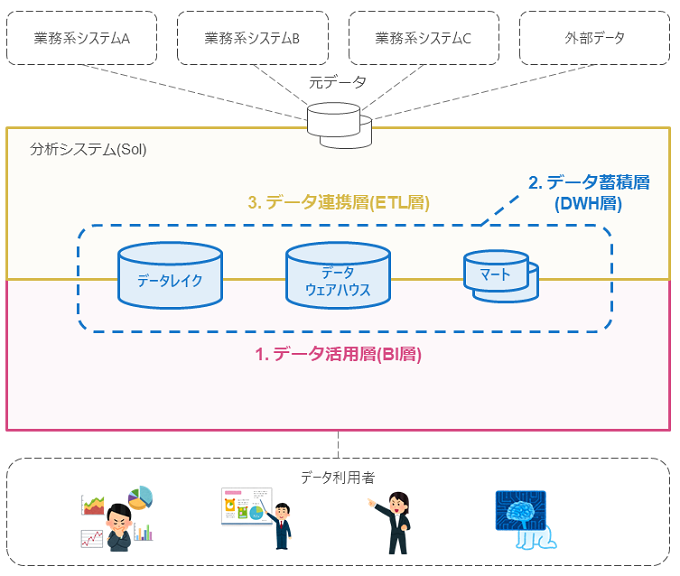
このデータ基盤の3層構造は、Web3層構造(Web/AP/DB)のデータ基盤アーキテクチャ版だと解釈してもよいと思います。このように分割することで、データ基盤の構成について考えやすくなり、チーム作業での議論や作業分担がしやすくなると思います。以降は、それぞれの階層の内容について説明していきます。
1.データ活用層(BI層)
データ利用者に最も近い層から順に、まずはデータ活用層から説明します。システム観点で考えると、この層でのデータ利用方法は大きく2通りあります。1つ目は、必ずしもデータ分析の専門家ではない利用者が、ダッシュボードを利用して業務上の意思決定に役立てる使い方です。ダッシュボードは、例えば前日の稼働状況などの最新の情報を意思決定者が利用しやすいように可視化する画面のことです。2つ目の方法は、データサイエンティストが、様々な切り口でデータを分析してアルゴリズム手法を検証する自由分析の使い方です。自由分析は、例えば商品の需要予測のような特定の分析テーマを立てて、業務知見の獲得や分析モデルの作成を目指します。
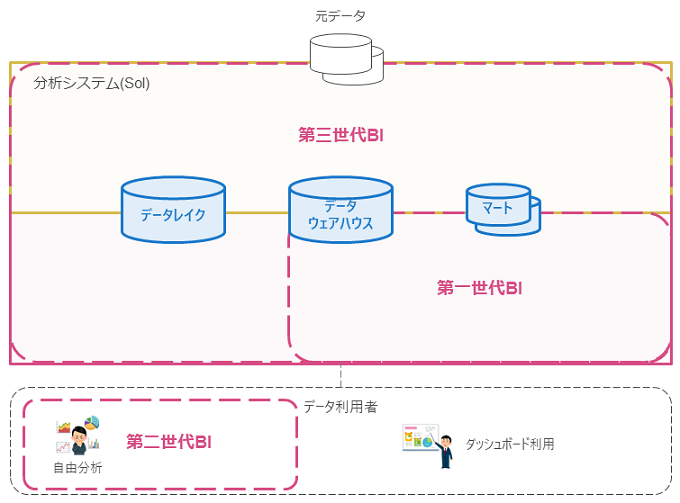
特にダッシュボード利用のユースケースの場合は、BI(Business Intelligence)ツールを利用するのが基本です。BIツールは企業向けのデータ可視化ツールのことで、特性によって第一世代BI(DWH統合型)、第二世代BI(セルフサービス型)、第三世代BI(ガバナンス型)の3種類に分けて考えることができます(下図)。各世代のBIの特徴を簡単に説明していきます。
第一世代BI(DWH統合型)
第一世代BIは、DWHに蓄積したデータを可視化することを目的に作られた最初期のBIツールです。2010年頃までは、BIツールはほぼこの種類のBIツールが主に利用されていました。このBIは、システム管理者がBIツール上にダッシュボードの画面を作成し、利用者はダッシュボード上のグラフについてドリルダウン、ダイシング、スライシング等の操作(OLAPといいます)により複数の切り口でデータを確認できるようにして利用します。
ダッシュボードのOLAP操作の性能を向上するためには、BIサーバやDWH/データマートにデータ集計処理の内容に合わせたOLAPキューブを定義します。そのため、同じダッシュボードを何年も利用し続ける分には良いですが、ダッシュボードやデータソースの情報を頻繁に変更する場合で、データ蓄積層(DWH層)やデータ連携層(ETL層)側の対応が追い付かなくなることには注意する必要があります。
第二世代BI(セルフサービス型)
第二世代BIは、利用者自身による分析に主眼を置いたセルフサービス型のBIツールです。このBIはモダンBIとも呼ばれ、利用者自身が手元のデータを様々な角度で分析できることに主眼を置いていることが特徴です。技術的には、専用のデータ圧縮技術やそのデータのインメモリ処理技術を利用し、GUIを試行錯誤による分析に主眼を置くことでで、セルフサービスのデータ分析を支援しています。このBIはデスクトップ型ツールとして提供される場合が多いですが、作成した分析レポートは共有サーバにアップロードしてダッシュボードとして他の分析者や意思決定者と共有することも可能です。
セルフサービスBIは、意思決定者に情報をどのような形を提供すべきかが未定で、データ分析スキルを有するデータアナリストが存在する場面に適していると思います。ただし、事前にダッシュボードで提供したい情報が決まっている場合では、このBIよりも第一/第三世代のBIを利用する方が良い場合が多いと思います。
第三世代BI(ガバナンス型)
第三世代BIは、データガバナンスに重点を置いた比較的新しいタイプのBIツールです。第三世代BIでは、接続先データソースを一元的にBIサーバに登録しておき、アクセス権限やダッシュボード管理の設定をBIサーバで仮想的に設定できることが特徴です。あるBI製品ではBIサーバ自体には分析データを保持せず、ダッシュボード定義をコードとしてバージョン管理することができます。このため、データソースやダッシュボード変更時の管理者側の対応は容易ですが、OLAP操作の処理性能はデータソース側のDB側の性能にほぼ完全に依存します。
第三世代BIは、特にデータレイクや大量のデータソースが存在する環境で、データ活用層の認証認可や監査ログを一元的に管理したい場合に力を発揮すると思います。ただし、接続可能なデータソースの範囲を拡大すればするほど、システム管理者の判断や責任や設定負荷が増大しますので、データガバナンスの管理体制について検討されていると良いと思います。
比較表(BI層)
ここまで述べたBIの世代別の違いを、比較表にまとめてみます。
| 項目 | 第1世代BI | 第2世代BI | 第3世代BI |
|---|---|---|---|
| 特徴 | DWH統合型 | セルフサービス型 | ガバナンス型 |
| 流行年代 | 1990年代~ | 2010年代~ | 2020年代~(?) |
| OLAPの主な実行主体 | 接続先DB, BIサーバ | 接続先DB, デスクトップPC | 接続先DB |
| 定型レポート分析 | 得意 | 苦手 | 得意 |
| 自由分析 | 苦手 | 得意 | 苦手 |
| 複数データソースの管理 | 苦手 | 苦手 | 得意 |
データ活用層のシステムとしてどの世代のBIも一長一短ですので、利用者が想定するデータ活用方法に合わせて適切なツールを検討することが重要です。また、近年では世代に関わらずクラウドBIが普及してきていて、BI導入のハードルは低下してきています。
要求スキル(BI層)
データ活用層(BI層)でのデータエンジニアの要求スキルを下記に挙げます。定型的なレポートでは利用者の要望をヒアリングしてダッシュボード設計に落とし込む能力が求められ、自由分析では業務データを理解して利用者の分析を支援できる能力がデータエンジニアに求められると思います。
- ダッシュボード
- 要件のヒアリング
- ダッシュボード設計
- 自由分析
- 業務データ理解
- 分析支援
- 運用設計
- 認証認可管理
- 分析結果管理
2.データ蓄積層(DWH層)
続いて、データ蓄積層(DWH層)について説明します。データ蓄積層(DWH層)は、データ分析に利用するデータを蓄積するための場所です。蓄積先のストレージに対しても、その目的によりデータウェアハウス(DWH | Data Warehouse)、データマート(Data Mart)、**データレイク(Data Lake)**の3種類に分けられることがよくあります(下図)。
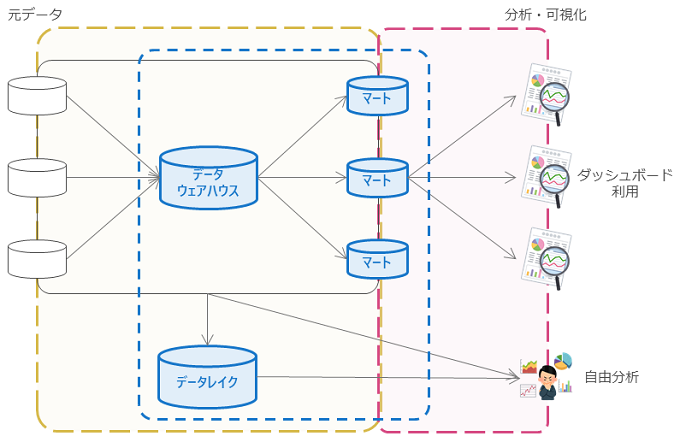
なお、複数のDWHを束ねる大元のDWHを構築する場合、それを**セントラルウェアハウス(CWH | Central Warehouse)**と呼びます。たまに混同されますが、CWHはスキーマオンライトのDBでありデータレイクとは異なります。
データウェアハウス
データウェアハウス(DWH)は、データ基盤の中心的な蓄積先となるスキーマオンライト(Schema-on-Write)のDBです。スキーマオンライトとは、データ保存前にデータモデリングを行いスキーマを定義する必要がある特性のことです。通常はDWHにはRDBを採用し、表形式でデータモデリングを実施してER図を作成します。その後で、業務システムの数千万件以上の履歴データなどを、DWHのスキーマに合わせてデータを変換して投入します。
多くの企業が苦労してDWHを構築している理由は、例えば日別店舗別の売上を確認したいなどで大量データの集計処理(OLAP)を実行するためです。DWHを構築せずにOLAP処理を元データのDBに対して直接実行すると、元データ側のシステム性能リソースを食い潰す懸念があります。DWHはOLAP性能向上に特化するために、ハードウェアが一体となったアプライアンス型製品として提供されたり、カラムストア(列指向)やMPP (Massively Parallel Processing)などの特殊な技術が採用されたりします。また、DWHのOLAP性能を向上するためには、エンジニア側にも特殊なデータモデリング技術(スタースキーマ)やクエリチューニング技術が求められます。このような理由からDWHの導入には苦労が多いのですが、近年では比較的手軽に利用できるクラウドDWHのおかげで導入のハードルは低下してきていて、今までDWHの導入を諦めていた業務でもクラウドOKであれば利用しやすくなってきていると思います。
データマート(マート)
データマートは、特定のデータ利用ケース向けにDWHを小分けにしたスキーマオンライトのDBです。単にマートとも呼ばれます。もし利用者がDWHを直接参照しても問題がなければ、データマートを作成する必要はありません。DWHは他システムからも共通的に利用され、詳細な粒度のデータが大量に含まれます。データマートは、DWHでは特定用途には使いにくいと思われる場合や、半集計済のデータを利用したい場合に用途に応じて作成すればよいです。
データマートではDWH専用のDBではなく、より使い慣れた普通のRDBが利用される場合もよくあります。データマートのモデル変更やデータの入れ直しが発生すると対応の手間が大きいため、データマートは**データ仮想化(DB仮想化)**の機能などで作成した仮想データマートを利用して、物理的なデータマートは利用しないこともあります。仮想データマートを利用する場合は、実行クエリに必要なデータがキャッシュに存在しない場合元DBまでデータを読みに行き、元DBの性能リソースにまで波及する場合もあるので性能設計に注意が必要です。
データレイク
データレイクは**スキーマオンリード(Schema-on-Read)のデータ蓄積先です。スキーマオンリードは、例えばJSONデータやログファイルのようなデータでも、データモデリングを行わずにそのまま蓄積できる特性のことです。むしろ、データレイクでは利用時にデータ信頼性を確認しやすいようにするために、できるだけ元データのままの状態で保存することが推奨されます。データレイクには、一般的にはRDBではなくオブジェクトストレージが採用されます。Hadoopが採用されることもあります。
データレイクはあらゆるデータを簡単に蓄積できる反面、無計画に利用されるとすぐに管理不能になってしまいます。管理不能となったデータレイクはデータスワンプ(Data Swamp)と呼ばれ、データレイクを運用する上での大きな課題になります。データスワンプになることを防ぐためには、データカタログを構築してデータレイクに蓄積したデータのメタデータや認証認可の管理を行うようにする方法が考えられています。
データカタログはデータレイクの管理のために有力なツールではありますが、単に導入するだけでデータを管理できるようにはなりません。データレイク上のデータは常に変化するため、その変化に合わせてデータカタログ上のメタデータやアクセス権限設定も更新しなければならないためです。メタデータは大きく「技術メタデータ」と「業務メタデータ」に分類することができます。「技術メタデータ」はデータカタログの機能でシステム的な自動更新が可能ですが、「業務メタデータ」はほとんどのケースでデータスチュワード(Data Steward)**による手動更新が必要です。そのため、データレイクの管理には、データスチュワードを含むデータ管理チームを作るといった組織的な対応も必要になります。
比較表(DWH層)
ここまでに述べたデータ蓄積用DBの違いを比較表にまとめてみました。
| 項目 | データウェアハウス | データマート | データレイク |
|---|---|---|---|
| スキーマ定義 | スキーマオンライト(Schema-on-Write) | スキーマオンライト(Schema-on-Write) | スキーマオンリード(Schema-on-Read) |
| 主な用途 | 定型分析 | 定型分析 | 自由分析 |
| 主な利用ユーザ | システム管理者 | システム管理者 | システム管理者, データ分析者 |
| 主なDBの種類 | RDB(DWH専用) | RDB | オブジェクトストレージ |
| データ状態 | 加工整形済 | 加工整形済 | そのまま(As-Is) |
| データ管理 | 管理しやすい | 管理しやすい | 大変 |
| 主な元データ | 業務DB | データウェアハウス | あらゆる元データ |
DWHとデータレイクの最大の違いはスキーマオンライトとスキーマオンリードの違いです。データレイクは管理が非常に困難なので、まずはDWHとデータマートの導入から検討して、それでは活用できないデータが顕在化してきてから本格的にデータレイクを検討し始めるのが良いと思います。
要求スキル(DWH層)
データ蓄積層(DWH層)でのデータエンジニアの要求スキルを下記に挙げます。DWHでは大量データ処理の性能設計技術が、データレイクではメタデータや認証認可の運用設計技術が求められやすいと思います。
- 性能設計
- データモデリング
- 索引設計/チューニング
- DB管理
- RDBMS
- NoSQL / Hadoop1
- 運用設計
- メタデータ管理
- 認証認可管理
3. データ連携層(ETL層)
最後に、データ連携層(ETL層)について説明します。データ連携層(ETL層)は、元データのDBから投入先DBへのデータ処理(データパイプライン)が実行される層です。データパイプラインの種類には、大きく分けてバッチ処理とストリーム処理があります。
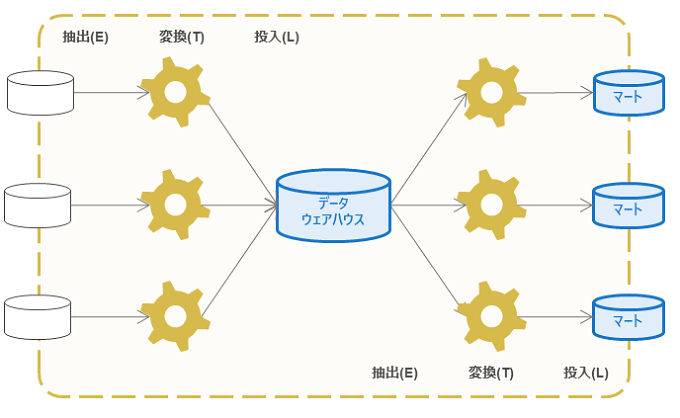
分析システム(SoI)では、よくデータのサイロ化の課題が取り上げられます。サイロ化とは、分析対象となるデータが複数の業務システムに散在していて、データ活用が困難になった状態のことを言います。データ連携層ではデータパイプラインを作成してDB間のデータ処理を繋ぎ合わせることで、散在した業務システムのデータをデータ活用層で利用できるようにします。
ただし、データパイプラインは継ぎ足しながら開発していくと、徐々に複雑化してデータパイプラインの変更管理や障害対応に時間がかかるようになります。そのため、特に大規模な案件では、データパイプラインの開発にはリネージ(Lineage)を管理可能なETLツールを利用することを推奨しています。データパイプラインのリネージが管理可能であれば、そのリネージを辿ることで元データ変更時の影響先データの調査や、データマートの元データ追跡などが容易に行えるようになります。
バッチ処理
バッチ処理は、一定時間ごとに一まとまりのデータを一括で処理する方式です。データパイプラインにおけるバッチ処理は、Extract(抽出)、Transform(変換)、Load(投入)のそれぞれの頭文字を取ってETLと呼ばれます。ETLは狭義にはE->T->Lの順番によるデータ移行の処理プロセスのことを指しますが、広義には処理プロセスの順番に関わらずDB間のデータ移行のことを指して呼ばれることもあります。
ETLで大量データを移行しようとする場合には、規定時間内にデータ移行を完了できるようにするための性能面の検討が不可欠です。ETLの性能向上施策としては、並列実行やELTへの変更などがあります。ETL処理の並列実行は有効な手段ですが、ETLサーバの構成やETL処理プログラムが並列実行可能かどうか確認する必要があり、実行プログラムの書き換えも必要になります。ELTは、ETLの順番のT(変換)とL(投入)を入れ替えてE->L->Tの順番で実行することで、システム負荷のかかりやすいT(変換)の処理リソースを投入先DB側に委譲する方式です。ETLからELTへの置き換えは、データ投入先がDWHなどの高性能なDBである場合に有効です。いずれにせよ、バッチ処理によるデータ移行の性能を向上させるためには、このような実行プログラムや基盤アーキテクチャの内容を考慮した設計が求められます。
ストリーム処理
ストリーム処理は、連続的なデータをリアルタイムに連携する方式で、例えばIoTデータや、ログ監視データ、SNSデータなどはこの方式によりデータを連携します。ストリーム処理では、大量データの流入や投入先DBの障害等によるデータ損失を防ぐために、**メッセージキューイング(MQ | Message Queuing)**を利用します。メッセージキューイングにより連携データを一時的にバッファに保管することで、連続的なデータでも安定して連携先システムに配信できるようになります。メッセージキューイングの内容ついては、下記スライドが分かりやすいと思いました。
また、ストリーム処理はDB間の**データレプリケーション(複製)でも利用されています。データレプリケーションでは、複製元DBのデータ更新時に生成されるトランザクションログ2を複製先DBに転送することで、転送先DBで更新データの内容を再現できます。このトランザクションログのDB間転送のストリーム処理の技術をCDC(Change Data Capture)**と呼び、DB間のデータ複製でリアルタイム性が要求される場合はこの機能の利用も選択肢の一つになります。
要求スキル(ETL層)
データ連携層(ETL層)でのデータエンジニアの要求スキルを下記に挙げます。SQLが書けることはほぼ必須です。
- パイプライン設計
- バッチ処理
- ストリーム処理
- プログラミング
- SQL
- Java / Python / Spark
- 運用設計
- 性能/障害対応
- 変更管理
最後に
データエンジニアが携わる分析システムの領域は専門用語がとても多く、最初は何の話をしているのか私は全く分かりませんでしたが、この記事で述べたように、データ基盤をBI層、DWH層、ETL層の3階層に分けると考えやすくなると思います。
**「ガベージイン・ガベージアウト(GIGO | Garbage in, Garbage out)」**と言われるように、データ基盤の整備が不十分な状態だとAIシステムやデータサイエンティストの力を十分に発揮させることができません。最強のデータ基盤を作るとともに、その基盤を設計できるようにデータエンジニアリング力を向上させましょう。
関連リンク
データエンジニアやデータ基盤の仕事に関連してそうなリンク。