なんの話?
三行で。
- サービスが急成長しデータ量が増えた際にデータエンジニアリングは必要とされる。
- エンジニアリングに必要なスキルセットは比較的明確で、駆け出しエンジニアにもポジションあるよ。
- データエンジニアリング業務を経て、データサイエンティストなど他職種にランクアップすることは可能。
[おまけ1] "data+engineer+positionでググる"と、主に海外のData Engineer(DE職)のお仕事が入門者レベルからエキスパートレベルまで見つかるよ...Tokyoをつけると、東京でのDE職も見つかる。転職活動で普通に有用。
*[おまけ2] 末尾におまけとして、現在私が取り組んでいる『2020年代のデータ分析基盤の基本設計』に関して日々調べていることを、公開できる範囲で書いておきたい(内容はコメント欄に随時更新)。実際のデータエンジニアリング実務の一端を知ってもらう意味で。これを見て、面白そうと思った方は、データエンジニアにジョブチェンジしていただいて、どこかで出会えたら嬉しいな。
データエンジニアリングは、データサイエンスで稼ぐための前提条件。
データを扱う医療系エンジニア職について軽く紹介した医薬系データエンジニアのはじめ方、稼ぎ方についてのエントリーを書いた後、何人かの方に医薬系のエンジニア職について質問をいただいた。そのほぼ全てがデータサイエンティスト職に関する質問だったことに(ある程度予想していたが)ちょい驚いた。確かにデータサイエンティストはバズワードで終わらずに給料高めの花形職業として定着したっぽいし、皆さんの関心も高いのだろう。あと、データサイエンティストと一般的ITエンジニアとは結構区分けしやすいのに対し、データエンジニアとITエンジニアの区分は曖昧(以下で述べる)。データエンジニア(DE)という職位を置く企業よりも、ITアーキテクトなどの職位がデータエンジニアリング業務を行っている企業の方が多いだろうし。
とはいえ、データサイエンティストが生涯収入ド高めとなる最短コースの一典型は、強力なデータ処理基盤を持ったベンチャー(含、ヘルステックベンチャー)で活躍すること。今回は、企業がデータサイエンス手法を用いて稼ぐための前提となる、データ基盤の構築を担うデータエンジニア(と位置付けられるエンジニア)がデータ処理基盤を構築するために何をしているのかについて、ポエムを書きたい(先達たちのブログを紹介したり、私が取り組んでいることを紹介したり)。
データエンジニアによるデータエンジニアリング業務の世間一般の知名度は低いのだろうけれど、じっくり取り組めば安定的に稼げる仕事だよといった意味合いも改めて込めて。その先に、ド高めの生涯年収が待っているかどうかは、その人次第だけれどもね。
いけてるベンチャーの機械学習プラットフォームたち
はじめに、明らかにデータサイエンティストが稼ぎを支えている、有名どころのベンチャーのデータエンジニアリングの成果物(機械学習プラットフォーム)を概観しておこう。
出典は、ブログ『Apache Airflowでエンドユーザーのための機械学習パイプラインを構築する』。現役データエンジニアと思われる方が、冒頭でいけてるベンチャーたちの機械学習プラットフォームを列挙してくれている。
注 Apache Airflowは、データエンジニアリング職人たちがデータ処理用パイプラインを構築するための道具(Airflow入門に良いスライドはこちら)。
例1: Uberの機械学習プラットフォーム『Michelangelo』:
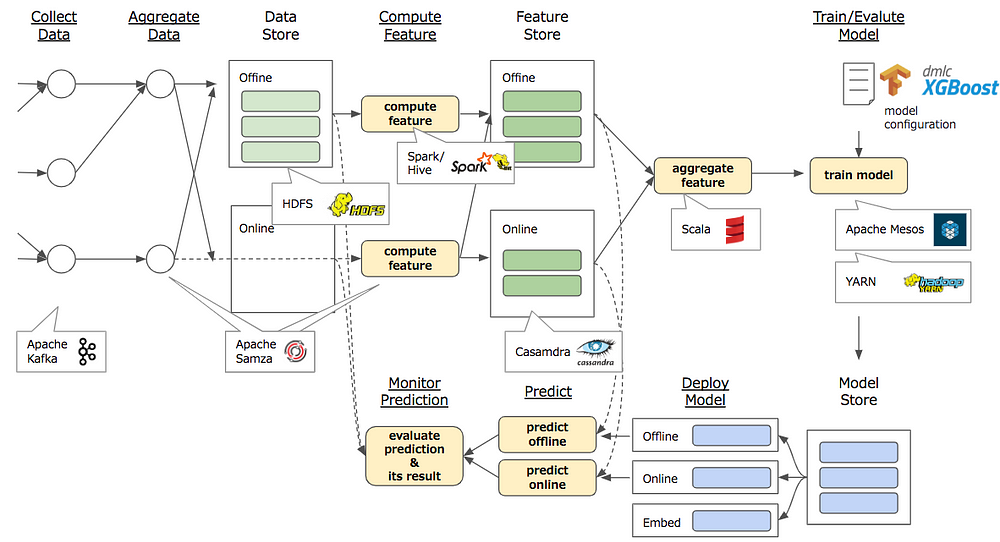
図の右側に"train model"とあるように、このプラットフォームはUberのサービスで発生する膨大なデータを訓練データとして、何らかの機械学習モデルを行い、予測(Predict)を行うパイプラインだと分かる。HDFS/Spark/Hive/Cassandra/Mesosといったビックデータ界隈ではおなじみの道具がいくつも組み合わせられていることがUberのサービスの規模感を示している。
Uberでは、Michelangeloプラットフォームがサービスの現場データを扱いやすい形でデータサイエンティスト(あるいは機械学習エンジニア)に送り届け続けることが、ビジネスを成長させるための大前提になっているわけだ。こうしたプラットフォームは、多くのデータエンジニアによって構築されている。いわゆるデータエンジニアリング業務の典型例だ。
例2: Twitterの「Deepbird-v2」
「Deepbird」については、Twitter社自身のブログによる紹介を見ておこう。
ブログは、以下のような言葉から始まる。
Machine learning enables Twitter to drive engagement, surface content most relevant to our users, and promote healthier conversations. As part of its purpose of advancing AI for Twitter in an ethical way, Twitter Cortex is the core team responsible for facilitating machine learning endeavors within the company. ※抜粋意訳 : 機械学習の力により、Twitter社は...(ここには書かないけど広告収入の売り上げを増やすことができ)...ユーザーが関心を持ちそうなコンテンツを送り届けられるようになると共に、ユーザー間での健全な対話を促進できるようになる。進歩したAIによりTwitterがより倫理的になるという、この目的の一環として、Twitter Cortexは、社内の機械学習力を高めていくコアとして働く責任がある。
このブログが書かれた2018年の初夏頃に、フェークニュースを拡散するツイート等が問題視された後、Twitterの株価は急落した。それに先んじて、Twitterのエンジニアチームは、AIの力で、フェークニュース等の問題に対処する取り組みを進めていたわけだ(2019年7月末になって、Twitterの株価は急騰しているね=>ツイッター、第2四半期は予想上回る増収 広告収入が好調)。
Uberの図に比べ、上の「Deepbird」の方は単純なように見えるだろうけれど、幾多の言語で次々と発せられるツイートを学習データに機械学習を行うためのプラットフォームの構築が簡単なわけはない。腕利きのScalaエンジニアが多数在籍することで有名のTwitterのエンジニアチームのデータエンジニアリング力は、極めて高いと推測される。
Who uses DeepBird?(誰がDeepBirdを使うの?)
DeepBird is used by Twitter researchers, engineers, and data scientists. ML theory and technology experience varies from the beginner to expert level. Not everyone has a PhD in ML, but again, some do. Our goal is to satisfy most users on the spectrum of ML knowledge. ※超訳 DeepBirdは、Twitterのリサーチャー、エンジニア、そしてデータサイエンティストによって使われている。メンバーの機械学習についての理論・技術の経験は、ビギナーから熟練者までさまざまだ。皆が学位(PhD)を持っているわけではないけれども、何人かもっているさ。我々のゴールは、機械学習知識の幅広いスペクトラムを持つ社内ユーザーたちの大多数を満足させることだね。

上の矢印において、データサイエンティストが左に、リサーチサイエンティストが右に位置付けられ、真ん中に位置づけられたソフトウェアエンジニアがapplied ML(実践的機械学習)を担うとされているのが、興味深い。ソフトウェアエンジニアの地位が高いTwitterらしいが、この何割かは他社ではデータエンジニアと呼ばれる職務を行っているものと思う。
Airbnbのデータサイエンティストによる『(翻訳) データエンジニアリングビギナーズガイド』
こちらは、大学院を出てから小さなスタートアップでデータサイエンティストとしてエンジニア生活をスタートさせた方が、Airbnbの(花形)データサイエンティストになるまでに身につけたデータエンジニアリングの基本技術を分かりやすく解説してくれている記事(良翻訳)。Apache Airflowによるワークフロー定義、データを扱うバッチ処理、およびSQL的言語(※)といった、3つの技術のさわりが紹介される。データサイエンティストというキャリアを充実したものとするための手段のひとつとしてのデータエンジニアリング力がわかりやすく解説されている。
(※)RDBおよびNoSQL(NotOnlySQL)の双方のデータベースにクエリを投げられる言語のことと思われる(例、Impalaのコマンド)
確かに、いわゆるビックデータを扱うワークフロー定義と、個々のデータを扱うバッチ処理の記述、そして、SQLや個別のDSL等を駆使してのクエリ的言語の作成はデータエンジニアリングの中心となる業務であり、データサイエンティストを志す上でも必要なスキルだ(全てが必須ではないにしても、データエンジニアリングをマスターしておくことがキャリア戦略上望ましい、という意味で)。現場で必要となるこうしたスキルが高めの人は、統計学や機械学習手法の知識に多少不十分なところがあるとしても、重宝されることだろう。
データエンジニアのキャリアプランとしてのデータサイエンティスト
...と、データサイエンティストにとっても、データエンジニアリングは重要なんだよ、というブログを紹介した後で、本屋でデータサイエンティストになるための入門書と思われる『データサイエンティスト養成読本 登竜門編』という本を見つけ、目次をパラパラ開いてみた。

あらら、以下の内容紹介にある通り、本のほとんどがデータエンジニアリングについての記述ではないですか。
内容紹介
データサイエンティストはここ数年で生まれた職種です。どんなスキルを身に付ければ良いかはいろいろなところで語られ、現役のデータサイエンティストのスキルもバラバラなのが現実です。さまざまな技術がある中で、本書ではデータ分析をはじめる前に最低限知っておきたい知識を取り上げます。たとえば
シェルの操作は知らなくても良いでしょうか?
基本的なSQLは書けなくても良いでしょうか?
データ形式についての知識は不要でしょうか?
機械学習の基礎知識は不要でしょうか?
出典 https://www.amazon.co.jp/exec/obidos/ASIN/4774188778/keiku-22/
この登竜門編の内容をマスターしても、例えば、著名データサイエンティストブロガー(?)のTJO氏の求めるデータサイエンティストのスキル要件は満たすことはできないと思われるが、データエンジニアとしてのキャリアをスタートさせることはできるだろう。データ分析の基礎知識は、まずはデータエンジニアリングの現場で役に立つ。そして、データサイエンティストにとってもほぼ必須の基礎素養である、と。
ただし、上のairbnbの方のように、データエンジニアからデータサイエンティストになるのが、キャリア戦略として常に正しいかというと、そうではないと思っている。
データサイエンティスト志望でこのポエムを読んている方は、データサイエンティストTJO氏の『データ分析人材の長期的キャリアという迷宮』をまずは読んでから以下を読み進めてほしい。
以下、まずは今後数年のデータエンジニア業界の展望を描いたうえで、非データサイエンティストのデータエンジニアである私の視点で、データエンジニアの中長期のキャリア戦略について書いていく。
2020年代の(日本人)データエンジニアのキャリアの積み方
さて、データエンジニアというお仕事は今後、どうなっていくのだろうか?
端的に言えば、業務内容の根本(データを適切に処理し必要なクエリをかけやすい形する)は変わらずに、待遇もさほど変わらず、だと思う。
データが21世紀の原油かどうかの話は問題設定の仕方次第(これとかこれとか)だとして、集められたデータは適切に加工する必要がある(いわゆるETL)。この業務を担うのは、多くのグローバル企業ではデータエンジニアと見なされる人々だ。
もちろん、国内のベンチャー企業にもデータエンジニアリング業務をしている方々はいる。
特に、ユーザーが堅調に増加し、データ量が増えている現場においてだ。例えば、ChatworkでPHPからscalaへの移行を担った方々が該当する(データエンジニアと自任しているわけではない方々ではないでしょうが)。
(インタビュー記事より引用) チャットのメッセージはかなりの流量なので技術的にはすごい面白いところではあります。...スマホが流行して以来、小さなリクエストを非同期で次々に捌く必要が出てきて、そういった問題解決に対してはScalaが妥当だろうと思っていました。Twitterがそれを証明したという後ろ盾の影響も大きいのですが...
『ひとつひとつのサイズは小さいが、大量のメッセージをさばき続ける必要性』に応えることに特化したデータエンジニアリングがここにはある。
サービスが急成長した場合、ほぼ確実に多量又は多数のデータが発生する。そうした現場で必要とされるのは、まずは、正しいデータエンジニアリングだ。Twitterでもそうであったように、データサイエンティストが真価を発揮するのは、データ処理が適切に行えるようになってから。
2020年代でも、データエンジニアのあるべき姿の典型は、データが急増していく現場にまっさきにかけつけ、データがあふれないように努めることだと思う。当然ながら、テクノロジー・スタックは時々で変わっていくにしても。
GAFAのようにグローバルにデータを持っているところや、BATのように世界最大の人口を抱える国を地盤としている企業に比べると、日本のベンチャーはスケールが小さくて、といった話を聞く(少なくともユーザー数については確かにその通り)。でも、日本国内に限っても、多くのデータを抱えている現場、抱えるようになっていく現場は数多くある。
(いかにもポエムっぽい言い方だが)急増するデータと肥大化するクラスタを前に、データエンジニアリングを行う心構えと技術力とを持っていれば、日本においてもデータエンジニアとしてのキャリアを積んでいけるだろう。
データエンジニアのキャリアアップの道
① CTO(最高技術責任者)の道
データエンジニアリングは技術力が試される格好の場。最高のデータ分析基盤を設計できる人は間違いなく一流のエンジニアといって良いだろう。故に、データエンジニアリングを極める方のキャリアの王道は、データを扱う企業のCTO(最高技術責任者)だろう。その他、もちろん、大企業であれば、データエンジニアリング部門のディレクター(部長~重役?)も、待遇面ではキャリアの到達点として申し訳ないだろう。
残念ながら、私にはCTOになれるだけの技術力はないので、技術力ある方をリスペクトするに留め、この道は選んでいない。
② (使える)データサイエンティストの道
データエンジニアがデータサイエンティストになって、収入をジャンプアップさせる例は多いだろう。キャリアップしては有望な道だ。
ただし、である。データサイエンティストは、統計の知識、地頭の良さに加え、社内政治とうまく付き合っていける要領の良さが求められる、悩ましいお仕事、らしい。
データサイエンティストの何が悩ましいかは、(ここまで読み進めた方の多くはご存じだろうが)TJO氏が常々語ってくれている。
https://tjo.hatenablog.com/
私は本質的なところ以外では平穏に生きたいので、データサイエンティストという道は選んでいない。...統計学が不得意分野だったというのもあるんだけどね。統計弱い人は、使えるデータサイエンティストになれないかもしれないから要注意ね。
③ サービスを成長させるプロダクトマネージャーの道
いい年してデータエンジニアとしてのキャリアは少なめな私が志向している道がこちら。
プロダクトマネージャーとは、もともとは経営学用語であって『企業においてマーケティング活動全般の権限と責任を持つ管理者を担当する職種』らしいが、IT業界では、「ITサービス・プロダクトを立ち上げスケールさせていくための活動全般の権限と責任を持つ職種」といった意味あいを持つ。私が志向しているのも後者。特に多くのデータを扱うITサービス・プロダクトを立ち上げ、スケールさせていくことをマネージしていきたいと思っている。
サービスが急成長している場合に起きる諸々は、現場から得られるデータの中にある...と書くと、現場のデータをさっそうと分析をするデータサイエンティストが活躍しそうな気がするのだけれども、実のところ、それ以上にサービスがどの方向を向くべきか、サービスの成長をどこまで指向するか、逆にどこを守るか、といった調整事は鬼のようにあるのだろう(私が携わってきた多くはない経験からというよりは、例えば、PayPayや7-Payのの立ち上げ過程で起きた事件の背景を考えるだけでも、スケールするサービスの立ち上げが複雑系であることは用意に想像がつくこと)。
プロダクトマネージャーについて、ここで多くを語りはしないけれども、今後のITプロダクト立ち上げスケールさせていく過程では、自らデジタルマーケティング手法を使いこなしつつ、データ分析系職種として、ここに書かれているアナリティクスディレクターのようなポジションの方を交えて、サービスの進む道を調整し続けることが必要条件となることが大多数と思っている。こうしたマネジメント業務で、データエンジニアとして現場のデータを扱い続けた際の勘は役に立つものと考えている。あと、ざっとしたデータ分析ならば自分でできる、というのはサービスの進む道を決める意思決定のスピードを上げるための一つの武器になるかと。
委細はここでは書かないとして、データエンジニアから技術や統計の道ではなく、マネージメントの道に進むのもキャリア戦略としてはあり、と私は思う。
データエンジニア実務に役立つ基本書。
2019年7月時点、データエンジニア実務に役立つ日本語書籍としては『データ指向アプリケーションデザイン ――信頼性、拡張性、保守性の高い分散システム設計の原理』一択かと。

個々の技術スタックの要否・新旧はさておいて、以下の目次の項目を見るだけでも、データ分析基盤を作るための基本の『いろはにほへと』がされていると思われる。この目次のレベルで知らないタームはないことがデータエンジニアとしては理想的か。
といいつつ、私はまだつまみ読みしかしていないのけれども、日本を代表するデータ分析基盤会社のバリバリのエンジニアの方が監訳者を務めるこの本を、私は通勤電車でKindleでちまちまと読んでいくよ。
監訳者まえがき
はじめに
第I部データシステムの基礎
1章 信頼性、スケーラビリティ、メンテナンス性に優れたアプリケーション
1.1 データシステムに関する考察
1.2 信頼性
1.2.1 ハードウェアの障害
1.2.2 ソフトウェアのエラー
1.2.3 ヒューマンエラー
1.2.4 信頼性の重要度
1.3 スケーラビリティ
1.3.1 負荷の表現
1.3.2 パフォーマンスの表現
1.3.3 負荷への対処のアプローチ
1.4 メンテナンス性
1.4.1 運用性:運用担当者への配慮
1.4.2 単純さ:複雑さの管理
1.4.3 進化性:変更への配慮
まとめ
2章 データモデルとクエリ言語
2.1 リレーショナルモデルとドキュメントモデル
2.1.1 NoSQLの誕生
2.1.2 オブジェクトとリレーショナルのミスマッチ
2.1.3 多対一と多対多の関係
2.1.4 ドキュメントデータベースは歴史を繰り返すのか?
2.1.5 今日のリレーショナルデータベースとドキュメントデータベース
2.2 データのためのクエリ言語
2.2.1 Web上での宣言的クエリ
2.2.2 MapReduceでのクエリ
2.3 グラフ型のデータモデル
2.3.1 プロパティグラフ
2.3.2 Cypherクエリ言語
2.3.3 SQLでのグラフクエリ
2.3.4 トリプルストアとSPARQL
2.3.5 礎となったもの:Datalog
まとめ
3章 ストレージと抽出
3.1 データベースを駆動するデータ構造
3.1.1 ハッシュインデックス
3.1.2 SSTableとLSMツリー
3.1.3 Bツリー
3.1.4 BツリーとLSMツリーの比較
3.1.5 その他のインデックス構造
3.2 トランザクション処理か、分析処理か?
3.2.1 データウェアハウス
3.2.2 スターとスノーフレーク:分析のためのスキーマ
3.3 列指向ストレージ
3.3.1 列の圧縮
3.3.2 列ストレージにおけるソート順序
3.3.3 列指向ストレージへの書き込み
3.3.4 集計:データキューブとマテリアライズドビュー
まとめ
4章 エンコーディングと進化
4.1 データエンコードのフォーマット
4.1.1 言語固有のフォーマット
4.1.2 JSON、XML、様々なバイナリフォーマット
4.1.3 ThriftとProtocol Buffers
4.1.4 Avro
4.1.5 スキーマのメリット
4.2 データフローの形態
4.2.1 データベース経由でのデータフロー
4.2.2 サービス経由でのデータフロー:RESTとRPC
4.2.3 メッセージパッシングによるデータフロー
まとめ
第II部分散データ
II.1 高負荷に対応するスケーリング
II.1.1 シェアードナッシングアーキテクチャ
II.2 レプリケーションとパーティショニング
5章 レプリケーション
5.1 リーダーとフォロワー
5.1.1 同期と非同期のレプリケーション
5.1.2 新しいフォロワーのセットアップ
5.1.3 ノード障害への対処
5.1.4 レプリケーションログの実装
5.2 レプリケーションラグにまつわる問題
5.2.1 自分が書いた内容の読み取り
5.2.2 モノトニックな読み取り
5.2.3 一貫性のあるプレフィックス読み取り
5.2.4 レプリケーションラグへの対処方法
5.3 マルチリーダーレプリケーション
5.3.1 マルチリーダーレプリケーションのユースケース
5.3.2 書き込みの衝突の処理
5.3.3 マルチリーダーレプリケーションのトポロジー
5.4 リーダーレスレプリケーション
5.4.1 ノードがダウンしている状態でのデータベースへの書き込み
5.4.2 クオラムの一貫性の限界
5.4.3 いい加減なクオラム(sloppy quorum)とヒント付きのハンドオフ
5.4.4 並行書き込みの検出
まとめ
6章 パーティショニング
6.1 パーティショニングとレプリケーション
6.2 キー‐バリューデータのパーティショニング
6.2.1 キーの範囲に基づくパーティショニング
6.2.2 キーのハッシュに基づくパーティショニング
6.2.3 ワークロードのスキューとホットスポットの軽減
6.3 パーティショニングとセカンダリインデックス
6.3.1 ドキュメントによるセカンダリインデックスでのパーティショニング
6.3.2 語によるセカンダリインデックスでのパーティショニング
6.4 パーティションのリバランシング
6.4.1 リバランスの戦略
6.4.2 運用:自動のリバランスと手動のリバランス
6.5 リクエストのルーティング
6.5.1 パラレルクエリの実行
まとめ
7章 トランザクション
7.1 トランザクションというとらえどころのない概念
7.1.1 ACIDの意味
7.1.2 単一オブジェクトと複数オブジェクトの操作
7.2 弱い分離レベル
7.2.1 Read Committed
7.2.2 スナップショット分離とリピータブルリード
7.2.3 更新のロストの回避
7.2.4 書き込みスキューとファントム
7.3 直列化可能性
7.3.1 完全な順次実行
7.3.2 ツーフェーズ(2相)ロック(2PL)
7.3.3 直列化可能なスナップショット分離(SSI)
まとめ
8章 分散システムの問題
8.1 フォールトと部分障害
8.1.1 クラウドコンピューティングとスーパーコンピューティング
8.2 信頼性の低いネットワーク
8.2.1 ネットワークのフォールトの実際
8.2.2 フォールトの検出
8.2.3 タイムアウトと限度のない遅延
8.2.4 同期ネットワークと非同期ネットワーク
8.3 信頼性の低いクロック
8.3.1 単調増加のクロックと時刻のクロック
8.3.2 クロックの同期と正確性
8.3.3 同期クロックへの依存
8.3.4 プロセスの一時停止
8.4 知識、真実、虚偽
8.4.1 真実は多数決で決定される
8.4.2 ビザンチン障害
8.4.3 システムモデルと現実
まとめ
9章 一貫性と合意
9.1 一貫性の保証
9.2 線形化可能性
9.2.1 システムを線形化可能にする条件は?
9.2.2 線形化可能性への依存
9.2.3 線形化可能なシステムの実装
9.2.4 線形化可能にすることによるコスト
9.3 順序の保証
9.3.1 順序と因果関係
9.3.2 シーケンス番号の順序
9.3.3 全順序のブロードキャスト
9.4 分散トランザクションと合意
9.4.1 アトミックなコミットと2相コミット(2PC)
9.4.2 分散トランザクションの実際
9.4.3 耐障害性を持つ合意
9.4.4 メンバーシップと協調サービス
まとめ
第III部導出データ
III.1 記録のシステム(Systems of Record)と導出データ
III.2 各章の概要
10章 バッチ処理
10.1 Unixのツールによるバッチ処理
10.1.1 単純なログの分析
10.1.2 Unixの哲学
10.2 MapReduceと分散ファイルシステム
10.2.1 MapReduceジョブの実行
10.2.2 Reduce側での結合とグループ化
10.2.3 map側での結合(map-side join)
10.2.4 バッチワークフローの出力
10.2.5 Hadoopと分散データベースとの比較
10.3 MapReduceを超えて
10.3.1 中間的な状態の実体化
10.3.2 グラフとイテレーティブな処理
10.3.3 高レベルAPIと様々な言語
まとめ
11章 ストリーム処理
11.1 イベントストリームの転送
11.1.1 メッセージングシステム
11.1.2 パーティション化されたログ
11.2 データベースとストリーム
11.2.1 システムの同期の保持
11.2.2 変更データのキャプチャ
11.2.3 イベントソーシング
11.2.4 状態、ストリーム、イミュータビリティ
11.3 ストリームの処理
11.3.1 ストリーム処理の利用
11.3.2 時間に関する考察
11.3.3 ストリームの結合
11.3.4 耐障害性
まとめ
12章 データシステムの将来
12.1 データのインテグレーション
12.1.1 データの導出による特化したツールの組み合わせ
12.1.2 バッチ処理とストリーム処理
12.2 データベースを解きほぐす
12.2.1 データストレージ技術の組み合わせ
12.2.2 データフロー中心のアプリケーション設計
12.2.3 導出された状態の監視
12.3 正確性を求めて
12.3.1 データベースのエンドツーエンド論
12.3.2 制約の強制
12.3.3 適時性と整合性
12.3.4 信頼しつつも検証を
12.4 正しいことを行う
12.4.1 予測分析
12.4.2 プライバシーと追跡
まとめ
用語集
索引
もう一冊、データエンジニアリング業務のアウトプットは全て英語でまとめなければならない私にとっての基本書『Next-Generation Big Data : A Practical Guide to Apache Kudu, Impala, and Spark』を紹介しておく。

こちらは、タイトルはなかなか勇ましいが内容は入門レベルの記述が多い。以下の目次(抜粋)を見ても、かなり具体的な記述が多く、抽象度が低いことがわかるだろう。ただ、私の実務には役立つ情報が書かれている。
Table of Contents
About the Author xvii
About the Technical Reviewer xix
Acknowledgments xxi
Introduction xxiii
Chapter 1 Next-Generation Big Data 1 (6)
About This Book 2 (1)
Apache Spark 2 (1)
Apache Impala 3 (1)
Apache Kudu 3 (1)
Navigating This Book 3 (2)
Summary 5 (2)
Chapter 2 Introduction to Kudu 7 (50)
Kudu Is for Structured Data 9 (1)
Use Cases 9 (3)
Relational Data Management and Analytics 10 (1)
Internet of Things (IoT) and Time Series 11 (1)
Feature Store for Machine Learning 12 (1)
Platforms
Key Concepts 12 (1)
Architecture 13 (1)
Multi-Version Concurrency Control (MVCC) 14 (1)
Impala and Kudu 15 (4)
Primary Key 15 (1)
Data Types 16 (1)
Partitioning 17 (2)
Spark and Kudu 19 (5)
Kudu Context 19 (5)
Kudu C++, Java, and Python Client APIs 24 (10)
Kudu Java Client API 24 (3)
Kudu Python Client API 27 (2)
Kudu C++ Client API 29 (5)
Backup and Recovery 34 (1)
Backup via CTAS 34 (1)
Copy the Parquet Files to Another Cluster 35 (8)
or S3
Export Results via impala-shell to 36 (1)
Local Directory, NFS, or SAN Volume
Export Results Using the Kudu Client API 36 (2)
Export Results with Spark 38 (1)
Replication with Spark and Kudu Data 38 (2)
Source API
Real-Time Replication with StreamSets 40 (1)
Replicating Data Using ETL Tools Such 41 (2)
as Talend, Pentaho, and CDAP
Python and Impala 43 (1)
Impyla 43 (1)
pyodbc 44 (1)
SQLAIchemy 44 (1)
High Availability Options 44 (3)
Active-Active Dual Ingest with Kafka 45 (1)
and Spark Streaming
Active-Active Kafka Replication with 45 (1)
MirrorMaker
Active-Active Dual Ingest with Kafka 46 (1)
and StreamSets
Active-Active Dual Ingest with 47 (1)
StreamSets
Administration and Monitoring 47 (4)
Cloudera Manager Kudu Service 47 (1)
Kudu Master Web Ul 47 (1)
Kudu Tablet Server Web Ul 48 (1)
Kudu Metrics 48 (1)
Kudu Command-Line Tools 48 (3)
Known Issues and Limitations 51 (1)
Security 52 (1)
Summary 53 (1)
References 53 (4)
Chapter 3 Introduction to Impala 57 (44)
Architecture 57 (6)
...
Chapter 4 High Performance Data Analysis 101 (12)
with Impala and Kudu
Primary Key 101 (1)
Data Types 102 (1)
Internal and External Impala Tables 103 (1)
Internal Tables 103 (1)
External Tables 104 (1)
Changing Data 104 (2)
Inserting Rows 104 (1)
Updating Rows 105 (1)
Upserting Rows 105 (1)
Deleting Rows 105 (1)
Changing Schema 106 (1)
Partitioning 106 (3)
Hash Partitioning 106 (1)
Range Partitioning 106 (1)
Hash-Range Partitioning 107 (1)
Hash-Hash Partitioning 108 (1)
List Partitioning 108 (1)
Using JDBC with Apache Impala and Kudu 109 (1)
Federation with SQL Server Linked Server 110 (1)
and Oracle Gateway
Summary 111 (1)
References 111 (2)
Chapter 5 Introduction to Spark 113 (46)
...
Chapter 6 High Performance Data Processing 159 (72)
with Spark and Kudu
Spark and Kudu 159 (1)
Spark 1.6.x 159 (1)
Spark 2.x 160 (1)
Kudu Context 160 (68)
Inserting Data 161 (1)
Updating a Kudu Table 162 (1)
Upserting Data 163 (1)
Deleting Data 164 (1)
Selecting Data 165 (1)
Creating a Kudu Table 165 (1)
Inserting CSV into Kudu 166 (1)
Inserting CSV into Kudu Using the 166 (1)
spark-csv Package
Insert CSV into Kudu by 167 (1)
Programmatically Specifying the Schema
Inserting XML into Kudu Using the 168 (3)
spark-xml Package
Inserting JSON into Kudu 171 (2)
Inserting from MySQL into Kudu 173 (5)
Inserting from SQL Server into Kudu 178 (10)
Inserting from HBase into Kudu 188 (6)
Inserting from Solr into Kudu 194 (1)
Insert from Amazon S3 into Kudu 195 (1)
Inserting from Kudu into MySQL 196 (2)
Inserting from Kudu into SQL Server 198 (3)
Inserting from Kudu into Oracle 201 (4)
Inserting from Kudu to HBase 205 (3)
Inserting Rows from Kudu to Parquet 208 (2)
Insert SQL Server and Oracle DataFrames 210 (4)
into Kudu
Insert Kudu and SQL Server DataFrames 214 (4)
into Oracle
Spark Streaming and Kudu 218 (4)
Kudu as a Feature Store for Spark MLlib 222 (6)
Summary 228 (1)
References 228 (3)
Chapter 7 Batch and Real-Time Data 231 (144)
...
Chapter 8 Big Data Warehousing 375 (32)
...
Chapter 9 Big Data Visualization and Data 407 (70)
Wrangling
...
Chapter 10 Distributed In-Memory Big Data 477 (18)
Computing
...
Chapter 11 Big Data Governance and 495 (12)
Management
...
Chapter 12 Big Data in the Cloud 507 (30)
Amazon Web Services (AWS) 507 (2)
Microsoft Azure Services 507 (1)
Google Cloud Platform (GCP) 508 (1)
Cloudera Enterprise in the Cloud 509 (1)
Hybrid and Multi-Cloud 509 (1)
Transient Clusters 510 (1)
Persistent Clusters 510 (22)
Cloudera Director 511 (21)
Summary 532 (1)
References 532 (5)
Chapter 13 Big Data Case Studies 537 (12)
Navistar 537 (2)
Use Cases 537 (1)
Solution 538 (1)
Technology and Applications 538 (1)
Outcome 539 (1)
Cerner 539 (2)
Use Cases 539 (1)
Solution 539 (1)
Technology and Applications 540 (1)
Outcome 541 (1)
British Telecom 541 (1)
Use Cases 541 (1)
Solution 542 (1)
Technology and Applications 542 (1)
Outcome 542 (1)
Shopzilla (Connexity) 543 (1)
Use Cases 543 (1)
Solution 543 (1)
Technology and Applications 544 (1)
Outcome 544 (1)
Thomson Reuters 544 (2)
Use Cases 545 (1)
Solution 545 (1)
Technology and Applications 545 (1)
Outcome 546 (1)
Mastercard 546 (1)
Use Cases 546 (1)
Solution 547 (1)
Technology and Applications 547 (1)
Outcome 547 (1)
Summary 547 (1)
References 547 (2)
Index 549
2020年代のデータ分析基盤の基本設計(随時更新)
私は、2020年代に稼働予定の医薬系のBig-Datalakeの基本設計を進めている。
PoC段階では、Hadoop(HDFS)+Kuduの分散クラスタをAirflow+Impala+Kafka+Sparkといった周辺技術を構成していく予定。Kuduは委細はググってほしいが、↑のデータ指向アプリケーションデザイン本にも書かれている、列指向(columnar)をキーコンセプトとしたデータ分析用データベースだ(このあたりを起点に私も微力ながら少しずつKuduを紹介していく予定)。
上の『Next-Generation Big Data』は、この辺りを扱う数少ないKudu本である。現時点では、Kuduは(上の本と関わりのある)Cloudera社のイントラ向けインフラ基盤で動作することが多いが、数年後には、パブリッククラウドでも動作するようになっているかと。そんな時に、データエンジニアリングの実務に取り組む誰かの足掛かりに以下のメモが役立ったらいいなと思う。
以下、まずは、『Next-Generation Big Data』の「Chap4. High Performance Data Analysis with Impala and Kudu」文章を抜き書きしつつ、Kuduを中心としたアーキテクチャ設計で考えたことなどを追記していく。これは、といった進捗があったら(半ば自分向けに)コメントで追記していく。
Kudu is a young project.
Kuduは若い。例えば、多くのRDBが持つ固定小数点数を扱うDecimal型がない、など。
=> 若いプロダクトを使う時には、留意点は一つずつチェックしていかねば。
Kudu's primary key is implemented as a cluster index.
Kuduのプライマリキーは、分散クラスタのインデックスとなる。Kuduは1000テラバイト以上(ペタバイトオーダー)のデータに列指向でアクセスできることを目指して作られている、と続く。
※ ペタバイトオーダーは、データエンジニア界隈で良くみつけるキーワード
Kudu doesn't have an auto-increment feature so you have to include an unique key value when inserting rows to a Kudu table.
Kuduに限らず、Cassandraなどの列指向データベースを用いたデータ分析基盤の設計では、ユニークな主キー(primary key)をどのように設計するかが肝要。
ここは(思うところはいくつかあるものの)私一人では決められないので、いかなる設計とするかの決定は、同僚と議論して決める予定。
...と自分だけでは決められないことが出てきてしまったので、今日はこのあたりで^^;