はじめに
Amazon Athena は、Amazon S3 に格納されたファイルへクエリが打てるサービスです。
RDS を利用するよりも料金が安く、S3 に向けてクエリが打てる大変便利なサービスであり、GCP の BigQuery と近い役割を果たせるのではないか?と感じることがあります。
仕事の関係で Athena に触れる機会があり、作業を進める中でいくつか嵌った点がありましたので、備忘録も兼ねて記事化しました。
本記事では以下の AWS リソースを利用します。
- Amazon S3
- Amazon Athena
- Amazon CloudWatch
- AWS Lambda
- AWS Glue
想定読者
- 業務で Athena を使うことになったので、注意点も兼ねてキャッチアップしたい
- S3にどんなフォーマットで格納すればいいか知りたい
- パーティションを定期的に更新する方法が知りたい
よくある IoT データの処理フロー
IoT デバイスから逐次送付されるデータの処理フローとしては、概ね以下の構造になると思われます。
- 複数の IoT デバイスから、何らかのデータが逐次送付されてくる
- 一旦は Kinesis で受け取り、Lambda をバッチ起動して S3 に格納する
- Athena から S3 にクエリを打ち、 IoT デバイスからのデータを分析する
- QuickSight で集計結果を可視化する

本記事では、2の S3 に格納される 処理から、3 の Athena による集計 処理までを説明します。
また、Athena のパーティションを更新する手法は、以下の2手法を説明します。
- CloudWatch Events から Lambda を定期起動し、パーティション更新コマンドを実行する
- Glue Crawlers によりパーティションを定期更新する
S3 へのデータ格納
Athena からクエリを打つには、Athena がサポートするデータ形式で、 S3 にデータを格納する必要があります。生の IoT データが適切なデータ型でない場合、Lambda などによるパース処理 → Athena 用のS3バケットに格納という事前処理が必要になります。
Athena 対応のデータ形式には以下のものがあります
- CSV
- TSV
- JSON
- カスタム区切り
- Hadoop関連形式
対応データ形式の一覧
また、Athena クエリの WHERE句などで パーティション を使いたい場合、S3 には Hive形式 でデータを格納する必要があります。
パーティションを設定しない場合、Athena はクエリ毎に S3 バケット内のデータを全文検索してしまいます。処理時間や利用料金を考えると、パーティションの設定をお勧めします。
Hive形式とは?
year=2020/
year=2020/month=01/
year=2020/month=02/
のように、
フォルダ名に = (等号) を用いた命名のことを Hive形式 と呼びます。
Hive形式でフォルダを作成することにより、Athenaクエリで条件式が利用できます。
ex) 2020年01月のデータを取得
SELECT *
FROM <テーブル名>
WHERE year = 2020
AND month = 01
ex) 2020年02月のデータを取得
SELECT *
FROM <テーブル名>
WHERE year = 2020
AND month = 02
Athena のパーティション設定 & 更新
S3バケット内のフォルダ名を Hive形式にすることで、Athena からパーティション情報を用いたクエリが打てるようになります。
ただし、Athena には S3バケットに新しいHive形式のフォルダが作成されても、そのパーティション情報を自動検知しない という特徴があります。
例えば、2020年03月に
year=2020/month=03/
というフォルダが新規作成され、そのフォルダにIoTデバイスからのデータが格納されたとしても、以下のクエリでは レコードはゼロ という結果が返ってきます。
SELECT *
FROM <テーブル名>
WHERE year = 2020
AND month = 03
したがって、一定の期間毎に新規作成される Hive形式のフォルダに対応するには、 定期的にパーティションを更新する 必要があります。
定期的にパーティションを更新する方法としては、以下の2手法が考えられます。
- CloudWatch Events から Lambda を定期起動し、パーティション更新コマンドを実行する
- Glue Crawlers によりパーティションを定期更新する
以下、それぞれの手法について説明します。
手法① CloudWatch Events から Lambda を定期起動し、パーティション更新コマンドを実行する
S3バケットにHive形式のフォルダが新規作成されるタイミングで、パーティション更新コマンドを実行する手法です。
パーティション更新コマンドは
MSCK REPAIR TABLE <テーブル名>;
なので、更新コマンドを Athena に向けて実行する Lambda関数を作成し、CloudWatch Events から一定時間毎にトリガーすれば、Athena は最新のパーティション情報に基づいたクエリが実行できるようになります。

この手法により パーティションの定期更新 は可能となりますが、
- 新しいリソース(Lambda, CloudWatch)を作成する
- Athena のテーブルが増える毎に、これらのリソースを作成するの?
という面倒ポイントがあります。
もっと簡単な方法はないか?と調査したところ、AWS Glue という便利サービスを見つけました。
手法② Glue Crawlers によりパーティションを定期更新する
AWS Glue を利用したところ、CloudWatch と Lambda の連携によるパーティションの更新よりも、Glue のクローラを利用したパーティションの更新の方が明らかに楽だと実感しました。
(Glue についての知見が全くなかったために、手動で Athena コンソール画面からデータベース作成 & テーブル作成を実施し、 CloueWatch Events → Lambda関数 の起動という遠回りの手法を使ってしまいました。)
Athena + Glue によるデータ分析
IoTデバイスから逐次送付されるデータの分析において
S3 に格納したデータを分析したい場合は
- Athen がクエリを打てるフォーマット(データ形式、Hive形式)で、S3 にデータを格納する
- Glue でデータベース & テーブルを作成し、クローラを設定する
- (Athena のコンソール画面でクエリ文の試し打ち)
- QuickSight からSQL文の実行 & 可視化
という流れにするのが楽パターンです。

クローラがデータカタログを更新する頻度は、クローラ設定画面で登録できます。クローラの起動頻度と S3バケットに新しいフォルダが作成される頻度を合わせることにより、Athena から適切にデータ分析できるようになります。
(クローラの起動頻度を設定する画面)
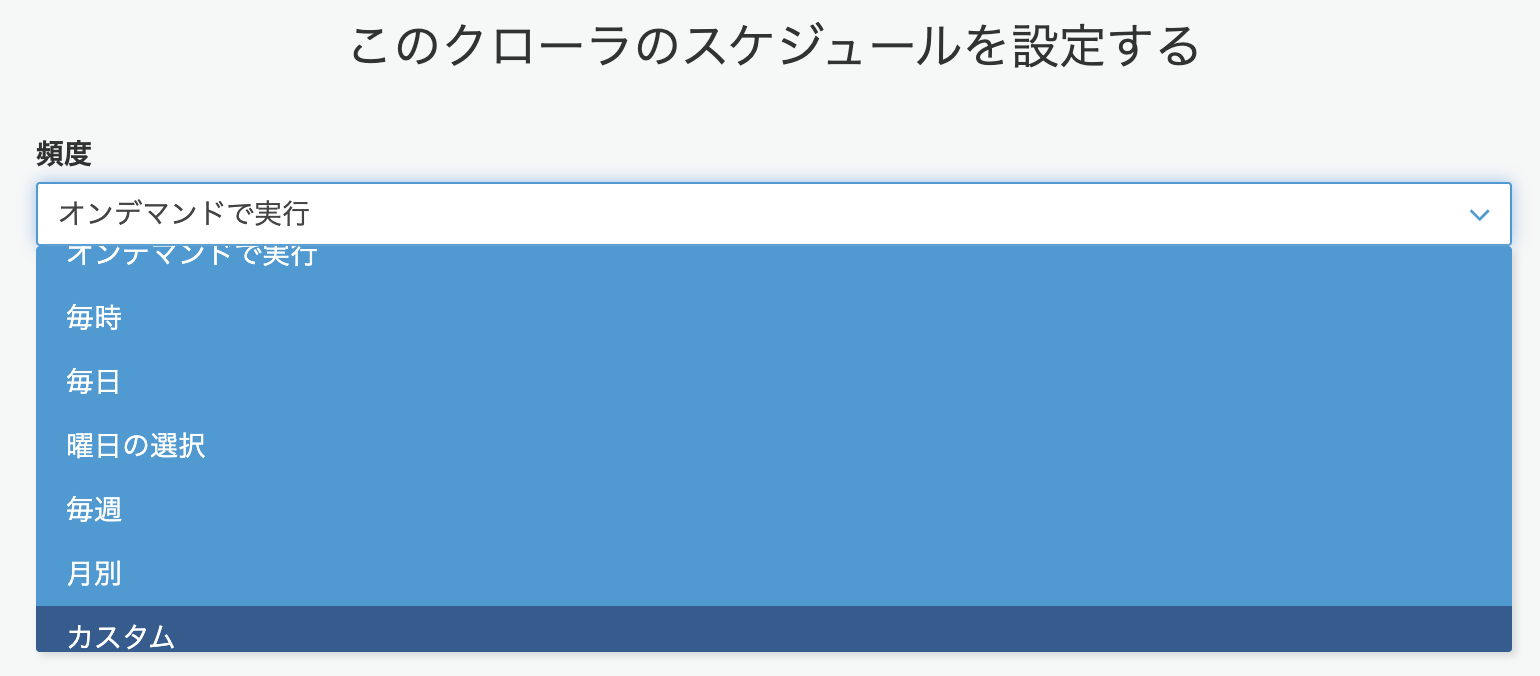
カスタム では cron式による起動タイミングの設定が可能です。
また、毎時 毎週 などからは
-
毎時: 毎時間の x分 に起動 -
毎週: 毎週 z曜日 の y時 x分 に起動
などの細かい設定も可能です。
まとめ
Amazon Athena を利用すれば、S3バケット内のデータを直接分析できます。
ただし、正しく利用する までにちょっとした壁があるため、本記事に掲載された
- S3バケットに格納する場合は、フォルダを Hive形式 にする
- 新しいフォルダが作成されたら、データカタログのパーティション設定を更新する
- パーティションの更新には Glue のクローラーを使う
などの注意点を意識する必要があります。
本記事が Athena を使い始めた人の助けになれば幸いです。
ここまでお付き合いいただき、ありがとうございました。