MCMCを理解して空も飛べるような気持ちになりましょう。
何を話すか
本日は難しい用語を一切使わず「数式を実装 → 図的理解」の流れで、MCMC(マルコフ連鎖モンテカルロ)の入門の話をしようかと思います。
ベイズ系は各所で使われてはいるが何をやっているか分かりにくい。
特に技術系ではない人にとっては理解が難しい部分かもしれません。
シミュレーションチックな側面が強いので違和感を感じられる方もいらっしゃるかもしれませんが、考え方としてはブートストラップが非常に近いです。
(という流れで去年の記事を紹介しておきます。)
本記事を読んで気力が残っていたら読んでみて下さい。
統計×シミュレーション というものを少し理解しやすくなるかもしれません。
Re:ゼロから始めるbootstrap-Re:sampling生活
今回は正規分布と尤度が分かっている前提でお話をしますが、なるべく初学者にもとっつきやすいようにステップを踏んでいこうと思います。
MCMCとは
MCMC、マルコフ連鎖モンテカルロという言葉は以下の2つのパーツから成り立っています。
マルコフ連鎖・・・状態遷移についての呼び方、一時点前の状態に影響を受けて連鎖的に繋がっている様子の事。時系列や強化学習でよく見る。
モンテカルロ・・・乱数を使ったシミュレーション法のこと。
乱数を使ったシミュレーションであり、マルコフ連鎖の状態をとっているような系列を扱うアルゴリズムの総称であり、実装方法によって更に詳細に個別の名前を持つアルゴリズムが存在しています。
正規分布についておさらい
正規分布に従う例として20歳の男性の身長を考えてみましょう。
まず正規分布とは以下のような数式でした。
f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp \left( -\frac{(x-\mu)^2}{2\sigma^2} \right)
20歳の男性の身長には真の平均というものがあるとします。
たとえば172cmだったとしましょう。
そして個体差によるバラツキもあります。
そのバラツキを表す指標である標準偏差が6だったとしましょう。
身長は172cmを中心に高い方向、低い方向に均一にばらついていることが想像できます。
100万人集めたらこんな感じになるはずです。
set.seed(123)
data_x <- rnorm(1000000,172,6)
hist(data_x)

100万人集めたならば、全体を1として考えれば各身長にの値をとる確率が計算されるのでした。
つまり、172cmの身長の人数が全体人数のうち何割であるかを計算するだけです。
このような確率を計算に上記の式を使うことができます。
たとえば160cmの身長となる確率は
f(160) = \frac{1}{\sqrt{2*3.14*6*6}}\exp \left( -\frac{(160-172)^2}{2*6*6} \right)
> exp(-(160-172)^2/2/6^2)/sqrt(2*pi*6^2)
[1] 0.008998494
> options(digits=15)
> exp(-(160-172)^2/2/6^2)/sqrt(2*pi*6^2)
[1] 0.00899849441886468
でした。R言語で求めてみると
> dnorm(160, 172, 6)
[1] 0.00899849441886468
一致します。
正規分布の尤度
今、真の平均身長が判明していたから上記の式で確率を求められました。
逆にデータがあって、真の平均身長が分からない時はどうしたらいいのでしょうか?
こういう真の平均が分からない問題は統計学の分野では頻繁にあり、そのために推測統計が使われますがとりあえず今回は推測統計との関係は忘れていいです。
10人の20歳男性だけ集めることができ、20歳の男性の身長平均のもっともらしい値を出したいとします。
身長は正規分布に従っている、という前提を信用して話を進めます。
(統計学では分布関数を前提として話を進める場面がまぁまぁあります。経験的に従っていることが知られているんだなぁ。と思いながら今回は読んでください。)
今回得られた10人のデータはμというパラメタからσのばらつきを持った範囲から得られたデータです。
それぞれの得られる確率はμとσが無ければ計算できないのですが、逆に今回の10人のデータが最も出やすいようなμとσを探せばいいと考えられないでしょうか?
パラメタ探索 μを探す
問題の簡単化のため、σはすでに6であると知っていて求める必要がないとします。
つまり、μを0~無限までの範囲で動かしながら、10人の身長の同時確率を求めて最大になるようなμを探すわけです。
探索してみると、
library(tidyverse)
mu <- seq(150,180,length=100)
f<- function(x){
prod(dnorm(x_height,x,6))
}
plot(mu,map_dbl(.x=mu,.f=f))
縦軸である尤度関数の値と横軸のパラメタはこのような関係になります。

こうして最も尤度が高くなるパラメタを見つけることが出来ます。
しかし、実際に実行すると掛け算はデータの量に応じて計算コストが非常に大きくなる。
そこで数式から最適な値を求めようと考えます。
既に上のRのコードで計算しましたが「同時確率」、つまりそれぞれの確率dnorm()を掛け算prod()した値、
L(\mu, \sigma)= \prod_{i=1}^{10} f(x_i) = \prod_{i=1}^{10} {1 \over \sqrt{2\pi\sigma^{2}}} \exp \left(-{}{(x_i-\mu)^2 \over 2\sigma^2} \right)
が最大になるようにしてあげればいいわけです。
この式を尤度関数と呼ぶことにします。
と思って調べていたらここまでの内容が分かりやすく書いてある記事を見つけました。
Qiita 【統計学】尤度って何?をグラフィカルに説明してみる。
この尤度関数をμについての二次関数だと考え、数学的に最大化させようと考えると微分して0となる地点を求めたらいいことが分かります。
計算テクニックとして対数変換を挟みますが、尤度関数の変曲点を求める問題になるので微分して傾きが0となる点を求めることが解になるということです。

図:高校数学の美しい物語 最尤法によるパラメータ推定の意味と具体例 より
対数化した後、μに対して偏微分した結果は
\sum_{i=1}^{n} {(x_i-\mu) \over \sigma^2} = 0
\mu = {1 \over n}\sum_{i=1}^{n} {x_i}
となり、データの平均値がもっともらしいμの値であることがわかります。
Rのコードで、高校の美しい数学の図を再現するならば以下のようになります。
f<- function(x){
sum(log(dnorm(x_height,x,6)))
}
plot(mu,map_dbl(.x=mu,.f=f))

より細かい数式変換はこちら
biostatistics 正規分布
シミュレーションによる尤度の計算
もっともらしい平均値を求めたければ、データの平均値を使えば良いことが分かりました。
ではなぜシミュレーションが必要なのでしょうか?
ひとつの理由として、全探索は効率が悪いためです。
もう一つの理由として、パラメータを一点でなく範囲で推定したい場合を考えましょう。
つまり今回のデータからもっともらしい平均値を一点求めるならば平均を計算するが、その一点がどの程度不確かさを持っているのかを知りたい場合です。
問題を簡単化するために平均0分散1の正規分布に従うデータを10点生成してみました。
set.seed(123)
x_mean <- rnorm(10,-3,2)
plot(0,0,xlim=c(-10,10),ylim=c(0,0.4),type="n")
points(x_mean,rep(0,length=length(x_mean)))

パラメタμを探索するまでの流れとして、
- 探索範囲は-9から9までと設定します。
- ランダムに初期値を設定します。
- 初期値で尤度を計算します。
すると初期値での尤度がもとまります。
set.seed(111)
syokiti <- runif(1,min=-9,max=9)
plot(0,0,xlim=c(-10,10),ylim=c(0,0.4),type="n")
points(x_mean,rep(0,length=length(x_mean)))
abline(v=syokiti)
abline(v=mean(x_mean),col="blue")
syokiti
> 1.673663

収束したいパラメータは青い縦線であり、現在の初期値は黒い縦線です。
この初期値をμとして尤度を計算すると
f<- function(x){
prod(dnorm(x_mean,x,6))
}
f(syokiti)
[1] 6.241757e-14
対数尤度が非常に小さい値となりました。
これを大きくする方向を探索したいのですが、
図としてみたら青い方向に進めばいいと分かりますが、
アルゴリズムの気持ちとしてはμを大きくしたらいいのか小さくしたらいいのか不明です。
そこで、初期値の周辺を探すことにしてみましょう。
初期値の周辺で再度乱数を発生させます。
そのために図の初期値からある程度左右に範囲を持っている「0を中心とした標準偏差0.02の正規分布」で乱数を生成することにしましょう。
分布から乱数をサンプリングし、初期値に加えます。
move <- rnorm(1,0,sd=0.02)
move
[1] 0.0120441
abline(v=syokiti+move,col="red")
※上図は赤線があまりにも小さいズレで見えにくいため分かりやすく0.01でなく0.6を足しています
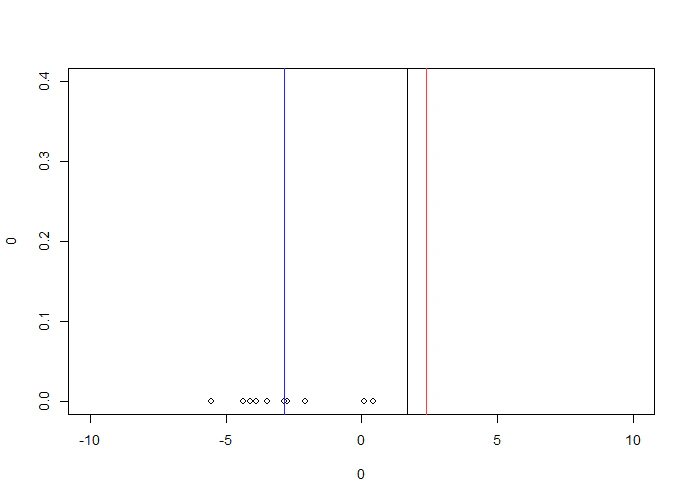
赤線は真のパラメタから更に離れてしまったので尤度も小さくなるはずです。
尤度を改めて求めると
f(syokiti+move)
[1] 6.147864e-14
小さくなっています。
真のパラメタに収束させるには
- 繰り返し乱数を生成させ
- もしも対数尤度が大きくなればμを採用する
を実行する必要があります
if(f(syokiti+move) > f(syokiti)){
next <- syokiti+move
}
繰り返すと青色の線μに収束していきます。
set.seed(123)
f<- function(x){
prod(dnorm(x_mean,x,6))
}
syokiti
koushin <- syokiti
hozon <- syokiti
for(i in 1:400000){
move_val <-rnorm(1,0,sd=0.02)
res <- f(koushin)
move_res <- f(koushin + move_val)
if(move_res > res){
koushin <- koushin + move_val
hozon <- c(hozon , koushin)
}
}
plot(0,0,xlim=c(-10,10),ylim=c(0,5),type="n")
points(x_mean,rep(0,length=length(x_mean)))
abline(v=syokiti)
abline(v=mean(x_mean),col="blue")
y_val <- 0.1
for(o in 1:length(hozon)){
points(hozon[o],y_val,col="red",pch=20)
y_val <- y_val +0.01
}
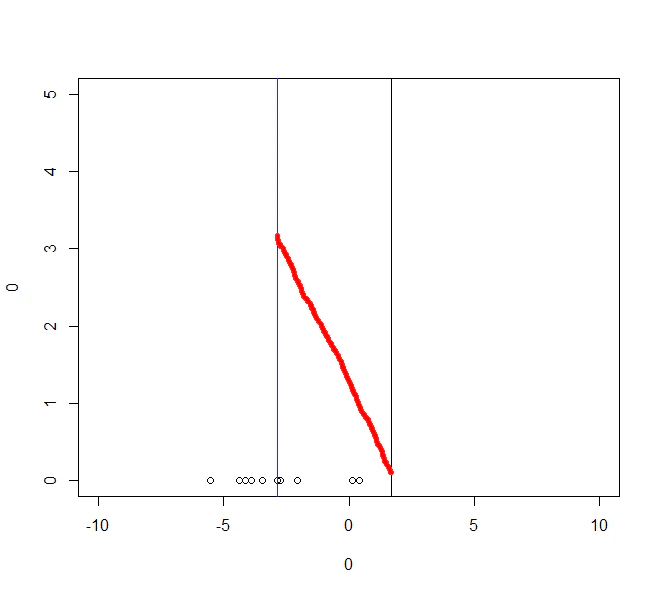
このように真のパラメタに収束していくことが確認できました。
しかしこれでは
- シミュレーションによる探索の効率化
という目的の少しは達成できますが、不確かさを表す情報が得られません。
そのため、適度にパラメータ周辺でふらふらする必要があります。
- 時々間違っているμも一定の確率で採用する
という操作を加えます。
話をシミュレーションの前まで戻して尤度を割り算して比較してみましょう。
f(syokiti+move) / f(syokiti)
青線に近い初期値の時の尤度は、動かした赤線での尤度よりも大きくなります。
割り算では分子小さく、分母が大きいため1よりも小さい値をとります。
尤度の割り算が1よりも大きければ真のパラメタに近づいているという事なので必ず採用し、1よりも小さければ確率で採用する。
と考えてみましょう。
こうすることで真のパラメタに近づきつつ、ある程度の確立で間違ったパラメタも多少探索を行うことができます。
ここで、ある確率とは、1よりも小さくなった尤度の割り算を確立とみなして使うことにします。
set.seed(123)
f<- function(x){
prod(dnorm(x_mean,x,6))
}
syokiti
koushin <- syokiti
hozon <- syokiti
for(i in 1:400000){
move_val <-rnorm(1,0,sd=0.02)
res <- f(koushin)
move_res <- f(koushin + move_val)
if( (move_res / res) > 1 ){
koushin <- koushin + move_val
hozon <- c(hozon , koushin)
}else if( (move_res / res) > runif(n=1,min=0,max=1) ){
koushin <- koushin + move_val
hozon <- c(hozon , koushin)
}
}
plot(0,0,xlim=c(-10,10),ylim=c(0,80000),type="n")
points(x_mean,rep(0,length=length(x_mean)))
abline(v=syokiti)
abline(v=mean(x_mean),col="blue")
y_val <- 0.1
for(o in 1:length(hozon)){
points(hozon[o],y_val,col="red",pch=1)
y_val <- y_val +0.2
}

かなり暴れていますが、真のパラメタの周辺を探索できていることが分かります。
尤度からの流れで、必ず真のパラメタ側に収束してゆくのでなく間違った方向にも進む方法の実装を尤度の割り算で実装してみました。
ここからは尤度の割り算部分をベイズの定理による説明に置き換えます。
ベイズの定理でのサンプリング
上記で尤度の割り算で
- 尤度が大きくなれば採用
- 尤度が小さくなったときもある確率で採用
という繰り返しから真のパラメタの周りで採用されたパラメタがふらつくことを確認できました。
今、真のパラメタが点でなく不確実性を持って説明できるようになりたいと考えているので、
これを点でなく分布で得たいという言葉になおします。
つまりパラメタμは何かの確立分布から得られる値と考えます。
ここでは以下のような正規分布に従っていると考えます。
\mu ~ N( \mu,1)
ベイズの定理から、事後分布は以下の式で求まる。
P(B|A) = \frac{P(B)P(A|B)}{P(A)}\\
これを言葉にすると、結果Yが起きた時、パラメタがXであった確率が求まる
P(B|A)・・・事後確率、データAの時パラメタがBである確率
P(A|B)・・・尤度、パラメタBの時データAが得られる確率
P(B)・・・事前分布、パラメタBの分布
P(A)・・・規格化定数
規格化定数に関しては一旦無視して構いません。
詳細はこちら
尤度については今まで何度も求めてきました。
事前分布については今、
\mu ~ N( \mu,1)
として考えていたので、この正規分布と尤度を掛け算します。
f(param)*dnorm(x_mean,param,1)
同時確率を考えるため総積を計算する必要があります。
事後分布とパラメタの関係を確認しておくと以下のようになります
param <- seq(-5,5,length=1000)
y <- NULL
for(i in 1:1000){
res <- prod(f(param[i])*dnorm(x_mean,param[i],1))
y<- c(y,res)
}
plot(param,y)
abline(v=mean(x_mean),col="blue")

尤度と同じように、真のパラメタ付近で値が大きくなることが分かります。
尤度の割り算と性質は同じであることがわかります。
これを先ほどの尤度の割り算部分に置き換えると以下のようになります。
set.seed(123)
f<- function(x){
prod(dnorm(x_mean,x,6))
}
syokiti
koushin <- syokiti
hozon <- syokiti
for(i in 1:100000){
move_val <-rnorm(1,0,sd=0.02)
res <- prod(f(koushin)*dnorm(x_mean,koushin,1))
move_res <- prod(f(koushin+ move_val)*dnorm(x_mean,koushin+ move_val,1))
if( (move_res / res) > 1 ){
koushin <- koushin + move_val
hozon <- c(hozon , koushin)
}else if( (move_res / res) > runif(n=1,min=0,max=1) ){
koushin <- koushin + move_val
hozon <- c(hozon , koushin)
}
}
plot(0,0,xlim=c(-10,10),ylim=c(0,35000),type="n")
points(x_mean,rep(0,length=length(x_mean)))
abline(v=syokiti)
abline(v=mean(x_mean),col="blue")
y_val <- 0.1
for(o in 1:length(hozon)){
points(hozon[o],y_val,col="red",pch=1)
y_val <- y_val +0.2
}
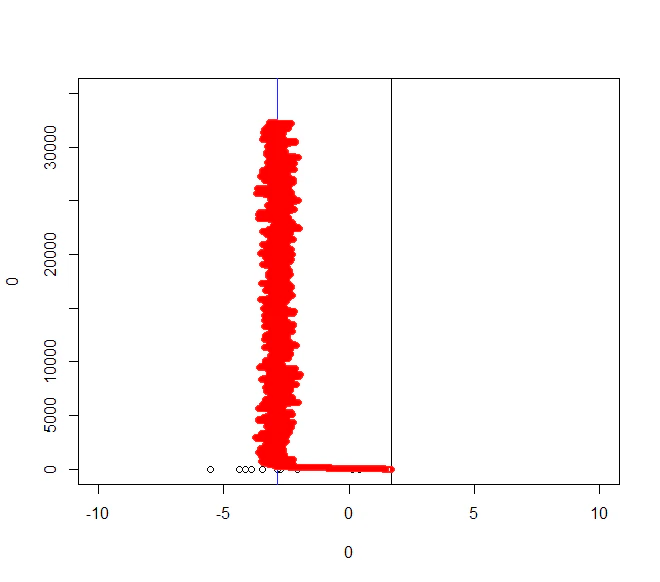
尤度の割り算よりブレが小さいが、多少のブレを持った採用パラメタがえられました。
この採用パラメタは事後分布の1点1点のデータなので、ヒストグラムを取ることで事後分布に近似できます。
ただし、初期値の周辺が不安定な値を取っているためヒストグラムを描く時の邪魔になります。
初期部分を5000ほど消してヒストグラムを描きましょう。
hist(hozon[5001:length(hozon)],breaks = 100)
abline(v=mean(x_mean),col="blue")

このように、パラメタμを点での推定でなく、分布として得ることができました。
まとめ
特別な用語を使わずに説明してみました。
MCMCの専門書を読む際に本記事の内容と照合できるように補足しておきますと、
- パラメタが従うと考えたN(μ,1)は事前分布と呼ばれます
- パラメタを更新するための乱数を発生させるN(μ,0.02)は提案分布と呼ばれます
- 除外した5000のデータはバーンイン(バーンイン期間)と呼ばれます
さらに専門書を読んでいただくと、効率化や局所解を避ける方法など様々な実装を目にされるかと思います。
「パラメタの分布」に「事前分布を置く」という考えが気にかかる方は「階層ベイズ」の本から導入されるといいかもしれません。
今回の記事で皆様の多少の疑問が解決したならば幸いです。
追記
間違い指摘等歓迎です
Rで楽しむベイズ統計入門[しくみから理解するベイズ推定の基礎]
おまけ
正規分布の対数尤度関数の実装
使おうと思ったけど使わなかったので供養
数式的に対数尤度関数は以下である
\begin{eqnarray*}
-\frac{n}{2}\log (2\pi\sigma^2)- \frac{1}{2\sigma^2}\sum(x-\mu)^2
\end{eqnarray*}
コードとして計算すると
x_mean <- rnorm(10,172,6)
hood_f <- function(x,sig,mu){
n<- length(x)
kou_1 <- (-n/2)
kou_2 <- log(2*pi*(sig^2))
kou_3<-sum( (x - mu)^2 )
kou_4 <- 2*(sig^2)
kou_12 <- kou_1*kou_2
kou_34 <- kou_3/kou_4
kou_12-kou_34
}
hood_f(x=x_mean,
sig=2,
mu=170)
既存の関数で同じことを行うと
get_normal_log_likelihood <-
function(observations,
mean_parameter,
sd_parameter){
res <- log(prod(dnorm(x = observations,
mean = mean_parameter,
sd = sd_parameter)))
return(res)
}
get_normal_log_likelihood(observations = x_mean,
mean_parameter = 170,
sd_parameter = 2)