Kinesisの監視項目まとめ
@itmaromaro さんに引き続き私が12日目のカレンダーを彩らせていただきます。
今年も年末がやってまいりましたね。
私は寒さと健康診断の結果で震えております。
さて、健康診断といえばシステムの健康状態を知るためにも監視は大切ですね。
今回は aws の Kinesis の監視に使える Datadog のメトリクスについて調べてみたのでそのまとめです。
Datadogメトリクスについて
今回は Datadog の監視として、レコードの経過時間など Kinesis に関する観測値(メトリクス)を基準に監視設定を入れたいと思います。
このメトリクスは純粋に計測された値だけでなく、合計や平均、99パーセンタイル など統計をとった結果を使うことも可能です。
また、用語として
プロデューサー: 書き込み側
コンシューマー: 読み込み側
として使っています。
これいつもどっちかわからなくなります。
統計の種類について
Datadog では収集した値をいろいろな形に集計して表示してくれます。よく利用するのは以下の集計方法です。
| 統計 | 意味 | 用途 |
|---|---|---|
.sum |
測定期間内の合計値 | 総バイト数、総レコード数など数や回数を計測するのに便利です |
.average |
測定期間内の平均値 | 平均レイテンシ、平均成功率など全体の傾向を計測するのに便利です |
.maximum |
測定期間内の最大値 | パフォーマンスのスパイク、最大遅延などを検出できます |
.minimum |
測定期間内の最小値 | maximum の反対で最小値を検出できます |
必要に応じて集計されたデータを参照します。
次に kinesis に関係するメトリクスの紹介です。
1. 書き込み系のメトリクス
kinesis にデータを書き込む側の動作を確認できます。
注意点として、 put_record と put_records の二つがあるので、知らないと あれ?メトリクスがないぞ? といったはまりポイントになる可能性があります。
| メトリクス名 | 説明 | 重要な統計 |
|---|---|---|
aws.kinesis.put_record_bytes |
単一レコード書き込みAPIで送信されたデータのサイズ(バイト)。 |
maximum, sum
|
aws.kinesis.put_record_latency |
単一レコード書き込みAPIの応答時間(ミリ秒)。 |
average, maximum
|
aws.kinesis.put_record_success |
単一レコード書き込みAPIの成功回数。 | sum |
aws.kinesis.put_records_bytes |
一括書き込みAPIで送信されたバッチデータのサイズ(バイト)。 |
maximum, sum
|
aws.kinesis.put_records_latency |
一括書き込みAPIの応答時間(ミリ秒)。 |
average, maximum
|
aws.kinesis.put_records_records |
一括書き込みAPIで送信されたレコードの総数。 | sum |
aws.kinesis.put_records_failed_records |
一括書き込みAPIで失敗したレコードの数。 | sum |
aws.kinesis.put_records_throttled_records |
一括書き込みAPIでスロットリングされたレコードの数。 |
sum, maximum
|
put_record_success や put_records_records を監視することでどの程度の量を書き込みできているのかを測ることができます。
ただ、データの量が常に一定ではなく多い時、少ない時がランダムに発生する場合は閾値を決めた監視の項目としては少し使いにくい値だと思います。
そういった場合は監視の方法として Anomaly Detection で検知すると、普段と違う傾向を検知してくれるので早めに異常を検知するための手掛かりになるかもしれません。
2. 読み込み系のメトリクス
こちらは kinesis からデータを読み出す側の動作を確認できます。
| メトリクス名 | 説明 | 重要な統計 |
|---|---|---|
aws.kinesis.get_records_bytes |
読み込みAPIで取得されたデータのサイズ(バイト)。 | sum |
aws.kinesis.get_records_records |
読み込みAPIで取得されたレコードの総数。 | sum |
aws.kinesis.get_records_latency |
読み込みAPIの応答時間(ミリ秒)。 |
average, maximum
|
aws.kinesis.get_records_success |
読み込みAPIの成功回数。 | sum |
aws.kinesis.get_records_iterator_age |
読み込みAPIで返された最後のレコードの古い度合い(ミリ秒)。 | maximum |
get_records_iterator_age が上がり続ける場合、書き込み側に対する読み込み側の処理性能が不足している可能性が考えられます。
このメトリクスを監視することでアプリケーションのスループットが十分であるのかが判断できますね。
ただ、この値は 取得側のアプリケーションが動いていないと値が出力されないようで、no_data の扱いになることもあるようです。
クリティカルな部分であれば no_data はエラーとするなど、扱いには注意が必要です。
3. ストリーム全体の健全性に関するメトリクス
ストリームのキャパシティ、スループット、シャードの状況に関する情報です。
| メトリクス名 | 説明 | 重要な統計 |
|---|---|---|
aws.kinesis.incoming_bytes |
ストリームに投入された総バイト数(入力データ量)。 | sum |
aws.kinesis.incoming_records |
ストリームに投入された総レコード数(入力レコード数)。 |
sum, average
|
aws.kinesis.outgoing_bytes |
ストリームから読み出された総バイト数(出力データ量)。 | sum |
aws.kinesis.outgoing_records |
ストリームから読み出された総レコード数(出力レコード数)。 |
sum, average
|
aws.kinesis.iterator_age_milliseconds |
返された最後のレコードが書き込まれてからの経過時間(ミリ秒)。コンシューマーの遅延(Consumer Lag)を示すメトリクス。 | maximum |
aws.kinesis.read_provisioned_throughput_exceeded |
読み取りスループットの上限を超過した回数。コンシューマー側のスロットリング監視に。 |
sum, maximum
|
aws.kinesis.write_provisioned_throughput_exceeded |
書き込みスループットの上限を超過した回数。プロデューサー側のスロットリング監視に。 |
sum, maximum
|
aws.kinesis.shard_count |
ストリーム内のアクティブなシャードの数。 | maximum |
スロットリングなどは kinesis の性能不足を検知するのに有用な指標ですね。
put_records_throttled_records もスロットリングに関するメトリクスですが、全体を監視する目的であれば write_provisioned_throughput_exceeded の方がより広く監視できそうです。
in, out のデータ量やレコード数は、普段からおおよそ一定のデータ量であれば異常な傾向を検知するのに使えます。
他にももっと細かい値を取得することは可能ですが、今回は割愛します。
4. 監視の設定例
これらの指標を使って監視の設定を作ってみます。
Datadog のメニューから Monitors を選び新しいモニターを作成します。
今回は Metric でモニターを作成します。
Step1 Choose the detection method
Choose the detection method から Threshold Alert を選びます。
今回はわかりやすく閾値を超えたかどうかでモニターを作成していますが、Anomaly Detection など他の項目を設定することで "いつもと傾向が違う場合" などもう少し柔軟な動きも可能です。

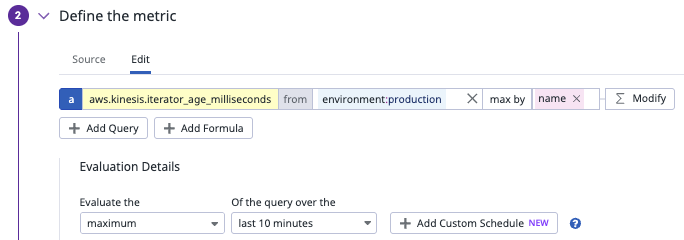
Step2 Define the metric に監視対象のメトリクス値を設定します。
Define the metric に監視対象のメトリクス値を設定します。
今回は読み取りされていない一番古いレコードの時間を表す iterator_age_milliseconds を監視対象としています。
メトリクス値には: aws.kinesis.iterator_age_milliseconds を、フィルタ条件として from には付与されているタグなどを指定します。
今回は本番環境のアラートを設定することを想定して environment:production を設定します。
次にメトリクスに条件を設定します。
iterator_age は計測されているものの中で一番古いものを参照したいので最大値を取得する max by を指定します。
次に集計する単位を指定します。 kinesis のストリームごとに設定する場合は name などで分割すると良いかと思います。
また、タグの候補が表示されるので、メトリクスにどんなタグが付与されているのか簡単に確認するのにも使えますね。
これで監視元となるメトリクスの設定ができました。次に Evaluation Details から閾値の集計方法を設定をします。
最大値を監視するため Evaluate the は maximun を選択
集計期間はよしなに。今回は10分としました。
Step3 Set alert conditions
閾値の基準値を設定します。
設定する閾値は2段階で、 Warning と Alert を設定します。
メトリクスの値はミリ秒なので Warning:1,800,000(30分) , Alert:3,600,000(1時間) としました。
値を設定すると画面上部のグラフに赤と黄のエリアが表示されているので、設定が正しいか確認しましょう。


Step4 アラート名とメッセージを設定します。
テキストエリアには通知で表示されるメッセージを表示します。
特定のタグで囲むことで関連したアクションが発生した際にそのメッセージを表示することができます。
通知先は Notify で指定します。今回はメールアドレスを設定しています。
{{#is_alert}}
アラート領域まで iterator age が増加しました。
{{/is_alert}}
{{#is_alert_to_warning}}
警告領域まで iterator age が減少しました。
{{/is_alert_to_warning}}
{{#is_alert_recovery}}
iterator age が減少しました。
{{/is_alert_recovery}}
Notify: @yourmail@example.com

設定できたら Save and publish ボタンから作成します。
これでアラートが作成できました。
ちなみに、複数のメトリクス値を定義して計算した結果を監視することも可能です。
Define the metric のところで Add Query ボタンからメトリクス値を追加することができます。
また、画面右の html タグのようなアイコン(</>)からメトリクスを式で扱うこともできます。
こんなイメージ
a: max:aws.kinesis.put_record_latency.maximum{streamname:your-stream}
b: max:aws.kinesis.put_records_latency.maximum{streamname:your-stream}
→: a + b
これで put_record_latency と put_records_latency を合わせて監視することができます。

Datadogは多機能すぎてまだまだ全然使いこなせてませんが、安全にシステムを運用するためぜひ使いこなせるようになりたいですね!
次回は @kuuuma さんです!お楽しみに!