はじめに
本記事を発表する時点で、BigQueryからOracle Autonomous Databaseにデータを直接移行することはできません。この記事は一つ方法として、BigQuery, Google Cloud Storage, OCI Object Storage, Oracle Autonomous DatabaseのSDKやAPIを利用した上で、データを移行できるよう説明します。
前提として、BigQueryにおける「bq2adw」というプロジェクトがあり、このプロジェクトの中にbqds02のデータセットがあります。そして、このデータセットにはT4_1というテーブルがあります。目標はこのテーブルのデータをOracle Autonomous Data Warehouseに移行します。
今のとこと、ADWからBigQueryへの直接アクセスすることはまだできませんから、最初に行うのはBigQueryに保存されているデータのエクスポートとなります。データをエクスポートされてから、自由に扱うになります。
テーブルをGCSにエクスポートした後、最も簡単な方法は、公式資料Load Data from Files in the Cloud に記述されている方法を参照して、エクスポートされたファイル(AVROまたはCSV)をADWに直接読み込みます。残念ながら、今までGoogle Cloud Storageはまだサポート対象リストに含まれていません。そのため、エクスポートされたファイルをGCSからADWが直接アクセスできる場所に移動する必要があります。Oracle OCI Object Storageは当然な選択です。
基本的に、GCSもOracle Object Storageもオブジェクトストレージサービスであるため、コマンドラインツールやSDKを使用して操作できます。次に、Python SDKを用いて、テーブルのエクスポートからADWにインポートまでのステップを詳しく記述します。
- BigQueryからGoogle Cloud Storageにテーブルをエクスポートします
- エクスポートされたファイルをGoogle Cloud Storageから中間サーバーにダウンロードします
- 中間サーバーからOracle Object Storageにファイルをアップロードします
- データをOracle Object StorageからOracle Autonomous Data Warehouseにロードします
下記ワークフローをご参照ください。
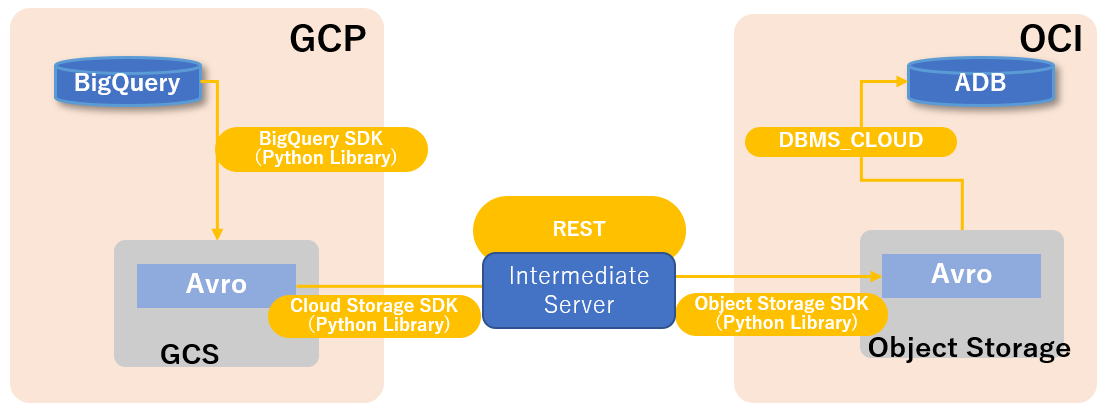
Google Cloud Platformの認証のセットアップ
サービスアカウントとキーファイルの作成
Google Cloud Serviceを利用するために、サービスアカウントと対応するキーファイルを作成する必要があります。
Google Cloud Platform console pageにアクセスして、[IAM & admin] -> [Service accounts]に移動します。このページにおいてサービスアカウントを作成できます。
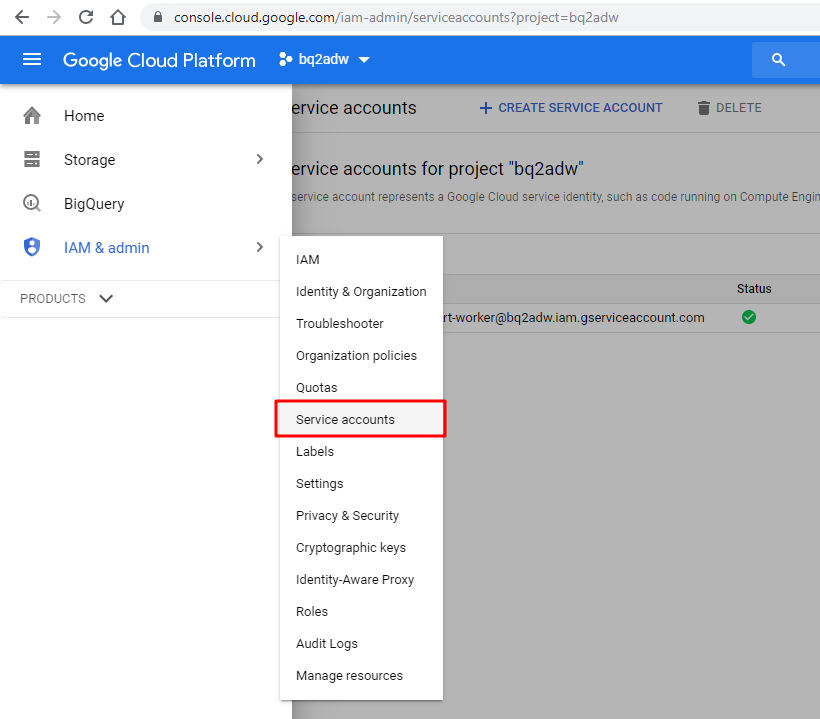
[CREATE SERVICE ACCOUNT]ボタンをクリックし、必要な情報を入力します。
ここは作成したサービスアカウントの役割を選択します。
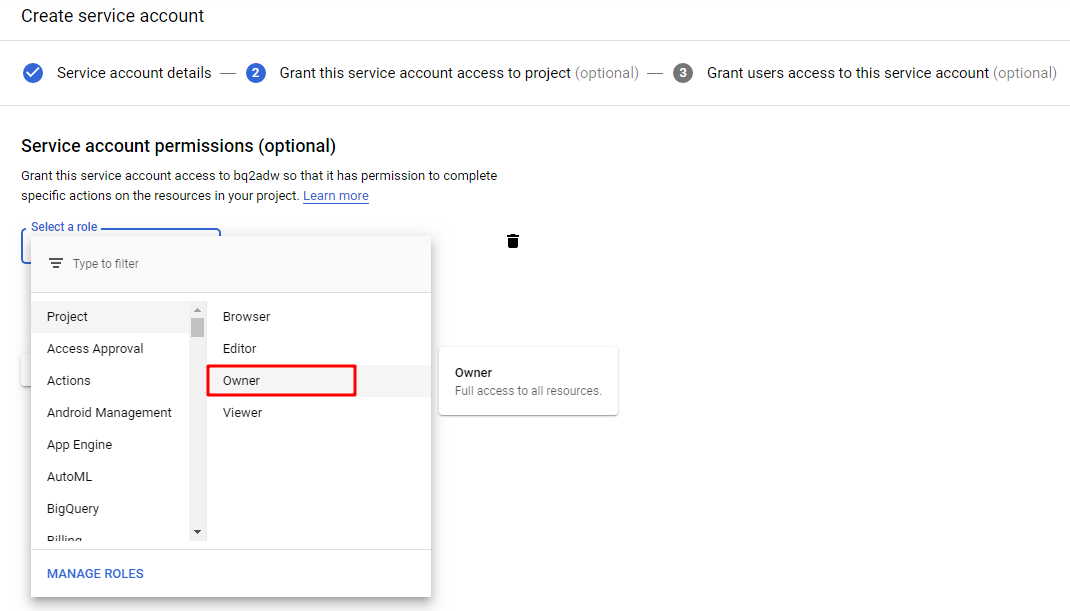
Googleアカウントを入力します。
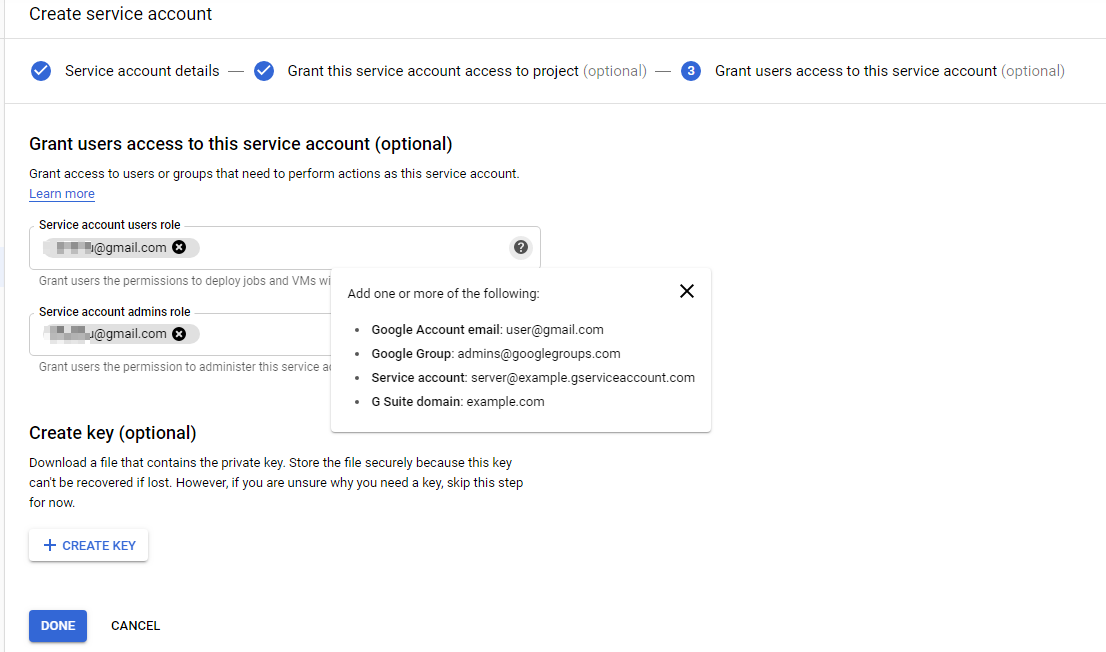
アクションアイコンをクリックし、[Create key]をクリックしてキーを生成します。
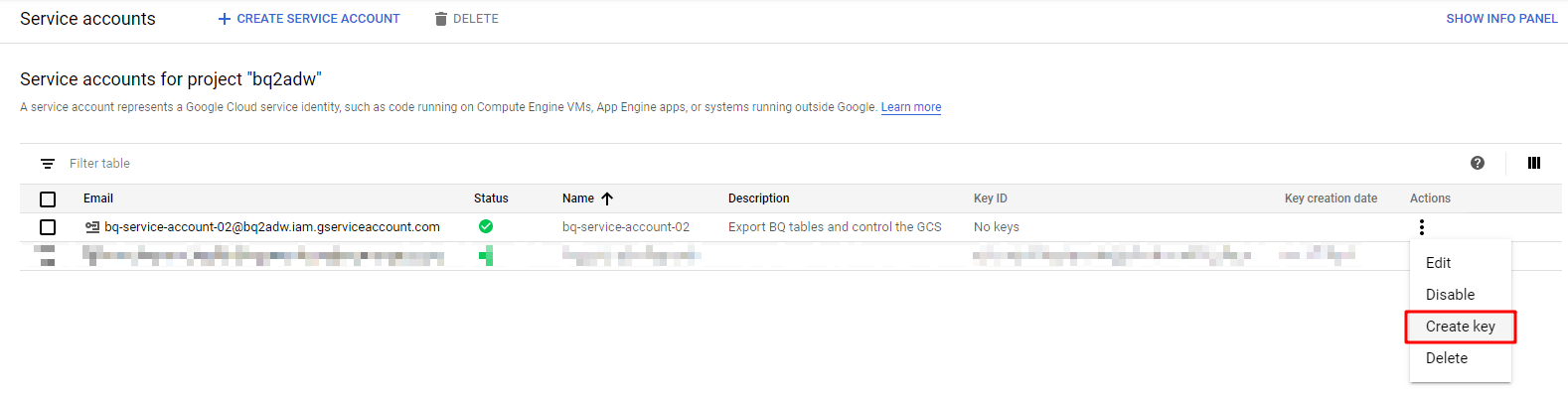
[Key type]]は[JSON]を選択し、[CREATE]ボタンをクリックします。

秘密鍵が生成され、安全に保管してください。
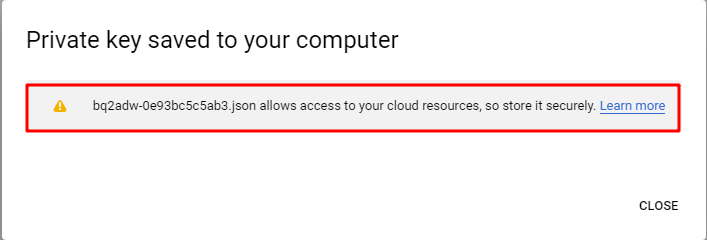
これで、GCPサービスアカウントが作成され、対応するキーファイルも生成できました。これらの情報は後で中間サーバーを構築するときに利用します。
中間サーバーにてGCPの認証を用意
まず、生成されたキーファイルを中間サーバーにダウンロードします。キーファイルのパスを環境変数GOOGLE_APPLICATION_CREDENTIALSとして中間サーバーに指定します。
export GOOGLE_APPLICATION_CREDENTIALS="[PATH TO THE KEY FILE]"

GCPプロジェクトのサービスにアクセスして操作できるようになります。
BigQueryテーブルのエクスポート
BigQueryクライアントライブラリのインストール
前述したように、Pythonスクリプトを使用して、プログラムで移行作業を制御つもりです。そのため、BigQueryサービスを操作するために、BigQueryクライアント・ライブラリをインストールする必要があります。中間サーバーには、使えるPython 3.6.8環境が既にありますので、ライブラリだけをインストールします。
python -m pip install --upgrade google-cloud-bigquery
BigQueryライブラリをインストールしたら、Pythonスクリプトを作成して、動作するかどうかを確認しましょう。
from google.cloud import bigquery
client = bigquery.Client()
query = (
"select keyid from `bqds02.T4_1` limit 10"
)
query_job = client.query(
query,
# Location must match that of the dataset(s) referenced in the query.
location="US",
) # API request - starts the query
for row in query_job: # API request - fetches results
# Row values can be accessed by field name or index
assert row[0] == row.keyid == row["keyid"]
print(row)
結果は次のように表示されると。ライブラリと認証は期待どおりに機能しています。
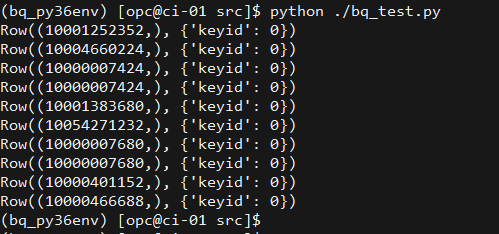
Export BiqQuery tables
BigQueryテーブルのエクスポート
これで、BigQueryサービスを操作できるようになりました。急いでテーブルをエクスポートしましょう!
以下は、テーブル T4_1がGoogle Cloud Storageにファイル名を「T4_1_export.avro」としてエクスポートするサンプル・スクリプトです。
from google.cloud import bigquery
client = bigquery.Client()
# set the basic export configuration
bucket_name = 'bucket-bq2adw'
project = "bq2adw"
dataset_id = "bqds02"
table_id = "T4_1"
destination_uri = "gs://{}/{}".format(bucket_name, "T4_1_export.avro")
dataset_ref = client.dataset(dataset_id, project=project)
table_ref = dataset_ref.table(table_id)
# Specify the export file format: AVRO
job_config = bigquery.job.ExtractJobConfig()
job_config.destination_format = (bigquery.job.DestinationFormat.AVRO)
extract_job = client.extract_table(
table_ref,
destination_uri,
# Location must match that of the source table.
location="US",
job_config=job_config
) # API request
extract_job.result() # Waits for job to complete.
print(
"Exported {}:{}.{} to {}".format(project, dataset_id, table_id, destination_uri)
)
ターミナルでは、上記サンプルスクリプトの出力が次のように表示されます。

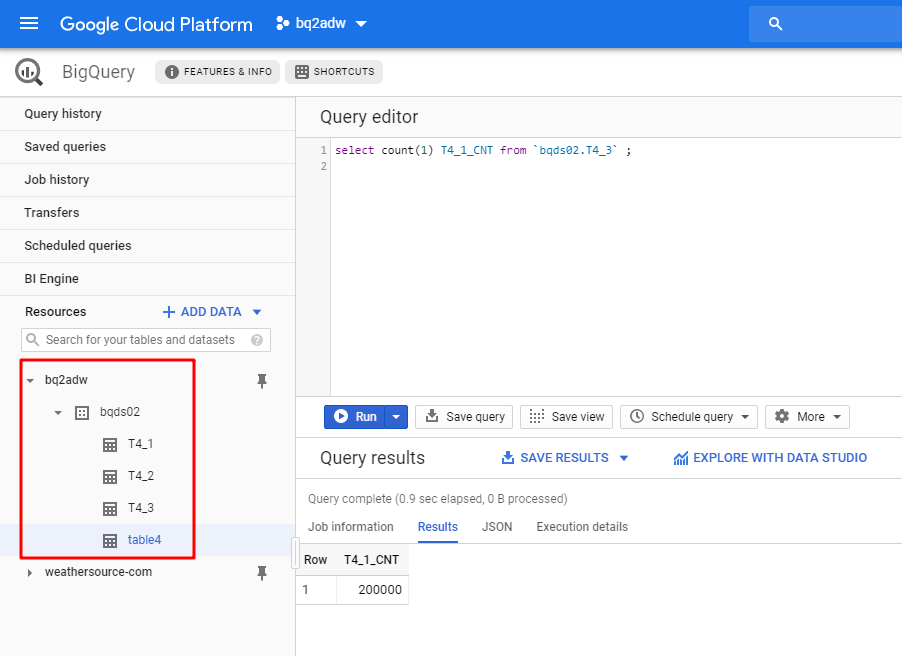
GCSバケットでは、エクスポートされたファイルがそこにあることも確認できます。
これまで、BigQueryにアクセスし、特定のテーブルをGoogle Cloud Storageバケットにエクスポートできました。
次に、エクスポートされたファイルを中間サーバーにダウンロードしてみましょう。
データ・ファイルを中間サーバーにダウンロード
このステップでは、引き続きPythonスクリプトを使用して作業を行います。Google Cloud Storageサービスを操作するため、まずはGCSのクライアント・ライブラリをインストールします。
Google Cloud Storageクライアント・ライブラリのインストール
インストールは非常に簡単です。以下のコマンドを実行してもいいです。
python -m pip install --upgrade google-cloud-storage
以下のサンプルスクリプトを使って、テーブル T4_1からエクスポートされたAVROファイルを中間サーバーにダウンロードします。
from google.cloud import storage
client = storage.Client()
def download_blob(bucket_name, source_blob_name, destination_file_name):
"""Downloads a blob from the bucket."""
# storage_client = storage.Client()
bucket = client.get_bucket(bucket_name)
blob = bucket.blob(source_blob_name)
blob.download_to_filename(destination_file_name)
print('Blob {} downloaded to {}.'.format(
source_blob_name,
destination_file_name))
if __name__ == "__main__":
download_blob('bucket-bq2adw', 'T4_1_export.avro', 'T4_1_export.avro')
AVROファイルが正常にダウンロードされたことがわかります。
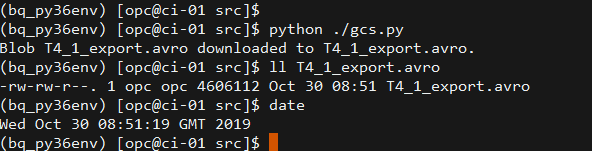
データ・ファイルをOracle Object Storageにアップロード
これまで、Google Cloud Platformとのやり取りが終わりました。次は、OCI Object StorageとAutonomous Data WarehouseなどのOracle Cloud サービスを操作する部分に入ります。
認証のセットアップ
現時点ではOCI CLIは必要ないですが、OCI認証を設定するもとも簡単な方法として、OCI Quickstart に従って、OCI CLIをインストールしてください。
OCI CLIをインストールされて、コマンドoci setup configを実行し、必要な情報(OCI User, tenancyなど)を入れて、OCI Serviceへアクセスの認証が設定できます。
次のコマンドを実行して、認証は正しいかを確認できます。
# get the namespace of the object storage with the authentication you have set
oci os ns get
次のように応答メッセージが返されたら、OCI認証の設定は完了です。

OCI Python SDKのインストール
超簡単です! 他のPythonライブラリのインストールと同じです。
python -m pip install --upgrade oci
次のサンプルスクリプトを実行すると、コマンド oci os ns getで取得した応答と同じ結果を取得できるはずです。
import oci
# use default config file: $HOME/.oci/config
config = oci.config.from_file()
compartment_id = "[OCID OF THE COMPARTMENT]"
client = oci.object_storage.ObjectStorageClient(config)
namespace = client.get_namespace().data
print(namespace)

データ・ファイルをOracle Object Storageにアップロード
認証設定とSDKのインストールは全て完了してから、次のサンプルスクリプトを使って、ファイル T4_1_export.avroをOracle Object Storageにアップロードできます。
import oci
# use default config file: $HOME/.oci/config
config = oci.config.from_file()
client = oci.object_storage.ObjectStorageClient(config)
namespace = client.get_namespace().data
bucket_name = "bq-tables"
# Then upload the file to Object Storage
file_name = 'T4_1_export.avro'
upload_file_name = file_name
with open("./"+file_name, 'rb') as f:
obj = client.put_object(namespace, bucket_name, upload_file_name, f)
print("Uploading {}".format(file_name))
スクリプトを実行すると、次のような出力が表示されます。

Oracle Object Storageバケットには、AVROファイル「T4_1_export.avro」があることを確認できます。
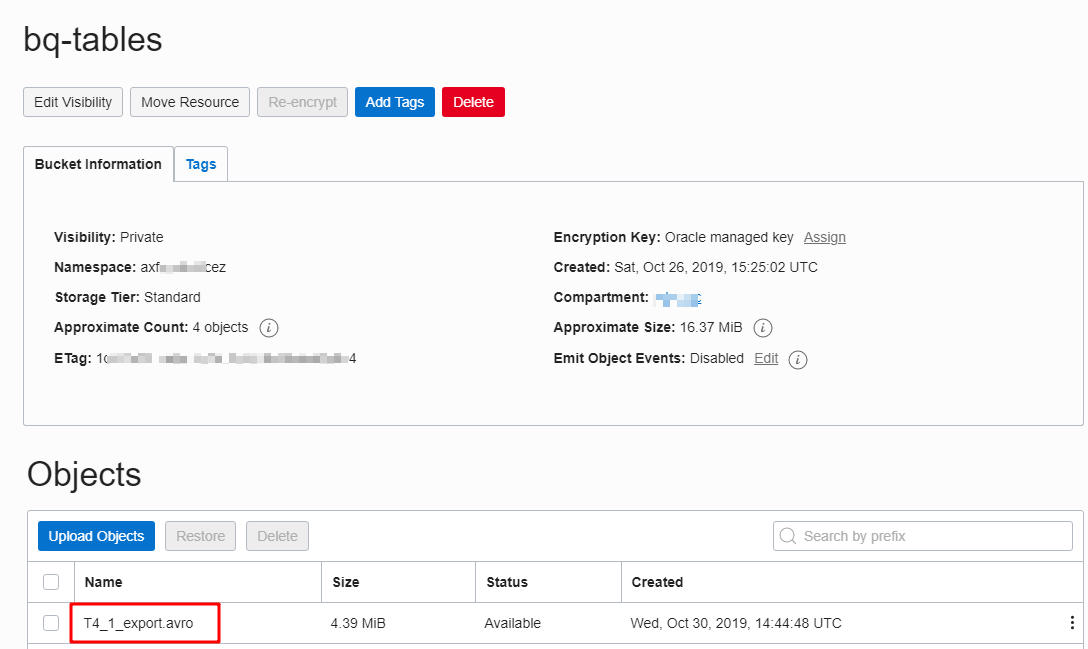
rcloneでデータの転送
GCSのSDKとOCI Object Storageを使用してデータを転送するほか、オープン・ソースのコマンドライン・ユーティリティ[rclone](https://rclone.org/)を使って、GCSからOCI Object Storageへデータを同期することもできます。
この記事では、主にSDKを使って移行作業を完成する方法について説明するため、rcloneの方法についての詳細を掘り下げません。Oracle White Paper: Transferring Data to Object Storage from Other Cloud Providers or Local File Systems におけるrcloneの方式を紹介されますから、ご参照ください。
このホワイトペーパーにGoogle Cloud Storageについて具体的な内容がないですが、方法は発表されている内容と似ています。
rclone を使用してGCSからOCI Object Storageへデータ同期する方法の詳細な手順は別記事で記述する予定があります。記事が完成したら、ここを更新します。
Oracle Autonomous Data Warehouseにデータをロード
Oracle Object StorageからADWにデータをロードするのは、主にObject StorageとADWインスタンス間のやり取りです。
中間サーバーはデータ・ロードのコマンドをADWに送信して、ADWインスタンスはコマンドに従って、OCI Object Storageからデータをロードします。
OCI Object Storage にアクセスするための認証を作成
ADW02というADWインスタンスを既に作成されたと仮定します。 Object StorageからADWインスタンスにデータを読み込むために、ADWインスタンスにおいて認証(クレデンシャル)を作成する必要があります。
クレデンシャルは、OCIの user name と Auth Tokenで作成されるため、まず、Auth Tokenを生成してください。
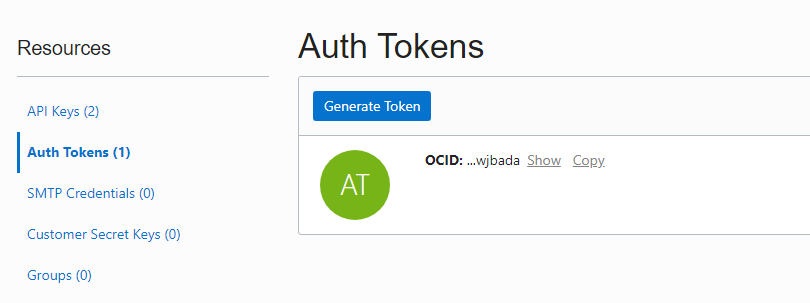
次に、移行ターゲットユーザー名でADWインスタンスにログインし、以下のようにクレデンシャルを作成します。
SET DEFINE OFF
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'ADW02_CRED',
username => '[OCI USER NAME]',
password => '[USER AUTH TOKEN]'
);
END;
/
このトピックの詳細情報はADW公式ドキュメントLoad Data from Files in the Cloudにご参照ください。
データのロード
AVROファイルをADWにロードするために、提供されているプロシージャDBMS_CLOUD.COPY_DATAを使用する必要があります。従って、SQLステートメントを実行するために cx_Oracleライブラリをインストールします。
python -m pip install --upgrade cx_Oracle
プロシージャDBMS_CLOUD.COPY_DATAを実行する前提としてはターゲット・テーブル(当該サンプルはT4_AVRO)を既に存在することです。なので、まずテーブルT4_AVROを作成します。
create table T4_AVRO(
keyid number(19),
col_01 binary_double,
col_02 binary_double
)
これで、Oracle Object Storageに保存されているAVROファイルをADWインスタンスにロードする必要な前提条件は全部準備できました。
次のスクリプトを実行して、データをロードします。
import cx_Oracle
def load_data_from_oos(connection):
sql_copy_data = """BEGIN
DBMS_CLOUD.COPY_DATA(
table_name =>'T4_AVRO',
credential_name =>'[CREDENTIAL NAME]',
file_uri_list =>'[OBJECT STORAGE URI OF FILE]',
format => '{
"type": "avro",
"schema": "all"
}'
);
END;"""
sql_count = """select count(1) from T4_AVRO"""
sql_truncate = """truncate table T4_AVRO"""
with connection.cursor() as cur:
cur.execute(sql_truncate)
cur.execute(sql_count)
cnt = cur.fetchone()[0]
print("Before: {}".format(cnt))
cur.execute(sql_copy_data)
cur.execute(sql_count)
cnt = cur.fetchone()[0]
print("After: {}".format(cnt))
if __name__ == "__main__":
con = cx_Oracle.connect(user='[USER]', password='[PASSWORD]', dsn='[ADW SERVICE NAME]')
load_data_from_oos(con)
次のような出力が表示されたよう、BigQueryテーブルからエクスポートされたすべての200000レコードがADWインスタンスにロードできましたとのことです。

SQLPlusにおいてデータがロードされたことを確認できます。
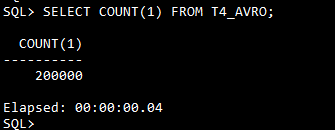
これまで、BigQueryからADWインスタンスにテーブルを移行するための各単一ステップを完成しました。
- BigQueryからGoogle Cloud Storageにテーブルをエクスポートします
- 中間サーバーを使用して、エクスポートされたファイルをGoogle Cloud StorageからOracle Object Storageに転送します
- Oracle Object StorageからADWインスタンスにデータをロードします
各ステップを統合します
上記のように、すべてのステップが完成しました。これらのステップを統合し、テーブルの移行をエンドツーエンドのジョブにします。
以下は、統合されたコードを使用して3つテーブル(T4_1、T4_2、T4_3)を移行したログです。
2019-11-06 07:19:18,372 - __main__ - INFO - =================================================
2019-11-06 07:19:18,373 - __main__ - INFO - Start to migrate table: T4_1
2019-11-06 07:19:25,315 - bq - INFO - Exported bq2adw:bqds02.T4_1 to gs://bucket-bq2adw/T4_1.csv.gz
2019-11-06 07:19:26,572 - gcs - INFO - Blob T4_1.csv.gz downloaded to /var/tmp/bq2adw/src/tmp_files/T4_1.csv.gz.
2019-11-06 07:19:26,766 - oos - INFO - Uploaded /var/tmp/bq2adw/src/tmp_files/T4_1.csv.gz
2019-11-06 07:19:26,937 - adw - INFO - T4_1: before loading count: 0
2019-11-06 07:19:29,824 - adw - INFO - T4_1: after loading count: 200000
2019-11-06 07:19:29,825 - __main__ - INFO - Spent 11.45 seconds to complete the migration of table: T4_1
2019-11-06 07:19:29,825 - __main__ - INFO - =================================================
2019-11-06 07:19:29,825 - __main__ - INFO - Start to migrate table: T4_2
2019-11-06 07:19:35,477 - bq - INFO - Exported bq2adw:bqds02.T4_2 to gs://bucket-bq2adw/T4_2.csv.gz
2019-11-06 07:19:36,444 - gcs - INFO - Blob T4_2.csv.gz downloaded to /var/tmp/bq2adw/src/tmp_files/T4_2.csv.gz.
2019-11-06 07:19:36,579 - oos - INFO - Uploaded /var/tmp/bq2adw/src/tmp_files/T4_2.csv.gz
2019-11-06 07:19:36,702 - adw - INFO - T4_2: before loading count: 0
2019-11-06 07:19:39,528 - adw - INFO - T4_2: after loading count: 200000
2019-11-06 07:19:39,528 - __main__ - INFO - Spent 9.7 seconds to complete the migration of table: T4_2
2019-11-06 07:19:39,529 - __main__ - INFO - =================================================
2019-11-06 07:19:39,529 - __main__ - INFO - Start to migrate table: T4_3
2019-11-06 07:19:44,353 - bq - INFO - Exported bq2adw:bqds02.T4_3 to gs://bucket-bq2adw/T4_3.csv.gz
2019-11-06 07:19:45,413 - gcs - INFO - Blob T4_3.csv.gz downloaded to /var/tmp/bq2adw/src/tmp_files/T4_3.csv.gz.
2019-11-06 07:19:45,561 - oos - INFO - Uploaded /var/tmp/bq2adw/src/tmp_files/T4_3.csv.gz
2019-11-06 07:19:45,683 - adw - INFO - T4_3: before loading count: 0
2019-11-06 07:19:48,382 - adw - INFO - T4_3: after loading count: 200000
2019-11-06 07:19:48,382 - __main__ - INFO - Spent 8.85 seconds to complete the migration of table: T4_3