はじめに
前回からの続きです。
AWSにおける、インシデント発生時のフローと概要をまとめます。
フロー
基本は以下のような基本的なフローとなります。
次節で詳細を解説します。
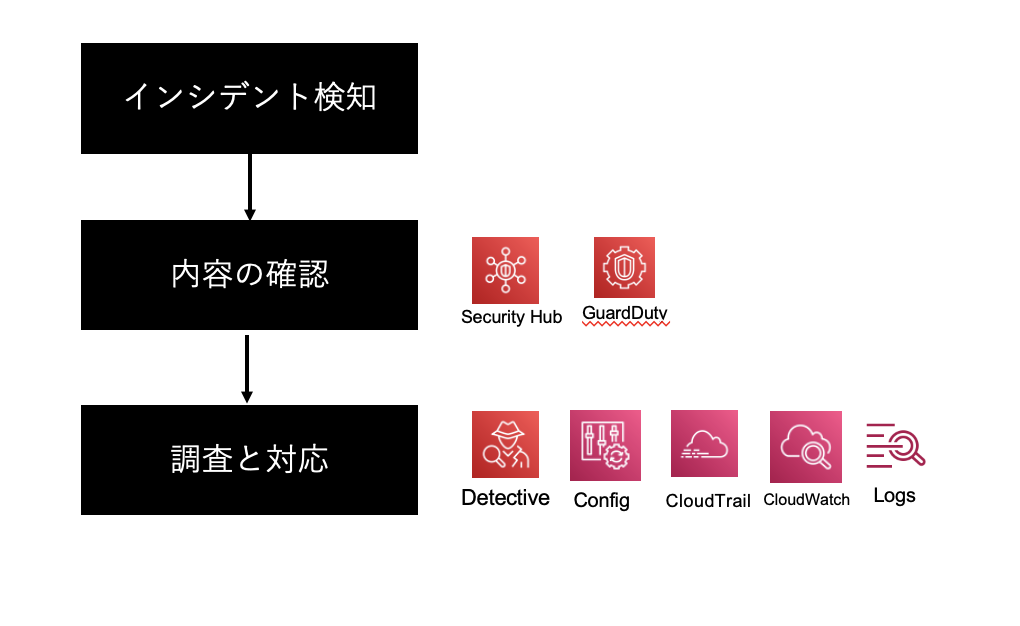
各種サービスと確認タイミング
| No | フェーズ | 概要 |
|---|---|---|
| 1 | インシデント検知 | CloudWatchやEventBridgeを利用し、各種セキュリティイベントの通知を行います。メール、SNS、Slack等々確認が容易なものに送付することが望ましいです。また、インシデント管理として、SSM IncidentManagerやServiceNowとの連携もおすすめです。 このフェーズでは、アラートのレベルにより通知有無、通知先を変更することをおすすめします。緊急度の高い(例;GuardDutyのシビリティ7.0以上など)ものは優先的に対応できるような運用体制をとっておくと良いでしょう。 |
| 2 | 内容の確認 | 通知内容から、詳細を確認します。AWS上でのイベントではSecurityHubに概ね通知内容をまとめることができるので、SecurityHubで情報を集約することがおすすめです。必要に応じて各種AWSのセキュリティサービスのコンソールまたは、検知元のサービスを確認し、対応の要否を見定めます。 |
| 3 | 調査、対応 | GuardDutyなどAWS上でのイベントであれば、Detectiveを利用することがおすすめです。該当のイベントから、どの国からの攻撃か、対象のIAMユーザは誰か、どのような操作をしたのか、どのEC2からリクエストされているのかなどドリルダウンにより関連サービスを調査可能です。この時点で、必要に応じて、該当IAMユーザ、ロールの無効化や、VPCでの通信遮断、対象EC2でのダンプ取得等、被害の拡大防止、調査のための環境保全を行いましょう。 |
まとめ
インシデント発生のフローは、比較的シンプルですが、実際に発生した場合に適切かつ迅速に対応ができるかがポイントとなります。定期的な構成の見直しや、セキュリティ診断、対応の自動化、メンバのトレーニングそしてなによりインシデント発生に備えた訓練を行いましょう。訓練により今不足していることが見えてくるはずです。
(例えばログ調査に必要なツールやノウハウなど)
Well-ArchitectedFrameworkのインシデントレスポンスを一度読むことをおすすめします。