要約
- コンセプト:報酬がスパースな環境だとエージェントが報酬に辿り着けず、学習が進まない・・ので模倣学習で人間が手本を見せる
- UnityのML-Agentsで強化学習+模倣学習(GAIL)をする手順の紹介
はじめに
Unityでは、ML-Agentsというライブラリを使うことで機械学習を行うことができます。ML-Agentsは特に強化学習(Reinforcement learning)を容易に行うことが可能であり、Unityエディタ上で容易に環境を構築、スクリプトで報酬の設定等を行うこともできます。
ですが、ゲームにおいて強化学習でうまく挙動を学習させることが難しい場合があります。
強化学習とその課題
強化学習は、エージェントの一連の行動の結果として報酬を与えることで学習が進行します。しかし、報酬がスパースな(少ない)環境では、エージェントが報酬となる行動に辿り着くことが難しいため、エージェントの学習が進まない、といった問題があります。
この問題の解決策はいくつかの方法が存在しますが、今回は模倣学習を取り入れた場合について紹介します。
模倣学習
模倣学習(Imitation learning)は、教師となる人間(TeacherやExpertとか言ったりします)のデモンストレーションをエージェントが模倣するように学習させます。
これを利用し、人間が報酬にたどり着くような行動を模倣学習でエージェントに学習させることで、エージェントは報酬を得ることが容易になります。
強化学習と模倣学習を組み合わせると、エージェントは強化学習のみの場合よりも早く報酬にたどり着く行動を学習することが可能になります。
ML-Agentsでは現在Behavioral Cloning(BC)とGenerative Adversarial Imitaiton Learning(GAIL)の2種類の模倣学習をサポートしています。
公式のドキュメントによると、それぞれ以下の特徴があるそうです。
詳しく知りたい方は敵対的模倣学習の紹介をみるといいかもです
Behavioral Cloning(BC)
- 高速に学習させられる
- デモンストレーションを正確に模倣するように学習させられる
- 多数の学習用のデモンストレーションが必要
- Unityの場合はエディタ上でリアルタイムにデモンストレーションしながら学習させられる
Generative Adversarial Imitaiton Learning(GAIL)
- デモンストレーションの数が少ない場合でも効果的
- 強化学習と組み合わせた学習が可能
- 事前学習が可能
今回は強化学習と組み合わせたいので、GAILを使う方針で進めていきます
動作環境
Unity ML-Agents 0.9.0を導入しています。
Unityではじめる強化学習 / Unity ML-Agents 0.9.0のチュートリアルを参考にして、導入と仮想環境の構築を行っています。
UnityのバージョンはUnity 2019.1.3f1、OSはWindows 10を使っています。
Pyramidsサンプルで強化学習+模倣学習を試す
ML-Agentsに入っているPyramidsサンプルを使って、強化学習+模倣学習でエージェントに課題を解かせてみます。
Pyramidsサンプルでは、エージェントは9つの部屋に区切られた環境で、以下の手順で報酬を得ます
- エージェントは赤色のボタンを探索する
- エージェントがボタンに接触すると赤色のボタンが緑色に変化。同時にゴールがランダムな位置に出現する
- エージェントはゴールを探索し、衝突によりゴールを突き崩す。
- エージェントがゴール上部の黄色のキューブに接触すると報酬をGET。
- 終了


報酬獲得までの流れをみると、よくある強化学習用のサンプル課題に比べて手順が多く、報酬が得るまでの道のりが長いようにみえます。
このような環境では、模倣学習を活用するのが有効そうです。模倣学習のために、まずはデモンストレーション用のデータを用意します。
デモンストレーション用データの作成
UnityのProjectタブから、Assets > ML-Agents > Examples > Pyramids > Scenes > PyramidsIL を開きます。
PyramidsILシーンでは、模倣学習用に予め教師用のエージェントを動かすための環境と、人間が操作するためのPlayerBrainが用意されているで、今回はこれを利用してデモンストレーション用データを作成します。
準備
PyramidsILシーンには、TeacherAreaPBとStudentAreaPBという2つのエージェント実行環境がありますが、今回はTeacherAreaPBのみを使用するので、StudentAreaPBはDisableにしておきましょう。
また、エージェントから見た視点をもとにしたデモンストレーション用データを生成したいので、OverviewCameraもDisableにし、代わりにTeacherAreaPBの中のAgentの子として新規にカメラを追加しておきます(位置・角度とかはエージェントから見た視点っぽくなっていればOKだと思います)。
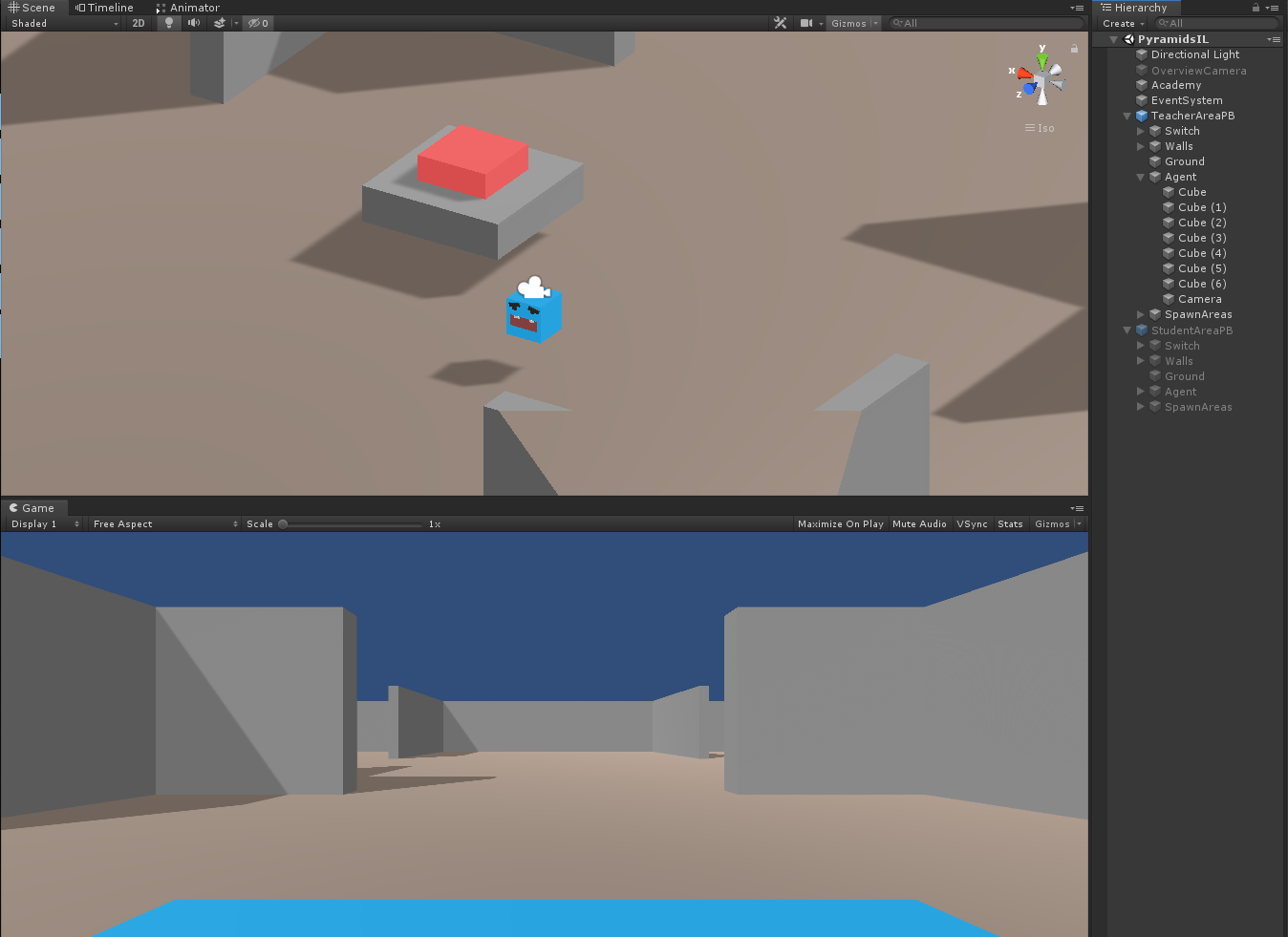
次に、TeacherAreaPBの中のAgentに、Demonstration Recorderをアタッチし、Recordにチェックをいれ、Demonstration Nameには適当な文字列をいれておきます(ここでいれた文字列が生成されるデータのファイル名になります。今回はPyramidTeacherDemonstrationにしておきます。)
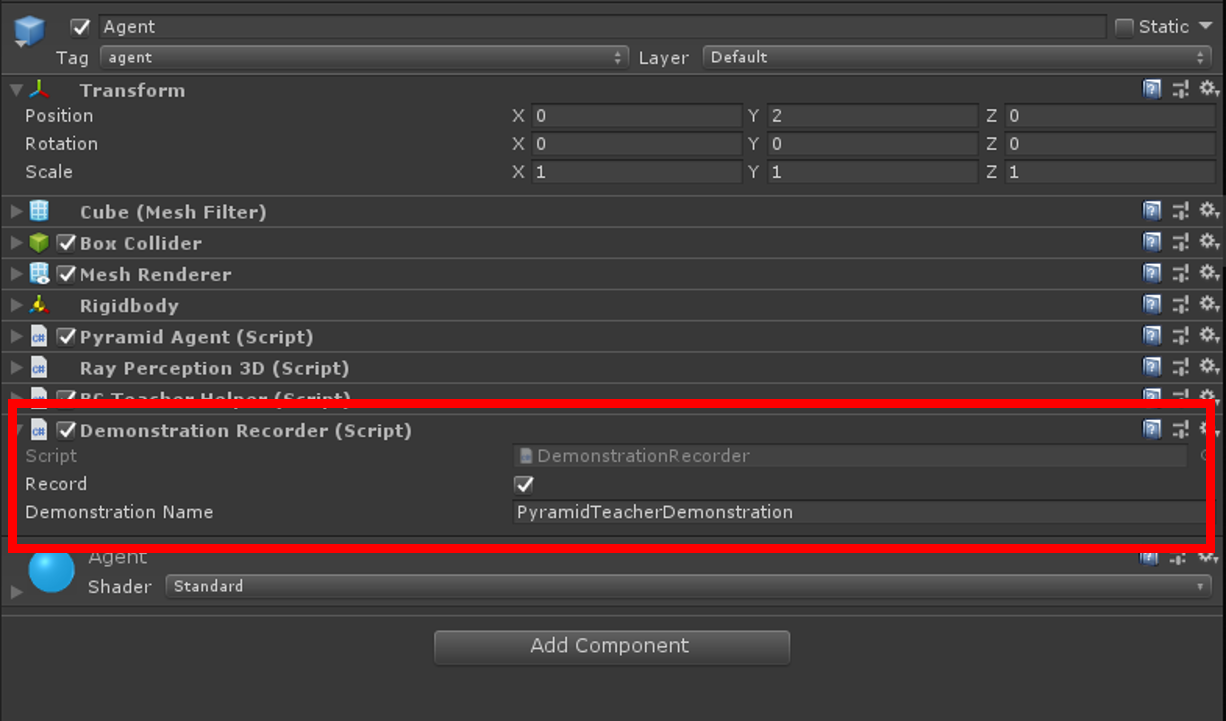
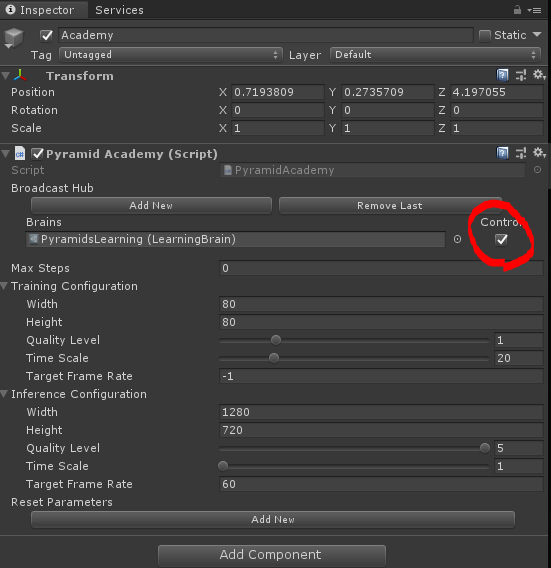
最後に、Academyに登録されたBrainのうち、PyramidsLearningのControllをチェックを外しておきます。
これでデモンストレーション用データ作成の準備は完了です。
実際にプレイしてデモンストレーション用データを作成する
Playボタンを押すとゲームが始まります。Play中はデモンストレーションが記録されます。
今回は約30回の課題を行いました。
再度Playボタンを押し、ゲームを止めるとデモンストレーションデータがAssets > Demonstrationsに生成されます。生成されるデータのファイル名はDemonstration RecorderのDemonstration Nameに入力した文字列に対応しています。ですので今回はPyramidTeacherDemonstration.demoが生成されます。
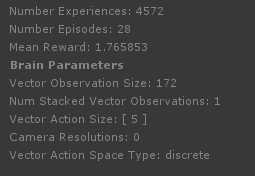
28回のデモンストレーションを行い。平均で1.7程度の報酬を得ています。
学習する
次に、生成されたデモンストレーション用データを使ってエージェントの学習を行います。
学習用のシーンとして、既に用意されているPyramidsシーンを利用します(Assets > ML-Agents > Examples > Pyramids > Scenes > Pyramids)
準備
Pyramidsシーンを開いたら、Academyの設定を行います。BrainのPyramidsLearningのControllにチェックを入れておきましょう。Time Scaleなどの設定も適宜変更しておきます(デフォルトのままでも問題ないです)
次に、先ほど生成したPyramidTeacherDemonstration.demoを、demosフォルダ(git cloneしてきたときにできたフォルダの中にあります)にコピーします。
また、同じdemosと同じ階層にある、configファイルの中の、gail_config.yamlのうち、PyramidsLearningについての設定を以下のように書き換えます。
PyramidsLearning:
summary_freq: 2000
time_horizon: 128
batch_size: 128
buffer_size: 2048
hidden_units: 512
num_layers: 2
beta: 1.0e-2
max_steps: 5.0e4
num_epoch: 3
pretraining:
demo_path: ./demos/PyramidTeacherDemonstration.demo.demo
strength: 0.5
steps: 10000
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
curiosity:
strength: 0.02
gamma: 0.99
encoding_size: 256
gail:
strength: 0.01
gamma: 0.99
encoding_size: 128
demo_path: demos/PyramidTeacherDemonstration.demo.demo
今回は、強化学習と模倣学習(GAIL)に加え、エージェントを報酬に早く導くために、デモンストレーションによるpretraining(BCののようなもの)を行い、また、curiosityによる報酬信号(エージェントの行動に対する結果の予測と実際の結果の差が大きいほど報酬がもらえる)を与えています。
準備ができたら、実際の学習を行っていきます。
学習を行う
ml-agentsディレクトリ(git cloneしてできるものです)上で、以下のコマンドを実行します。
(run-idは今回PyramidTrainingとしていますが、モデル生成時のフォルダ名になるだけなので、適当な文字列で構いません)
mlagents-learn .\config\gail_config.yaml --run-id=PyramidTraining --train
実行するとUnityエディタ上でプレイボタンを押して学習の開始を促されるので、UnityエディタのPyramidsシーン上でPlayボタンを押しましょう。
Playボタンを押すと、学習が始まります。しばらくエージェントの動きを眺めましょう。
学習結果
今回は50000ステップの学習を行いました。
2000ステップごとのMean Rewardをまとめてみました。
参考までに、デモンストレーション用データを使わない場合(GAIL+pretrainingなし)で学習させたときの結果を並べています。
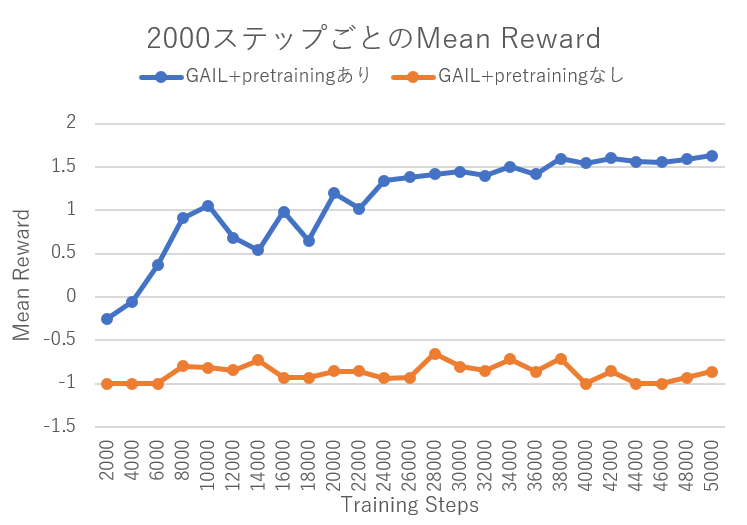
GAIL + pretrainingありの場合、早い段階でRewardを獲得できており、学習が早く進んでいることが分かります。
デモのMean Rewardが1.7くらいだったことを考えると、いい線いってるのではないでしょうか
学習したエージェントの動きを確認する
上記で学習したエージェントの振る舞いを実際に確認してみます。
準備
学習が完了すると、modelsフォルダの中に学習済みのモデルデータ(.nn形式)が作成されます。
今回の場合、models > PyramidTraining > PyramidsLearning.nn がモデルデータです。
このPyramidsLearning.nnをUnityのProjectタブにD&Dします。
学習の時と同様に、Pyramidsシーンを開きます。
次に、Assets > ML-Agents > Examples > Pyramids > Brainsにある、PyramidsLearningのModelの箇所にPyramidsLearning.nnを適用します。
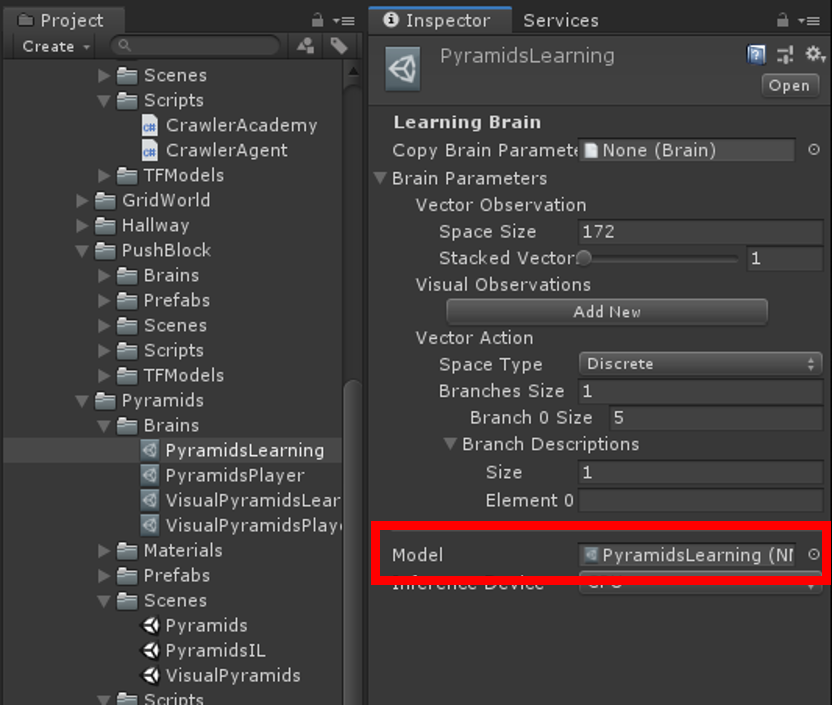
これでPyramidsLearning Brainをもつエージェントは、学習済みモデルで定義された振る舞いをとるようになります。
最後に、AcademyのControllのチェックを外します。
これで準備は完了です。
確認する
ここまでの設定ができたら、Playボタンを押して動作を確認しましょう。
ML-AgentsのPyramidサンプルを強化学習+模倣学習で学習(50000 steps) pic.twitter.com/zO58rknh2n
— らうじぃスタァライトXV4DJ:漆黒のヴィランズ Grace note (@Rauziii) August 22, 2019
ちゃんとオブジェクトを探索したり、ブロックを突き崩す動作をしていますね。
もう少し学習stepを増やせばよりスマートな挙動になるかもしれません。
まとめ
強化学習だけでうまくいかない場合でも模倣学習を組み合わせて報酬までたどり着く見本を教えてやれば、早く学習してくれることがわかりました。
今まで強化学習だけで開発していた独自のプロジェクトで利用する場合も基本的に設定用のyamlを記述して設定するだけでよいので、試してみてはどうでしょうか