いくつかの"適用するステップ"で処理を進め結果を得るとき、途中の"適用するステップ"を選択して確認できるのはその時点の状態をプレビューしているだけであって、次の"適用するステップ"のソースになるとは言えないのです。
データを抽出し変換する多くの場合、行ごとに処理が進む処理になるのでほとんど意識する必要はないでしょう。だけど、行をまたぐような処理、例えばグループ化やソートを仕掛けたとき、途中のプレビューされた状態とクエリの結果に想定していない違いが発生することがある。
すでに作業済みのクエリがあってローカル環境に保存されたキャッシュが使われることがある、ということもあるのだけど、キャッシュとは別の話。
例えばこんな話
取得したデータがすでにテーブルとして得られていて、区分ごとで最大値を持つ行を抽出したいという内容
きっと、こう考えたのでしょう。
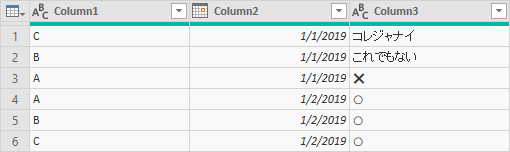
となっているとき、Column1 ごとで Column2 の最大値を持つ行を抽出したいので、Column2を降順ソートした。
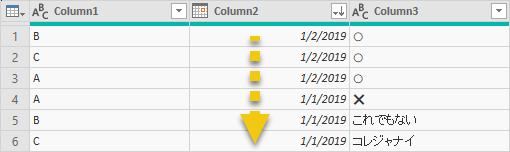
むむっ、Column1 を見るとの行の順番が違う。Excel テーブルの場合、こうなるのに...

ソートするメカニズムはExcel テーブルのそれと異なるから。Power Query のトレースログを見ればこうなるんだなってことはわかる。でも、同じような順番で結果が欲しいので Column1 を昇順でソート。
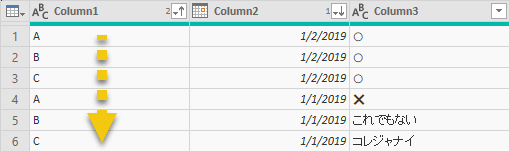
で、Column1 ごとで先頭に現れる行を抽出するために Column1 だけをキーにして[重複の削除]を適用。経験上そういう動作をすることを知っていたのでしょう。

でも、期待する結果とちがーう
let
Source = #table(
type table [Column1 = text, Column2 = date, Column3 = text],
{
{"C", #date(2019, 1, 1), "コレジャナイ"},
{"B", #date(2019, 1, 1), "これでもない"},
{"A", #date(2019, 1, 1), "❌"},
{"A", #date(2019, 1, 2), "⭕"},
{"B", #date(2019, 1, 2), "⭕"},
{"C", #date(2019, 1, 2), "⭕"}
}
),
SortedRows = Table.Sort(
Source,
{
{"Column2", Order.Descending},
{"Column1", Order.Ascending}
}
),
RemovedDuplicates = Table.Distinct(SortedRows, {"Column1"})
in
RemovedDuplicates
このクエリで見えてるデータはすべてプレビューだ
まぁ、どのクエリでもすべてプレビューなんだけど。
ソートした(データの)状態から 重複の削除をしているのではない。クエリの結果を得るまでの途中経過でもない。
クエリで得られる結果
ソート時のプレビューの状態から[重複の削除]が適用されたのではなく、このクエリの最初のステップ(Source)の状態に対し[重複の削除]が適用され、その後 Column1 のみ昇順ソートという感じになるので???となる。
適用されるべきステップがすべて適用された状態になるだけ
途中経過として観察できる(データの)状態を次に適用されると想像しているステップに渡されるということではない。Excel ワークシート上でのソートとか操作と大きく異なる。
どのような処理になっているのか
"適用するステップ"ごとに状態を保存する動作は必要にならない限りしないので、このクエリの最終結果を得るために必要な処理を取りまとめたものにソースとなるデータをダバーっと流し込んでいるイメージでよいと思う。
ここにソートするステップを含めていたとしても、Table.Distinct / 重複の削除 するためには必要なものではないから無視するような動作となると考えてよいだろう。
列を指定した Table.Distinct / 重複の削除 の有効な結果は指定した列だけなので、対象としない列についてはクエリの結果に影響を受けないものとして判定されたということかな。
どのように処理しているかはトレースログなど見るとよいかなと。
Power Query のトレースログを見て、どのように処理されているか推測するなど - Qiita
思ったこと🙄
Excel ワークシートのノリで作業をしたらだめですよ、という話。手順ごとに状態が保存されているわけではないので。そして、ソートで集計された結果を得るというのは得策ではないね。まぁ、[重複の削除] = 先頭行の抽出 ではないから、ピットフォールというかそもそもそれが間違いなんだけど。
その他
おまけ
では、挙げた例ではどうするべきなのか
Table.Group して Table.MaxN もしくは Table.Max
let
Source = #table(
type table [Column1 = text, Column2 = date, Column3 = text],
{
{"C", #date(2019, 1, 1), "コレジャナイ"},
{"B", #date(2019, 1, 1), "これでもない"},
{"A", #date(2019, 1, 1), "❌"},
{"A", #date(2019, 1, 2), "⭕"},
{"B", #date(2019, 1, 2), "⭕"},
{"C", #date(2019, 1, 2), "⭕"}
}
),
GroupedRows = Table.Group(
Source,
{"Column1"},
{
{
"Grouped",
each Table.MaxN(_, "Column2", 1),
type table [Column1=text, Column2=date, Column3=text]
}
}
),
ExpandedColumns = Table.ExpandTableColumn(
GroupedRows,
"Grouped",
{"Column2", "Column3"},
{"Column2", "Column3"}
)
in
ExpandedColumns
ソートした結果を Table.Buffer したりインデックス列を追加するのはその状態(行の順番)を保存することになるので Table.Distinct で期待する結果を得られると思うのだけど、それぞれの先頭行が現れることが保証されると考えていないので使わない。だって、重複(行)の削除のロジックが変わってしまったら結果が得られないんだから。