複数のデータソースからイイ感じデータを集めてひとつのデータセットに収める、Power BI レポートを展開していくうえでとても便利な機能である。データソースごとの プライバシー レベル (分離レベル) を適切に設定してあげるとよいのだけど、目的としてはデータロードのパフォーマンス向上とちょっとした DLP。
大事なこと
異なるデータソースのクエリをマージするときなど、プライバシー レベル についてよく知っておいた方がよい。
- Understand Power BI Desktop privacy levels - Power BI | Microsoft Docs
- Power BI Desktop のプライバシー レベルを理解する - Power BI | Microsoft Docs
The Ignore the Privacy levels and potentially improve performance does not work in the Power BI service. As such, Power BI Desktop reports with this setting enabled, which are then published to the Power BI service, do not reflect this behavior when used in the service.
Power BI Service (データセット) にはプライバシー レベルを無視するオプションがない。なので、Power BI Service で プライバシー レベルをきちんと設定してしてねってこと。
Power BI Desktop に比べ Power BI Service での ETL はなんか遅くね?とかなぜか スケジュール更新したら全行取得してんじゃね?とか起こる可能性があるのです。
そもそもの話として、Power BI Desktop の データソース設定(資格情報 / プライバシー レベル)と Power BI Service のそれは個別に管理されていて、pbix ファイルから引き継がれるものでもない。pbix ファイルには 接続先情報は含まれているけれども、資格情報とプライバシー レベルは含まれていない。
Excel でも同じです。
Privacy levels (Power Query) - Excel
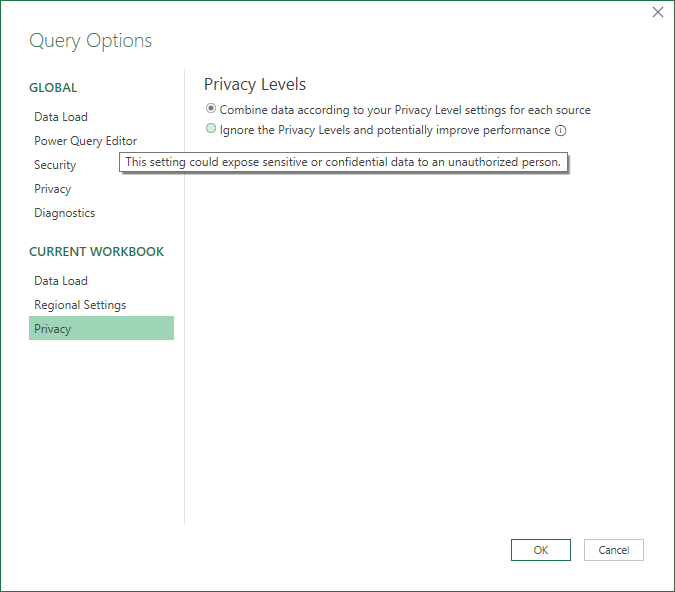
"プライバシー レベルを無視すると、パフォーマンスが向上する場合があります" とは?
このオプションを選択したときどんな事件が起きるのかということではなく、どのような動作をするのかをまずは見ておくとよい。
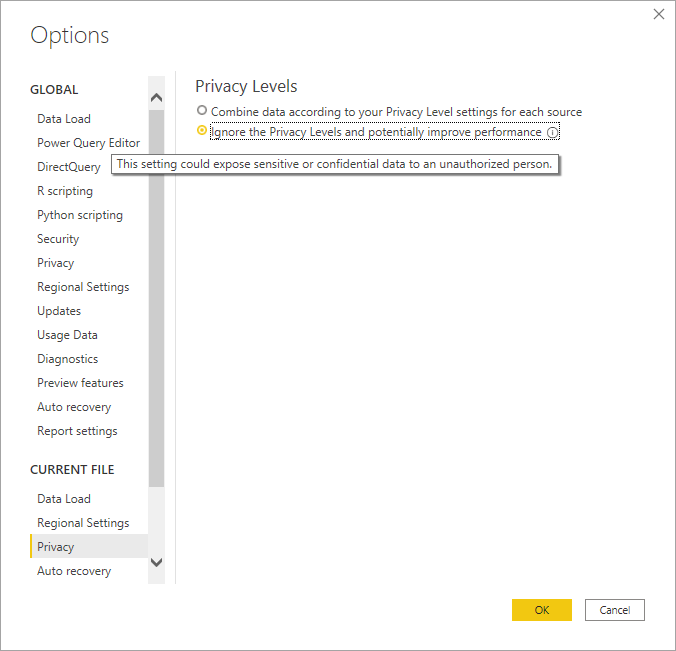
よその人に大事だったり機密のデータが開示されることがありますよというようなこと表示されてますね。
どのような動作か
パフォーマンスを向上させる Power Query のそもそもな機能を制限なく有効とするもの。
"向上する場合があります" というのもデータソース次第だから。
クエリの状態にも影響する可能性があるから Power Query の クエリ フォールディングについて併せて理解しておくとよいかと。
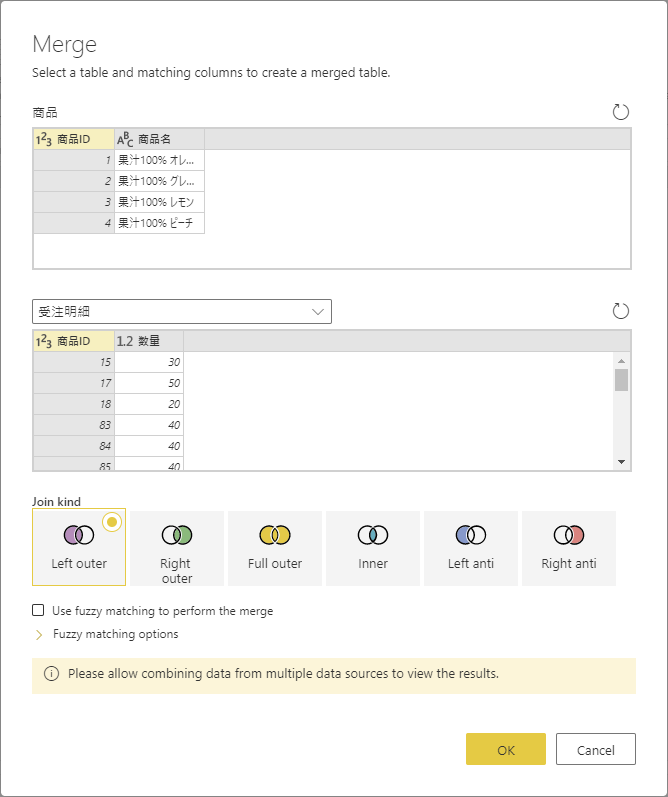
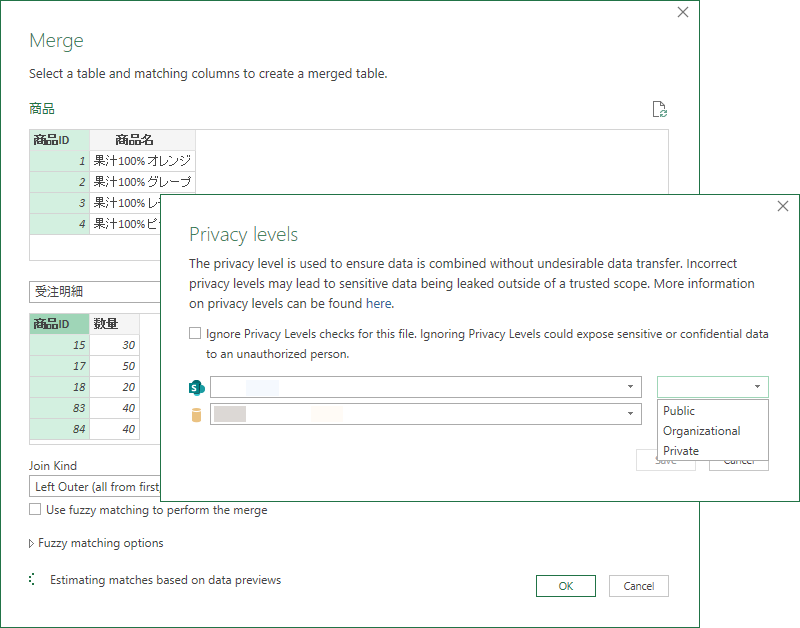
例として、Excel ワークシート上にある 4つの製品についてそれら受注数量をマージしたい。受注の実績は 同じExcel ブックにはなく、Azure SQL Database にある。ふたつのデータソースからマッシュアップしデータセットにロードするイメージ。
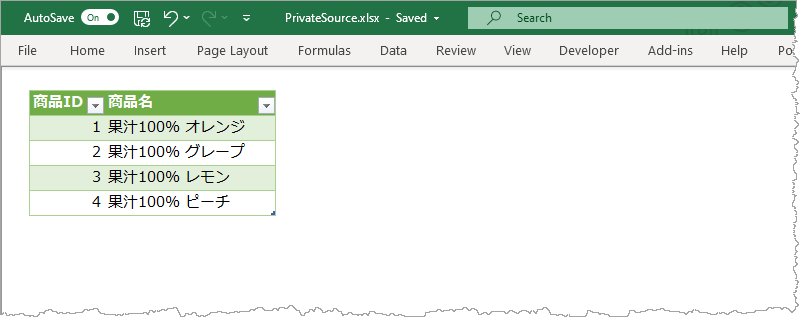
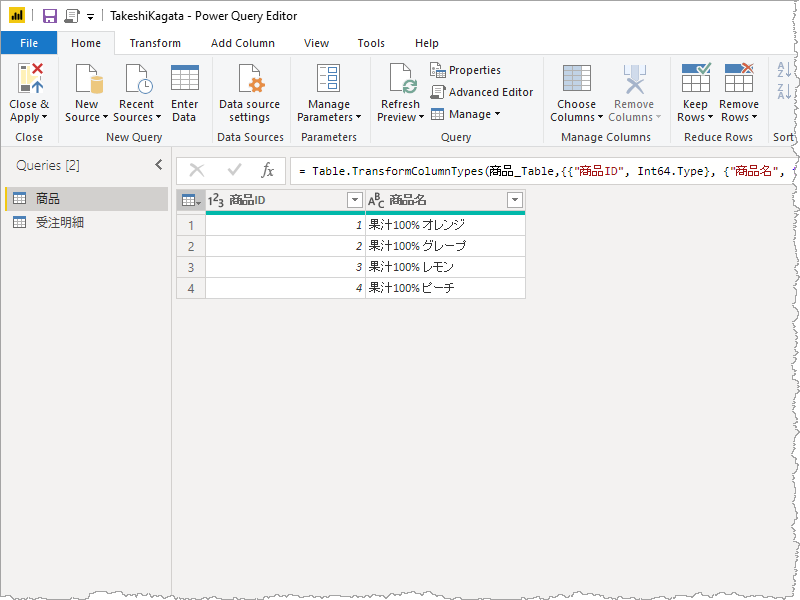
Excel のテーブルからデータ型だけ合わせてそのままロード。それぞれの関連付けでできる各行を集計する。
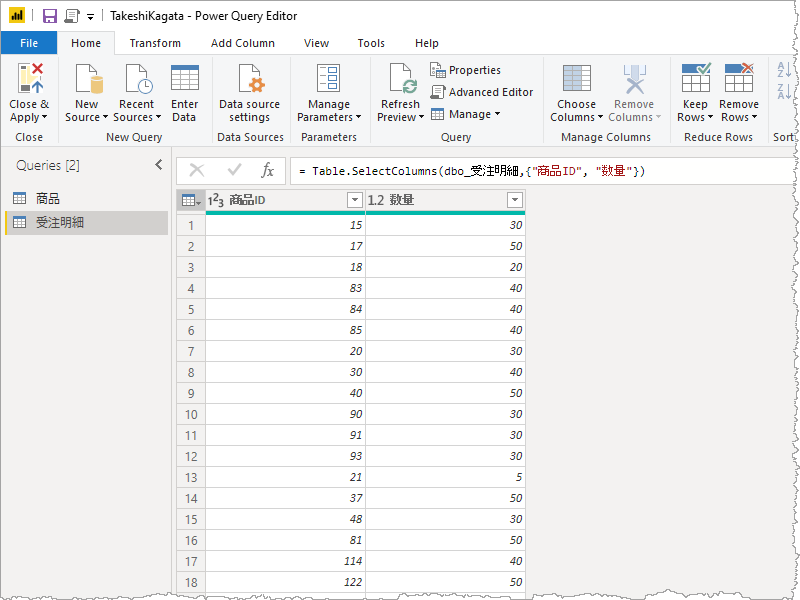
必要な列だけをAzure SQL Database から抽出。関連付けできる列:商品ID とその数量
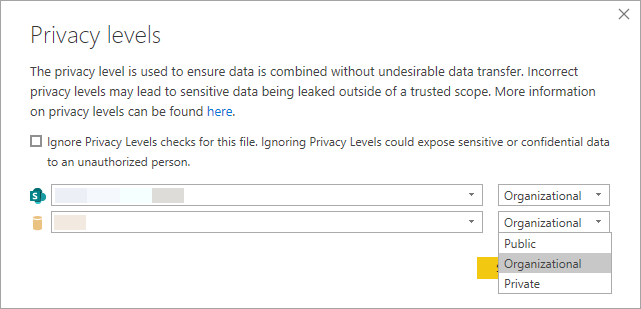
マージを試みると、まずダイアログは表示される。個々のデータソースについてプライバシー レベルを設定していないので、どうする?って聞かれる。ここでは、プライバシー レベルを無視するオプションを選択。
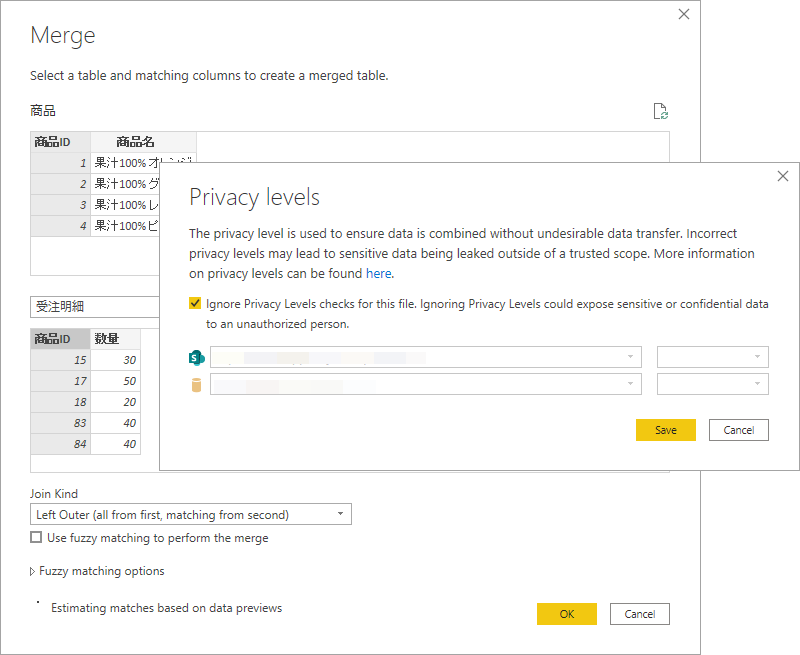
マージで得られた列から集計
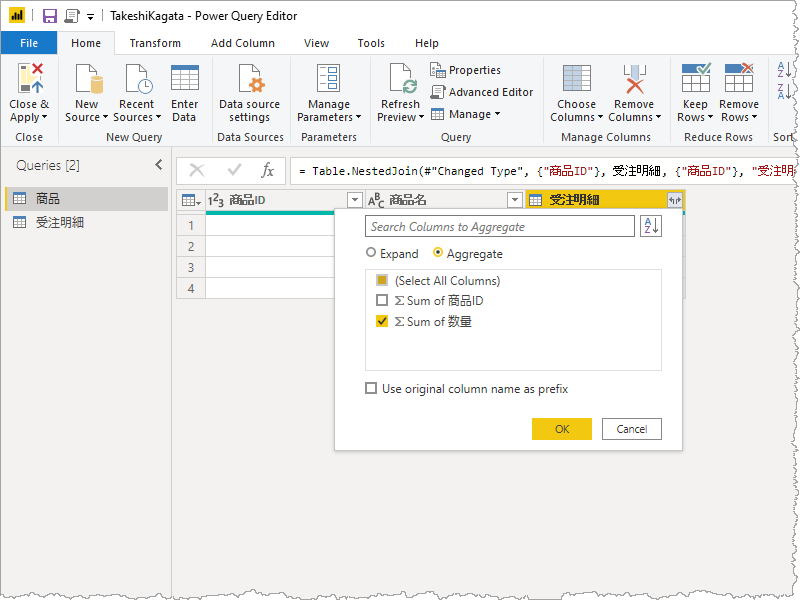
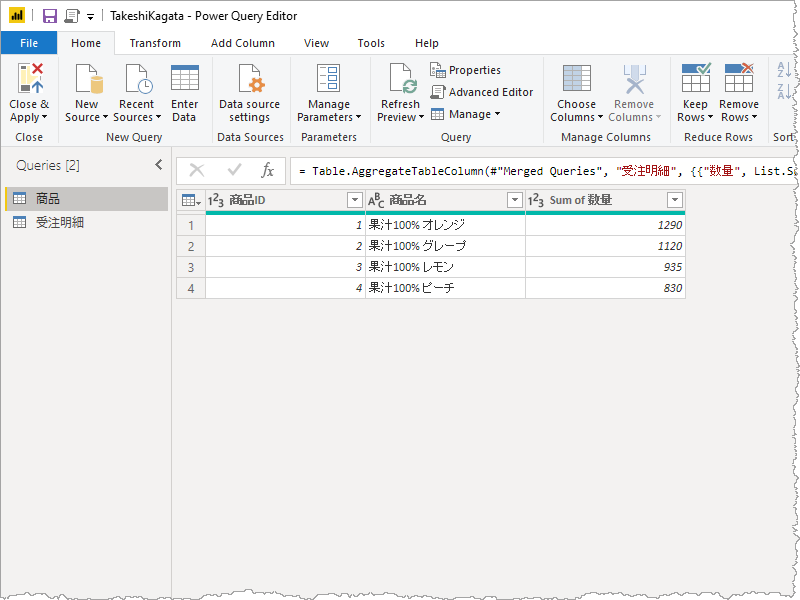
観察すべきことはなにか
ここでは Power Query (Mash-Up Engine) が Azure SQL Database にどのような問い合わせをしたか。Profiler で観察するというのもよいのだけど、Power BI Desktop にはちょうど良い機能 (クエリ診断 / Query Diagnostics) があるのでそれを使う。
Query Diagnostics | Microsoft Docs
まだプレビューだけど問題ない。細かいことは置いといても何となくわかるはず。
スタートして、Power Query エディターは閉じない。
データセットを更新する。
停止する。
すると、データセットにデータをロードするまでにどのような処理がされたかなど参照できるという機能。
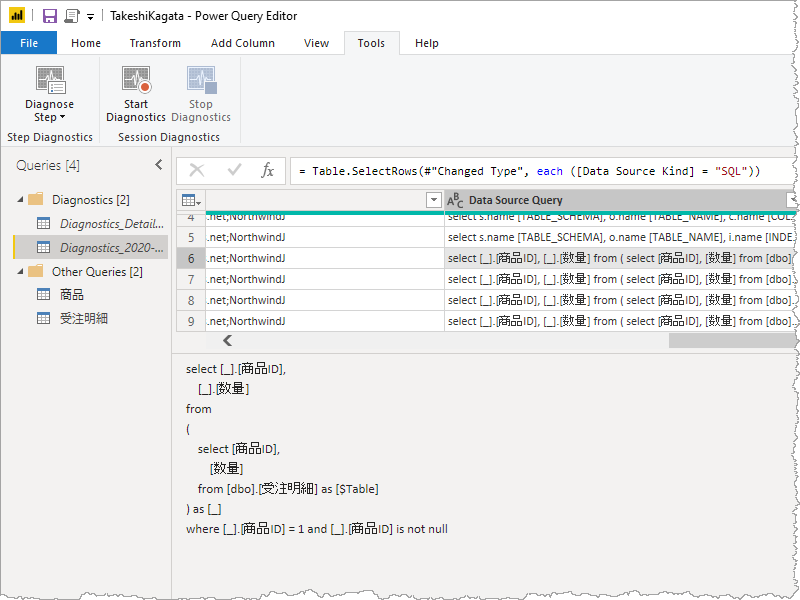
ここで注目するのは、どのような T-SQL が発行されたのか。マージ元のクエリは 4 行でそれぞれ[商品ID] 1, 2, 3, 4 であった。Azure SQL Database に対しこれらを使い問い合わせていたということが推しはかれる。
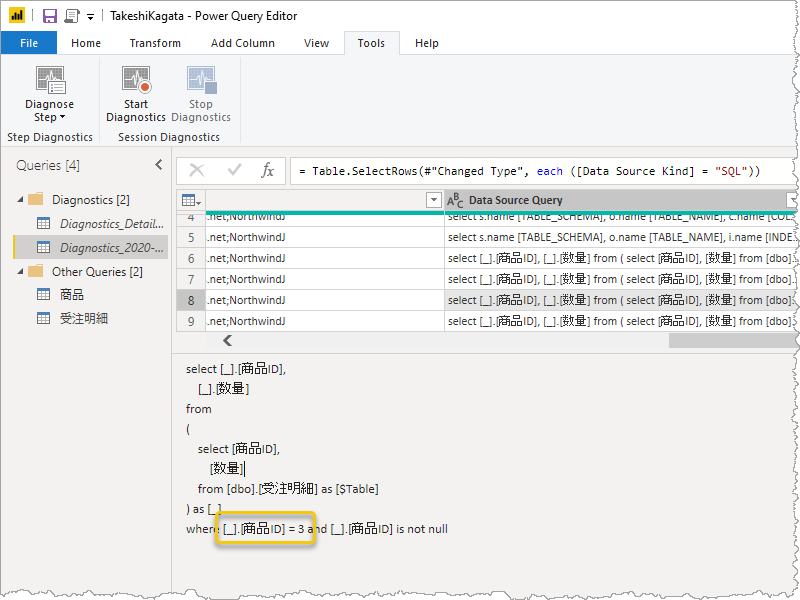
なので、Azure SQL Database のテーブルに無数の行数が存在していたとしてもPower Query では必要な行のみを取得するということがパフォーマンスが向上するということ。で、マージするための問い合わせに元のデータ、ここでは 商品ID が 異なるデータソースに渡されたということになる。渡されるデータが機微なものということもあるから、そのデータ渡しちゃっていいのかい?ってことは使う人が考えなければならないこと。
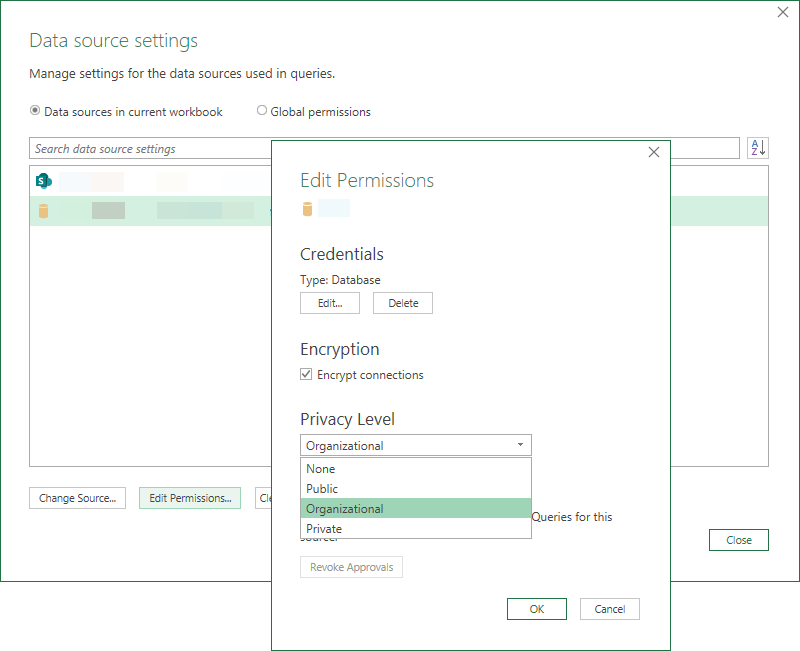
プライバシー レベル を設定しよう
プライバシー レベル は 3 つあって、それら組合せで動作が決定する。"なし" も含めると 4 だけど、"なし" との組み合わせはできないので 3 つ。
- プライベート / Private
- 組織 / Organizational
- パブリック / Public
これらの組合せで確かめるとこんな感じになった。
| マージ取得元 | マージ取得先 | マージ元の情報を... クエリの最適化を... |
|---|---|---|
| プライベート | プライベート 組織 パブリック |
情報を渡さない クエリの最適化をしない |
| 組織 | プライベート | 情報を渡さない クエリの最適化をしない |
| 組織 | 組織 |
情報を渡す クエリの最適化をする |
| 組織 | パブリック | 情報を渡さない クエリの最適化をしない |
| パブリック | プライベート 組織 パブリック |
情報を渡す クエリの最適化をする |
なお、"情報を渡す" となる組み合わせであっても、データソースが対応していなければならないので必ず最適化されるということではない。クエリの最適化が期待できるだけであって、Power Query は可能であれば最適化を試みるというスタイルなのです。
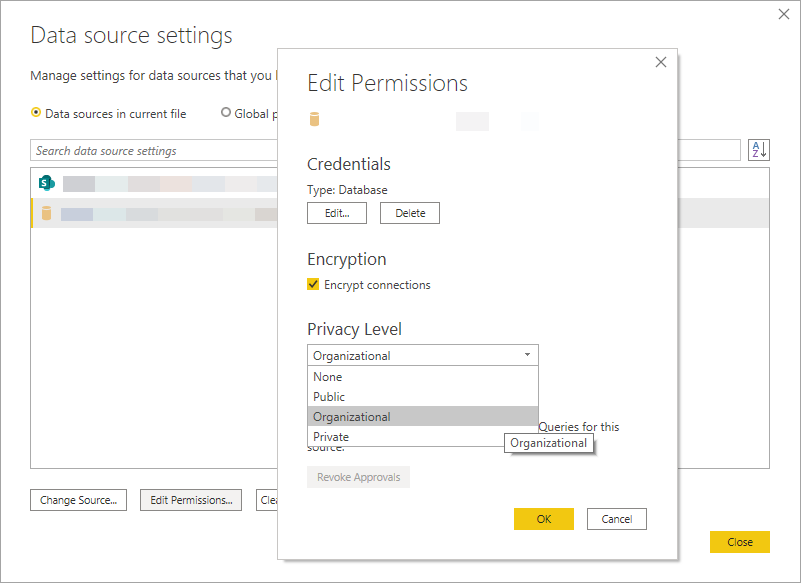
Power BI Desktop
データ セット設定 / Data source settings などから
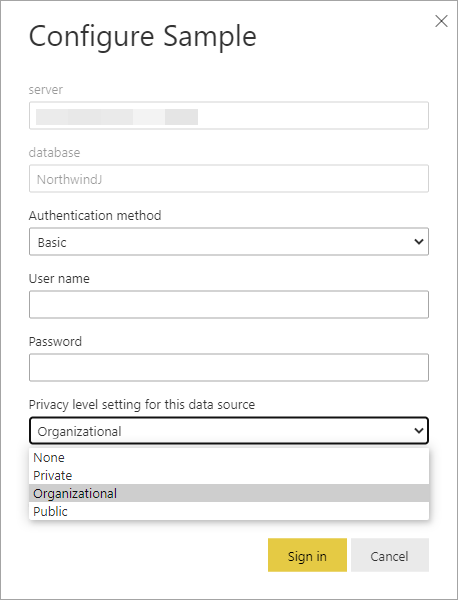
Power BI Service
設定 / Settings → データセット / Datasets → データ ソースの資格情報 / Data source credentials から
Power BI dataflows
Power BI データフローには プライバシー レベルを無視する設定がある。
データ ソースのプライバシー レベルが確認できない状態だと、どうするの?ってなる。
データ ソースのプライバシー レベルが設定されていれば なにも聞かれない。
他と同じく動作すると思ってたけど少々調子が悪いっていう事情があるので少々放置
ちなみに Excel
まぁ一緒ね。
最適化ができかった場合はどうなるのか
全行を取得することになるけど、これは仕方がない。バッファしてくれるようだ。
更新完了が遅くなるというよりは、更新を早く終えることができないだけ。
思ったこと🙄
Power Query の最適化戦略はいくつかある。そのうち、できるだけ多くの行を取り込まないということなのだけど、これらは可能な限りというスタンスになっているのである。だって、本来の目的であるデータを取得するということが重要だから。多少しょっぱいことしてても、とりあえず目的を達成することは多いかな。
別途、タイムアウトっていうことがあるから、できる設定や調整はできるだけやっておいた方がよいねと。
データソースの組合せによって違いがあったりするのか🙄たぶんないと思うけど。