Power BI Desktop / Excel でのETL作業に使用する Power Query エディターにはクエリ フォールディング機能がある。この機能は SQL Server や Office Accessなどリレーショナルデータベースをデータソースにするとき、可能な限りデータベースに発行する クエリを折りたたみ ます。データの抽出や変換時のパフォーマンスを低下しにくくすると同時に分析に必要なデータのみ取得することができる。
使いどころ
機能自体は内部的に行われるから対応するための特別な手続きをとる必要はないが、期待する結果や効果を得るためには意識しておく必要はある。クエリ フォールディングが終了すると以降の [適用するステップ] は読み込み済みのデータに対する処理となる。なので、必要最小限のデータ量を変換加工するため、最初や序盤に適用されるべきもの。
データソースに専用のビューを用意できればよいのだけど、そうもいかないときや用意されるまでにないものであれば有用かと。
機能
クエリ フォールディング(Query Folding)はサポートされるコネクターを使用する [適用するステップ] で自動的に実施されるので事前の準備や設定は不要。たとえば、
| 商品ID | 商品名 | 区分ID |
|---|---|---|
| 1 | 果汁100% オレンジ | 1 |
| 2 | ブルーベリーヨーグルト | 2 |
| 3 | ラズベリーヨーグルト | 2 |
| 4 | 清涼スカッシュ | 1 |
| というテーブル:商品から抽出しようとしていて、 |
列の除外
フィールド:[区分ID]は分析から除外とするとき、[他の列の削除]こと、Table.SelectColumns | Power Query M function reference で列を選択する。
let
Source = Source,
_商品 = Source{[Schema="dbo",Item="商品"]}[Data],
RemovedOtherColumns =
Table.SelectColumns(
_商品,
{"商品ID", "商品名"}
)
in
RemovedOtherColumns
データソースに対して発行されるクエリは
select [商品ID],
[商品名]
from [商品] as [$Table]
行の除外
フィールド:[区分ID] = 1 の行(record)のみを抽出したいとき、
let
Source = Source,
_商品 = Source{[Schema="dbo",Item="商品"]}[Data],
FilteredRows =
Table.SelectRows(
_商品,
each ([区分ID] = 1
)
),
RemovedOtherColumns =
Table.SelectColumns(
FilteredRows,
{"商品ID", "商品名"}
)
in
RemovedOtherColumns
データソースに対して発行されるクエリは
select [_].[商品ID],
[_].[商品名]
from [商品] as [_]
where [_].[区分ID] = 1 and [_].[区分ID] is not null
クエリのマージ
| 区分ID | 区分名 |
|---|---|
| 1 | 飲料 |
| 2 | 乳製品 |
| テーブル:商品にテーブル:商品区分をマージするとき、 |
let
Source = Source,
_商品 = Source{[Schema="dbo",Item="商品"]}[Data],
ExpandRecordColumn =
Table.ExpandRecordColumn(
_商品,
"商品区分",
{"区分名"}, {"区分名"}
)
in
ExpandRecordColumn
データソースに対して発行されるクエリは
select [$Outer].[商品ID] as [商品ID],
[$Outer].[商品名] as [商品名],
[$Outer].[区分ID2] as [区分ID],
[$Inner].[区分名] as [区分名]
from
(
select [_].[商品ID] as [商品ID],
[_].[商品名] as [商品名],
[_].[区分ID] as [区分ID2]
from [商品] as [_]
) as [$Outer]
left outer join [商品区分] as [$Inner] on ([$Outer].[区分ID2] = [$Inner].[区分ID])
コネクターのオプション
クエリ フォールディングをサポートするコネクターのオプション CreateNavigationProperties = true(既定値:true) であれば、マージするクエリを読み込んでおかなくても結合が可能。
その他の動作
グループ化
| 区分名 | カウント |
|---|---|
| 飲料 | 2 |
| 乳製品 | 2 |
let
Source = Source,
_商品 = Source{[Schema="dbo",Item="商品"]}[Data],
ExpandRecordColumn =
Table.ExpandRecordColumn(
_商品,
"商品区分",
{"区分名"}, {"区分名"}
),
GroupedRows =
Table.Group(
ExpandRecordColumn,
{"区分名"},
{
{"カウント", each Table.RowCount(_), type number}
}
)
in
GroupedRows
select [rows].[区分名] as [区分名],
count(1) as [カウント]
from
(
select [$Inner].[区分名]
from
(
select [_].[商品ID] as [商品ID],
[_].[商品名] as [商品名],
[_].[区分ID] as [区分ID2]
from [dbo].[商品] as [_]
) as [$Outer]
left outer join [dbo].[商品区分] as [$Inner] on ([$Outer].[区分ID2] = [$Inner].[区分ID])
) as [rows]
group by [区分名]
列のピボット
グループ集計されていれば [列のピボット] も対応
| 飲料 | 乳製品 |
|---|---|
| 2 | 2 |
let
Source = Source,
_商品 = Source{[Schema="dbo",Item="商品"]}[Data],
ExpandRecordColumn =
Table.ExpandRecordColumn(
_商品,
"商品区分",
{"区分名"}, {"区分名"}
),
GroupedRows =
Table.Group(
ExpandRecordColumn,
{"区分名"},
{
{"カウント", each Table.RowCount(_), type number}
}
),
PivotedColumn =
Table.Pivot(
GroupedRows,
List.Distinct(GroupedRows[区分名]),
"区分名",
"カウント",
List.Sum
)
in
PivotedColumn
select [$Table].[飲料],
[$Table].[乳製品]
from
(
select [rows].[区分名] as [区分名],
count(1) as [カウント]
from
(
select [$Outer].[商品ID],
[$Outer].[商品名],
[$Outer].[区分ID2],
[$Inner].[区分名]
from
(
select [_].[商品ID] as [商品ID],
[_].[商品名] as [商品名],
[_].[区分ID] as [区分ID2]
from [dbo].[商品] as [_]
) as [$Outer]
left outer join [dbo].[商品区分] as [$Inner] on ([$Outer].[区分ID2] = [$Inner].[区分ID])
) as [rows]
group by [区分名]
) [$Pivot] pivot (sum([カウント]) for [区分名] in ([飲料], [乳製品])) as [$Table]
列のマージ
Text.Combine | Power Query M function reference や Combiner functions | Power Query M function reference はサポートされていないので、&演算子を使用。
| 商品名 | 区分名 | 結合済み |
|---|---|---|
| 果汁100% オレンジ | 飲料 | 果汁100% オレンジ(飲料) |
| ブルーベリーヨーグルト | 乳製品 | ブルーベリーヨーグルト(乳製品) |
| ラズベリーヨーグルト | 乳製品 | ラズベリーヨーグルト(乳製品) |
| 清涼スカッシュ | 飲料 | 清涼スカッシュ(飲料) |
let
Source = Source,
_商品 = Source{[Schema="dbo",Item="商品"]}[Data],
ExpandRecordColumn =
Table.ExpandRecordColumn(
_商品,
"商品区分",
{"区分名"}, {"区分名"}
),
InsertedMergedColumn =
Table.AddColumn(
ExpandRecordColumn,
"結合済み",
each [商品名] & "(" & [区分名] & ")",
type text
),
RemovedOtherColumns =
Table.SelectColumns(
InsertedMergedColumn,
{"商品名", "区分名", "結合済み"}
)
in
RemovedOtherColumns
select [_].[商品名] as [商品名],
[_].[区分名] as [区分名],
(([_].[商品名] + '(') + [_].[区分名]) + ')' as [結合済み]
from
(
select [$Outer].[商品名],
[$Inner].[区分名]
from
(
select [_].[商品ID] as [商品ID],
[_].[商品名] as [商品名],
[_].[区分ID] as [区分ID2]
from [dbo].[商品] as [_]
) as [$Outer]
left outer join [dbo].[商品区分] as [$Inner] on ([$Outer].[区分ID2] = [$Inner].[区分ID])
) as [_]
得られる効果
クエリ フォールディングがサポートされるデータソースからデータを抽出するとき、すべてのレコード/フィールドを読み込んでから変換加工とすることはないので、データモデルにロードされるまでのパフォーマンス向上が期待できる。
ネイティブ クエリの表示
どのようなクエリに変換されるのかは、[適用したステップ]のコンテキストメニューから。このメニューが使用できないとき、SQLへの変換は行われていない状態にある。
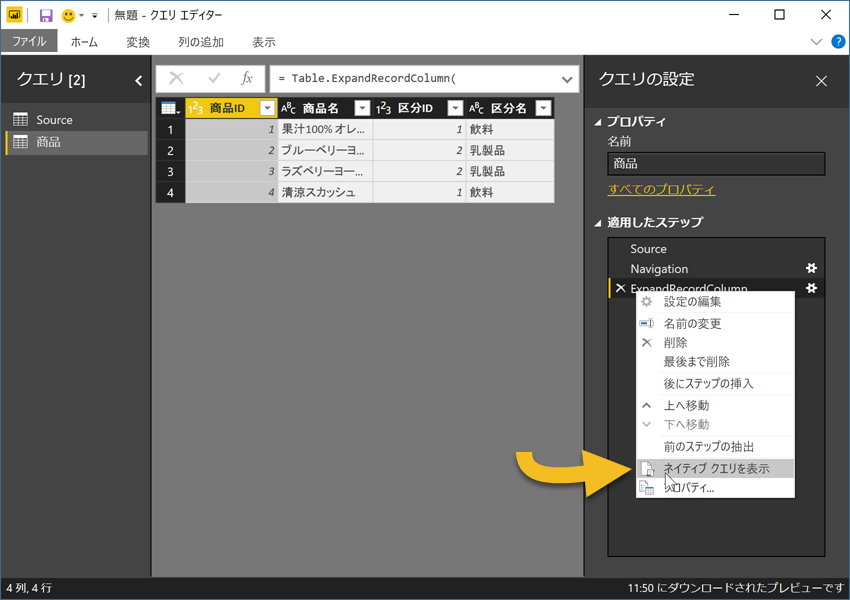
クエリ フォールディングが終了するとき
- データ型の変換やパースなど クエリ エディター独自のステップが適用された
- データソースが異なるクエリとマージされた
- Table.Buffer が適用された
※ コネクターの オプション:Queryを使用した場合はクエリ フォールディングは機能しない。
情報
Query and Data Modeling Languages | MSDN