4-4 scikit-learn
scikit-learn:公式HP
前処理
前処理
・欠損値への対応
・カテゴリ変数のエンコーディング・・・何らかの方法で数値に変換する符号化()
・特徴量の正規化
前処理-欠損値への対応
・欠損値を除去する・・・残念ながらsckit learnに「除去」機能なし!!pandas使って!!
・欠損値を補完する
*注意)「欠損値の補完」は、pandas と scikit learn の両方にあるので注意!!
前処理-カテゴリ変数のエンコーディング
・[次元を増やさない方法]カテゴリ変数の数値置換エンコーディング・・・label encoding
・[次元を増やす方法]カテゴリ変数のOne-hot(ダミー変数化)エンコーディング
前処理-カテゴリ変数のエンコーディング-カテゴリ変数のOne-hot(ダミー変数化)エンコーディング
# scikit-learn使用=preprocessingモジュール OneHotEncorderクラス
# pandas使用=get_dummies関数
*注意)preprocessingモジュール・・・まさに和訳通りで「前処理」モジュール!!
前処理-特徴量の正規化

AIで取り扱う変数について
データの値の持つ意味合い、尺度を考えると次の4つに分類できる
大別すると「定性的データ」「定量的データ」になる
### 定性的データ(質的データ、カテゴリーデータ、カテゴリカルデータ)
# 名義尺度
・電話番号、血液型
・数として意味はない
・この数を用いて計算できない。計算できるのは出現頻度だけ。
# 順序尺度
・スポーツの順位
・数の順序・大きさに意味がある。間隔に意味はない。
・大小比較ができる。間隔や平均は意味がない。
### 定量的データ(量的データ)
# 間隔尺度
・温度、西暦
・数値として間隔に意味がある。
・和差の計算はできる。比率は意味がない。
# 比例尺度
・長さ、重さ
・数値として間隔/比率に意味がある。
・和/差/比率が計算できる。
学習
教師あり学習の概要
教師あり学習
・分類(classification):離散値・・・サポートベクタマシーン、決定木、ランダムフォレスト、K近傍法
・回帰(regression):連続値
教師なし学習の概要
教師なし学習
・次元削減
・クラスタリング(cluster):離散値[グループ分類]分類グループ数を分析者が決めるアルゴリズムと決めないアルゴリズム
## 分類グループ数を分析者が決めるアルゴリズム(非階層的クラスタリング)
k-means(k平均法)
## 分類グループ数を分析者が決めないアルゴリズム(階層的クラスタリング)
### 凝集型
### 分割型
### 非階層的クラスタリング
・クラスタリング(cluster):離散値・・・k-means、階層的クラスタリング、DBSCAN
アンサンブル学習の概要
アンサンブル学習
・普通は高精度のモデルを1つ作る<=>低精度のモデルを複数作る∴アンサンブル学習
・「モデルを複数作る」ということは、「訓練データ+テストデータを複数つくる」ということ
・「全データを母集団」 => 「標本を複数抽出」 => 「モデルを複数作成」
## アンサンブル学習の手法
・バギング(bagging)・・・ブートストラップ法(重複可能な復元抽出のこと)
・ブースティング(boosting)・・・
## 結果の予測方法・・・モデル複数なので結果複数
・多数決
・平均
・加重平均
教師あり学習-分類(classification)
分類モデルの構築
# i.データセットの分割・・・学習/テストデータに分割
# ii.学習(モデルの構築)・・・既知データ学習データを用いてモデル構築
# iii.予測・・・
# iv.モデルの評価・・・未知データへの汎化性能評価
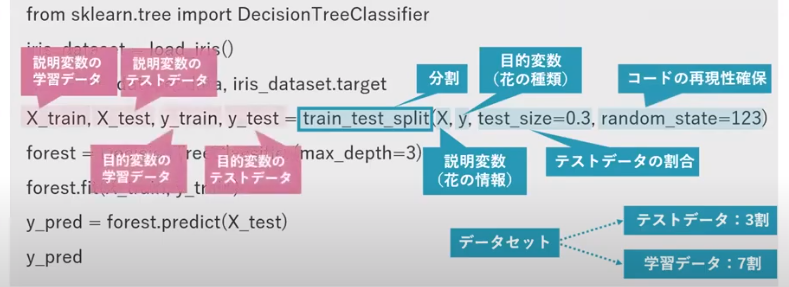
from sklearn.datasets import load_iris #[irisデータセット]datasetモジュールload_iris関数
from sklearn.model_selection import train_test_split #[データ分割]modelモジュールtrain_test_split関数
from sklearn.tree import DecisionTreeClassifier #[アルゴリズム:決定木]treeモジュールDecisionTreeClassifier関数
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)# 学習データとテストデータに分割
iris = load_iris() #irisデータセットを読み込む
X, y = iris.data, iris.target #iris情報(説明変数:長さ・幅)、iris種類(目的変数)
tree = DecisionTreeClassifier(max_depth=3) #決定木をインスタンス化する (木の最大深さ=3)
forest.fit(X_train, y_train) #学習(分類モデルの構築)
y_pred = forest.predict(X_test) #予測:説明変数のテストデータを与える
y_pred #予測値の表示
from sklearn.metrics import classification_report #評価指標:適合率、再現率
print(classification_report(y_test,y_pred))
*内容:決定木のパラメータ・・・決定木の深さ
(補足)

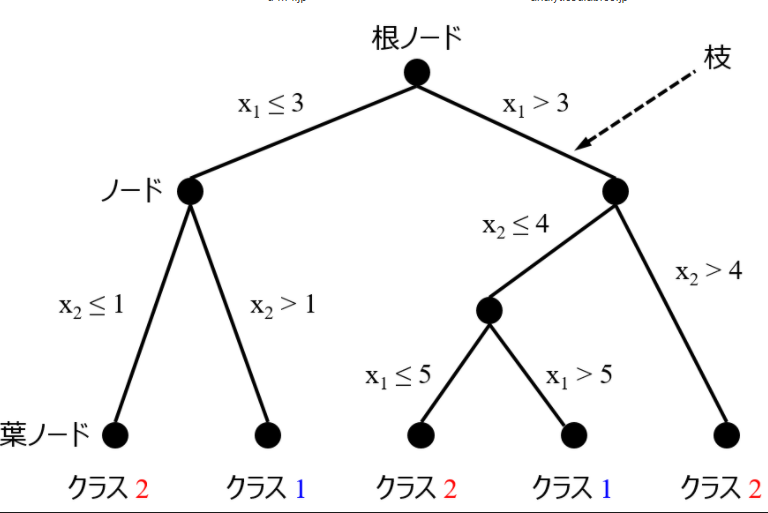
決定木
## 決定木ですること
・どの特徴量のどの値で分割するかを決めること
・クラスをきれいに決めること
## 評価指標
[不純度]・・・「クラスをきれいに分けられず、どれだけ混在しているか」
[情報利得]・・・「クラス分けしてどれだけ不純度が下がったか(良くなったか)」
「」
## 不純度の評価指標
[エントロピー]
[分類誤差]
[ジニ不純度]・・・確率に注目する
・ノード(頂点)とエッジ(線)からなる
・最上位ノード=根ノード(root node)、最下位ノード=葉ノード(leaf node)
from sklearn.tree import DecisionTreeClassifier #
## ハイパーパラメータ
決定木の深さ・・・深くしすぎる(細かく分類しすぎる)と「過学習」を起こす
細かく分類すればいいというものでもない
*注)決定木の可視化ツール・・・pydotplus、
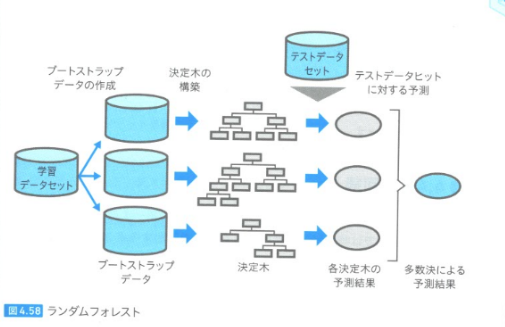
ランダムフォレスト
## 概要
・決定木の発展版。
・決定木の深さによる過学習を回避するための方法がランダムフォレスト
・学習データから複数の学習データ(ブートストラップデータ)を作って、複数の決定木を作る。=>モデルを複数作る!!
・決定木+バギング=>ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier #アンサンブルモジュールのRandomForest使う=>アンサンブル学習だから!!
ランダムフォレストの周辺技術
・ブートストラップ:データをランダムにサンプルする手法の1つ
・ブートストラップサンプリング:学習データから複数の学習データを復元抽出で作る方法
・ブートストラップデータ:ブートストラップサンプリングで作った複数の学習データの集合
・バギング:アンサンブル学習の1種。複数モデルを作り平均の多数決を取って予測結果とする。
・アンサンブル(仏:ensemble):
ランダムフォレストの周辺技術:詳細はここ
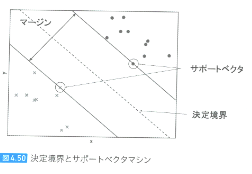
サポートベクタマシン
・分類、回帰、外れ値検出・・・どれでもOK!!
・線形分離できないデータも次元拡張することで線形分離可能
・線形分離する直線とそれに最も近い各クラスのデータ間の距離が最も大きくなる直線を引く=>マージンを最大化
## 評価指数
・[マージン]・・・2つのクラスの直線間距離
・[サポートベクタ]・・・各クラスの直線に乗っているデータ
・[決定境界]・・・2つのクラスの直線間のど真ん中
## ハイパーパラメータ
[パラメータC]・・・マージンの広さと狭さを設定
マージン大・・・サポートベクタの個数増加
マージン小・・・サポートベクタの個数減少
## 特徴
特徴量間のオーダーに影響を受けやすい
正則化をかならず行う
教師あり学習-回帰(regression)
## 正則化法
損失関数に正則化項(ペナルティー関数)を付ける
目的関数に
・ラッソ回帰(L1正則化,マンハッタンノルム)・・・least absolute shrinkage and selection operator, Lasso, LASSO
・リッジ回帰(L2正則化,ユークリッドノルム)・・・歴史的には1970年にHoerlとKennardによってリッジ回帰は提案された。
行列の対角成分について畝(ウネ/ridge)を作る意味でリッジ回帰と呼ばれる。
短縮形ではなさそうです。
ラッソとリッジのイメージ:詳細はここ
ラッソとリッジのイメージ:詳細はここ
教師なし学習
教師なし学習
・次元削減・・・主成分分析
・クラスタリング・・・[グループ分類] 階層的クラスタリング、非階層的クラスタリング
次元削減
主成分分析
主成分分析(次元圧縮手法)
・高次元のデータに対して分散が大きくなる方向を探す
・元の次元 or 低い次元にデータを変換する=>次元圧縮
from sklearn.decomposition import PCA
pca=PCA(n_components=2) # 新たな2つの特徴量に変換
X_pca = pca.fit_transform() #
*注意)decomposition 分解、PCA principal Component Analysis 主 成分 分析

クラスタリング
概要
クラスタリングには2つの手法がある
・非階層的クラスタリング:k-means法(k平均法)
・階層的クラスタリング:
一言でいうと「グループに分類」
## k-means法
・全データに適当にラベリングする(最終的にこのラベリングを適正にしてクラスタリングする)
・各々のラベル毎に重心を求める
・ラベルの貼り直し(一番近い重心のラベルに変更)
・改めてラベル毎の重心を求める
## 階層的クラスタリング
・凝集型、分割型の2つ手法がある
・
モデルの評価
精度
分類と回帰で精度の評価指標が異なる
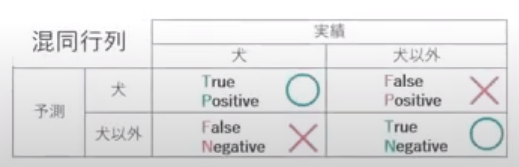
# 「分類」の4評価指標
混合行列を作りデータを抜き出して4つの評価指標を求める
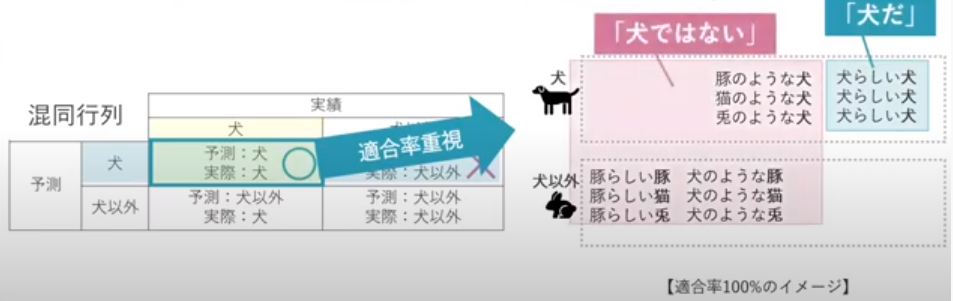
適合率と再現率はトレードオフの関係にある
# 使うクラス
scikit-learnのmetricsモジュールのclassification_report関数
### 正解率
### 再現率・・・取りこぼしたくない時に重視する指標(最大公約数、ルーズにする)
・グレイなデータ(答えが確実でないデータ)の教師ラベル(答え)をTrueにしてしまえば適合率はアップする
### 適合率・・・なるべく間違えないようにしたい時に重視する指標(最小公倍数、シビアにする)
・グレイなデータ(答えが確実でないデータ)の教師ラベル(答え)をFalseにしてしまえば適合率はアップする
### F値 ・・・バランス(再現率と適合率)の調和平均
# 「回帰」の3評価指標
### R 決定係数
### RMSE 平方平均二乗誤差
### MAE 平均絶対誤差
ハイパーパラメータの最適化
パラメータは学習時に決定されない
学習とは別にユーザーが値を指定する
決定木の深さ
ランダムフォレストに含まれる決定木の個数
・グリッドリサーチ・・・
・ランダムリサーチ
まとめ
使うクラスと関数
from sklearn.preprocessing import Imputer #
from sklearn.preprocessing import LabelEncoder # ラベルエンコーディング
from sklearn.preprocessing import OneHotEncoder # One-hotエンコーディング
from sklearn.preprocessing import StandardScalar # 分散正規化
from sklearn.model_selection import train_test_split # [関数]学習データとテストデータに分割
from sklearn.svn import SVC #[クラス]サポートベクタマシン
from sklearn.tree import DecisionTreeClassifier #[クラス]決定木
from sklearn.ensemble import RandomForestClassifier #[クラス]ランダムフォレスト
from sklearn.linear_model import LinearRegression #[クラス]線形回帰
from sklearn.decomposition import PCA #[クラス]主成分分析
from sklearn.metrics import classification_report #[関数]分類器の定量化指標(適合率、再現率、F値、正解率)
from sklearn.model_selection import cross_val_score #[関数]交差検証(cross validation)
from sklearn.svn import SVC
from sklearn.svn import SVC
*注)classfier 分類