はじめに
データ分析を勉強しているので自分の好きな物を分析してみようと考えたところ、SHISHAMOに行き着きました。どう分析してみようかとQiitaをみていたところ面白い記事を見つけました。
どうやら、Spotifyには曲ごとに属性データなるものがあるらしいです。そこでSpotifyの属性データを使ってSHISAMOを分析してみました。
手順
Spotify APIの詳細な解説は他の人に任せて、具体的な手順を簡単に説明しておきます。
1.認証作業
import spotipy
import pandas as pd
client_id = 'client_id'
client_secret = 'client_secret'
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
spotify for developersからcliend_idとclient_secretを発行します。こちらの記事を参考に行いました。
2.データ収集
albums = spotify.artist_albums(artist_id, album_type=None, country=None, limit=20, offset=0)
df = pd.DataFrame()
for i in range(len(albums['items'])):
album_url = albums['items'][i]['external_urls']['spotify']
album_name = albums['items'][i]['name']
album_truck = spotify.album_tracks(album_url)['items']
for j in range(len(album_truck)):
truck_name = album_truck[j]['name']
truck_url = album_truck[j]['external_urls']['spotify']
truck = spotify.audio_features(truck_url)[0]
tmp = pd.DataFrame(truck,index=['1',]).iloc[:,:11]
tmp['album_name'] = album_name
tmp['truck_name'] = truck_name
df = df.append(tmp)
artist_idは以下のようにSpotifyのwebplayerから取得できました。
こんな感じで以下のようなデータを取得できました。
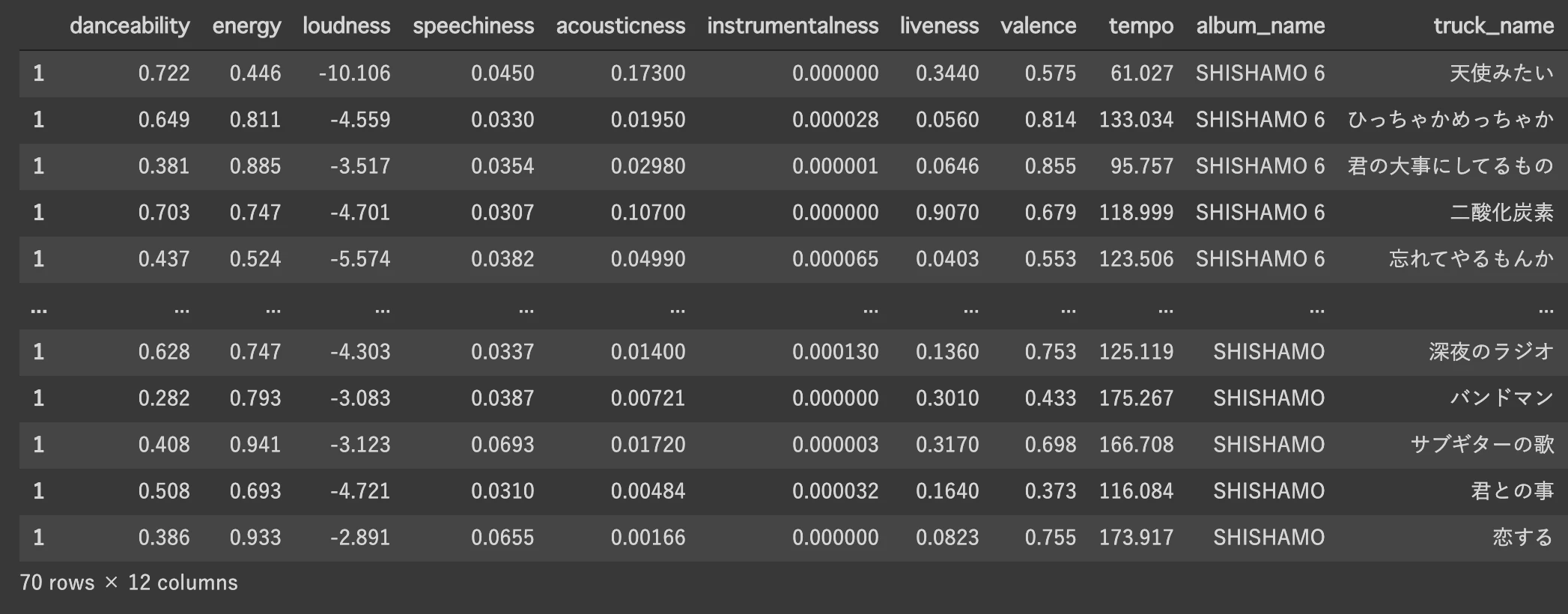
とても可愛らしい曲名が並んでいますね、またその曲を表す特徴量として11変数がSpotify上で与えられています、こちらがSpotifyの曲ごとの属性データです。この詳細についてはこちらの記事を参考にしてください。曲のテンポであったり、音圧、インスト感などがあるみたいです。
3.データ分析
今回はUmapを用いた次元圧縮&可視化による分析を行いました、Umapの詳細についてはこちらの記事を参考にしてみてください。PCAと同様にクラスタリングに適した低次元空間に射影するためのアルゴリズムと考えていただければ良いかと思っています(詳細は私も理解しきれていません)。
こちらがUmapを用いて、SHISHAMO1~6の全アルバムの曲データを二次元にプロットした結果になります。
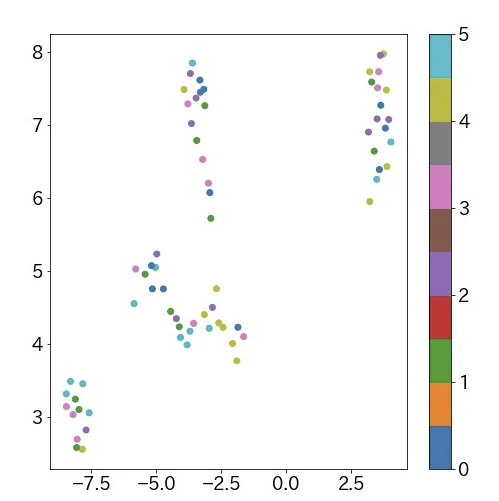
なんとなく4グループあるように見えますね。きれいにクラスタリングされたので、この結果に対して
1. アルバムごとの特徴はあるのか?
2. 人気曲の特徴はあるのか?
3. 自分の好きな曲に特徴はあるのか?
の三点についてみてみました。
1.アルバムごとに特徴はあるのか?
アルバムごとに赤丸でプロットしたグラフです。
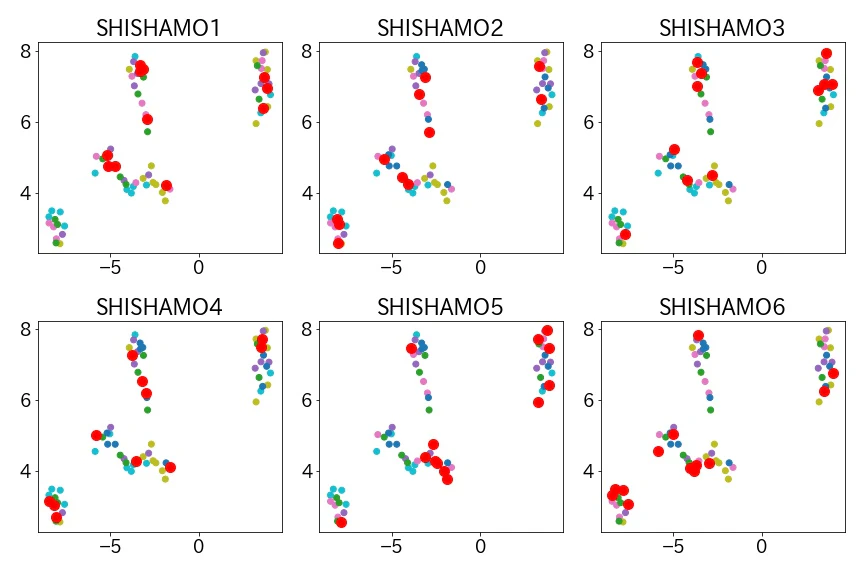
グラフ左下のグループに属する曲が1stアルバムにはなかったことがわかりました、曲の振り幅の広がるSHISHAMOの成長が感じ取れますね。またアルバムごとにバランスよく各グループの曲を収録されていることがわかります。
2.人気曲の特徴はあるのか?
人気曲には特徴があるのかについて分析してみました。SHISHAMOの人気曲については判断が難しいので独断で知名度の高そうな4曲を選びました。
**「明日も」「君と夏フェス」「恋する」「僕に彼女ができたんだ」**です、一部独断です。
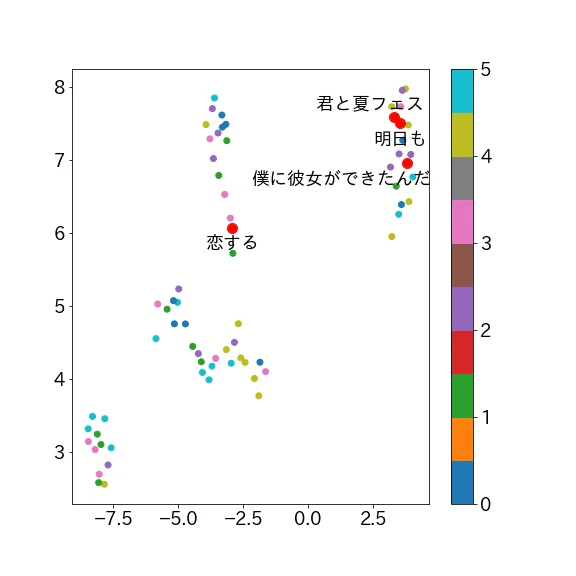
右上に集まっている気がします、アップテンポな曲が多いからですかね?二大有名な曲の**「明日も」「君と夏フェス」がかなり近くて驚きました。「恋する」はライブの締めで演奏することの多いアップテンポな曲で、「君と夏フェス」**と同じクラスターかと思っていたので意外でした。
3. 自分の好きな曲に特徴はあるのか?
自分の好きな曲に特徴があるのか分析してみました。どの曲も大好きで優劣がつかないので各アルバムから1曲ずつ選びました。
**「深夜のラジオ」「花」「中庭の少女たち」「明日も」「私の夜明け」「忘れてやるもんか」の6曲です。
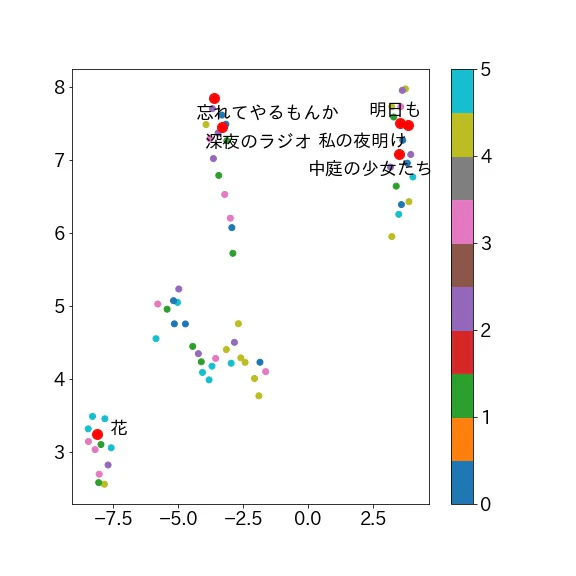
これまた右上に集まっている気がします、「花」だけ完全に分離していますね。「私の夜明け」という曲は「明日も」**とは雰囲気が異なり、暗い雰囲気もある曲なのですが右上に来ています。私自身はそんなに似ていないと思っていたのですが、似た曲なのかもしれませんね。
最後に
売れている曲や自分の好きな曲が意外に偏っていて驚きました。今回は自分の好きな歌手で分析を行いましたが、好きな曲はあるが他の曲をあまり知らないアーティストで同様の分析を行い自分へのおすすめ曲を探してみるとかやっても面白いかなと思いました。同じアーティストでもハマる曲とハマらない曲はあると思うのでそういうのが分類できたら楽しそうですね。
補足
PCAにおける各主成分の寄与率をみてました。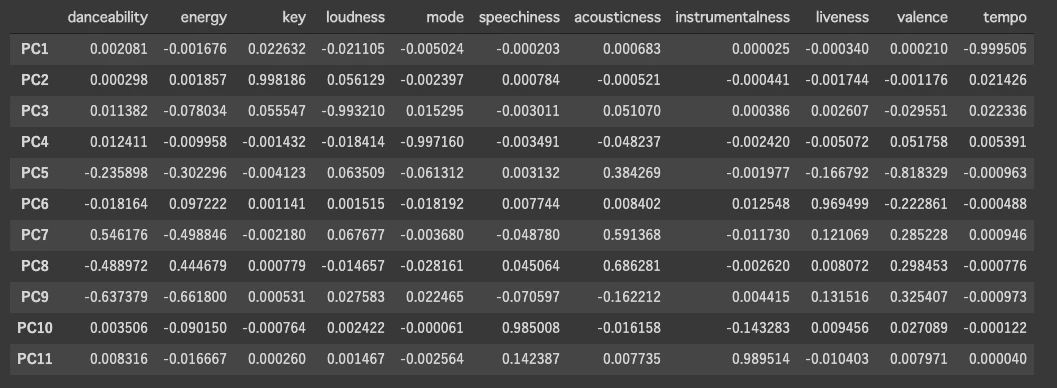
第一主成分がほとんどテンポ、第二主成分がほとんどキーで決まっていることがわかります。Umapの二軸とは完全に一致するものではありませんが、似たものをみている可能性は高いと思います。分析の最後にこれをみて少しがっかりしました。。