これまでの記事で気象庁のデータの扱い方をいくらか取り上げてきましたが、また違ったデータ取得方法(現状、この方法が一番効率的)を実践し、取得したデータの解析も軽くしていこうと思います。
<過去の記事>
・気象×Python 〜AMeDASの地点データ自動取得〜
https://qiita.com/OSAKO/items/264c77b70843045bc12b
・気象×Python 〜AMeDASの地点データ自動取得(番外編)〜
https://qiita.com/OSAKO/items/505ecee67df424963e53
・気象×Ruby 〜Mechanizeを使ってRubyスクレイピング〜
https://qiita.com/OSAKO/items/3c1cac0b5448be9ab243
1. クローリング
▶以下のような表形式で埋め込まれている数値 or 文字列を一気に取得したい。(例:東京における2019年1月の1日データ)
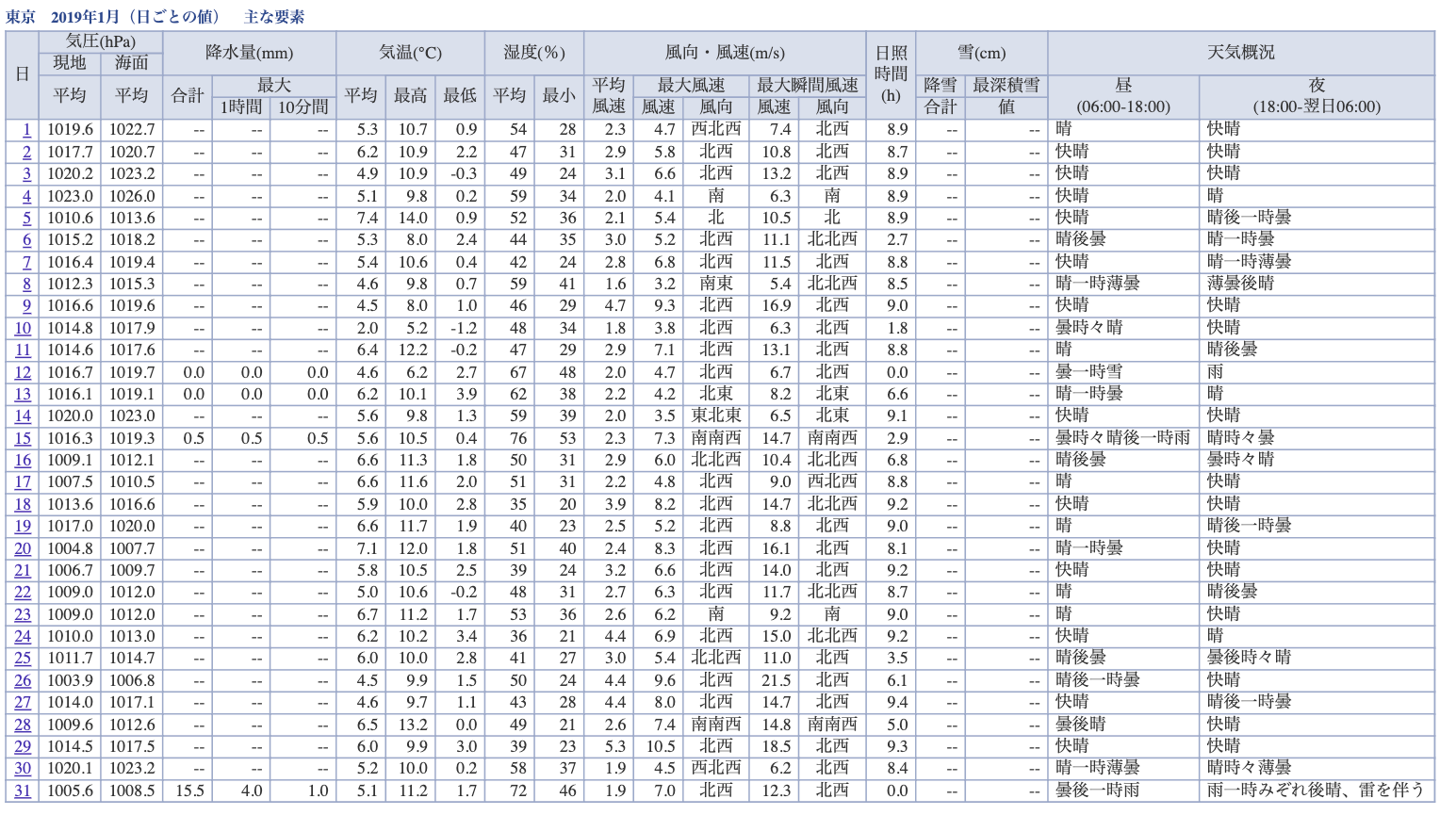
https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=44&block_no=47662&year=2019&month=01&day=1&view=
▶まずは1000以上にわたる地点のurlを全部取得して、リスト化するためのクローラを実装する。
https://www.data.jma.go.jp/obd/stats/etrn/index.php?prec_no=44&block_no=47662&year=&month=&day=&view=
↑取得したいurlの例(prec_noやblock_noのidが地点によって異なる)
手順
①まずはこちらのurlから各地域にアクセスするためのurlが欲しいので、areaタグ配下のhref属性を検索してリスト化する。(下記コードのget_area_linkメソッド)
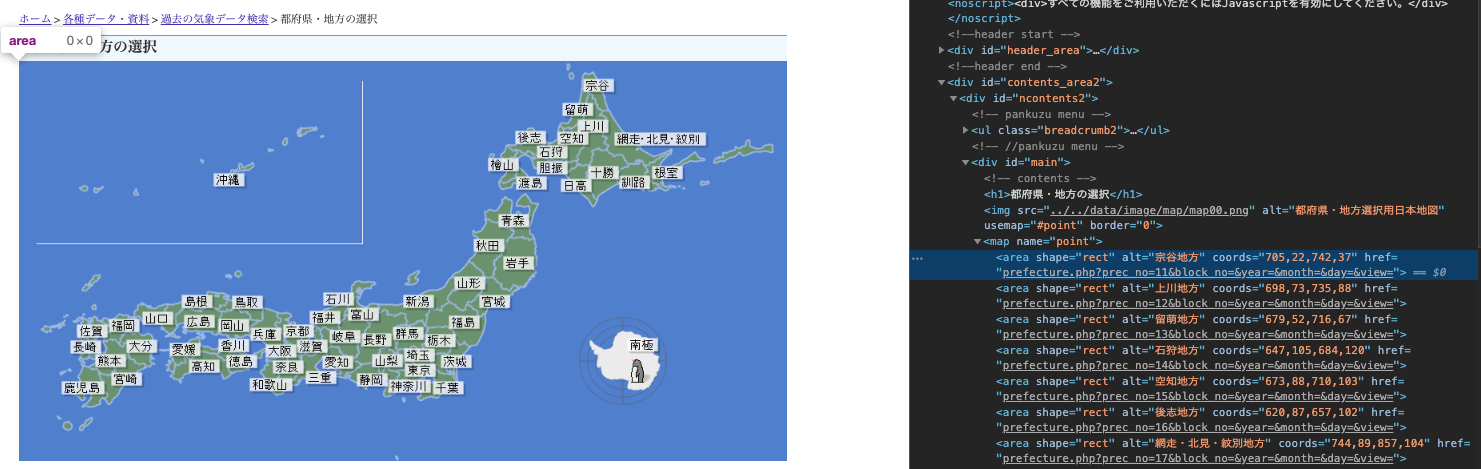
②上記でリスト化した各地域のurlをキーにして、同様に各地点のhref属性を検索すれば、prec_noとblock_noにidが含まれた目的のurlが取得できる。(下記コードのget_station_linkメソッド)
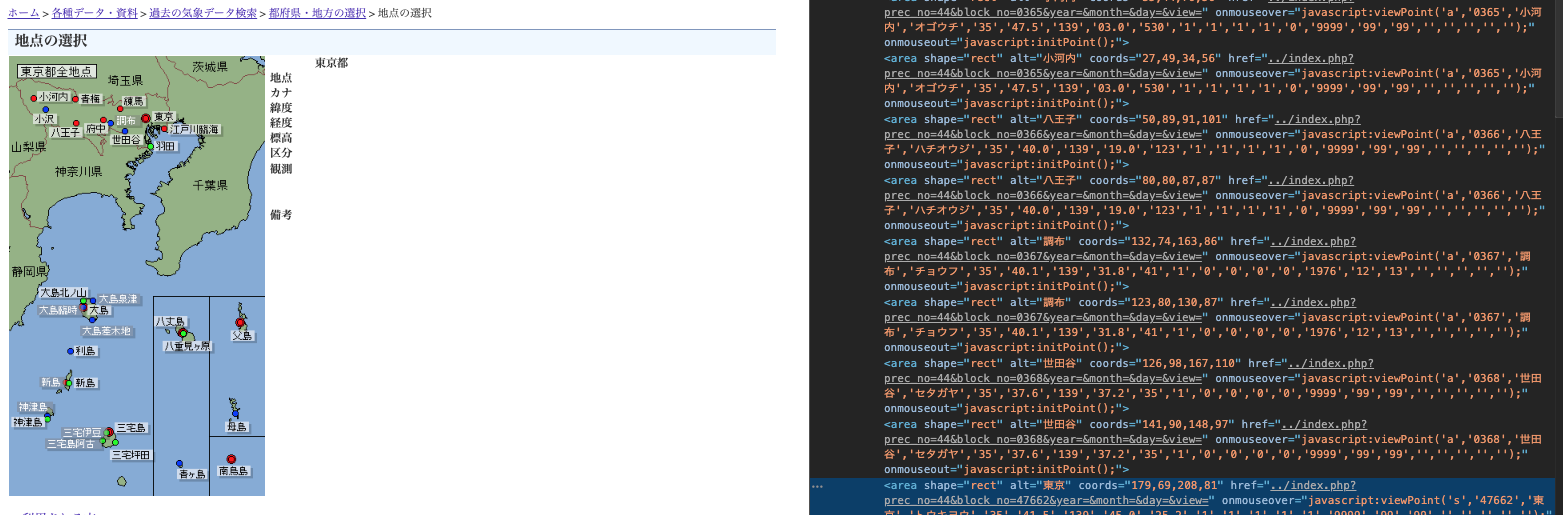
③あとは、リスト化したurlを少々整形してからcsvに保存する。(下記コードのdata_arangeメソッド)
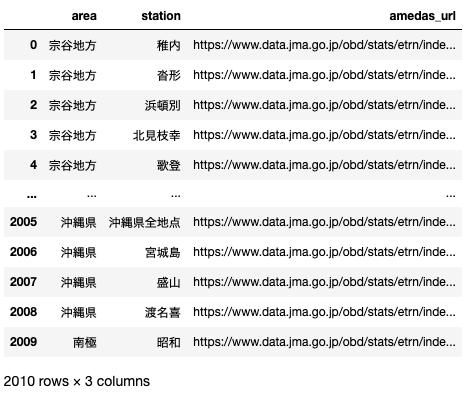
プログラム
# -*- coding: utf-8 -*-
import pandas as pd
import urllib.request
from bs4 import BeautifulSoup
class Get_amedas_station:
def __init__(self):
url = 'https://www.data.jma.go.jp/obd/stats/etrn/select/prefecture00.php?prec_no=&block_no=&year=&month=&day=&view='
html = urllib.request.urlopen(url)
self.soup = BeautifulSoup(html, 'html.parser')
def get_area_link(self):
elements = self.soup.find_all('area')
self.area_list = [element['alt'] for element in elements]
self.area_link_list = [element['href'] for element in elements]
def get_station_link(self):
out = pd.DataFrame(columns=['station','url','area'])
for area, area_link in zip(self.area_list, self.area_link_list):
url = 'https://www.data.jma.go.jp/obd/stats/etrn/select/'+ area_link
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
elements = soup.find_all('area')
station_list = [element['alt'] for element in elements]
station_link_list = [element['href'].strip('../') for element in elements]
df1 = pd.DataFrame(station_list,columns=['station'])
df2 = pd.DataFrame(station_link_list,columns=['url'])
df = pd.concat([df1, df2],axis=1).assign(area=area)
out = pd.concat([out,df])
print(area)
self.out = out
def data_arange(self):
out = self.out[~self.out.duplicated()].assign(append='https://www.data.jma.go.jp/obd/stats/etrn/')
out['amedas_url'] = out['append'] + out['url']
out = out.loc[:,['area','station','amedas_url']]
out.to_csv('amedas_url_list.csv',index=None, encoding='SJIS')
if __name__ == '__main__':
amedas = Get_amedas_station()
amedas.get_area_link()
amedas.get_station_link()
amedas.data_arange()
2. スクレイピング
▶本題のAMeDASデータの取得に関してだが、今回は1日・1時間・10分データの異なる時間スケールに対応したプログラムを書いた(ただし、コード量は比較的多く、無駄が多いかもしれないので要改善)
▶注意点として、どのAMeDAS地点を選択するかで観測種目が違う。(選択された地点が気象台とそうでない場合で異なる)
<例えば、各時間スケールで東京と八王子間で観測種目を比較してみる。>
・1日データ
東京
八王子
・1時間データ
東京
八王子
・10分データ
東京
八王子






プログラム
# -*- coding: utf-8 -*-
import re
import time
import numpy as np
import pandas as pd
import urllib.request
from bs4 import BeautifulSoup
from datetime import timedelta
from datetime import datetime as dt
from dateutil.relativedelta import relativedelta
# 各AMeDAS地点のurlから取得対象データを検索し、リスト化するメソッド
def search_data(url):
html = urllib.request.urlopen(url)
time.sleep(1)
soup = BeautifulSoup(html, 'html.parser')
element = soup.find_all('tr', attrs={'class':'mtx', 'style':'text-align:right;'})
out = [list(map(lambda x: x.text, ele)) for ele in element]
return out
class Get_amedas_data:
def __init__(self,area_name,station_name):
# 指定した地域と地点から対象のurlを参照する
self.st_name = station_name
self.a_name = area_name
amedas_url_list = pd.read_csv('amedas_url_list.csv',encoding='SJIS')
df = amedas_url_list[(amedas_url_list['area']==self.a_name) & (amedas_url_list['station']==self.st_name)]
amedas_url = df.iat[0,2]
# urlから正規表現で数字を取得する(prec_noとblock_noのidが必要)
pattern=r'([+-]?[0-9]+\.?[0-9]*)'
id_list=re.findall(pattern, amedas_url)
self.pre_id = id_list[0]
self.s_id = id_list[1]
# 1日データは1月分のデータとしてまとめて取得できるため、開始月と終了月を指定する
def set_date1(self, startmonth, endmonth):
self.start = startmonth
self.end = endmonth
strdt = dt.strptime(self.start, '%Y%m')
enddt = dt.strptime(self.end, '%Y%m')
months_num = (enddt.year - strdt.year)*12 + enddt.month - strdt.month + 1
# 開始月〜終了月までの月をリスト化
self.datelist = map(lambda x, y=strdt: y + relativedelta(months=x), range(months_num))
# 1時間 or 10分データに関しては、開始日と終了日を指定する
def set_date2(self,startdate,enddate):
self.start = startdate
self.end = enddate
strdt = dt.strptime(self.start, '%Y%m%d')
enddt = dt.strptime(self.end, '%Y%m%d')
days_num = (enddt - strdt).days + 1
# 開始日〜終了日までの日付をリスト化
self.datelist = map(lambda x, y=strdt: y + timedelta(days=x), range(days_num))
# 予め空のデータフレームを作成しておく。気象台のある地点の方が取得できる要素が多い。
# 取得したい時間スケールを指定(type)
def dl_data(self, type):
# dailyデータに関する空のデータフレーム
data1 = pd.DataFrame(columns=['年月','日','平均現地気圧','平均海面気圧','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均湿度','最小湿度','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','日照時間','降雪','最深積雪','天気概況(昼)','天気概況(夜)'])
data1_ = pd.DataFrame(columns=['年月','日','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','最多風向','日照時間','降雪','最深積雪'])
# hourlyデータに関する空のデータフレーム
data2 = pd.DataFrame(columns=['日付','時','現地気圧','海面気圧','降水量','気温','露点温度','蒸気圧','湿度','風速','風向','日照時間','全天日射量','降雪','積雪','天気','雲量','視程'])
data2_ = pd.DataFrame(columns=['日付','時','降水量','気温','風速','風向','日照時間','降雪','積雪'])
# 10minデータに関する空のデータフレーム
data3 = pd.DataFrame(columns=['日付','時分','現地気圧','海面気圧','降水量','気温','相対湿度','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間'])
data3_ = pd.DataFrame(columns=['日付','時分','降水量','気温','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間'])
# リスト化した月 or 日付リストを回しながらデータを取得しつつ、縦に結合しながらデータフレームを作成する
for dt in self.datelist:
d = dt.strftime("%Y%m%d")
yyyy = d[0:4]
mm = d[4:6]
dd = d[6:8]
if type=='daily':
# 気象台のある地点のblock_noは5桁の番号
if len(self.s_id) == 5:
pattern = 's1'
url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1'
out = search_data(url)
df = (pd.DataFrame(out, columns=['日','平均現地気圧','平均海面気圧','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均湿度','最小湿度','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','日照時間','降雪','最深積雪','天気概況(昼)','天気概況(夜)'])).assign(年月=f'{yyyy}{mm}')
df = df.loc[:,['年月','日','平均現地気圧','平均海面気圧','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均湿度','最小湿度','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','日照時間','降雪','最深積雪','天気概況(昼)','天気概況(夜)']]
data1 = pd.concat([data1, df])
data1.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS')
else:
pattern = 'a1'
url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1'
out = search_data(url)
df = (pd.DataFrame(out, columns=['日','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','最多風向','日照時間','降雪','最深積雪'])).assign(年月=f'{yyyy}{mm}')
df = df.loc[:,['年月','日','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','最多風向','日照時間','降雪','最深積雪']]
data1_ = pd.concat([data1_, df])
data1_.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS')
elif type=='hourly':
if len(self.s_id) == 5:
pattern = 's1'
url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1'
out = search_data(url)
# 日付の列を追加(24個分)
date = pd.DataFrame((np.full([24,1], f'{yyyy}{mm}{dd}')),columns=['日付'])
df = pd.DataFrame(out, columns=['時','現地気圧','海面気圧','降水量','気温','露点温度','蒸気圧','湿度','風速','風向','日照時間','全天日射量','降雪','積雪','天気','雲量','視程'])
df = pd.concat([date, df],axis=1)
data2 = pd.concat([data2, df])
data2.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS')
else:
pattern = 'a1'
url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1'
out = search_data(url)
date = pd.DataFrame((np.full([24,1], f'{yyyy}{mm}{dd}')),columns=['日付'])
df = pd.DataFrame(out, columns=['時','降水量','気温','風速','風向','日照時間','降雪','積雪'])
df = pd.concat([date, df],axis=1)
data2_ = pd.concat([data2_, df])
data2_.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS')
elif type=='10min':
if len(self.s_id) == 5:
pattern = 's1'
url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1'
out = search_data(url)
# 日付の列を追加(6×24個分)
date = pd.DataFrame((np.full([144,1], f'{yyyy}{mm}{dd}')),columns=['日付'])
df = pd.DataFrame(out, columns=['時分','現地気圧','海面気圧','降水量','気温','相対湿度','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間'])
df = pd.concat([date, df],axis=1)
data3 = pd.concat([data3, df])
data3.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS')
else:
pattern = 'a1'
url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1'
out = search_data(url)
date = pd.DataFrame((np.full([144,1], f'{yyyy}{mm}{dd}')),columns=['日付'])
df = pd.DataFrame(out, columns=['時分','降水量','気温','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間'])
df = pd.concat([date, df],axis=1)
data3_ = pd.concat([data3_, df])
data3_.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS')
print(f'{self.a_name}_{self.st_name}_{yyyy}-{mm}-{dd}_{type}')
print(f'{self.a_name}_{self.st_name}における{self.start}〜{self.end}の{type}データをダウンロードしました。')
if __name__ == '__main__':
a_name = input('ダウンロードしたい地域を入力してください:')
st_name = input('ダウンロードしたい地点を入力してください:')
amedas = Get_amedas_data(a_name,st_name)
type = input('時間スケールを選択してください(daily or hourly or 10min):')
if type == 'daily':
start= input('取得したい開始月(yyyymm)を入力してください:')
end = input('取得したい終了月(yyyymm)を入力してください:')
amedas.set_date1(start,end)
else:
start= input('取得したい開始日(yyyymmddを入力してください:')
end = input('取得したい終了日(yyyymmdd)を入力してください:')
amedas.set_date2(start,end)
amedas.dl_data(type)
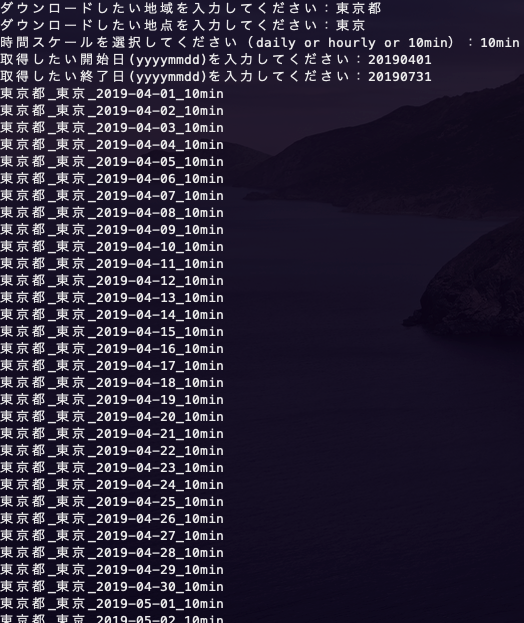
地域:東京都
地点:東京
時間スケール:10min
開始日:20190401
終了日:20190731
という条件で試しにデータをダウンロードしてみる。
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from numpy.fft import fftn, ifftn, fftfreq
class FFT:
def __init__(self):
df = pd.read_csv('東京都_東京_20190401-20190731_10min.csv', encoding='SJIS').replace(['--','×'],-99)
df['気温'] = df['気温'].astype(float)
y = df['気温'].replace(-99, (df['気温'] > -99).mean()).values
y = (y - np.mean(y)) * np.hamming(len(y))
'''
サンプリング周波数 fs → 1秒間にサンプリングされるデータ数 第二引数にはd=1.0/fs
今回のサンプリング周波数は10分間隔データなので1/600
'''
self.z = np.fft.fft(y)
self.freq = fftfreq(len(y), d=1.0/(1/600))
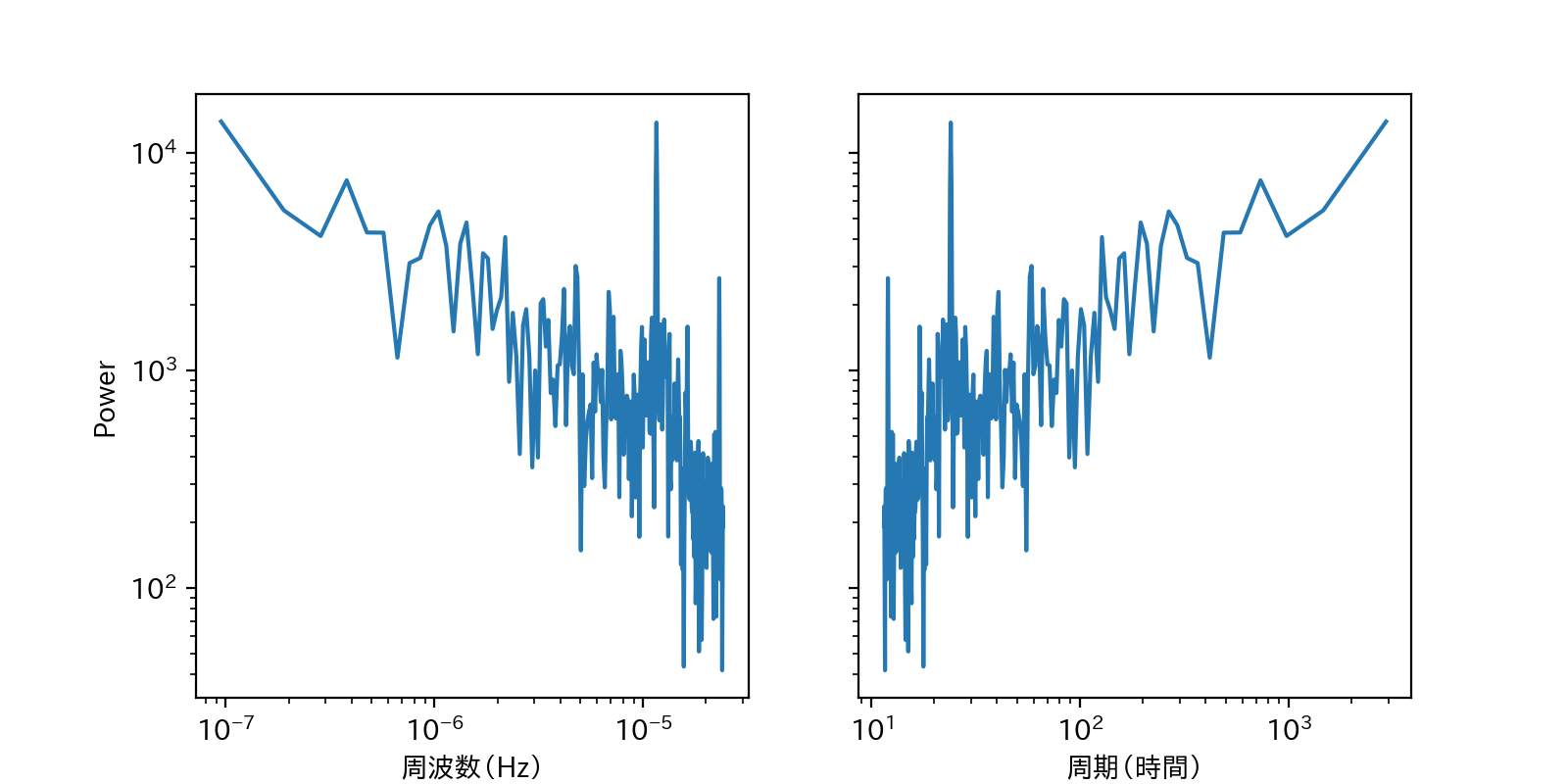
def plot(self, n_samples):
fig, axes = plt.subplots(figsize=(8, 4), ncols=2, sharey=True)
ax = axes[0]
ax.plot(self.freq[1:int(n_samples/2)], abs(self.z[1:int(n_samples/2)]))
ax.set_yscale('log')
ax.set_xscale('log')
ax.set_ylabel('Power')
ax.set_xlabel('周波数(Hz)')
ax = axes[1]
ax.plot((1 / self.freq[1:int(n_samples / 2)])/(60*60), abs(self.z[1:int(n_samples / 2)]))
ax.set_yscale('log')
ax.set_xscale('log')
ax.set_xlabel('周期(時間)')
plt.show()
def periodic_characteristics(self, n_samples):
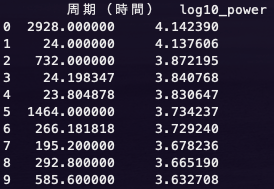
fft_pow_df = pd.DataFrame([(1 / self.freq[1:int(n_samples / 2)])/(60*60), np.log10(abs(self.z[1:int(n_samples / 2)]))], index=['周期(時間)', 'log10_power']).T
fft_pow_df = fft_pow_df.sort_values('log10_power', ascending=False).head(10).reset_index()
print(fft_pow_df.loc[:, ['周期(時間)', 'log10_power']])
if __name__ == '__main__':
fft = FFT()
fft.periodic_characteristics(512)
fft.plot(512)
一番パワースペクトルの大きい122日周期はいまいちピンとは来ないが、想定通り、23,24時間の周期も卓越していたのでおそらく合っているのかと。(朝から昼にかけて気温が上がり、夜にかけてまた下がるという日周期の物理特性を持っているため)
何か間違いなどあればご指摘いただけるとありがたいです。
以上!!!