今回の試み
・ 気象データAMeDASの10分ごとの値を一気に取得する
・ PythonとRubyの両方でスクレイピングしてみる
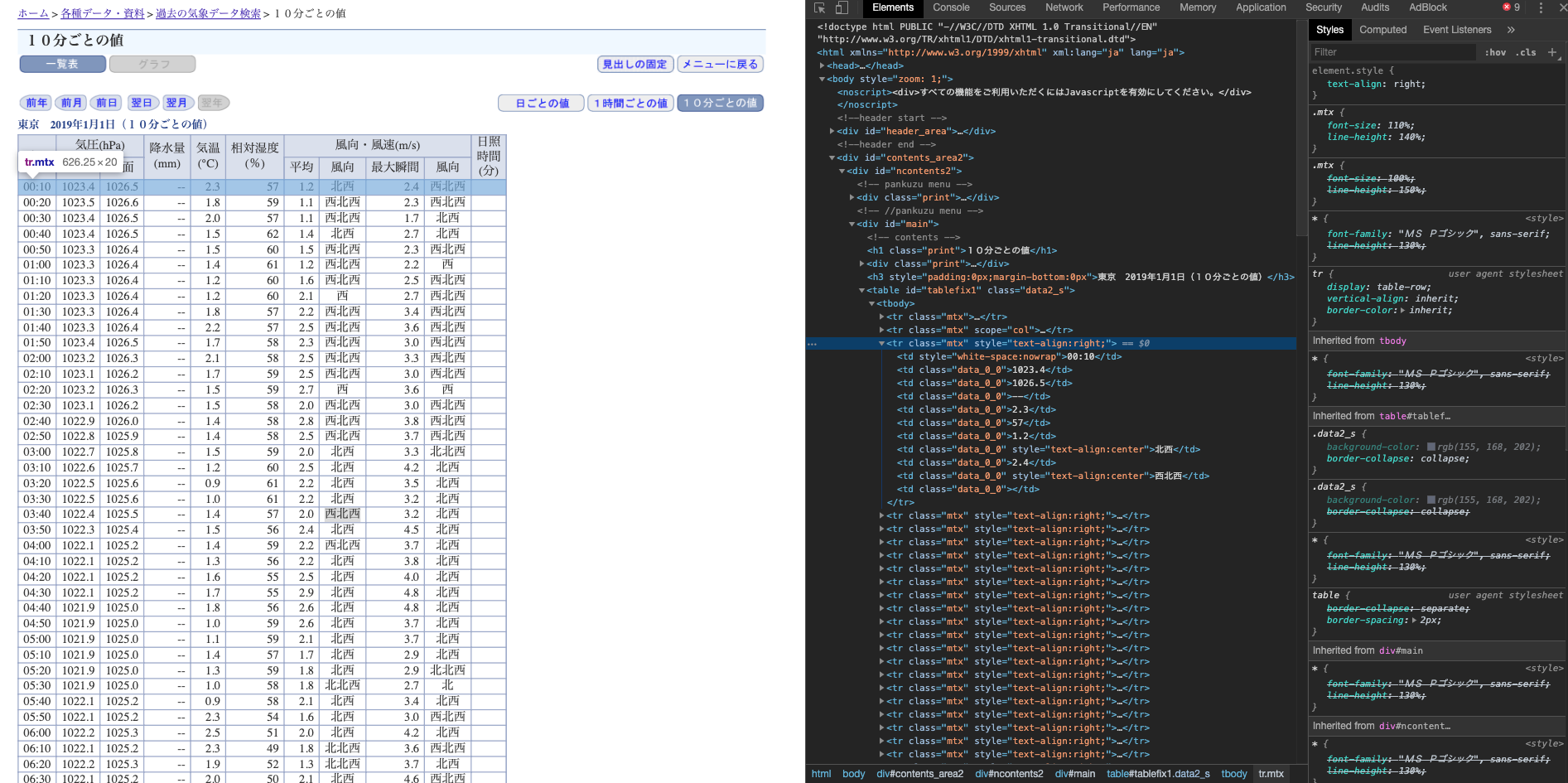
スクレイピングするデータはこちら
1. Pythonによるスクレイピング
# -*- coding: utf-8 -*-
import pandas as pd
import urllib.request
from bs4 import BeautifulSoup
url = 'https://www.data.jma.go.jp/obd/stats/etrn/view/10min_s1.php?prec_no=44&block_no=47662&year=2019&month=01&day=01&view=p1'
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
element = soup.find_all('tr', attrs={'class':'mtx', 'style':'text-align:right;'})
out = []
for ele in element:
data_list = []
for e in ele:
data_list.append(e.text)
out.append(data_list)
df = pd.DataFrame(data=out, columns=['時分','現地気圧','海面気圧','降水量','気温','相対湿度','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間'])
df.to_csv('tokyo_2019-01-01.csv', index=None,encoding='SJIS')
解説
# ① 指定したHTMLを解析するためのオブジェクト生成
soup = BeautifulSoup(html, 'html.parser')
# ② 条件を指定してtrタグを全て取得
element = soup.find_all('tr', attrs={'class':'mtx', 'style':'text-align:right;'})
あとはそこからテキストを抽出してリストに逐一追加していく
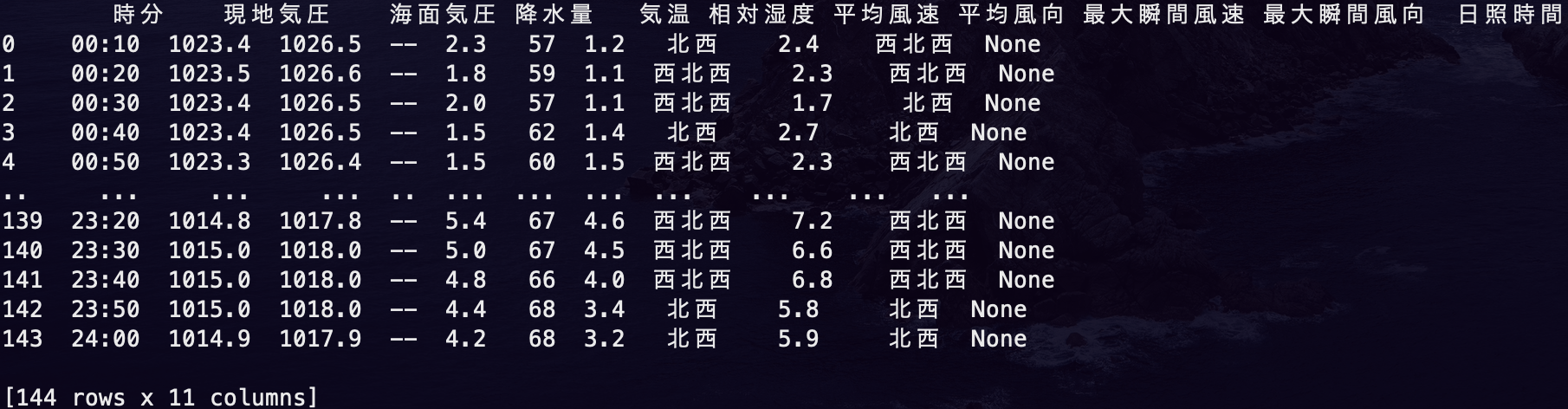
↓出力結果↓
2. Rubyによるスクレイピング
require 'csv'
require 'mechanize'
agent = Mechanize.new
url = 'https://www.data.jma.go.jp/obd/stats/etrn/view/10min_s1.php?prec_no=44&block_no=47662&year=2019&month=01&day=01&view=p1'
page = agent.get(url)
html = page.search('tr')
out = []
html.each do |element|
if element.get_attribute('style') == 'text-align:right;' then
data_list=[]
ele = element.search('td')
ele.each do |e|
data_list << e.inner_text
end
out << data_list
end
end
header = ['時分','現地気圧','海面気圧','降水量','気温','相対湿度','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間']
CSV.open('tokyo_2019-01-01.csv','w') do |csv|
csv << header
out.each do |val|
csv << val
end
end
解説
# ① Mechanizeクラスのインスタンスを生成し、指定したurlのHTMLを取得
agent = Mechanize.new
page = agent.get(url)
# ② searchメソッドでtrタグを検索後、styleタグがtext-align:rightであるとき、inner_textメソッドでテキスト取得
html = page.search('tr')
out = []
html.each do |element|
if element.get_attribute('style') == 'text-align:right;' then
data_list=[]
ele = element.search('td')
ele.each do |e|
data_list << e.inner_text
# 〜省略〜
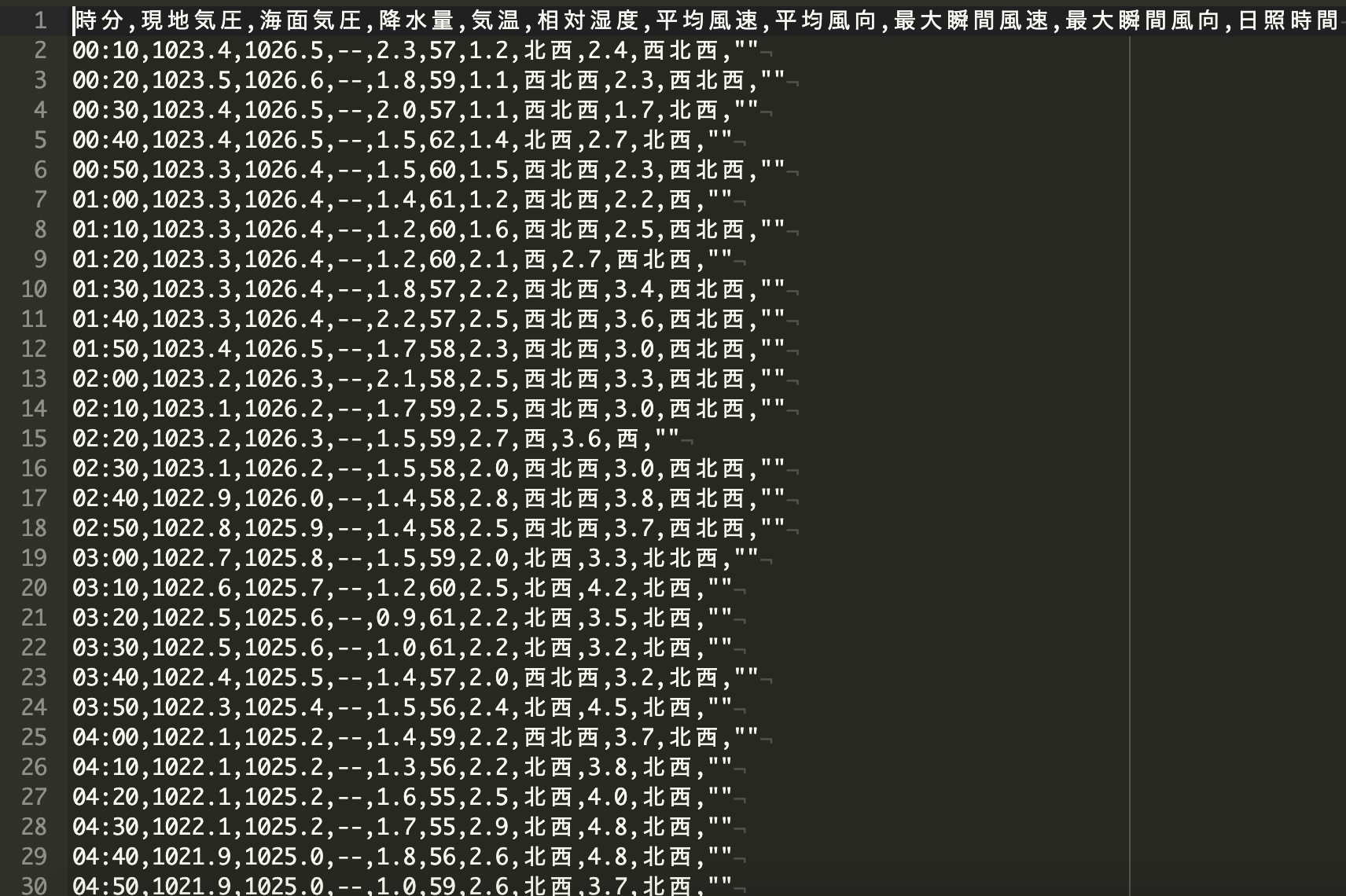
↓出力結果↓
意外とコード量的にはそこまで差はありませんでした。
Rubyで属性を指定してタグ検索することってできるんですかね。。。
以上!!!