Seleniumを使って、気象データダウンロードの半自動化を目指します。
※追記:下の記事で紹介しているやり方でより効率良くダウンロードできると思います。
気象×Python 〜天気データ取得からスペクトル解析まで〜
https://qiita.com/OSAKO/items/d25b8484d35ef4fe19e0
1. 経緯
▶任意の地点である一定期間の気象データ(気温・降水量など)が欲しい場合、気象庁のアメダス(AMeDAS:Automated Meteorological Data Acquisition System:自動気象データ収集システム)をよく利用している。
▶手軽にダウンロードできる反面、一度に取得できるデータ量には上限がある。
▶仮に長期間の1時間間隔のデータを取得しようとした場合、期間を区切りながら手動でダウンロードするのはめんどう。地点が増えればなおさらである。
⇒ある地点を選択してダウンロードして、また地点を変えてダウンロードして、、、この作業を全部自動化できないのか。
2. Seleniumによるブラウザ自動操作
2.1 Chromedriverの導入
Chromedriver導入に関しては、多くの参考記事があると思うのでここでは省略します。
https://sites.google.com/a/chromium.org/chromedriver/downloads
2.2 ダウンロードするアメダス地点の選定
①まず目的のダウンロードサイトから、地域を選択する操作をしなければならないので、各地域の場所情報をリスト化する。
今回は各地域のid属性値(id=pr××)を取得した(=計61地域)
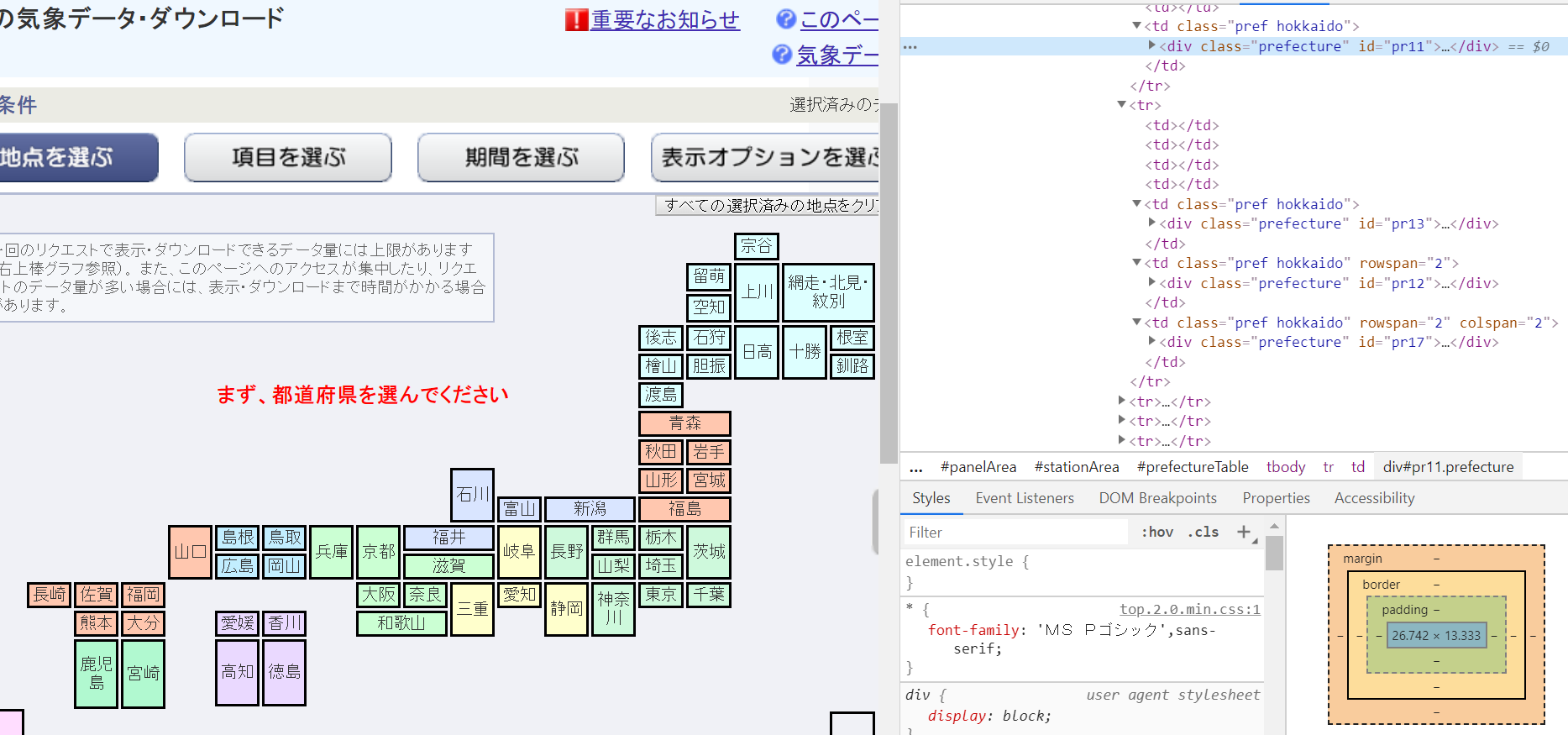
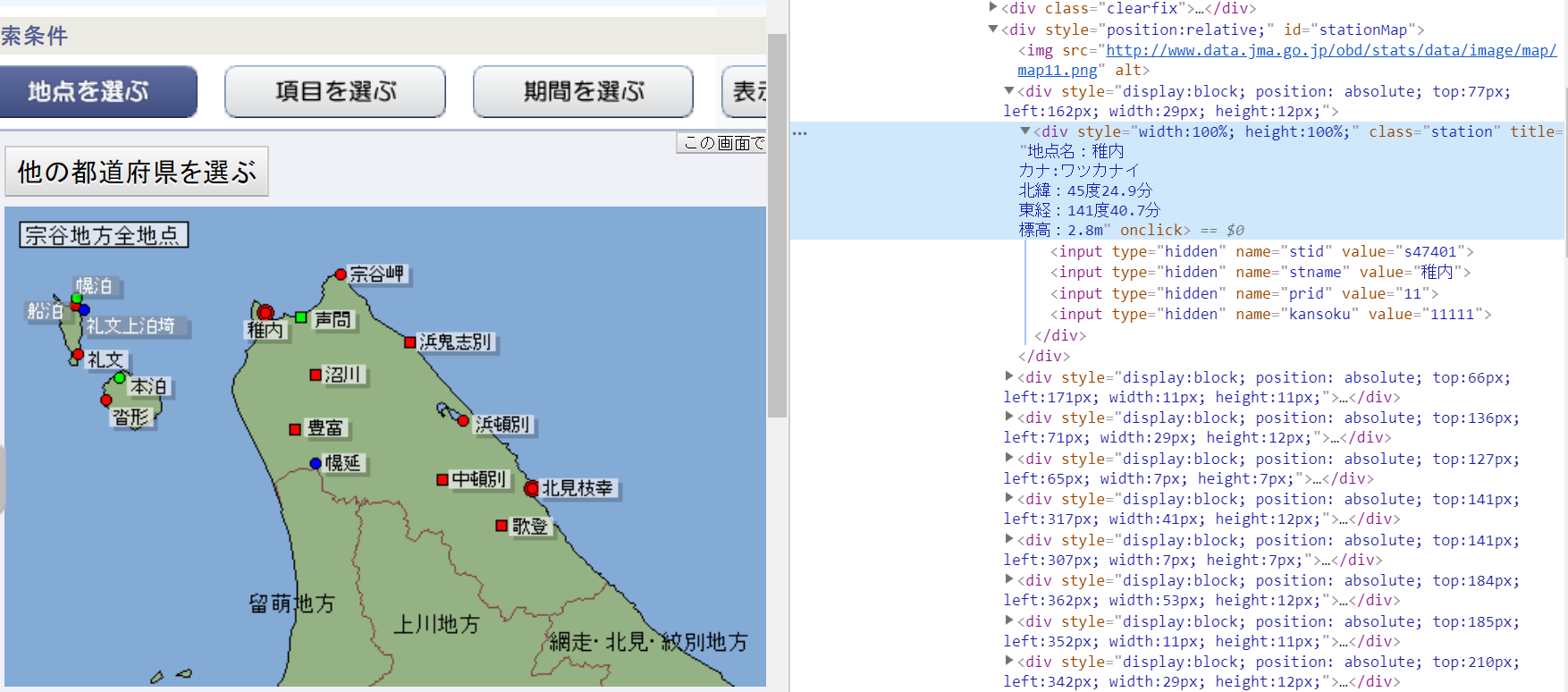
②各地域の観測地点を1地点ずつ選択するための情報をリスト化する。
今回はname="stname"のvalue="××"を取得した(=計1300地点)
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome('C:/selenium/chromedriver', options=options)
html = driver.get("https://www.data.jma.go.jp/gmd/risk/obsdl/index.php")
time.sleep(1)
# 各地域のid属性取得==========================================================
pr_list = []
prefecture = driver.find_elements_by_class_name("prefecture")
for pr in prefecture:
pr = pr.get_attribute("id")
pr_list.append(pr)
# ==========================================================================
# 各地域の観測地点名取得==========================================================
stname_list = []
for i in pr_list:
#順番に各地域へアクセス
driver.find_element_by_xpath('//*[@id="{}"]'.format(i)).click()
time.sleep(1)
#その地域の観測地点情報の取得
stations = driver.find_elements_by_xpath('//*[@class="station"]')
for station in stations:
station.click() #地点選択
time.sleep(1)
#地点名取得
stname = station.find_element_by_name("stname").get_attribute("value")
stname_list.append(stname)
#全部選択し終わったらその地域から離れ、別の地域へ
driver.find_element_by_css_selector("#buttonSelectStation").click()
time.sleep(1)
# ==============================================================================
各地域・地点情報のリストは以下の通り。稼働中の地点は1300ヶ所、この中から各自ダウンロードしたい地点を選定する。
※リスト化のプログラムは時間かかります。


2.3 AMeDASデータダウンロード
実際にデータをダウンロードするには物理量や期間などを選択する必要があります。
以下のプログラムでは2017年12月1日から2019年3月31日の冬季期間における時間降雪量を取得しています。
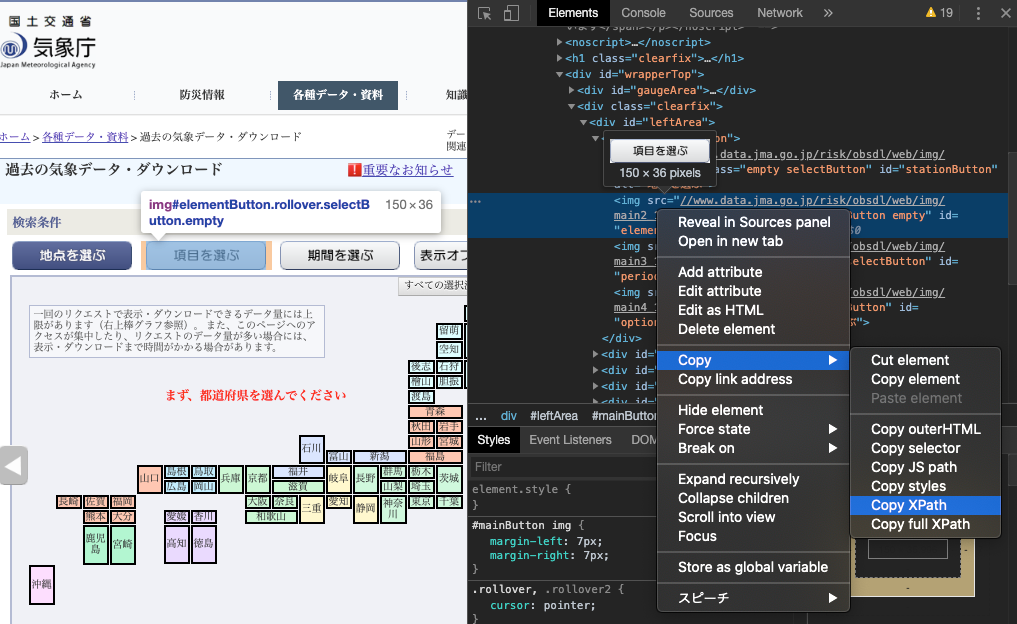
各要素をクリックするためのidやxpathを丁寧に指定してあげてください。
※ちなみにxpathはChromeの検証(デベロッパーツール)からクリックしたいタグ上で「Copy XPath」を選択すればオーケー
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
driver = webdriver.Chrome('C:/selenium/chromedriver')
html = driver.get("https://www.data.jma.go.jp/gmd/risk/obsdl/index.php")
time.sleep(1)
# ダウンロードするデータの詳細設定==============================================================================
# 項目を選ぶ
driver.find_element_by_id('elementButton').click()
time.sleep(1)
# 時間降雪量を選択
driver.find_element_by_xpath('//*[@id="aggrgPeriod"]/div/div[1]/div[1]/label/input').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="降雪の深さ"]').click()
time.sleep(1)
# 期間を選ぶ
driver.find_element_by_id('periodButton').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[1]/label/span').click()
time.sleep(1)
driver.find_element_by_xpath( '//*[@id="selectPeriod"]/div/div[2]/div[2]/div[2]/select[1]/option[3]').click() # 2017年
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[1]/option[12]').click() #12月
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[2]/option[1]').click() #1日
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[2]/select[2]/option[1]').click() #2018年
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[3]/option[3]').click() #3月
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[4]/option[31]').click() #31日
time.sleep(1)
# 表示オプションを選ぶ
driver.find_element_by_id('optionButton').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectOp"]/div[1]/div/div[2]/p/label/input').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectOp"]/div[2]/div/div[2]/p/label/input').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="selectOp"]/div[3]/p[3]/label/input').click()
time.sleep(1)
driver.find_element_by_xpath('// *[@id="selectOp"]/div[4]/div/div[2]/label/input').click()
time.sleep(1)
# ==================================================================================================
# 地点を選ぶ
driver.find_element_by_id('stationButton').click()
time.sleep(1)
# 今回は試しに以下のリストに示した観測地点のデータをダウンロードする
select_list = ['稚内', '北見枝幸', '歌登', '中頓別', '豊富', '沼川', '浜鬼志別']
for i in pr_list:
driver.find_element_by_xpath('//*[@id="{}"]'.format(i)).click()
time.sleep(1)
stations = driver.find_elements_by_xpath('//*[@class="station"]')
time.sleep(1)
for station in stations:
station.click()
time.sleep(1)
stname = station.find_element_by_name("stname").get_attribute("value")
#選択中の地点がselect_listになければ、その地点をスキップする
if not stname in select_list:
print(stname + " skip")
else:
driver.find_element_by_xpath('//*[@id="csvdl"]/img').click()
time.sleep(5) #ダウンロードには多少時間がかかる
print(stname + " DL")
#選択した地点を解除する
driver.find_element_by_id("deleteAllStPref").click()
time.sleep(1)
driver.find_element_by_css_selector("#buttonSelectStation").click()
time.sleep(1)
$ python get_amedas.py
稚内 DL
沓形 skip
浜頓別 skip
北見枝幸 DL
歌登 DL
中頓別 skip
豊富 DL
沼川 DL
宗谷岬 skip
浜鬼志別 DL
本泊 skip
:
:
上記プログラムを実行すると、ダウンロードフォルダなどに保存されます。
あとは、ループしつつも、同時にデータ整形して別フォルダに保存し、元のファイルは削除しておくようなプログラムを組み込むといいと思います。
ではでは。