はじめに
UnityからGoogle Cloud Speech-to-Textを使用する方法をメモします。
OculusQuestでも問題なく動作しました。
Google Cloud Speech-to-Text
Googleの提供する音声認識APIです。
下記リンクより登録に進みAPIキーを取得します。
【参考リンク】:Speech-to-Text
登録後、下記ダッシュボードの画面からAPIキーを取得可能です。
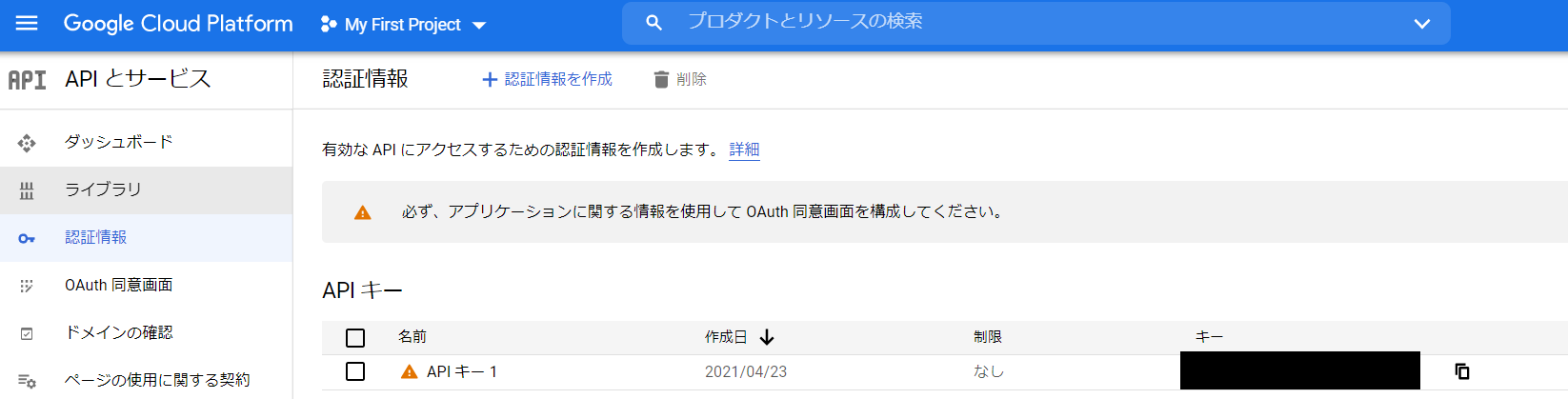
料金は従量課金制ですが、1月当り60分までは無料で使えるようです。(精度の検証でしゃべりまくってたら42円請求されてしまいました。)
こちらのAPIを使うには少し複雑で、ただ、APIをUnityから叩けばよいという訳ではありません。
かといっていろいろと面倒なことを自前で実装するのも億劫なので、
今回はアセットを使いました。
下記のページでも紹介されている、Google Cloud Speech Recognitionを使用しました。
【参考リンク】:【Unity】自分の声をテキスト化する方法【Google Cloud Speech Recognition 】
バージョン
念のため使ったライブラリ等のバージョンも書いときます。
Unity 2019.4.8f1
UniTask.2.2.4
UniRx 7.1.0
Google Cloud Speech Recognition 4.1.2
準備
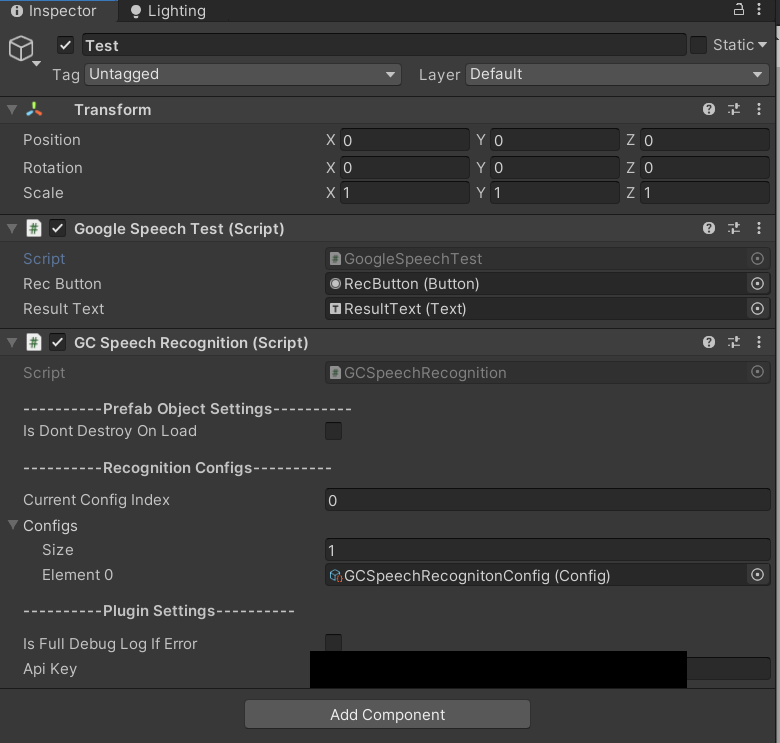
アセットをプロジェクトにインポートしたら任意のシーンのヒエラルキーに
適当なオブジェクトを作って下記のように設定します。APIキーは先ほど取得したものです。
GoogleSpeechTestは後述のサンプルコードです。
コード
Unityから使用するサンプルです。
using FrostweepGames.Plugins.GoogleCloud.SpeechRecognition;
using UniRx;
using UniRx.Triggers;
using UnityEngine;
using UnityEngine.UI;
/// <summary>
/// Google音声認識テスト
/// </summary>
public class GoogleSpeechTest : MonoBehaviour
{
[SerializeField] private Button recButton;
[SerializeField] Text resultText;
private GCSpeechRecognition _speechRecognition;
void Start()
{
_speechRecognition = GCSpeechRecognition.Instance;
_speechRecognition.FinishedRecordEvent += OnFinishedRecordEvent;
_speechRecognition.RecognizeSuccessEvent += OnRecognizeSuccessEvent;
if (_speechRecognition.HasConnectedMicrophoneDevices())
{
_speechRecognition.SetMicrophoneDevice(_speechRecognition.GetMicrophoneDevices()[0]);
}
recButton.OnPointerDownAsObservable()
.Subscribe(_ => _speechRecognition.StartRecord(false)).AddTo(this);
recButton.OnPointerUpAsObservable()
.Subscribe(_ => _speechRecognition.StopRecord()).AddTo(this);
}
private void OnDestroy()
{
_speechRecognition.FinishedRecordEvent -= OnFinishedRecordEvent;
_speechRecognition.RecognizeSuccessEvent -= OnRecognizeSuccessEvent;
}
/// <summary>
/// 音声認識成功時のコールバックイベント
/// </summary>
/// <param name="recognitionResponse">認識結果のレスポンス</param>
private void OnRecognizeSuccessEvent(RecognitionResponse recognitionResponse)
{
string r = "";
foreach (var result in recognitionResponse.results)
{
foreach (var alternative in result.alternatives)
{
if (recognitionResponse.results[0].alternatives[0] != alternative)
{
r = alternative.transcript;
}
}
}
resultText.text = r;
}
/// <summary>
/// 録音終了時のコールバックイベント
/// </summary>
/// <param name="clip">音声クリップ</param>
/// <param name="raw">生データ</param>
private void OnFinishedRecordEvent(AudioClip clip, float[] raw)
{
if (clip == null) return;
RecognitionConfig config = RecognitionConfig.GetDefault();
config.languageCode = Enumerators.LanguageCode.ja_JP.Parse();
config.audioChannelCount = clip.channels;
GeneralRecognitionRequest recognitionRequest = new GeneralRecognitionRequest()
{
audio = new RecognitionAudioContent()
{
content = raw.ToBase64()
},
config = config
};
_speechRecognition.Recognize(recognitionRequest);
}
}
デモ
下記のように動作します。若干レスポンスが遅いです。送信するAudioデータの容量に比例して遅くなる?ようです。
— KENTO⚽️XRエンジニア😎Shader100記事マラソン挑戦中30/100 (@okprogramming) April 24, 2021
おわりに
音声データをストリームしながらリアルタイムでしゃべった言葉を認識するような形式を取れば
サクサク動くのかもしれません。
何やら複雑なことをやってそれを成し遂げている海外の方がいらっしゃいました。(料金ヤバそう)
【参考リンク】:Streaming recognition
【参考リンク】:[Announce] Google Cloud Streaming Speech Recognition [VR\AR\Desktop]