はじめに
前編のおさらいと後編の位置づけ
前編では、RAGの基礎からAzure AI SearchのHybrid Search、そしてAgentic RAGにおけるクエリプランニングまでを見てきました。検索技術の進化によって、より正確な情報検索が可能になってきていることを学びました。
後編となるこの記事では、セッションの後半で紹介された「Knowledge Bases」という新しいアプローチに焦点を当てます。従来のRAG実装では、データの取り込み、インデックス作成、検索ロジック、結果の統合など、多くのコードを自分で書く必要がありました。Knowledge Basesは、これらの複雑さを大幅に軽減し、より宣言的な方法でエージェントに知識を提供できる仕組みです。
Youtube視聴での気づき
セッションの 25:00頃 から始まるKnowledge Basesのデモ部分を繰り返し視聴しました。特に印象的だったのは、従来300行以上必要だったコードが、Knowledge Basesを使うことで大幅に削減される様子です。デモを一時停止しながら、UIの操作手順やコード例を確認できたのは、Youtube視聴ならではのメリットでした。
この記事で学べること
- 従来の手動RAG実装の課題と限界
- Knowledge Basesのアーキテクチャと設計思想
- 多様なデータソースへの対応方法
- Foundry IQとMCP(Model Context Protocol)によるエージェント統合
- 実際の導入を考えた際の考慮点
従来のRAG実装の課題
コードの複雑さと保守の難しさ
セッションでは、講師のMattさんが率直に「従来のRAG実装は非常に複雑だった」と語っていました。
典型的なRAGアプリケーションを構築するには、以下のような多くのステップが必要でした:
- データの取り込み: さまざまなソースからデータを読み取る
- 文書の分割(チャンキング): 適切なサイズに文書を分割
- 埋め込みの生成: Vector Searchのためのベクトル化
- インデックスの作成と管理: 検索インデックスの構築
- 検索ロジックの実装: クエリの実行と結果の取得
- 結果の統合: 複数の検索結果をマージ
- LLMへのプロンプト作成: 適切なコンテキストと質問の組み立て
セッションでは、GitHubリポジトリの例が示されていました。1つのRAGアプリケーションを構築するために:
- 300行以上のPythonコードが必要
- 複数のAzureリソースを手動で設定
- カスタムのデータパイプラインを構築
- 各データソースごとに異なる統合コードを記述
この複雑さは、以下のような問題を引き起こします:
保守性の課題:
- データソースが増えるたびにコードを追加
- 検索ロジックの変更が全体に波及
- チーム内でのナレッジ共有が困難
スケーラビリティの課題:
- 新しいユースケースごとにコードをコピー&修正
- 同じようなロジックが複数の場所に分散
- パフォーマンスチューニングが個別に必要
社内でRAG実装を検討したときも、同じような課題に直面しました。SharePoint、社内Wiki、Dynamics 365のデータなど、複数のデータソースを統合しようとすると、それぞれのAPIやデータ構造に対応するコードが必要になり、コードベースがどんどん複雑化していくんですよね。
データソース統合の難しさ
もう一つの大きな課題は、異なるデータソースを統合する際の困難さです。
SharePoint: Microsoft Graph APIを使用し、認証とアクセス許可を管理
SQL Database: JDBCまたはODBCで接続し、適切なクエリを構築
Cosmos DB: NoSQLの特性に合わせたクエリロジック
外部Web: スクレイピングとコンテンツ抽出
それぞれのデータソースには:
- 独自の認証メカニズム
- 異なるデータ形式
- 固有のアクセスパターン
- 独立した更新サイクル
これらを統一的に扱うためには、かなりの抽象化レイヤーが必要になります。また、データソースごとにアクセス権限やセキュリティポリシーが異なる場合、その管理も複雑化します。
企業環境を考えると、この課題はさらに深刻です。部門ごとに異なるシステムを使っていたり、レガシーシステムとモダンなシステムが混在していたりすることが多く、統合の難易度は高くなります。
Knowledge Basesの登場
設計思想と解決するもの
Knowledge Basesは、これらの課題を解決するために設計された新しいアプローチです(28:20頃)。
基本的な考え方:
- データの取り込みと管理を自動化
- 宣言的な設定でデータソースを定義
- 統一されたインターフェースで検索を実行
- エージェントとのシームレスな統合
セッションで強調されていたのは、「Knowledge BasesはAzure AI Searchの上に構築されている」という点です。つまり、前編で学んだHybrid SearchやSemantic Rankerといった強力な検索機能は、そのままKnowledge Basesでも利用できるということですね。
Knowledge Basesの構成要素
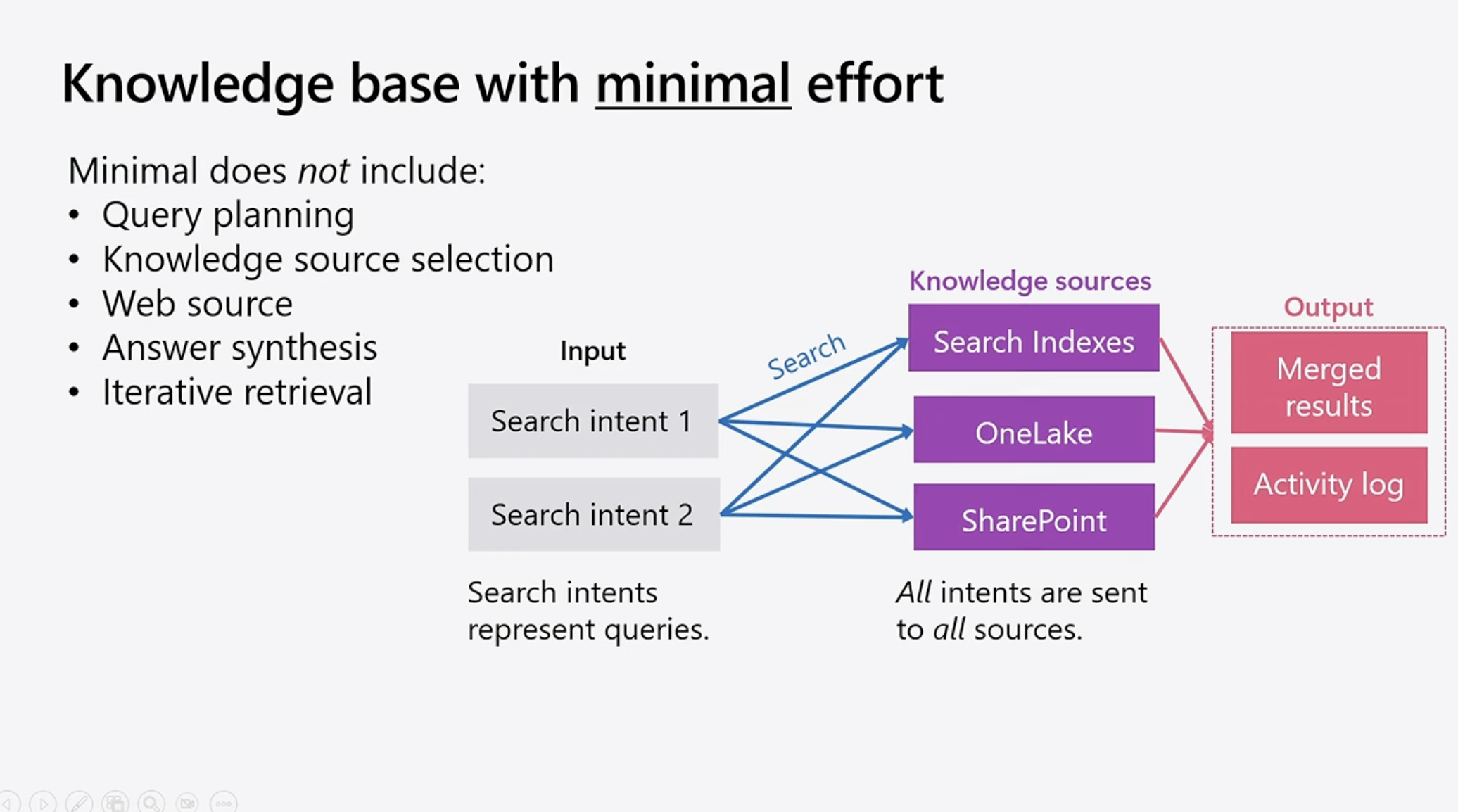
Knowledge Basesは、以下の3つの主要な要素で構成されています:
1. Data Sources(データソース)
- どこからデータを取得するか
- ローカルファイル、SharePoint、Web、データベースなど
2. Index(インデックス)
- データをどのように格納し、検索可能にするか
- Azure AI Searchのインデックスとして管理
3. Retrieval Configuration(検索設定)
- どのように検索を実行するか
- Hybrid Search、フィルター、再ランキングなどの設定
これらを組み合わせることで、1つの「Knowledge Base」として統一的に扱えるようになります。
データソースの多様性
Index Knowledge Sourcesとは
Knowledge Basesでは、2種類のデータソースタイプがサポートされています。1つ目は「Index Knowledge Sources」です。
Index Knowledge Sourcesの特徴:
- データをAzure AI Searchのインデックスに取り込む
- インデクサーとスキルセットを自動的に作成
- データの変更を定期的に同期
サポートされているソース:
- Azure Blob Storage: PDF、Word、Excel、画像など
- Azure Data Lake Storage: 大規模なデータセット
- ローカルファイル: 開発時のテストデータ
セッションのデモでは、Blob Storageに配置されたZavaの製品カタログ(PDF形式)を、UIから数クリックでKnowledge Baseに追加する様子が示されていました。
デモで印象的だったポイント:
- コンテナやフォルダを選択するだけでデータが取り込まれる
- チャンキング、埋め込み生成、インデックス作成が自動化
- 数分後には検索可能な状態になる
これは開発者体験として非常に優れていると感じました。以前、社内でPDFからテキストを抽出してインデックス化するツールを作ったときは、PyPDFやその他のライブラリと格闘する必要がありましたが、Knowledge Basesではそういった低レベルの処理を意識する必要がないんですね。
Remote Knowledge Sourcesの可能性
2つ目のデータソースタイプは「Remote Knowledge Sources」です。これは、データをインデックスに取り込まず、検索時に直接外部ソースにクエリを実行する方式です。
Remote Knowledge Sourcesの特徴:
- データは元のシステムに残る
- リアルタイムで最新データにアクセス
- ストレージコストの削減
サポートされているソース:
- SharePoint: ドキュメントライブラリやページ
- Web検索(Bing): インターネット上の公開情報
- Azure SQL Database: リレーショナルデータ
- Cosmos DB: NoSQLデータ
セッションでは、SharePointを例にRemote Knowledge Sourceの設定が紹介されていました。
設定のポイント:
- SharePointのサイトURLを指定
- OAuth認証を設定
- フィルター条件を指定(特定のサイトやドキュメントライブラリに限定)
質疑応答の時間で、SharePointのフィルタリングについて質問が出ていました。講師の回答によると、サイトIDやドキュメントライブラリなど、かなり細かいレベルでフィルタリングが可能とのことです。
この機能は、企業での導入を考える際に重要だと思います。全社のSharePointデータを取り込むのではなく、特定の部門やプロジェクトに関連するデータだけを対象にできることで、セキュリティとパフォーマンスの両面でメリットがありそうです。
複数のデータソースを統合する
Knowledge Basesの強力な点は、複数のデータソースを1つのKnowledge Baseとして統合できることです。
統合の例:
- 製品情報: Blob StorageのPDFカタログ(Index)
- 顧客FAQ: SharePointのナレッジベース(Remote)
- 在庫データ: Azure SQL Database(Remote)
- 競合情報: Web検索(Remote)
これらを組み合わせることで、「製品Xの在庫はある?お客様からよくある質問は?競合製品との違いは?」といった複合的な質問に対応できるエージェントを構築できます。
従来であれば、これらのデータソースごとに個別の検索ロジックを実装し、結果を手動でマージする必要がありました。Knowledge Basesでは、それらが統一的なインターフェースで扱えるため、エージェント側のコードがシンプルになります。
社内システムに当てはめて考えると、以下のような統合が考えられます:
- 営業資料: SharePointの提案書テンプレート
- 顧客データ: Dynamics 365のアカウント情報
- 製品仕様: Blob Storageの技術ドキュメント
- 最新ニュース: Web検索による業界動向
このような多様なデータを横断的に検索できることで、営業担当者をサポートするエージェントが実現できそうです。
Foundry IQとMCP統合
Foundryエコシステムでのエージェント開発
セッションの後半では、Azure AI FoundryとKnowledge Basesの統合について説明されていました。
Azure AI Foundryは、エージェント開発のための統合プラットフォームで、以下の要素を一元管理できます:
- Tools(ツール): エージェントが使える機能
- Knowledge(知識): Knowledge Basesによるデータアクセス
- Evaluations(評価): エージェントの品質測定
- Deployments(デプロイ): 本番環境への展開
[画像挿入: Foundryの統合エージェントビルダー画面]
「Foundry IQ」という名称は、Foundryエコシステム全体でKnowledge Basesを活用する仕組みを指しています。
MCP(Model Context Protocol)による連携
Knowledge BasesとFoundryエージェントを繋ぐ技術として、MCP(Model Context Protocol)が使われています。
MCPとは:
- エージェントが外部サービスを利用するための標準プロトコル
- Anthropicが提唱し、業界で採用が広がっている
- ツールやデータソースを統一的なインターフェースで扱える
MCPでのKnowledge Base連携:
- エージェントがクエリプランを作成
- MCPを通じてKnowledge Baseに問い合わせ
- 複数のサブクエリを並列実行
- 結果をマージして回答を生成
セッションのデモでは、Foundryのエージェントプレイグラウンドで、前編と同じ「浴室の壁に最適な塗料は?」という質問をする様子が示されていました(39:25頃)。
デモのポイント:
- エージェントがMCP経由でKnowledge Baseにアクセス
- 「knowledge base retrieval tool」という名前のツールを使用
- 前編で見たアプリケーションと同じ回答が得られる
この統合により、既存のKnowledge Basesをエージェントから簡単に利用できるようになります。「Lift and shift」という表現が使われていましたが、既存のナレッジベースをそのままエージェントに組み込めるイメージですね。
MCPの採用は、長期的な視点で見ると重要だと感じました。特定のベンダーやプラットフォームに依存しない標準プロトコルを使うことで、将来的な拡張性や他システムとの統合が容易になりそうです。
実装の実際とベストプラクティス
Knowledge Basesの構築手順
セッションで示されたKnowledge Base構築の基本的な流れは以下の通りです([32:00-35:00頃]:
Step 1: Knowledge Baseの作成
- Azure AI Foundryポータルで新規作成
- 名前と説明を設定
Step 2: データソースの追加
- Index SourceまたはRemote Sourceを選択
- 接続情報と認証を設定
- フィルター条件を指定(必要に応じて)
Step 3: インデックス設定の調整
- チャンキング戦略(デフォルトまたはカスタム)
- 埋め込みモデルの選択
- 検索フィールドの定義
Step 4: 検索設定の構成
- Hybrid Searchの有効化
- Semantic Rankerの使用
- フィルターやファセットの設定
Step 5: テストとデプロイ
- テストクエリで動作確認
- アプリケーションやエージェントに統合
[画像挿入: Knowledge Base構築のステップバイステップ図]
実際の開発では、Step 3のインデックス設定が重要になると思います。質疑応答でも、チャンキング戦略についての質問が出ていました。
チャンキング戦略のオプション:
- デフォルト: Azure AI Searchの標準設定を使用
- カスタムスキルセット: Split Skillでサイズや重複を調整
- 完全カスタム: 独自のチャンキングロジックを実装
日本語の文書では、文の区切りや意味のまとまりが英語と異なるため、カスタムチャンキングが有効な場合があります。例えば、技術文書では見出しや箇条書きの構造を保持するようなチャンキングが望ましいこともありますね。
セキュリティとガバナンスの考慮
企業でKnowledge Basesを導入する際、セキュリティとガバナンスは最重要課題です。セッションでは直接的な言及は少なかったですが、Remote Knowledge Sourcesの説明の中で関連する内容がありました。
アクセス制御のポイント:
- データソースレベル: SharePointやSQL Databaseのアクセス許可を継承
- Knowledge Baseレベル: 誰がKnowledge Baseを利用できるか
- エージェントレベル: どのエージェントがどのKnowledge Baseにアクセスできるか
特に重要なのは:
- Remote Sourceの場合、元のシステムのアクセス権限が適用される
- Index Sourceの場合、データをインデックスに取り込む時点で権限を考慮する必要がある
社内での導入を考えると、部門ごとや役職ごとに異なるKnowledge Baseを用意することも検討すべきかもしれません。例えば:
- 全社共通: 製品情報、社内規程
- 営業部門: 顧客情報、提案書テンプレート
- 開発部門: 技術ドキュメント、APIリファレンス
パフォーマンスとコストの最適化
Knowledge Basesを本番環境で運用する際、パフォーマンスとコストのバランスも重要です。
パフォーマンスの考慮点:
- Remote Sourceは検索時にリアルタイムクエリが発生するため、レスポンスタイムが長くなる可能性
- Index Sourceは高速だが、データの同期に時間がかかる
- 用途に応じて使い分けることが重要
コストの考慮点:
- Index Sourceはストレージコストが発生
- Semantic Rankerは検索ごとにコストが発生
- Remote Sourceは元システムのAPIコストを考慮
実際の運用では、以下のような戦略が考えられます:
- 頻繁にアクセスされるデータ: Index Sourceで高速化
- リアルタイム性が重要なデータ: Remote Sourceで常に最新
- 大量のデータ: フィルターを活用してスコープを限定
既存システムからの移行戦略
段階的な移行アプローチ
既にRAGシステムを運用している場合、Knowledge Basesへの移行は段階的に行うのが現実的だと思います。
Phase 1: 並行運用
- 既存のRAGシステムはそのまま維持
- 新しいユースケースでKnowledge Basesを試験的に導入
- パフォーマンスと品質を比較評価
Phase 2: 部分的な置き換え
- 保守が難しいデータソースからKnowledge Basesに移行
- エージェントは両方のシステムを併用
- ユーザーフィードバックを収集
Phase 3: 完全移行
- 全てのデータソースをKnowledge Basesに統合
- 既存のRAGコードを削除
- 運用保守の簡素化
この段階的なアプローチにより、リスクを最小化しながら移行できます。特に、既存システムの動作を基準として、Knowledge Basesの品質を評価できる点が重要です。
既存コードの活用
セッションの質疑応答で、カスタムスキルセットについての言及がありました。既存のチャンキングロジックや前処理コードは、カスタムスキルとしてKnowledge Basesに組み込むことができます。
これは、既存の投資を無駄にせずに新しいシステムに移行できることを意味します。例えば:
- 独自のPDF解析ロジック
- 業界特有の用語抽出
- メタデータの補完処理
これらをAzure Functionsなどで実装し、カスタムスキルとして登録することで、Knowledge Basesの機能を拡張できます。
実際の導入を考えてみて
企業での活用シナリオ
Knowledge Basesの技術を見て、いくつかの具体的な活用シナリオが思い浮かびました。
シナリオ1: カスタマーサポートエージェント
-
Knowledge Sources:
- 製品マニュアル(Blob Storage / Index)
- FAQ(SharePoint / Remote)
- 過去の問い合わせ履歴(SQL Database / Remote)
- 最新の不具合情報(Web検索 / Remote)
- 期待効果: サポート担当者の回答時間短縮、品質の均一化
シナリオ2: 営業支援エージェント
-
Knowledge Sources:
- 提案書テンプレート(SharePoint / Remote)
- 顧客情報(Dynamics 365 / Remote)
- 競合分析資料(Blob Storage / Index)
- 業界ニュース(Web検索 / Remote)
- 期待効果: 提案書作成の効率化、最新情報の活用
シナリオ3: 社内ヘルプデスクエージェント
-
Knowledge Sources:
- 社内規程(SharePoint / Remote)
- 手続きマニュアル(Blob Storage / Index)
- システム操作ガイド(SharePoint / Remote)
- IT部門のナレッジベース(Confluence / Index)
- 期待効果: 従業員の自己解決率向上、ヘルプデスク負荷軽減
これらのシナリオに共通するのは、複数の異質なデータソースを統合する必要があるという点です。Knowledge Basesを使うことで、この統合を宣言的に行え、保守性が大幅に向上しそうです。
導入時の課題と対策
もちろん、実際の導入では課題も予想されます。
課題1: データ品質のばらつき
- 各データソースでフォーマットや品質が異なる
- 古い情報と新しい情報が混在
- 対策: データガバナンスの確立、定期的なクリーンアップ
課題2: 組織的な抵抗
- 新しいツールへの学習コスト
- 既存のワークフローの変更
- 対策: パイロットプロジェクトでの成功事例、段階的な導入
課題3: コスト管理
- 複数のAzureリソースのコスト
- Semantic Rankerなどオプション機能の費用
- 対策: 使用パターンの監視、適切なティアの選択
課題4: 日本語対応の品質
- 埋め込みモデルの日本語精度
- チャンキングの最適化
- 対策: カスタムモデルの検討、日本語特化のチャンキング戦略
特に日本語対応については、実際に試してみないと分からない部分が多いと思います。Azure OpenAIの埋め込みモデルは日本語もサポートしていますが、専門用語や業界特有の表現にどこまで対応できるかは、検証が必要そうです。
次のステップ
このセッションを視聴して、Knowledge Basesは非常に有望な技術だと感じました。実際に試してみたいアクションとしては:
-
小規模なPOCの実施
- 社内の限定されたデータセットでKnowledge Baseを構築
- シンプルなエージェントを実装して動作確認
- 既存のRAG実装と品質を比較
-
MCPプライベートプレビューへの参加
- セッションで案内されていたプライベートプレビューに登録
- 最新機能を試しながらフィードバックを提供
-
社内での知識共有
- このセッションの内容を社内勉強会で共有
- RAG実装を検討しているチームへの情報提供
- エージェント開発のベストプラクティスをドキュメント化
まとめ
学んだポイント
このセッションの後編から、以下の重要なポイントを学びました:
- Knowledge Basesの価値: 従来300行以上必要だったコードを大幅に削減し、宣言的にデータソースを管理できる
- データソースの柔軟性: Index SourceとRemote Sourceを使い分けることで、様々なユースケースに対応
- エージェントとの統合: MCPによるFoundry統合で、エージェント開発がよりシンプルに
- 段階的な移行戦略: 既存システムから無理なく移行できる道筋がある
前編と後編を通して
前編で学んだAzure AI Searchの強力な検索機能と、後編で学んだKnowledge Basesの統合管理機能を組み合わせることで、非常に強力なエージェントシステムが構築できることが分かりました。
特に印象的だったのは:
- 技術の複雑さを抽象化し、開発者体験を向上させる設計
- 既存の投資(カスタムコード、データインフラ)を活かせる拡張性
- エンタープライズでの実用を見据えたセキュリティとガバナンス
最後に
Microsoft Ignite 2025では、エージェントと知識管理が大きなテーマでした。このセッションで紹介されたKnowledge Basesは、その中核となる技術の一つだと感じます。
Youtube視聴だからこそ、デモの細部まで繰り返し確認でき、理解を深めることができました。現地参加も素晴らしい体験ですが、こうして後からじっくり学べるのも、オンラインセッションの大きなメリットですね。
今後、実際にKnowledge Basesを使ったエージェント開発に挑戦し、その経験をまた記事として共有できればと思います。