はじめに
このセッションを視聴した背景
Microsoft Ignite 2025で「Build agents with knowledge: agentic RAG and Azure AI Search (BRK193)」というセッションを視聴しました。現地では別のセッションに参加していたため、このセッションはYoutubeでの視聴となりましたが、繰り返し視聴できるメリットを活かして、特に検索技術の部分を重点的に学ぶことができました。

社内でRAGを使ったアプリケーションを検討する機会が増えている中で、「検索精度をどう高めるか」という課題に直面していました。単純なVector Searchだけでは不十分なケースがあり、かといってKeyword Searchだけでも限界がある。このセッションでは、Azure AI Searchがどのようにこの課題を解決しているのか、そしてエージェント時代における検索戦略について詳しく解説されていました。
Youtube視聴での気づき
デモの部分を一時停止しながら、実際のコードやクエリの動きを確認できたのが非常に有益でした。特に 14:30頃 のHybrid Searchのデモでは、検索結果のスコアリングの変化を詳しく見ることができ、Reciprocal Rank FusionとSemantic Rankerの効果を実感できました。
この記事で学べること
- RAGの基本的な仕組みと実装パターン
- Keyword SearchとVector Searchの特徴と使い分け
- Azure AI SearchのHybrid Searchによる精度向上
- Agentic RAGにおけるクエリプランニングの重要性
- Query Rewrite機能による複雑なクエリの処理
この記事は前編として、主に検索技術とAgentic RAGの実装戦略にフォーカスしています。後編では、Knowledge BasesとFoundry統合について詳しく扱う予定です。
RAGの基本とその課題
RAGとは何か
RAG(Retrieval Augmented Generation)は、LLMが組織固有のデータを活用するための基本的な技術です。セッションでは、講師のPamelaさんが会場に「RAGを使っている人?」と質問したところ、かなり多くの手が挙がっていました(00:53頃)。それだけRAGは既に一般的な技術になっているということですね。
基本的な流れは以下の通りです:
- ユーザーからの質問を受け取る
- その質問を使って検索インデックスを検索
- 検索結果をLLMに渡す
- LLMが検索結果に基づいて回答を生成し、引用を提供
[RAGの基本的なフロー図]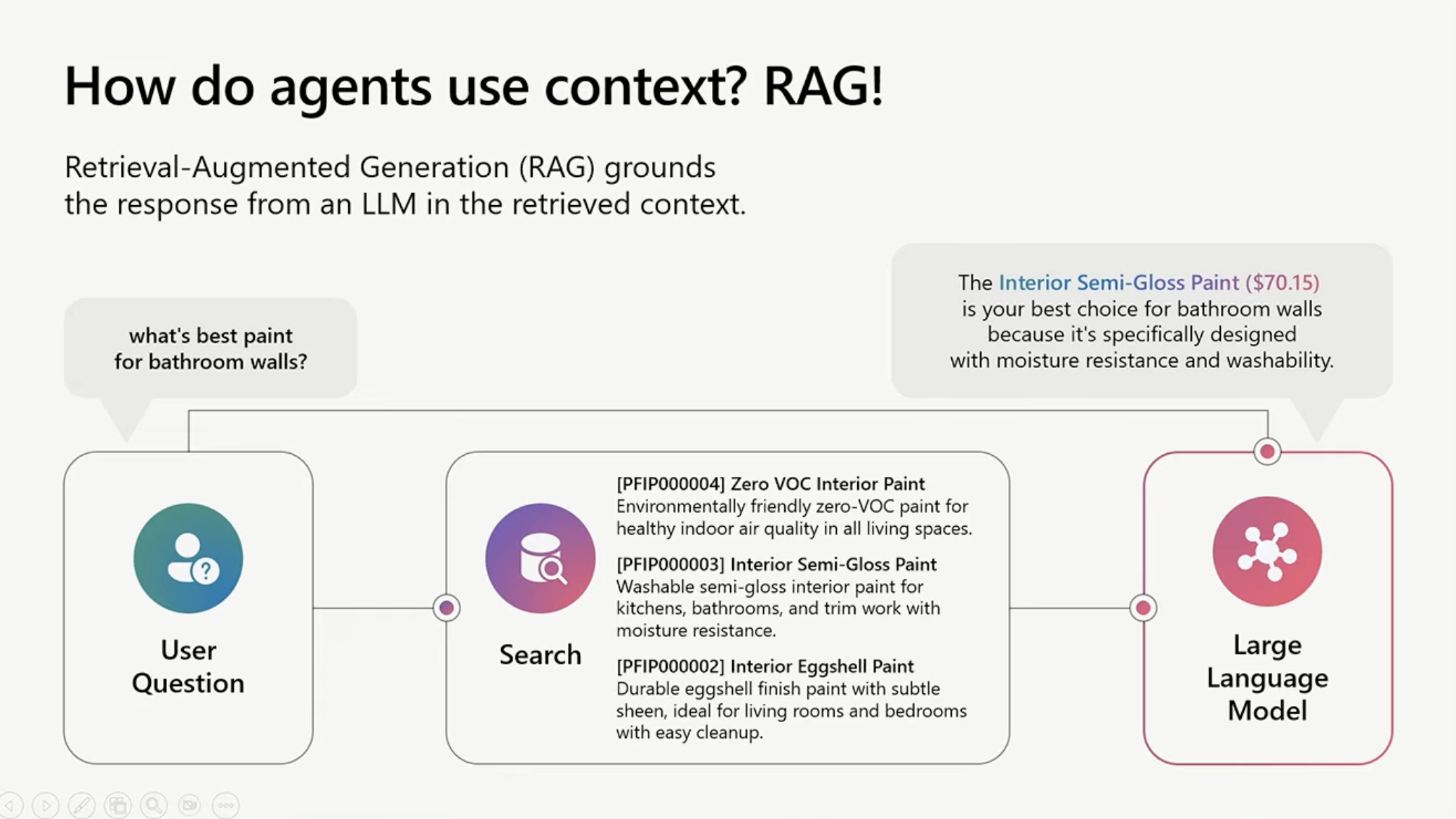
セッションでは、Zavaという架空の塗料メーカーのカタログを例に、「浴室の壁に最適なZavaの塗料は?」という質問に答えるデモが紹介されていました(02:24頃)。システムは「Interior Semi-Gloss Paint」を推奨し、その理由として「子供が浴室の壁に落書きをしたときに洗いやすい」という実用的な説明がありました。講師の実体験が反映されているようで、リアリティがありましたね。
検索方式の違いがもたらす結果の差
RAGの品質を左右するのは、検索の精度です。セッションでは、Keyword SearchとVector Searchの違いが具体的な例で説明されていました。
Keyword Searchの強みと弱み
Keyword Searchは、私たちが何十年も使ってきた伝統的な検索技術です。Azure AI SearchではBM25アルゴリズムを使用しており、これは業界標準の優れたアルゴリズムです。
強み: 明確なキーワードがある場合は非常に効果的
- 「25 foot hose」という検索では、25、foot、hoseという単語が全て含まれる商品が上位にランクされます(05:54頃)
- 製品番号や型番での検索に最適
弱み: 意味的な検索には不向き
- 「植物に無駄なく効率的に水をやるには?」という質問では、「water」という単語にマッチして「水性ポリウレタン」や「水性木材用染料」が上位に来てしまいます(06:26頃)
- 講師のコメント「これで植物に水をやろうとしたけど、うまくいかなかった」というジョークが印象的でした
この例を見て、社内のドキュメント検索でも同じような問題が起きているなと感じました。「障害対応の手順書」と検索しても、「障害」「対応」「手順書」という単語が含まれる全く関係ない文書がヒットしてしまうケースがありますよね。
Vector Searchの登場
Vector Searchは、テキストを多次元のベクトル空間に埋め込むことで、意味的な類似性を捉える技術です。
[Vector Searchの概念図]
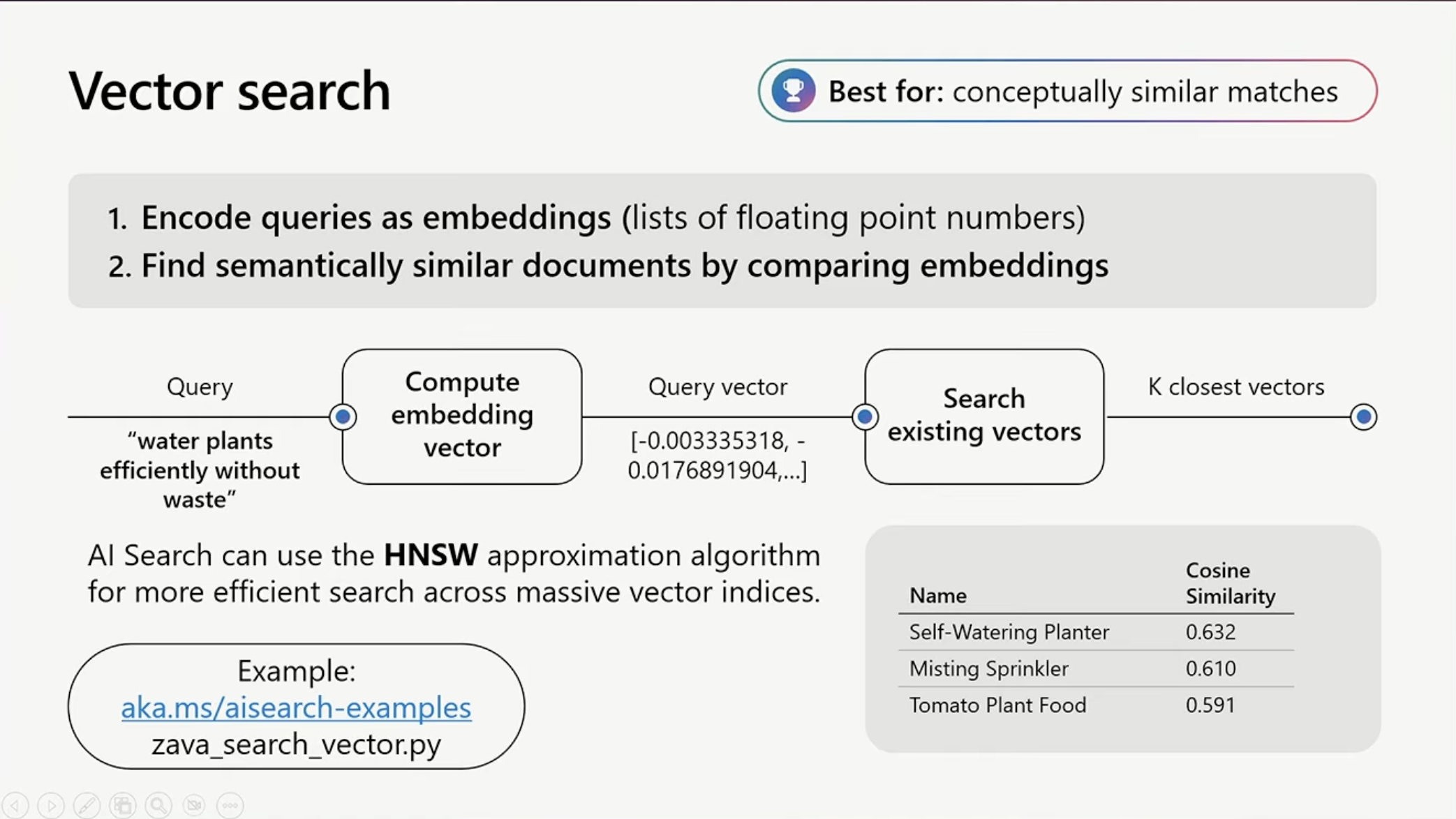
セッションでは、同じ「植物に無駄なく効率的に水をやるには?」という質問で、今度はVector Searchを使った結果が示されていました(07:52頃):
1位: Precision Drip Irrigation Kit(点滴灌漑キット)
2位: 25 foot hose
3位: Efficient Garden Sprinkler System(効率的な庭用スプリンクラーシステム)
これは素晴らしい結果です。質問の意図を正しく理解し、効率的な水やりに関連する商品を返しています。
しかし、Vector Searchにも弱点があります。先ほどの「25 foot hose」という明確なキーワード検索では、Vector Searchは3位に「25 foot hose」を返すものの、1位と2位にはスプリンクラー関連の商品が来てしまいます(08:34頃)。ユーザーが具体的な商品を探している場合、これは望ましくない結果ですよね。
企業のナレッジベースで考えると、「請求書発行手順」のような具体的なドキュメント名で検索する場合はKeyword Searchが有効ですが、「取引先とのトラブル時の対応方法」のような抽象的な検索にはVector Searchが必要になります。両方に対応できる仕組みが求められているのかなと思います。
Azure AI SearchのHybrid Search
両方の良いところ取りをする戦略
Azure AI Searchの大きな特徴は、Keyword SearchとVector Searchを組み合わせた「Hybrid Search」を標準で提供している点です(04:15頃)。
Hybrid Searchは以下のステップで動作します:
- 並列実行: Keyword SearchとVector Searchを同時に実行
- 結果のマージ: Reciprocal Rank Fusion(RRF)を使って2つの結果を統合
- 再ランキング: Semantic Rankerで最終的な順位を決定
[Hybrid Searchのフロー図]
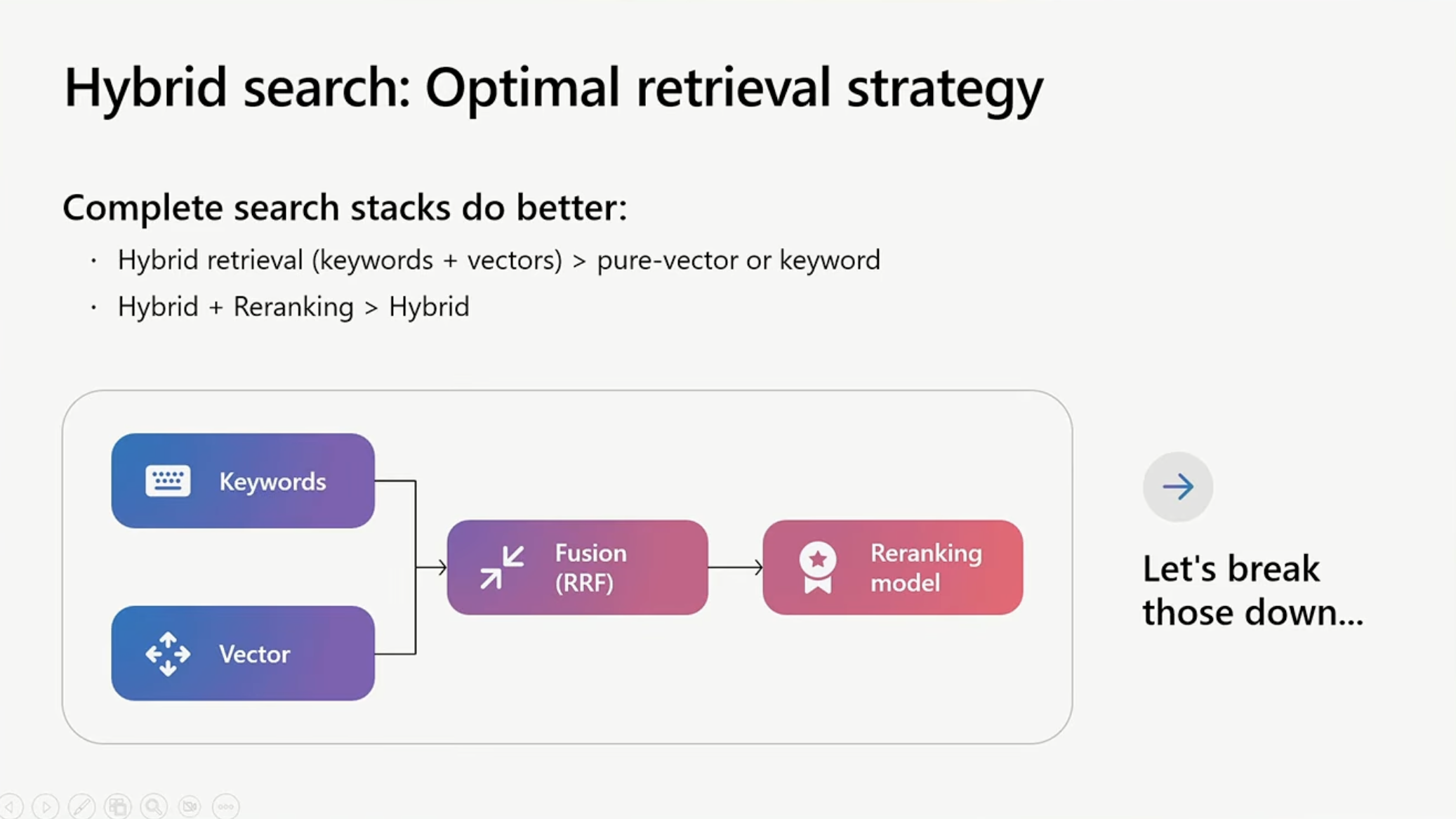
Reciprocal Rank Fusion(RRF)の仕組み
RRFは、複数の検索結果を統合するための数学的な手法です。セッションでは具体的な例が示されていました(09:42頃):
シナリオ: 「25 foot hose」で検索
- Keyword Search結果: 25 foot hoseが1位
- Vector Search結果: sprinkler systemsが1位、25 foot hoseが3位
RRFは各検索結果の順位に基づいてスコアを計算します:
- 1位の文書: 1/(60+1) = 0.016
- 2位の文書: 1/(60+2) = 0.016
- 3位の文書: 1/(60+3) = 0.016
両方に出現する文書は、スコアが加算されます。その結果、25 foot hoseは両方の検索で上位に現れるため、最終的に1位になります。
この仕組みは非常に賢いなと感じました。どちらか一方の検索だけでは見逃してしまう結果を、もう一方がカバーできるんですね。
Semantic Rankerによる最終調整
RRFで統合された結果は、さらにSemantic Rankerによって再ランキングされます(10:41頃)。
Semantic Rankerは、BingやMicrosoft 365で使われている技術で、質問と文書の意味的な関連性をより深く理解します。具体的には:
- 質問と各文書の内容を詳細に比較
- コンテキストを考慮した関連性の評価
- 最も適切な順序に再配置
セッションのデモでは、Hybrid SearchとSemantic Rankerを組み合わせることで、「25 foot hose」でも「植物に効率的に水をやるには?」でも、どちらのクエリでも適切な結果が得られることが示されていました(14:30頃)。
実装の観点から考えると、この機能がAzure AI Searchに組み込まれているのは大きなメリットです。自分でRRFやSemantic Rankerを実装する必要がなく、設定を有効にするだけで使えるのは、開発の手間を大きく削減できますね。
Agentic RAGとクエリプランニング
複雑なクエリの課題
エージェントが登場すると、RAGに求められる要件も変わってきます。セッションでは、こんな例が紹介されていました(15:30頃):
複雑なクエリ: 「今年の売上トップ5の製品と、それぞれの在庫状況、そして顧客レビューの平均評価を教えて」
このような質問には、複数の情報源からデータを取得する必要があります:
- 売上データベースから売上ランキング
- 在庫管理システムから在庫情報
- レビューシステムから評価データ
従来のRAGでは、この種の複雑なクエリを単一の検索として処理しようとすると、十分な結果が得られないことがあります。
クエリプランニングとサブクエリへの分解
Agentic RAGでは、エージェントが複雑なクエリを複数のサブクエリに分解し、それぞれを個別に処理してから結果を統合します(16:45頃)。
例:
- 「今年の売上トップ5の製品は?」
- 「それぞれの在庫状況は?」
- 「各製品のレビュー平均は?」
これらのサブクエリを並列または順次実行し、結果を統合することで、より包括的な回答を生成できます。
社内のDynamics 365環境で考えると、例えば「直近の大口顧客の商談状況と、担当営業の稼働率、そして今四半期の売上予測」のような複雑な質問にも対応できそうです。CRMデータ、リソース管理データ、予測分析データをそれぞれ取得して統合するイメージですね。
Azure AI SearchのQuery Rewrite機能
Azure AI Searchには、この「クエリの書き換え」を支援する機能が追加されています(18:20頃)。
Query Rewrite機能は:
- 元のクエリをより検索に適した形に変換
- 複数の検索意図を持つクエリを分解
- 検索精度を向上させるための最適化
セッションのデモでは、「屋外用のペンキで、耐久性が高く、価格が手頃なものを教えて」という質問が、以下のようなサブクエリに分解されていました(19:10頃):
- 「outdoor paint durable」
- 「exterior paint affordable」
- 「weather resistant paint reasonable price」
これらの検索結果を統合することで、元の複雑な質問に対する適切な回答を生成できます。
この機能は、エンドユーザーが自然な言葉で質問できるようにする上で重要だと感じました。社内ポータルのチャットボットなどでは、ユーザーは必ずしも検索に最適化された言葉を使うわけではないので、この種の自動最適化は非常に有用だと思います。
実装時の考慮点
Hybrid Searchの効果を最大化するために
セッションを視聴して、Hybrid Searchを効果的に使うためのポイントがいくつか見えてきました:
1. 適切なチャンキング戦略
文書をどのサイズに分割するかは、検索精度に大きく影響します。セッションの後半(43:44頃)で質疑応答があり、チャンキング戦略についての質問が出ていました。Azure AI Searchでは:
- デフォルトのチャンキング設定を使う
- カスタムスキルセットで独自のチャンキングロジックを実装する
という2つのオプションがあります。
日本語の文書を扱う場合、文の区切りや段落の構造が英語と異なるため、カスタムチャンキングが必要になるケースもありそうです。
2. Semantic Rankerのコスト意識
Semantic Rankerは強力ですが、追加のコストが発生します。全ての検索でSemantic Rankerを使う必要はなく、ユースケースに応じて使い分けるのが良いのかなと思います:
- 高精度が求められる場面: Semantic Rankerを有効化
- 大量の単純な検索: RRFまでで十分
3. エージェントとの統合設計
Agentic RAGを実装する場合、エージェントがどのように検索を制御するかの設計が重要です:
- エージェントがクエリプランニングを担当
- 各サブクエリに対してAzure AI Searchを呼び出し
- 結果の統合と回答生成はエージェント側で実施
この役割分担を明確にすることで、保守性の高いシステムが構築できそうです。
まとめ
学んだポイント
このセッションの前編から、以下の重要なポイントを学びました:
- Hybrid Searchの威力: Keyword SearchとVector Searchの良いところ取りができ、幅広いクエリタイプに対応できる
- RRFとSemantic Rankerの役割: 複数の検索結果を統合し、意味的に最も関連性の高い結果を提供する
- Agentic RAGの必要性: エージェント時代には、複雑なクエリを分解して処理する能力が重要
- Query Rewrite機能: 自然な質問を検索に適した形に変換し、ユーザー体験を向上させる
実際の導入を考えて
社内でRAGシステムを構築する場合、Azure AI SearchのHybrid Searchは非常に有力な選択肢だと感じました。特に:
- 日本語と英語が混在するドキュメント環境では、Keyword SearchとVector Searchの併用が効果的
- 既存の検索システムからの移行を考えると、API経由で段階的に統合できる点が魅力的
- エージェント開発を見据えた場合、Query Rewrite機能は開発工数の削減につながりそう
ただし、実際の導入では以下の点も検討が必要です:
- コスト最適化(特にSemantic Rankerの使い方)
- 日本語特有のチャンキング戦略
- セキュリティとアクセス制御の設計
次回予告
後編では、このセッションのもう一つの大きなテーマである「Knowledge Bases」について詳しく見ていきます。従来の手動RAG実装から、よりシンプルで保守性の高いKnowledge Basesへの移行、そしてFoundry IQとMCPを使ったエージェント統合について解説する予定です。