はじめに
IBM watsonx Orchestrateとwatsonx.data上のMilvusを組み合わせ、「自然言語で質問 → 関連する文章を検索 → 回答を生成」する最小構成のRAG環境を構築する手順を紹介します。
本記事では、厚生労働省が公開しているモデル就業規則をベクトルDBに格納し、就業規則に関する自然言語Q&AができるAgentを作ります。
👉 公式の詳細なマニュアルは以下をご参照ください。
1. 事前準備
IBM Cloud API Key の取得
IBM CloudアカウントでAPI Keyを発行します。
👉 手順はこちらの記事が参考になります:
watsonx.dataでMilvusを作成
watsonx.dataの管理画面からMilvusを作成します。
👉 詳細な手順はこちら:
ドキュメントのベクトル化とMilvusへの格納
PDF等のドキュメントを埋め込みベクトル化し、Milvusに保存します。
今回はこちらのモデル就業規則(厚生労働省)を対象とします:
今回の記事用に作成したサンプルコードを以下のGitHubに公開しました。
実際に動作するNotebook形式になっているので、そのまま試せると思います 👍
https://github.com/Natsuki0726/ibm-watsonx-rag-milvus/blob/main/rag_wx_milvus.ipynb
👉 他にも参考記事があります:
2. watsonx OrchestrateでAgentを作成する
watsonx Orchestrateのホーム画面です。
サイドバーから「Agent Builder」を選択します。
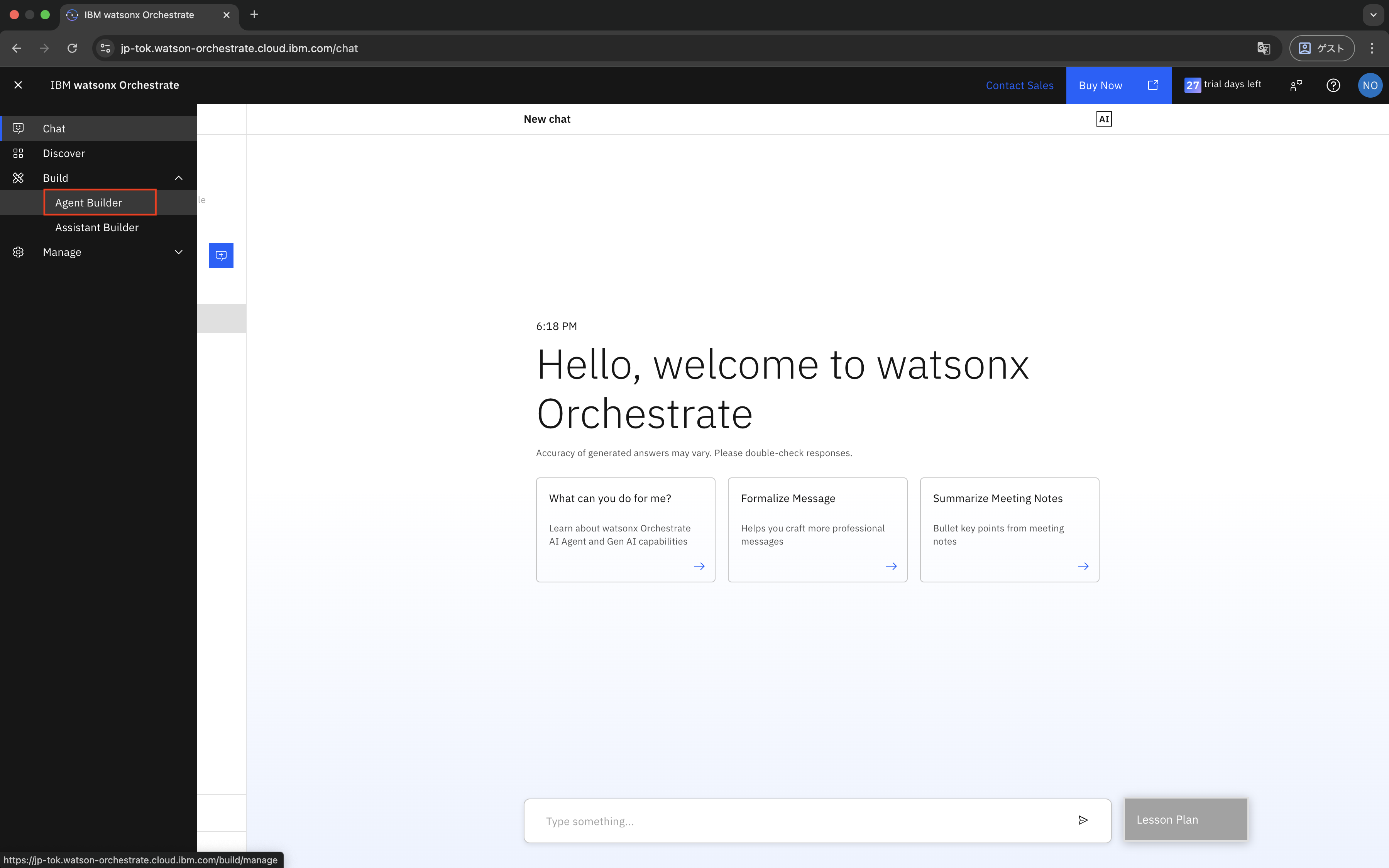
「Create agent」をクリックします。
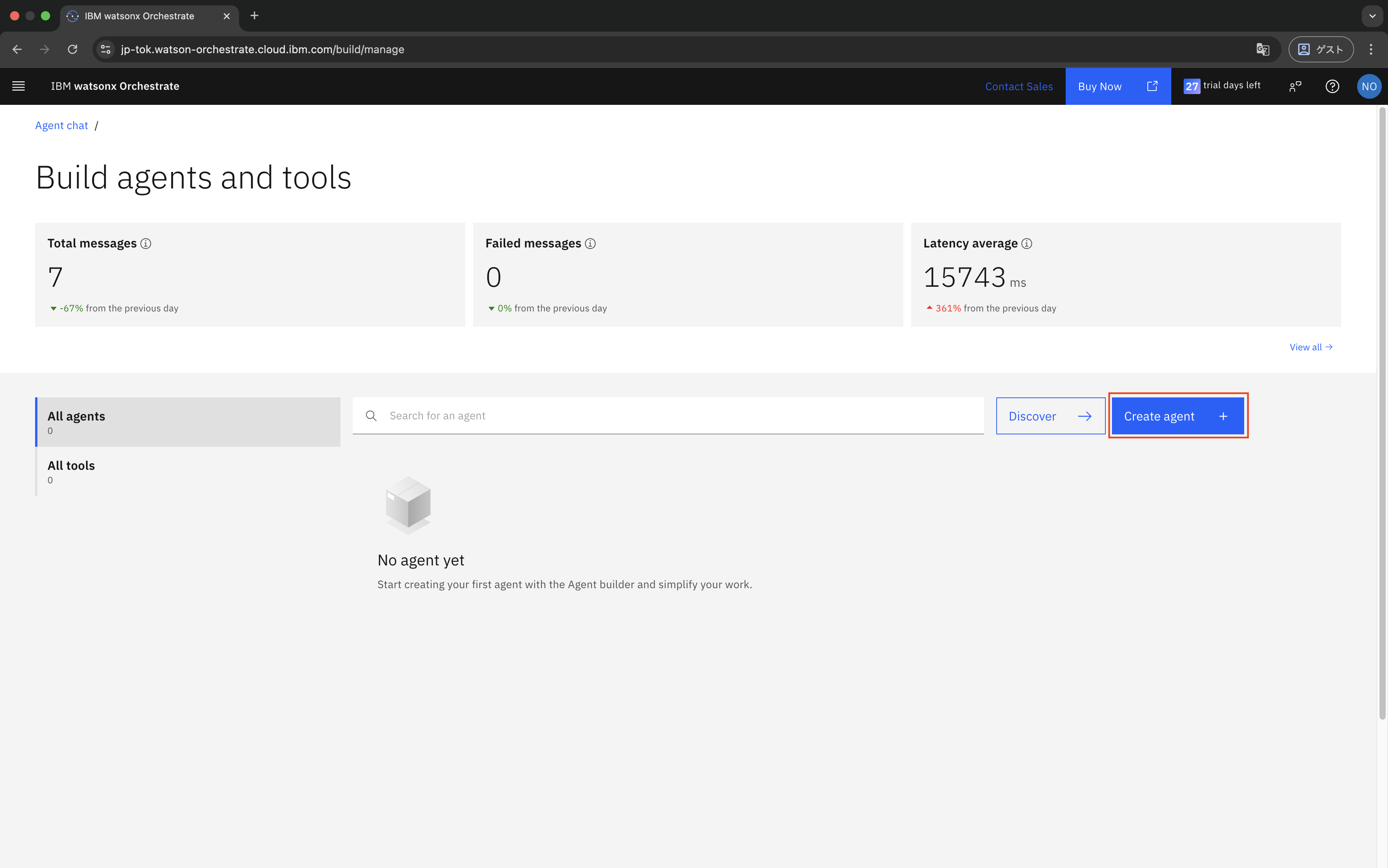
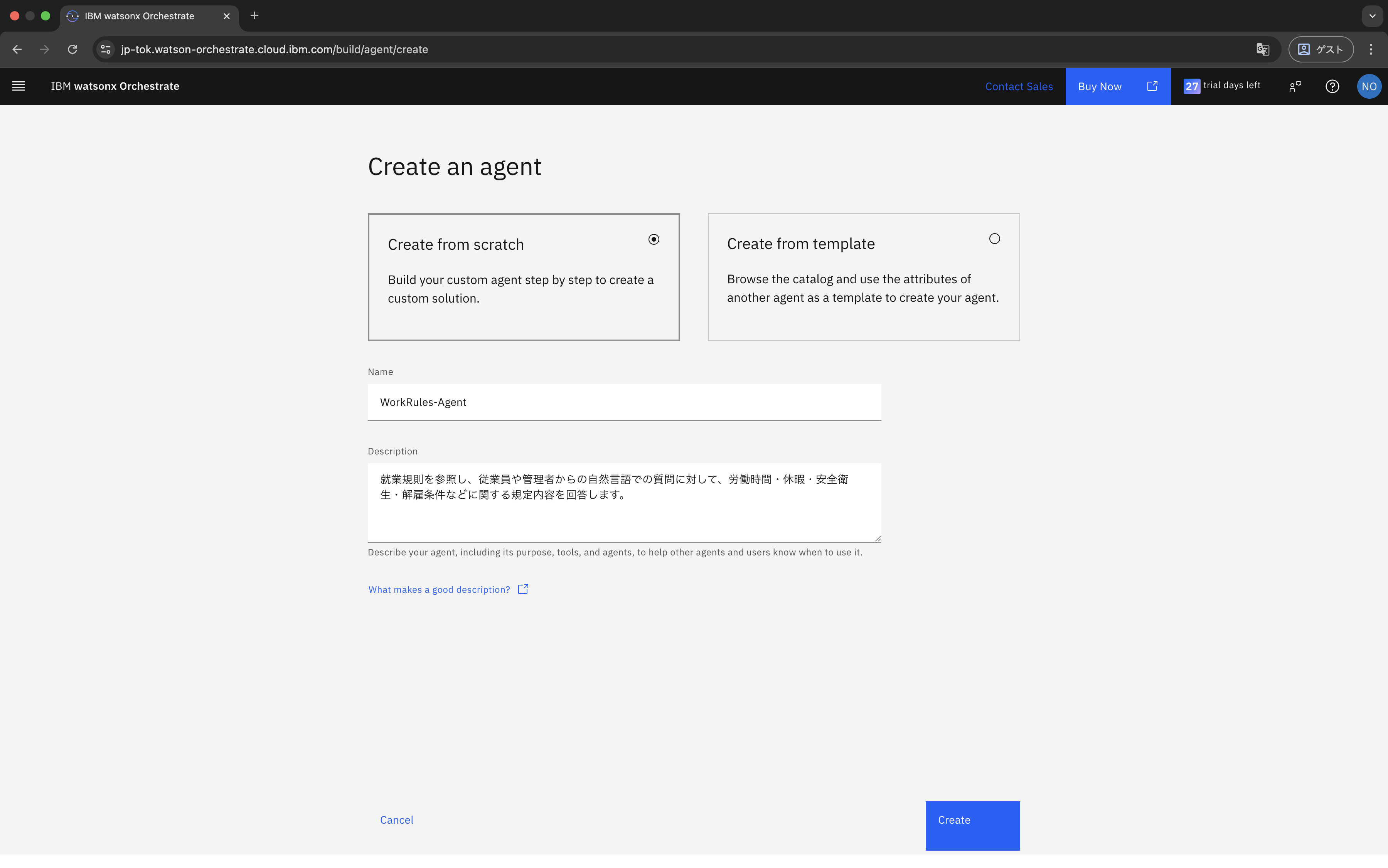
今回はテンプレートを使用せず、ゼロからAgentを作成するため、「Create from scratch」を選択します。任意のName(名前)とDescription(説明)を入力し、「Create」をクリックします。
入力例:
- Name:
WorkRules-Agent - Description:
就業規則を参照し、従業員や管理者からの自然言語での質問に対して、労働時間・休暇・安全衛生・解雇条件などに関する規定内容を回答します。
Agentが作成されました。
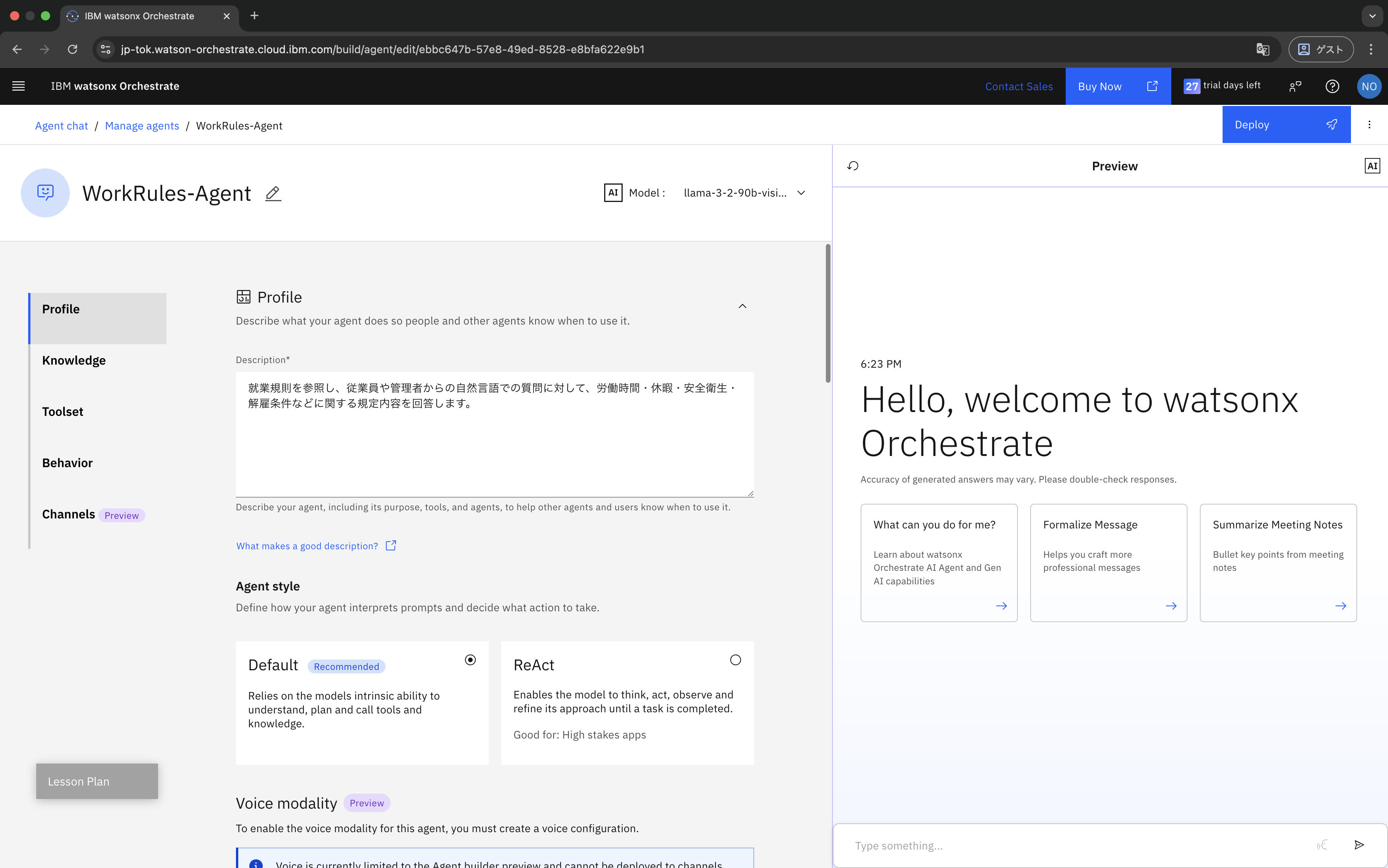
3. Agentの設定
作成したAgentに対して、まずはBehaviorを設定します。
ここではエージェントがユーザーからの質問にどう答えるべきかを指示します。
例として、就業規則に基づいて回答するよう以下のように設定します:
エージェントは就業規則に基づき、従業員や管理者からの質問に正確かつ簡潔に回答してください。
答えが文書に含まれていない場合は「就業規則からは分かりません」と回答してください。
不確かな推測や規則外の情報は答えないでください。
次に、 利用するモデルを設定します。
今回はDefaultのllama-3-2-90b-vision-instructを利用します。
試しに、以下の質問を投げてみます。
事業者が実施しなければならない一般健康診断の頻度はどのくらいですか?
その内容が記載されている就業規則の条番号も教えてください。
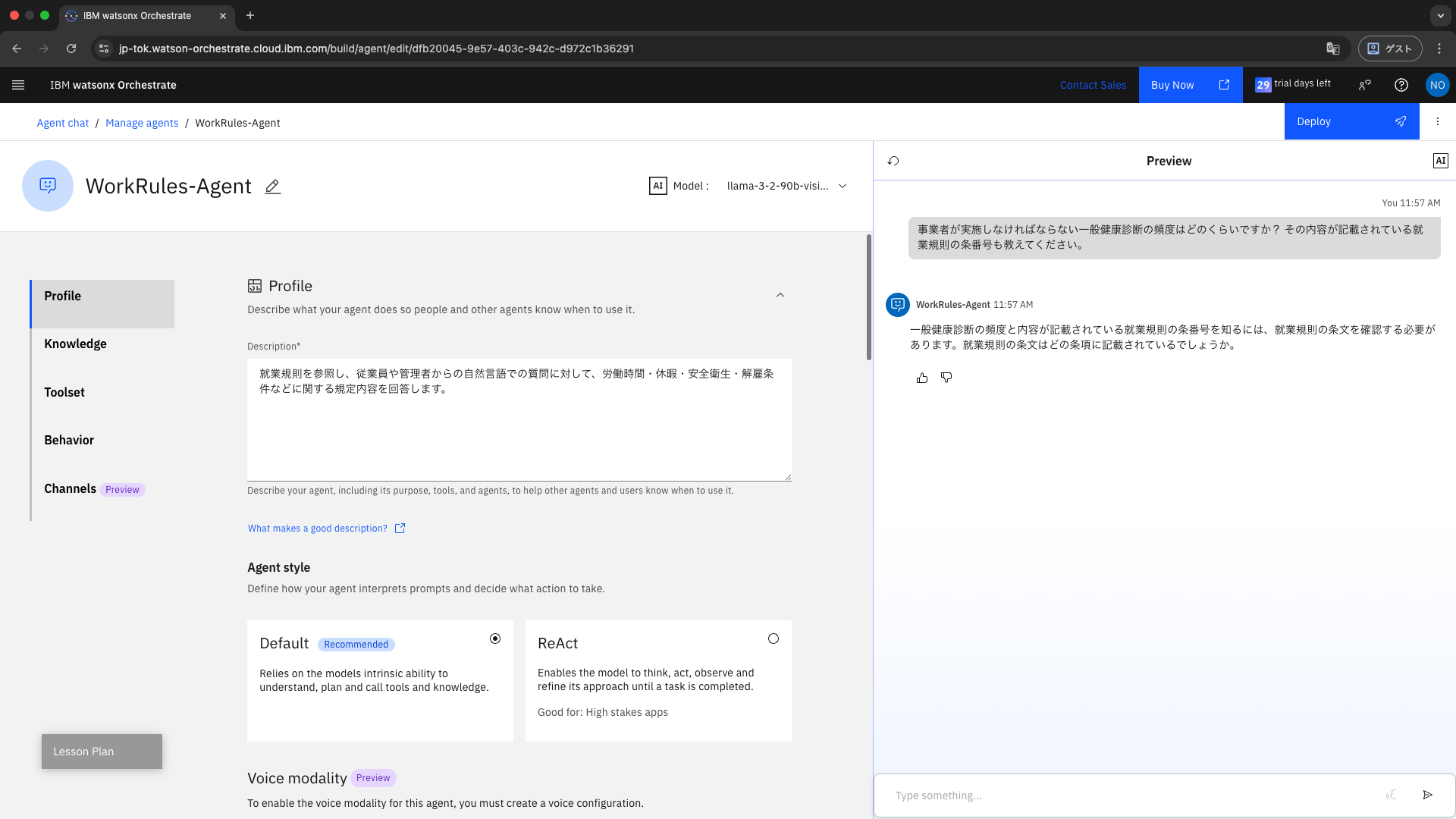
この時点では、まだMilvusとの接続を行っていないため、正しい回答は得られません。
4. watsonx.data上でMilvusの接続情報を取得する
次に、watsonx OrchestrateからMilvusにアクセスできるように、watsonx.data上で作成したMilvusの接続情報(GRPCホスト / ポート)を確認します。
まず、watsonx.dataの管理画面からMilvusを選択します。
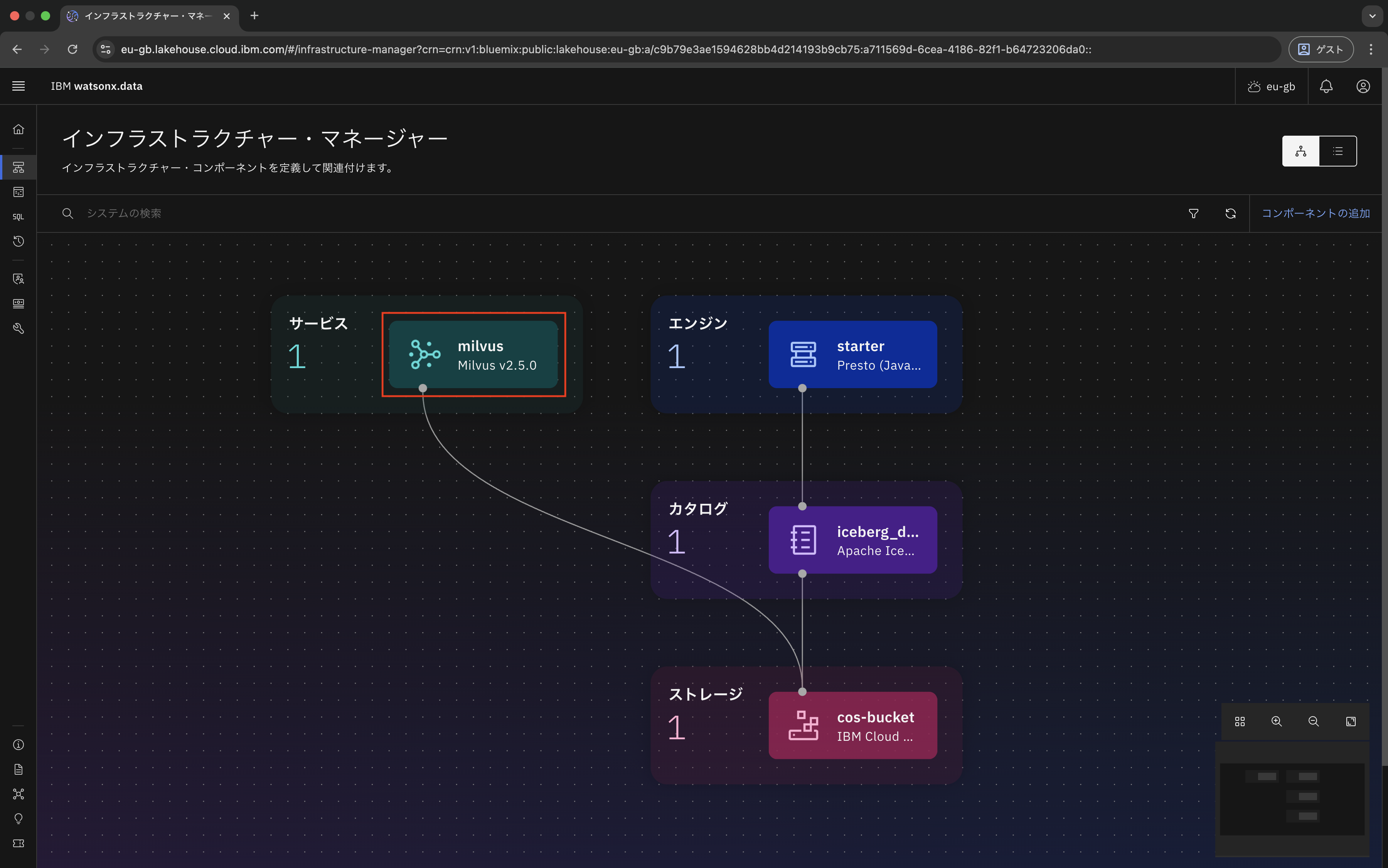
「接続の詳細を見る」をクリックします。
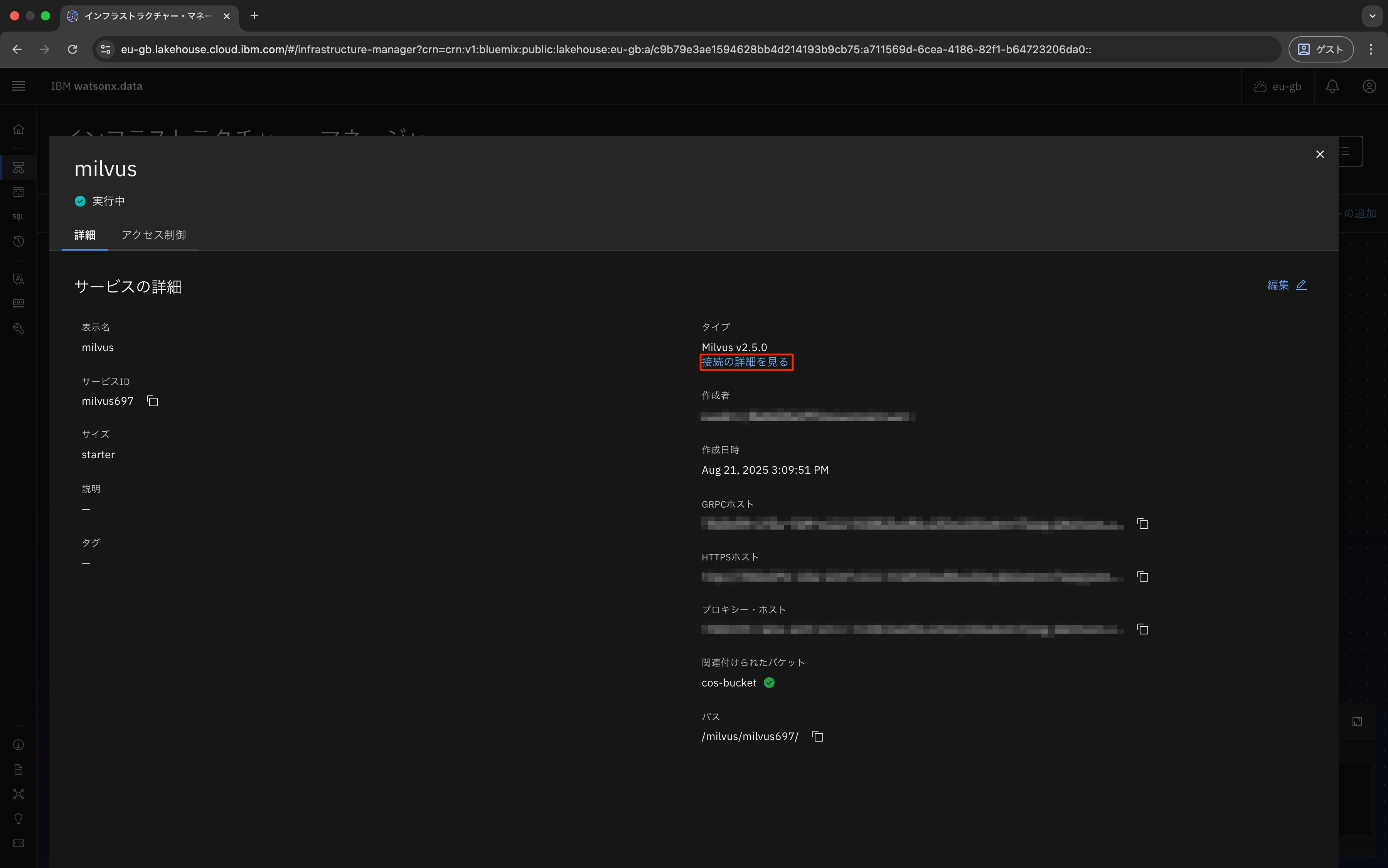
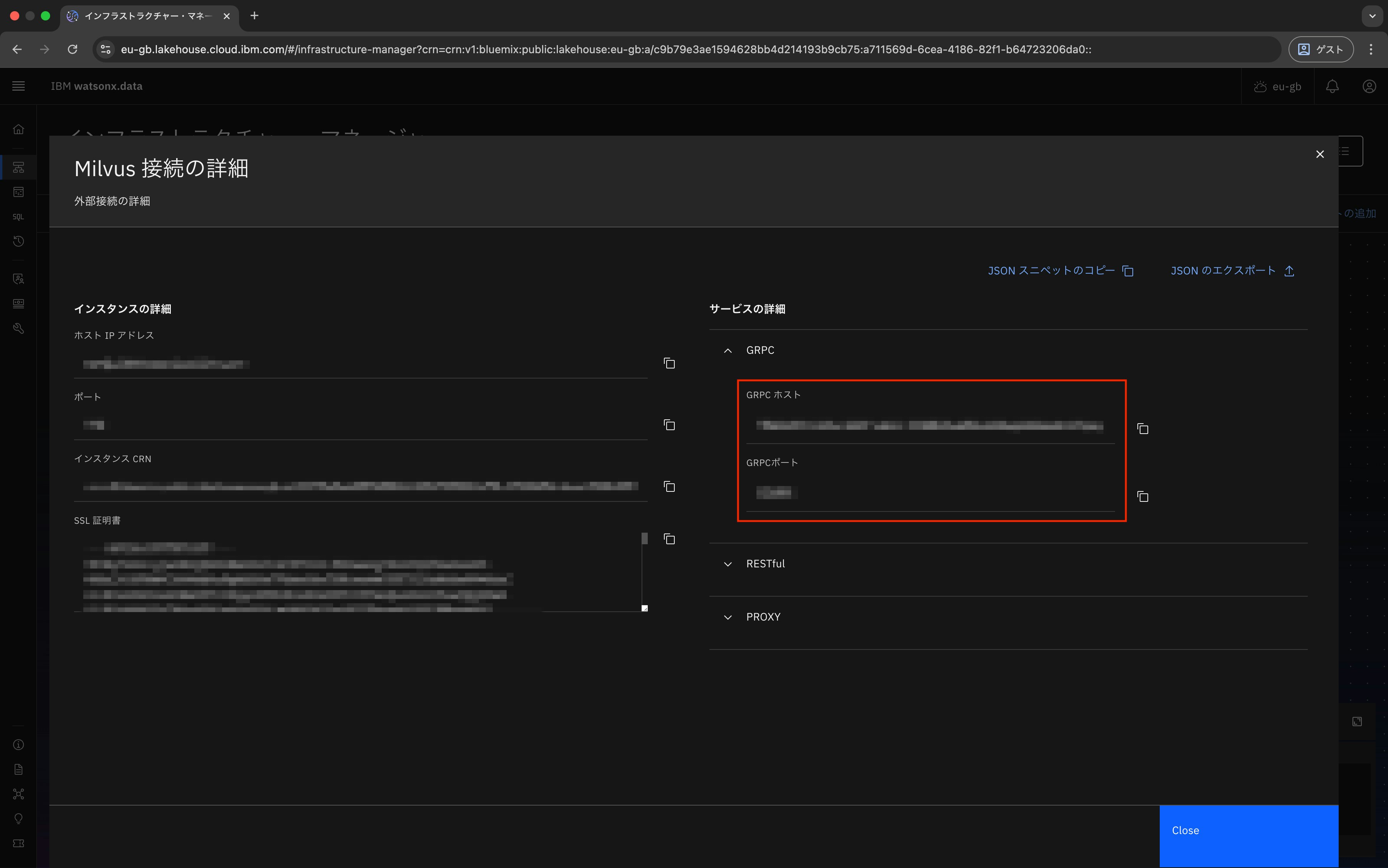
ここに表示されるGRPCホストとGRPCポートを控えておきます。
この情報は後ほどwatsonx OrchestrateでMilvusを接続するときに入力します。
5. watsonx OrchestrateにMilvusを接続する
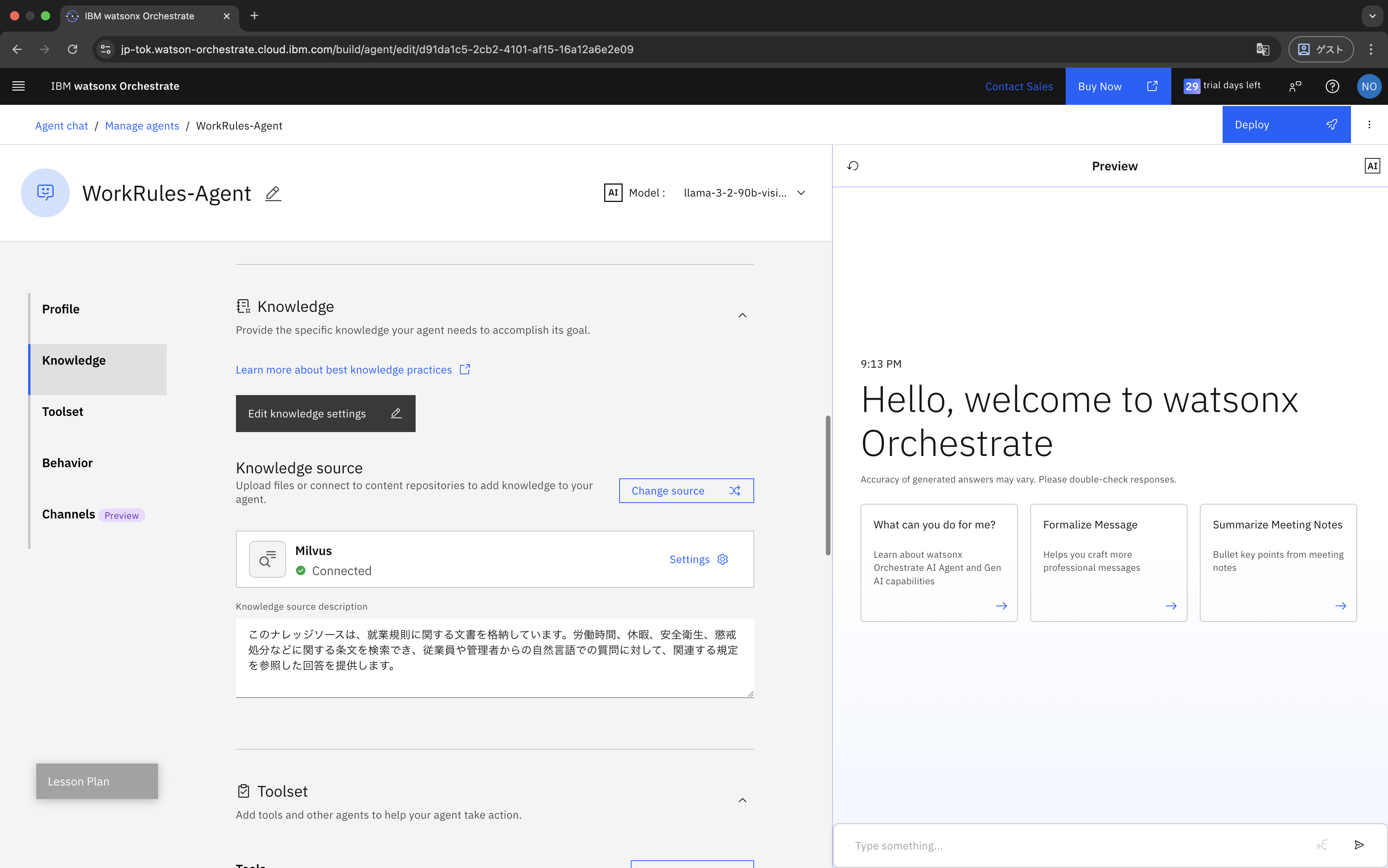
次に、作成したwatsonx OrchestrateのAgentにMilvusをナレッジソースとして接続します。
まず、Agentの編集画面に戻り、Knowledge欄の「Choose knowledge」をクリックします。
Knowledge sourceとして「Milvus」を選択します。
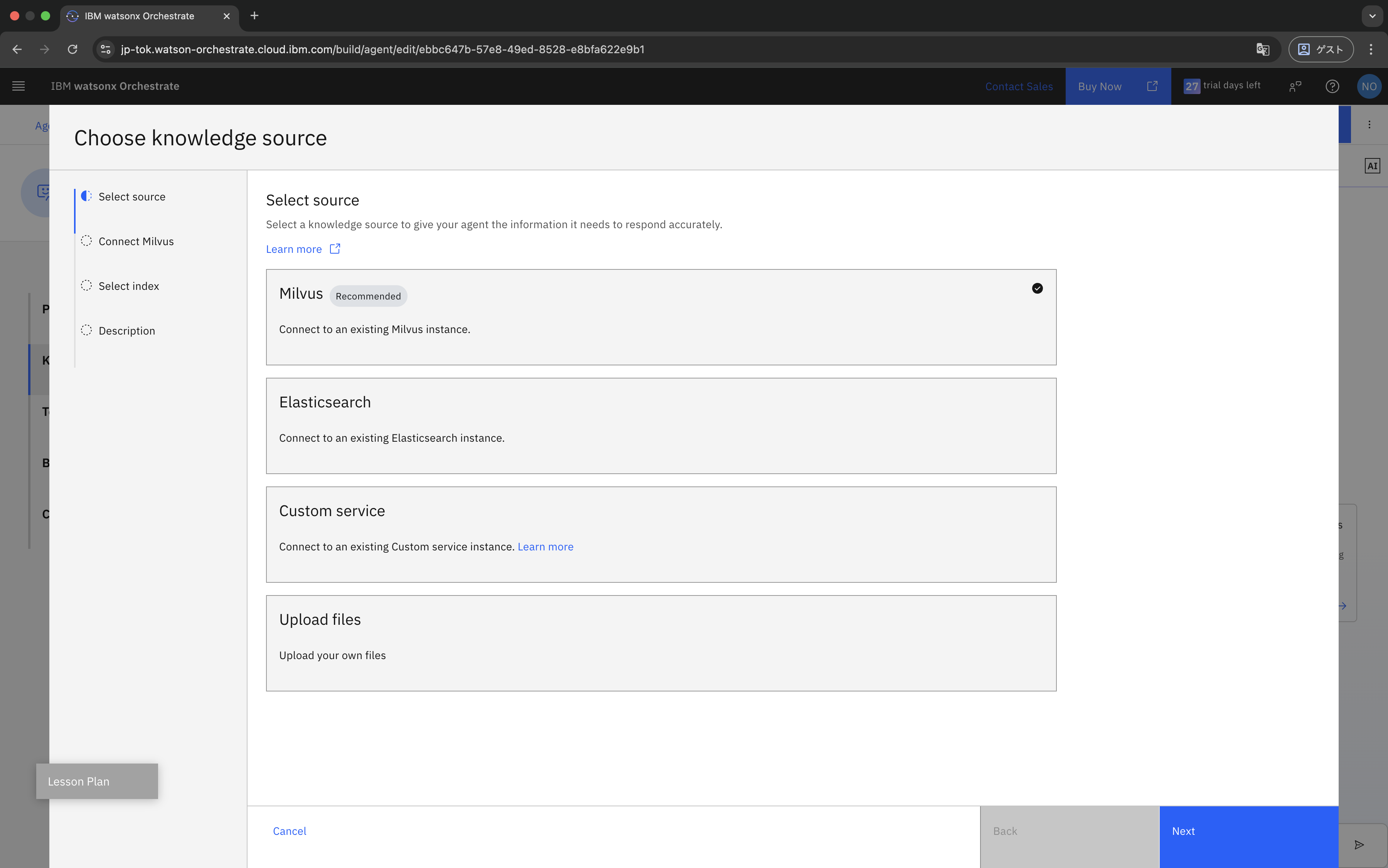
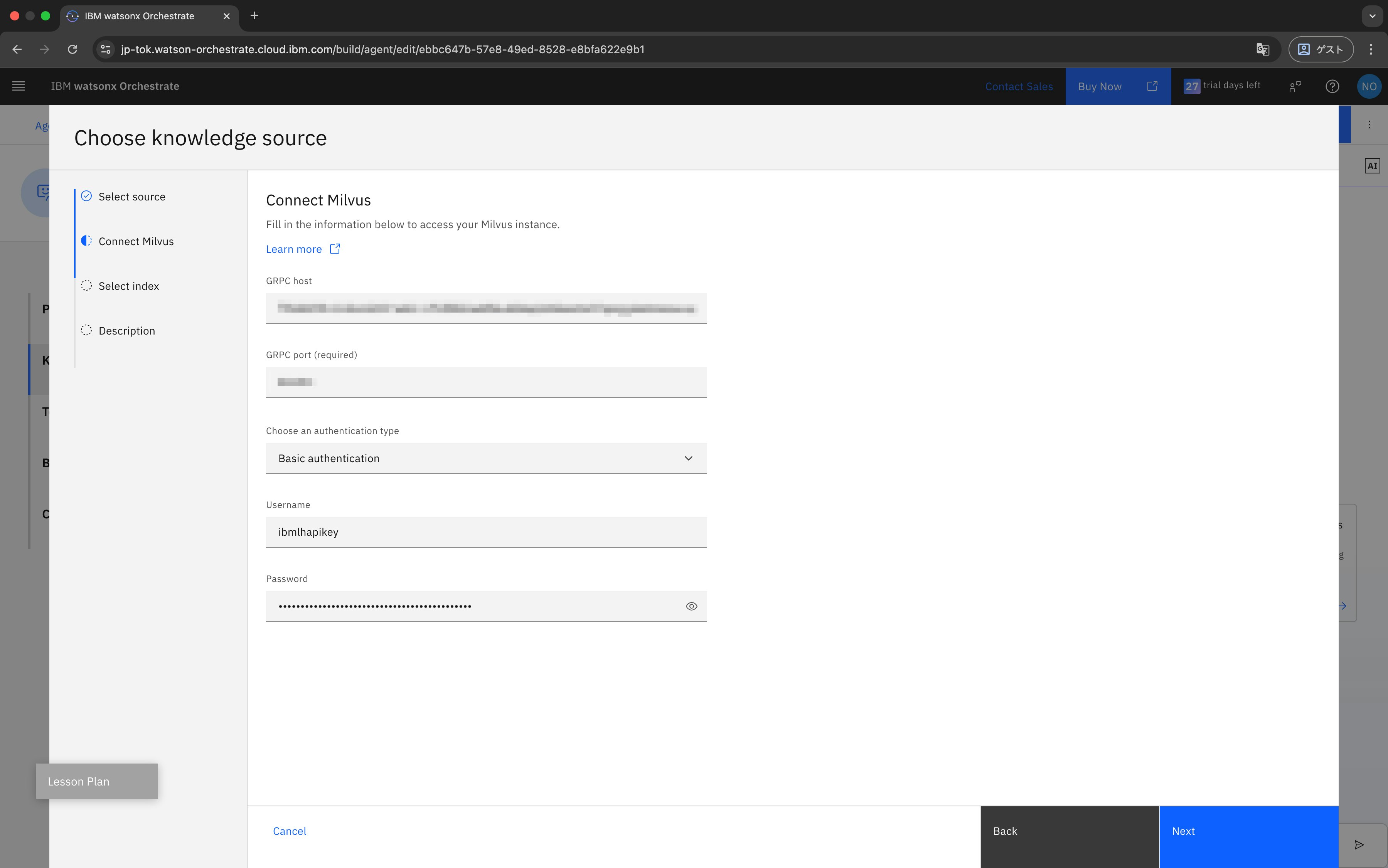
次に、接続情報を入力します。
ここで利用するのは、先ほどwatsonx.dataで確認したGRPCホスト/ポートです。
- GRPC host:控えておいたGRPCホスト
- GRPC port:控えておいたGRPCポート
- Username:
ibmlhapikey - Password:IBM Cloudで取得したAPI Key
入力後に「Next」をクリックします。
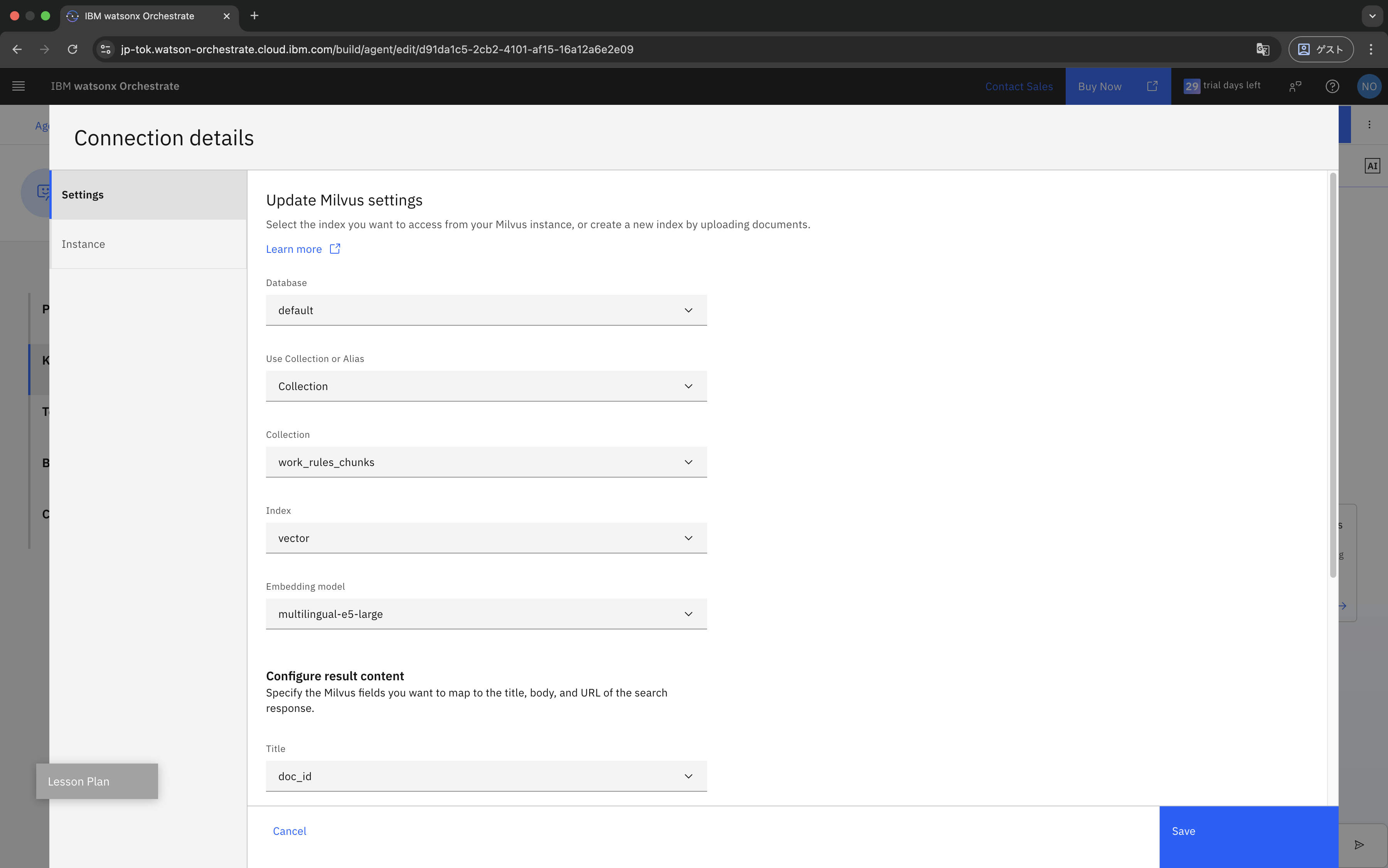
続いて、Milvusに格納したドキュメントのインデックスを選択します。
Embedding modelは、インデックスを作成したときに利用したモデルと必ず一致させる必要があります。
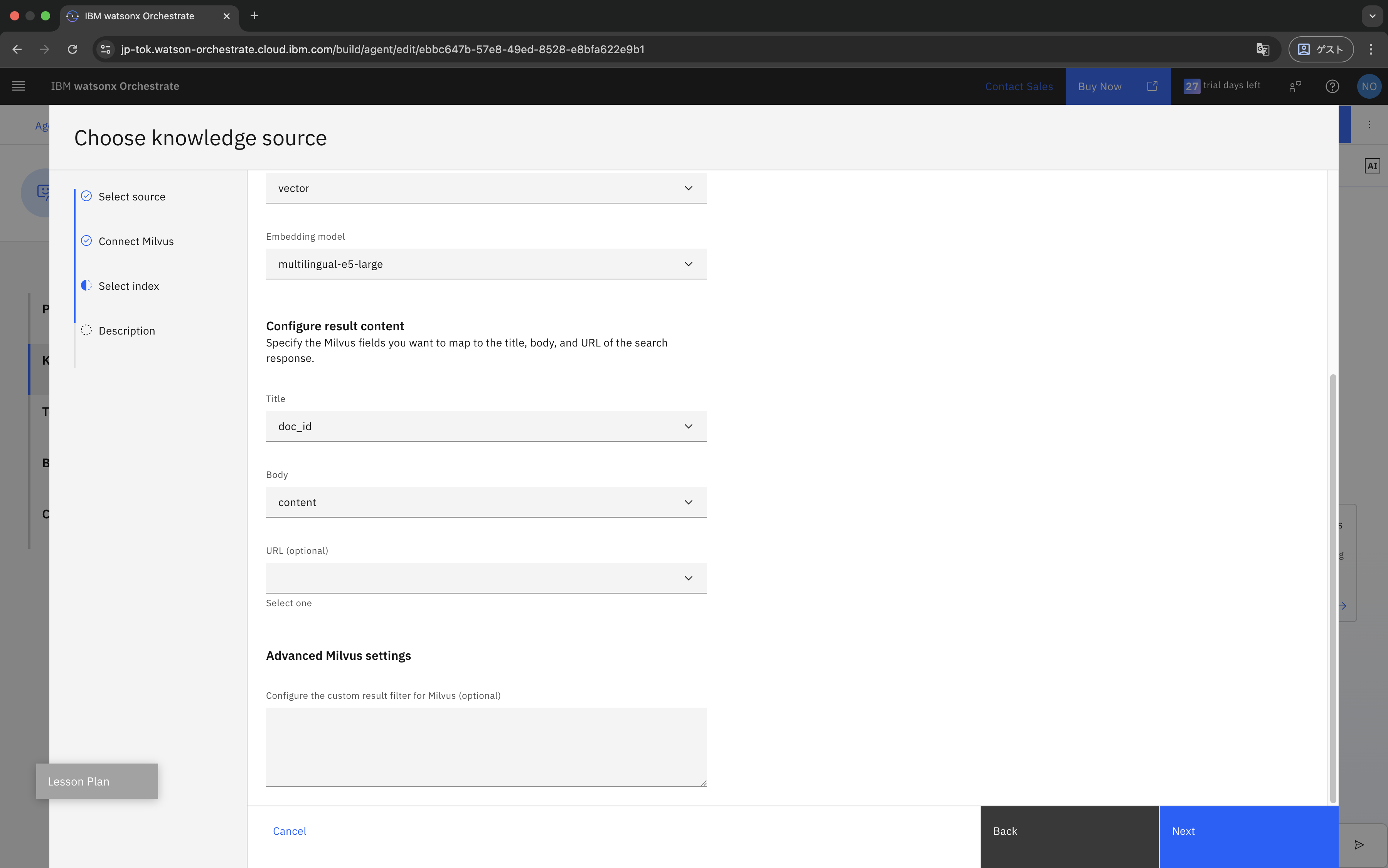
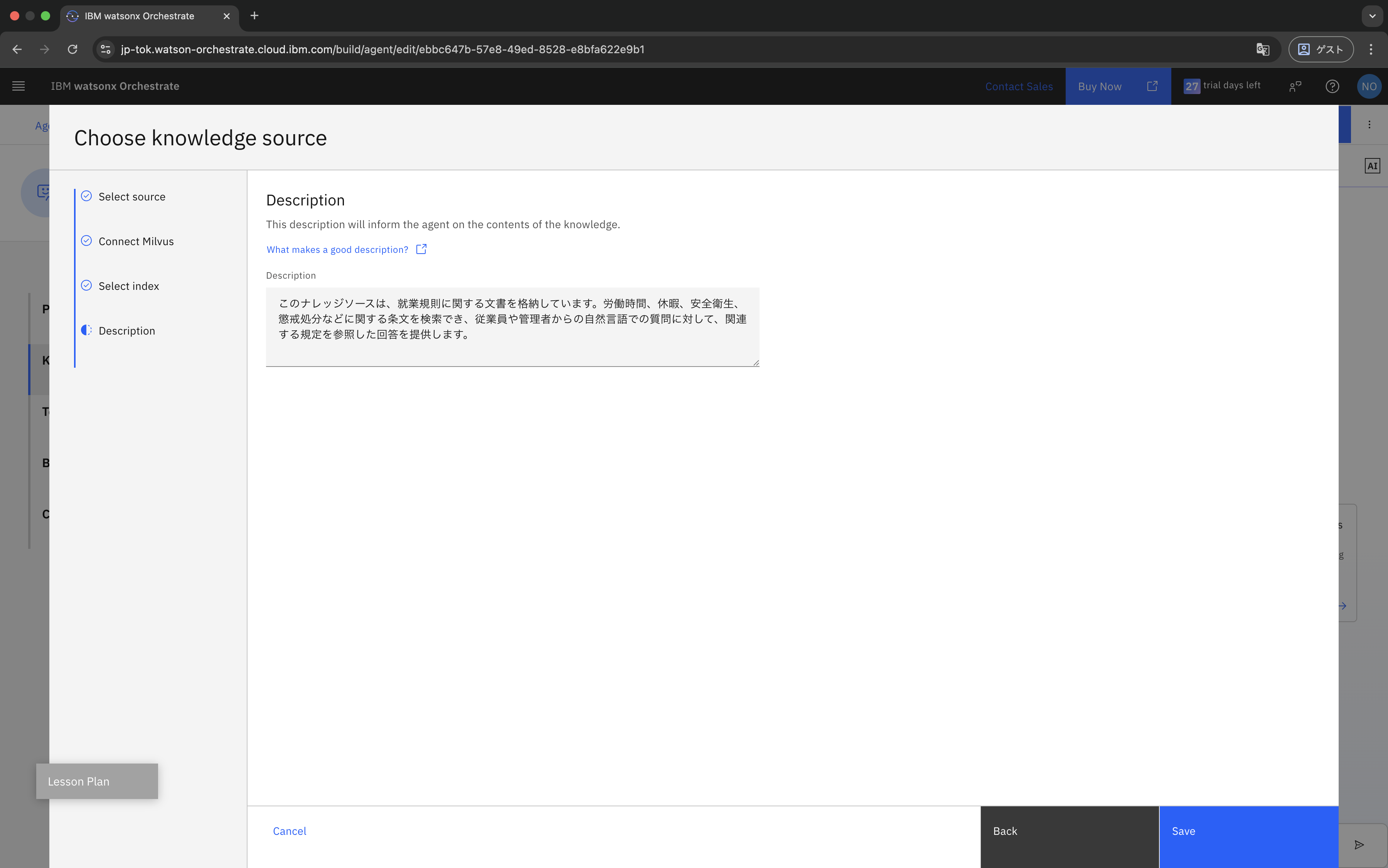
最後に、Knowledgeの説明を入力して保存します。
入力例:
このナレッジソースは、就業規則に関する文書を格納しています。労働時間、休暇、安全衛生、懲戒処分などに関する条文を検索でき、従業員や管理者からの自然言語での質問に対して、関連する規定を参照した回答を提供します。
これで、AgentのKnowledge sourceにMilvusが接続されました。
6. 動作確認
実際に質問をして、Milvusに格納した就業規則が正しく参照されるか確認します。
Milvus接続前にも投げてみた質問をもう一度実行します。
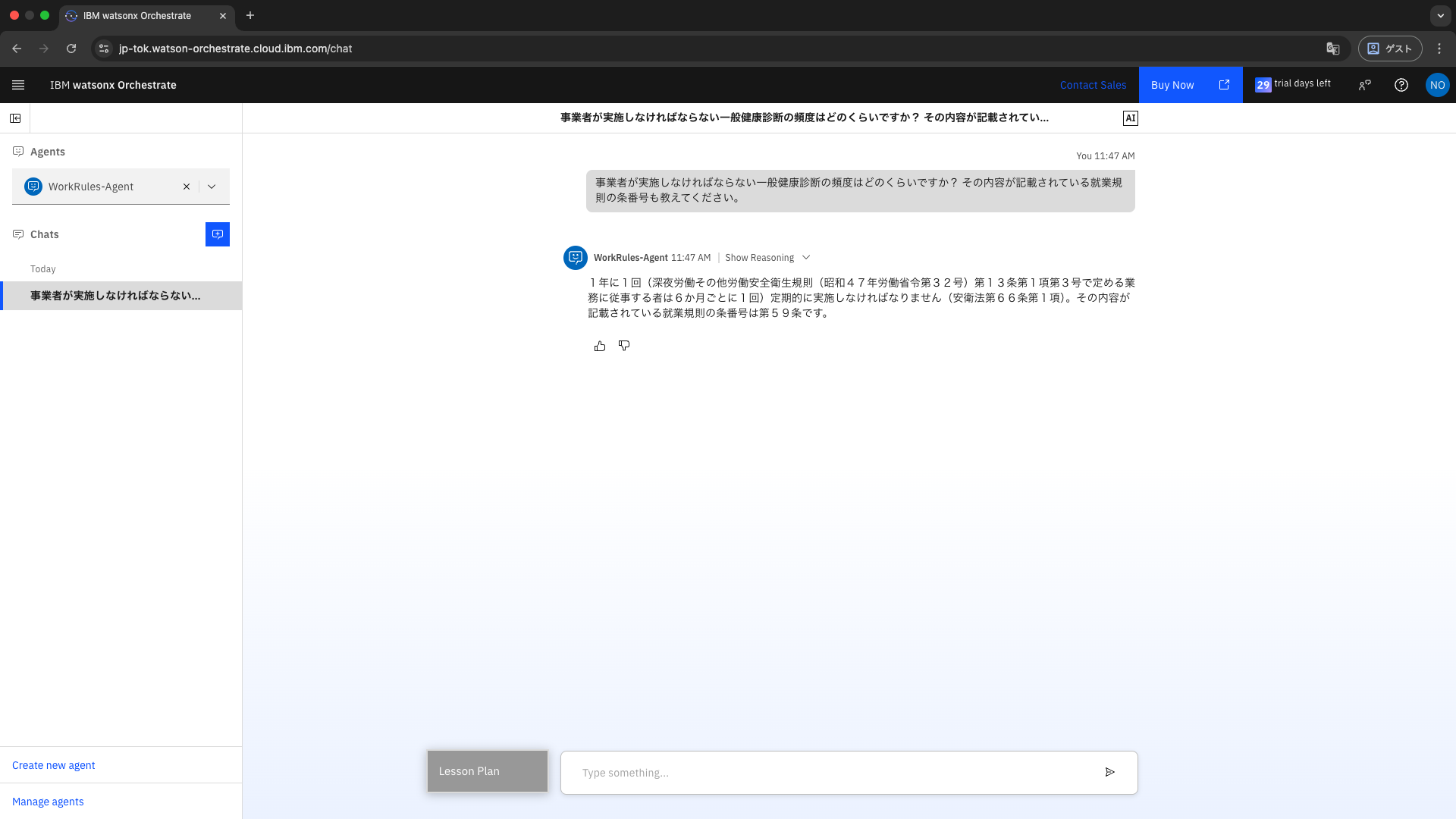
事業者が実施しなければならない一般健康診断の頻度はどのくらいですか?
その内容が記載されている就業規則の条番号も教えてください。
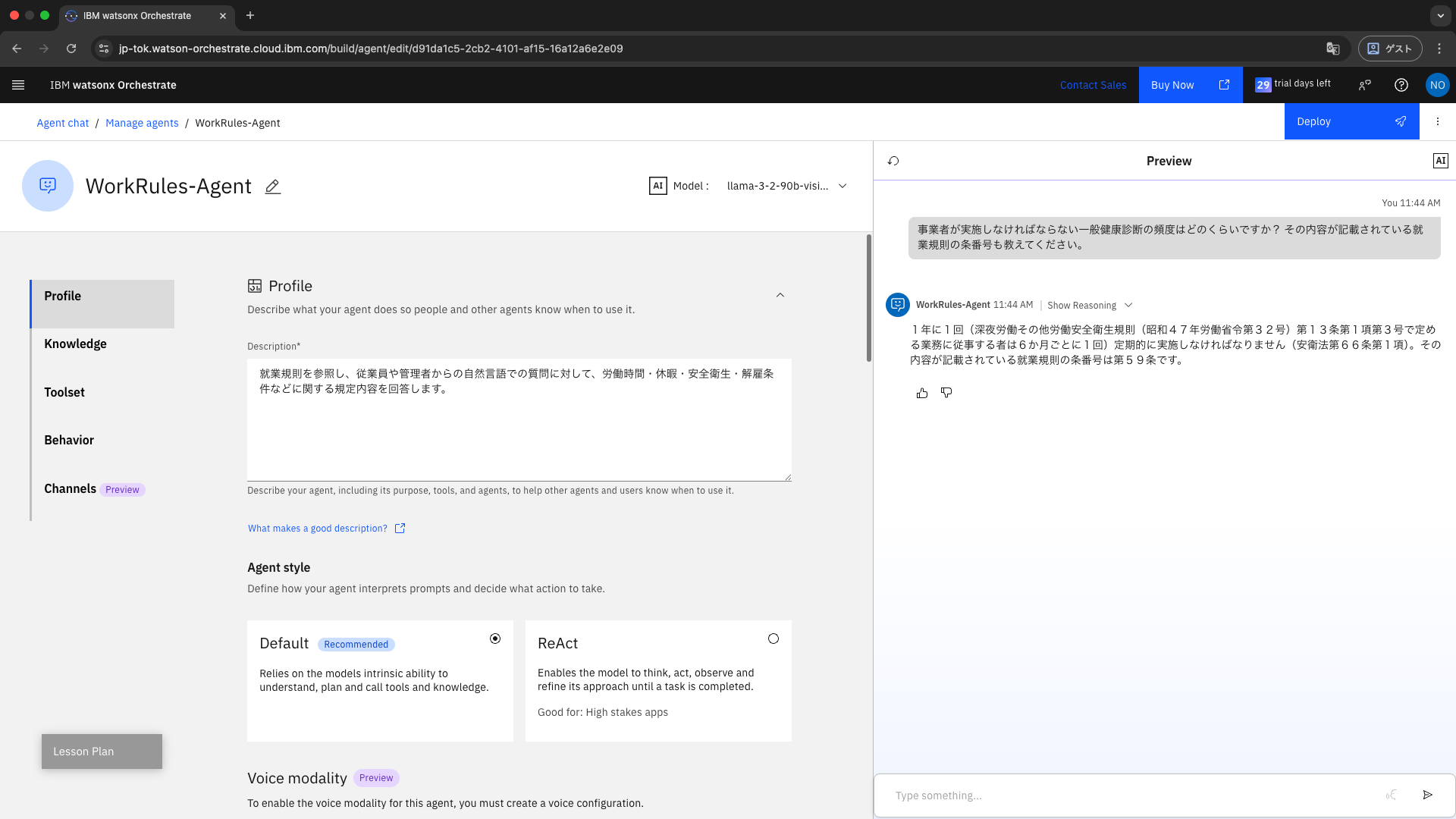
以下のモデル就業規則 第59条(健康診断)を根拠に、「年1回(深夜業務従事者などは6か月ごと)」 といった正しい答えが返ってきました ✅

7. AgentのDeploy
エージェントを作成しただけでは利用できないため、誰でも使えるようにDeploy(デプロイ)を行います。
画面右上の「Deploy」をクリックします。
特に追加の入力は不要です。そのまま「Deploy」をクリックします。
これでデプロイが完了しました。
「WorkRules-Agent」が選択されている状態になり、利用可能になっていることがわかります。
8. まとめ
本記事では watsonx Orchestrate × watsonx.data (Milvus) を組み合わせて、自然言語でQ&Aができる最小構成のRAGエージェントを構築しました。就業規則のような長文文書であっても、ユーザーは自然な質問を入力するだけで、エージェントが 「関連条文を検索 → 回答を生成」 する一連の流れを自動化できることを確認しました。
今回の仕組みはシンプルですが、この基盤を応用することで、より複雑なフローや複数の知識ソースを組み合わせた高度なエージェント構成へと発展させることが可能です。