はじめに
今回はジャルジャルの動画のタイトルから再生回数を予測するモデルを作るお話です。NLPは全くの素人のため他の方の記事を参考に見様見真似でやってみました。
ジャルジャルとは
ジャルジャルは、吉本興業東京本社所属の後藤淳平さんと福徳秀介さんで構成されてる今最も勢いのあるお笑いコンビです。現在、ジャルジャル公式YouTubeチャンネルにてJARUJARU TOWERという企画で毎日ネタを投稿しています。

背景
Youtubeに毎日投稿されるネタをその都度チェックするのは非常にコストがかかります。また、ジャルジャルの動画は意味不明なタイトルの方が伸びやすい傾向にあります(めっちゃ主観)。例えば、「ヤバい店員にヤバい客にされた奴」「独裁者の卵な奴」といったネタです。タイトルに「ヤバイ、頭おかしい」などのワードが入っていたら大体再生回数が多いような気がしています。逆に「チャラ男番長のネタを見る奴」というネタは再生回数が少ない傾向にあり、このタイトルの動画にはみんな問答無用で低評価をつけるのが恒例行事となっています。

開発環境
- Python
- Mecab
- scikit-learn
- gensim
データ集め
今回はYoutubeDataAPIを使って動画のタイトルと再生回数をセットで集めてきます。こちらの「YouTube Data api v3をPythonから使って特定のチャンネルの動画を取得する1」という記事と「YouTube Data api v3をPythonから使って動画の閲覧数をごそっと取得する2」という記事を参考にさせて頂きました。また、YoutubeのAPIを使うにはAPIkeyが必要なので「YouTube API APIキーの取得方法3」こちらの記事を参考にkeyを取得しました。
まず、以下のコード動画のタイトルと動画ID(動画の再生回数を取得するときに必要)を集めます。
import os
import time
import requests
import pandas as pd
API_KEY = os.environ['API_KEY']#環境変数に追加したIDを持ってくる
CHANNEL_ID = 'UChwgNUWPM-ksOP3BbfQHS5Q'
base_url = 'https://www.googleapis.com/youtube/v3'
url = base_url + '/search?key=%s&channelId=%s&part=snippet,id&maxResults=50&order=date'
infos = []
while True:
time.sleep(30)
response = requests.get(url % (API_KEY, CHANNEL_ID))
if response.status_code != 200:
print('エラーで終わり')
print(response)
break
result = response.json()
infos.extend([
[item['id']['videoId'], item['snippet']['title'], item['snippet']['description'], item['snippet']['publishedAt']]
for item in result['items'] if item['id']['kind'] == 'youtube#video'
])
if 'nextPageToken' in result.keys():
if 'pageToken' in url:
url = url.split('&pageToken')[0]
url += f'&pageToken={result["nextPageToken"]}'
else:
print('正常終了')
break
videos = pd.DataFrame(infos, columns=['videoId', 'title', 'description', 'publishedAt'])
videos.to_csv('data/video1.csv', index=None)
動画タイトルとIDを集めたら以下のコードで再生回数も集めてきます。
import os
import time
import requests
import pandas as pd
API_KEY = os.environ['API_KEY']
videos = pd.read_csv('videos.csv')
base_url = 'https://www.googleapis.com/youtube/v3'
stat_url = base_url + '/videos?key=%s&id=%s&part=statistics'
len_block = 50
video_ids_per_block = []
video_ids = videos.videoId.values
count = 0
end_flag = False
while not end_flag:
start = count * len_block
end = (count + 1) * len_block
if end >= len(video_ids):
end = len(video_ids)
end_flag = True
video_ids_per_block.append(','.join(video_ids[start:end]))
count += 1
stats = []
for block in video_ids_per_block:
time.sleep(30)
response = requests.get(stat_url % (API_KEY, block))
if response.status_code != 200:
print('error')
break
result = response.json()
stats.extend([item['statistics'] for item in result['items']])
pd.DataFrame(stats).to_csv('data/stats.csv', index=None)
videos = pd.read_csv('videos.csv')
stasas = pd.read_csv('stats.csv')
pd.merge(videos, stasas, left_index=True, right_index=True).to_csv('data/jarujaru_data.csv')
以下のようなデータが保存されます。
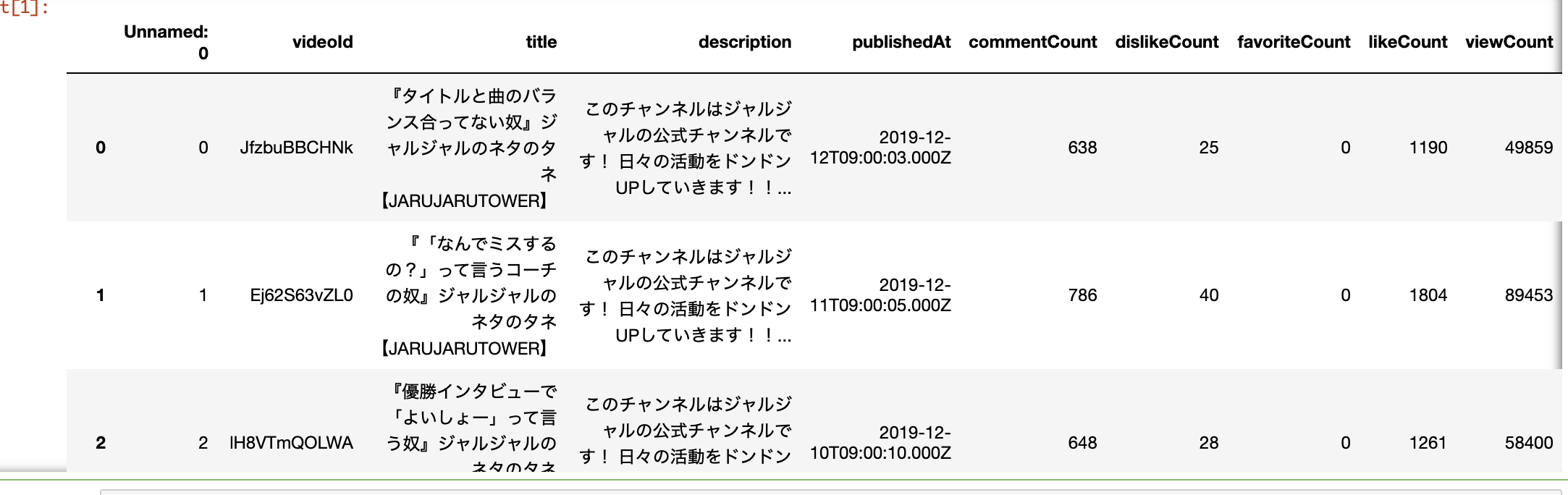
再生回数予測モデル
ラベル付け
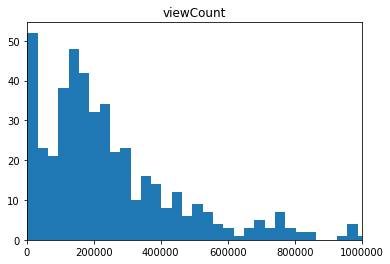
今回は再生回数を3段階に分けて分類問題にしようと思います。再生回数のヒストグラムは以下になります。以下のグラフから圧倒的主観でラベル付けをしていきます。再生回数10万未満、10万以上25万未満、25万以上の3段階で分けました。
以下のコードはラベル付けと動画のタイトルからコント名だけをとってくるコードです。ジャルジャルのコント動画は必ずコントの名前を『』で囲っているのを利用しています。
import re
import pandas as pd
info = []
df = pd.read_csv('data/jarujaru_data.csv')
for row, item in df.iterrows():
if '『' in item['title']:
title = 'x' + item['title']
title = re.split('[『』]', title)[1]
if item['viewCount'] >= 250000:
label = 2
elif 100000 <= item['viewCount'] < 250000:
label = 1
elif item['viewCount'] < 100000:
label = 0
info.extend([[title, item['viewCount'], item['likeCount'], item['dislikeCount'], item['commentCount'], label]])
pd.DataFrame(info, columns=['title', 'viewCount', 'likeCount', 'dislikeCount', 'commentCount', 'label']).to_csv('data/jarujaru_norm.csv')
形態素解など
こちら4の記事を参考にコントのタイトルを形態素解析し、タイトルを特徴ベクトル(Bag-of-words形式)に変換していきます。以下はコードの一部です。全実装はGitHub5に載せておきます。
import analysis #自作のコード、GitHubに載せておきます。
import pandas as pd
from gensim import corpora
from gensim import matutils
def vec2dense(vec, num_terms):
return list(matutils.corpus2dense([vec], num_terms=num_terms).T[0])
df = pd.read_csv('data/jarujaru_norm.csv')
words = analysis.get_words(df['title']) #ここに形態素解析されたタイトル入る
# 辞書を作る
dictionary = corpora.Dictionary(words)
dictionary.filter_extremes(no_below=2, keep_tokens=['チャラ','男','番長'])
dictionary.save('data/jarujaru.dict')
courpus = [dictionary.doc2bow(word) for word in words]
# Bag-of-words形式に変換
data_all = [vec2dense(dictionary.doc2bow(words[i]),len(dictionary)) for i in range(len(words))]
モデルの学習
今回はデータ数が少ないためモデルにSVMを採用しました。データを学習データとテストデータに分けてモデルに突っ込みます。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# トレーニング・テストデータの設定
train_data = data_all
X_train, X_test, y_train, y_test = train_test_split(train_data, df['label'], test_size=0.2, random_state=1)
# データの標準化
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
# 学習モデルの作成
clf = SVC(C = 1, kernel = 'rbf')
clf.fit(X_train_std, y_train)
import pickle
with open('data/model.pickle', mode='wb') as fp:
pickle.dump(clf, fp)
モデルの評価をしてみます。
score = clf.score(X_test_std, y_test)
print("{:.3g}".format(score))
predicted = clf.predict(X_test_std)
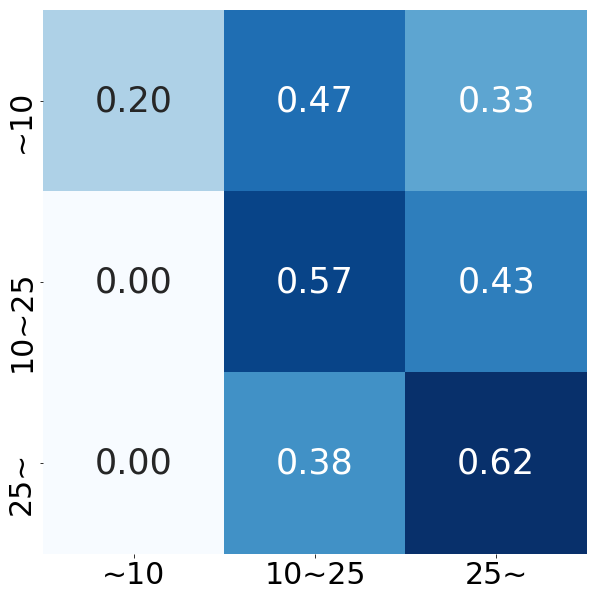
精度は53%でした。当てずっぽうで33%なので一応学習はできてる(ひどいけど)。混同行列もみてみます。ほとんどの動画が10万再生以上と予測してしまうガバガバモデルになっているようです。
終わりに
今回はジャルジャルの動画のタイトルから再生回数を予測するモデルを作ってみました。NLP素人なので、文章のベクトル化などわからないことだらけでしたが一応最後までモデルを作ることができました。全実装はGitHub5に載せておきます。次回はこのモデルを使って「ジャルジャルの動画が投稿されたら見る価値があるかどうかを通知してくれるLINEbot」を開発しようと思います。また、文章のベクトル化の手法や時系列データを扱うモデル(LSTMなど)についても勉強していきたいです。