1 この記事は
Pandas ,pythonの各種操作方法をメモする。
| 題名 | リンク |
|---|---|
| 【python】Pandasの使い方 | LINK |
| 【python】Pandas2の使い方 | LINK |
| 【python】Pandas3の使い方 | LINK |
| 【python】Pandas4の使い方 | LINK |
| 【python】Pandas5の使い方 | LINK |
| 【python】Pandas ,pythonコードメモ 6 | LINK |
2 内容
2-1 getattr クラスのメソッドを呼び出す
sample.py
class MyClass:
def __init__(self):
print("Test of getattr")
def add(self, x, y):
return x + y
def sub(self, x, y):
return x - y
def mult(self, x, y):
return x * y
def divs(self, x, y):
return x / y
myclass = MyClass()
x = 6
y = 2
result = getattr(myclass, 'add')(x, y)
print("addの演算結果:", result)
result = getattr(myclass, 'sub')(x, y)
print("subの演算結果:", result)
result = getattr(myclass, 'mult')(x, y)
print("multの演算結果:", result)
result = getattr(myclass, 'divs')(x, y)
print("divsの演算結果:", result)
実行結果
Test of getattr
addの演算結果: 8
subの演算結果: 4
multの演算結果: 12
divsの演算結果: 3.0
2-2 xs Dataframeから指定したデータを取り出す
sample.py
import pandas as pd
import numpy as np
dat0 = [
["A0","B0","C0",98,90],
["A0","B0","C1",449,11],
["A0","B1","C2",39,17],
["A0","B1","C3",75,71],
["A1","B2","C0", 1,89],
["A1","B2","C1",54,60],
["A1","B3","C2",476,8],
["A1","B3","C3",165,3],
["A2","B0","C0", 75,22],
["A2","B0","C1",194,45],
["A2","B1","C2", 25,52],
["A2","B1","C3", 57,40],
["A3","B2","C0", 64,54],
["A3","B2","C1", 27,96],
["A3","B3","C2",100,77],
["A3","B3","C3", 22,50],
]
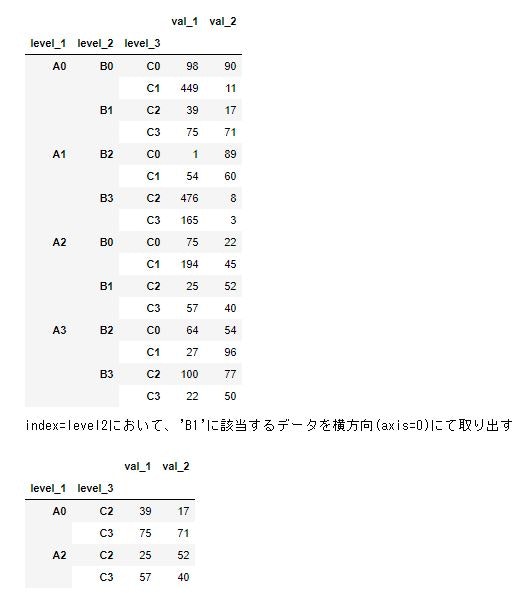
df0 = pd.DataFrame(dat0,columns=["level_1","level_2","level_3","val_1","val_2"])
df0=df0.set_index(["level_1","level_2","level_3"])
display(df0)
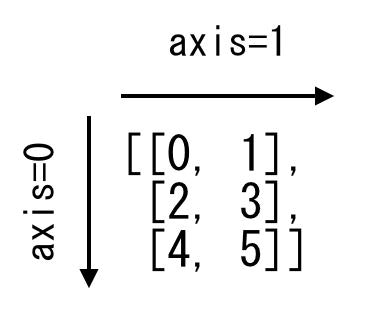
print("index=level2において、'B1'に該当するデータを横方向(axis=0)にて取り出す")
display(df0.xs('B1', axis=0, level="level_2"))
実行結果
参考情報 axis
2-3本日の日付を取得する。year,monthなどを取り出す
sample.py
import datetime
print("本日の日付時刻を取得する")
dt_now = datetime.datetime.today()
print(dt_now)
print("日付から年を取り出す")
print(dt_now.year)
print("日付から月を取り出す")
print(dt_now.month)
print("日付から日を取り出す")
print(dt_now.day)
print("日付から年を取り出す")
print(dt_now.year)
print("日付からhourを取り出す")
print(dt_now.hour)
print("日付からminutesを取り出す")
print(dt_now.minute)
print("日付からsecondを取り出す")
print(dt_now.second)
print("本日の日付のみを取り出す")
print(datetime.date.today() )
実行結果
本日の日付時刻を取得する
2021-07-14 20:28:45.888535
日付から年を取り出す
2021
日付から月を取り出す
7
日付から日を取り出す
14
日付から年を取り出す
2021
日付からhourを取り出す
20
日付からminutesを取り出す
28
日付からsecondを取り出す
45
本日の日付のみを取り出す
2021-07-14
2-4 日付でデータを抽出する。(日付にTimezoneを付加する)
sample.py
#dataを定義する。
import pandas as pd
import datetime
import pytz
dat = [
['2019-07-01',2,7,0,0],
['2019-07-02',4,77,0,0],
['2019-07-03',8,8,0,0],
['2019-07-04',16,89,0,0],
['2020-07-05',100,9,0,0],
['2019-07-06',200,99,0,0],
['2019-07-07',400,123,0,0],
['2019-07-08',200,345,0,0],
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["T","B","C","D","E"])
df['T'] = pd.to_datetime(df['T'], format='%Y-%m-%d') #文字列型を日付型に変更する
jp = pytz.timezone('Asia/Tokyo') #TimezoneをTokyoに設定するモジュールを定義する。
df['T']=df['T'].apply(lambda x:x.tz_localize('Asia/Tokyo')) #日付にTimezoneを付加する
df=df.set_index("T")
print("抽出前データ")
display(df)
print("抽出後データ")
display(df[df.index>jp.localize(datetime.datetime(2019,7,4))]) #日付が2019/7/4以降ので
実行結果
抽出前データ
B C D E
T
2019-07-01 00:00:00+09:00 2 7 0 0
2019-07-02 00:00:00+09:00 4 77 0 0
2019-07-03 00:00:00+09:00 8 8 0 0
2019-07-04 00:00:00+09:00 16 89 0 0
2020-07-05 00:00:00+09:00 100 9 0 0
2019-07-06 00:00:00+09:00 200 99 0 0
2019-07-07 00:00:00+09:00 400 123 0 0
2019-07-08 00:00:00+09:00 200 345 0 0
抽出後データ
B C D E
T
2020-07-05 00:00:00+09:00 100 9 0 0
2019-07-06 00:00:00+09:00 200 99 0 0
2019-07-07 00:00:00+09:00 400 123 0 0
2019-07-08 00:00:00+09:00 200 345 0 0
2-5 列の数値型をfloat型からint型に変更する
sample.py
import pandas as pd
df = pd.DataFrame(
data={
'a': [1, 4, 9, 16, 25],
'b': [2.4, 5.1, 10.3, 17.9, 26.0],
'c': [0, 1, np.nan, 2, None],
'd': [True, True, False, False, True],
})
display(df)
print("列bをfloat型からint型に変更する")
df['b']=df['b'].astype('int')
display(df)
実行結果
a b c d
0 1 2.4 0.0 True
1 4 5.1 1.0 True
2 9 10.3 NaN False
3 16 17.9 2.0 False
4 25 26.0 NaN True
列bをfloat型からint型に変更する
a b c d
0 1 2 0.0 True
1 4 5 1.0 True
2 9 10 NaN False
3 16 17 2.0 False
4 25 26 NaN True
2-6 各indexごとにrolling(x).mean()の演算を実施する。 ->groupby
sample.py
import pandas as pd
import numpy as np
import scipy.stats
idx = pd.IndexSlice
#dataを定義する。
dat = [
[100,'2019-07-01',2,7],
[100,'2019-07-02',4,77],
[100,'2019-07-01',8,8],
[100,'2019-07-02',16,89],
[200,'2019-07-03',100,9],
[200,'2019-07-01',200,99],
[200,'2019-07-01',400,123],
[200,'2019-07-01',200,345],
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["A","B","C","D"])
#A,B列をindexに指定する。
df=df.set_index(["A","B"])
print("df",df)
df["E"]=df.groupby(["A"]).rolling(2)["C"].mean().values
print("D列において各indexごとにrolling(x).mean演算を実施する")
df
実行結果
df C D
A B
100 2019-07-01 2 7
2019-07-02 4 77
2019-07-01 8 8
2019-07-02 16 89
200 2019-07-03 100 9
2019-07-01 200 99
2019-07-01 400 123
2019-07-01 200 345
D列において各indexごとにrolling(x).mean演算を実施する
C D E
A B
100 2019-07-01 2 7 NaN
2019-07-02 4 77 3.0
2019-07-01 8 8 6.0
2019-07-02 16 89 12.0
200 2019-07-03 100 9 NaN
2019-07-01 200 99 150.0
2019-07-01 400 123 300.0
2019-07-01 200 345 300.0
2-7 Multiindexの特定のindexを取り出す。
xxx.index.get_level_values(level=xx)を使う
sample.py
import pandas as pd
import numpy as np
dat=[
[1570,"2021/7/5",15650,15670,15490,15520,2],
[1570,"2021/7/6",15620,15690,15500,15560,1],
[1570,"2021/7/7",15050,15340,15030,15260,4],
[1570,"2021/7/8",15200,15280,14990,15020,-2],
[1570,"2021/7/9",14620,14880,14240,14850,3],
[1570,"2021/7/12",15440,15500,15360,15460,-5],
[1570,"2021/7/13",15630,15780,15610,15640,1],
[1570,"2021/7/14",15410,15610,15370,15510,3],
[1570,"2021/7/15",15430,15480,15120,15160,9],
[1570,"2021/7/16",14840,15090,14700,14890,2],
[1570,"2021/7/19",14500,14650,14320,14470,5],
[1570,"2021/7/20",14200,14400,14140,14220,0],
[1570,"2021/7/21",14610,14730,14260,14380,2],
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["Code","Date","Open","High","Low","Close","DUMMY"])
df['Date'] = pd.to_datetime(df['Date'], format='%Y/%m/%d') #文字列型を日付型に変更する
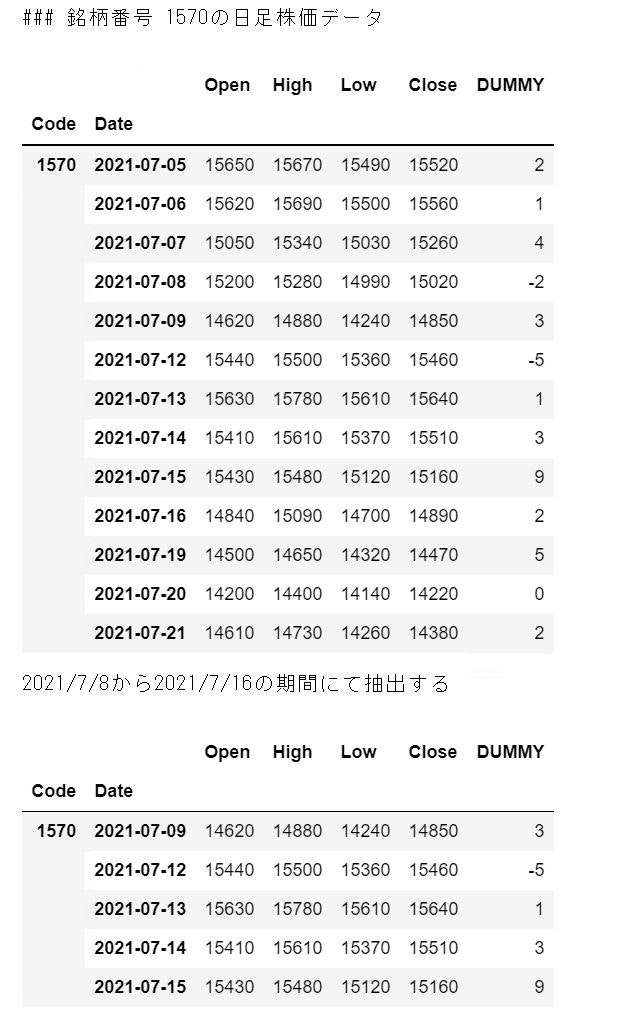
print("### 銘柄番号 1570の日足株価データ")
df=df.set_index(['Code','Date'])
display(df)
XLIMD=datetime.datetime(2021,7,8) #横軸開始日
XLIMU=datetime.datetime(2021,7,16) #横軸終了日
df0=df[ (df.index.get_level_values(level=1) > XLIMD) & (df.index.get_level_values(level=1) < XLIMU)]
print("2021/7/8から2021/7/16の期間にて抽出する")
display(df0)
実行結果
2-8 DataFrameから指定したindexの行を抽出する。
sample.py
#DataFrameから指定したindexの行を抽出する。
import pandas as pd
dat1 = [
['2019-07-02','9997','769'],
['2019-07-02','1','2'],
['2019-07-05','3','4'],
['2019-07-06','3','4']
]
df1 = pd.DataFrame(dat1,columns=["A","B","C"])
df1=df1.set_index(["A"])
display(df1)
SELINDEX=['2019-07-02','2019-07-06'] #抽出するINDEX名を設定する。
df1.loc[SELINDEX,:]
実行結果
B C
A
2019-07-02 9997 769
2019-07-02 1 2
2019-07-05 3 4
2019-07-06 3 4
Index(['2019-07-02', '2019-07-02', '2019-07-05', '2019-07-06'], dtype='object', name='A')
B C
A
2019-07-02 9997 769
2019-07-02 1 2
2019-07-02 9997 769
2019-07-02 1 2
2019-07-05 3 4
2019-07-06 3 4
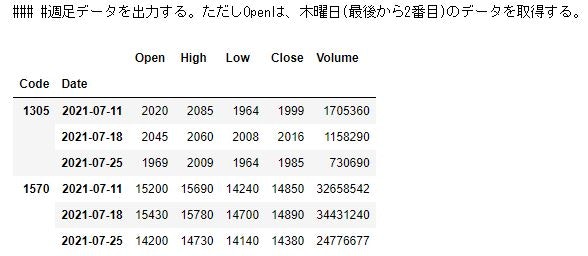
2-9 週単位で指定したデータを取り出す。(例えばlastのデータではなく2nd lastのデータを取り出す)
sample.py
import pandas as pd
import numpy as np
dat=[
[1570,"2021/7/5",15650,15670,15490,15520,3315590],
[1570,"2021/7/6",15620,15690,15500,15560,3165551],
[1570,"2021/7/7",15050,15340,15030,15260,6047534],
[1570,"2021/7/8",15200,15280,14990,15020,4927900],
[1570,"2021/7/9",14620,14880,14240,14850,15201967],
[1570,"2021/7/12",15440,15500,15360,15460,8908945],
[1570,"2021/7/13",15630,15780,15610,15640,6024571],
[1570,"2021/7/14",15410,15610,15370,15510,4788303],
[1570,"2021/7/15",15430,15480,15120,15160,6687459],
[1570,"2021/7/16",14840,15090,14700,14890,8021962],
[1570,"2021/7/19",14500,14650,14320,14470,8402245],
[1570,"2021/7/20",14200,14400,14140,14220,8901150],
[1570,"2021/7/21",14610,14730,14260,14380,7473282],
[1305,"2021/7/5",2073,2076,2066,2074,155700],
[1305,"2021/7/6",2080,2085,2072,2078,188890],
[1305,"2021/7/7",2054,2070,2047,2058,740510],
[1305,"2021/7/8",2020,2024,2007,2007,216620],
[1305,"2021/7/9",1976,2004,1964,1999,403640],
[1305,"2021/7/12",2035,2042,2028,2036,208860],
[1305,"2021/7/13",2049,2060,2048,2051,655740],
[1305,"2021/7/14",2041,2056,2038,2047,83270],
[1305,"2021/7/15",2045,2045,2021,2022,132610],
[1305,"2021/7/16",2014,2027,2008,2016,77810],
[1305,"2021/7/19",1995,2001,1981,1991,162720],
[1305,"2021/7/20",1969,1981,1964,1970,476450],
[1305,"2021/7/21",2000,2009,1983,1985,91520]
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["Code","Date","Open","High","Low","Close","Volume"])
df['Date'] = pd.to_datetime(df['Date'], format='%Y/%m/%d') #文字列型を日付型に変更する
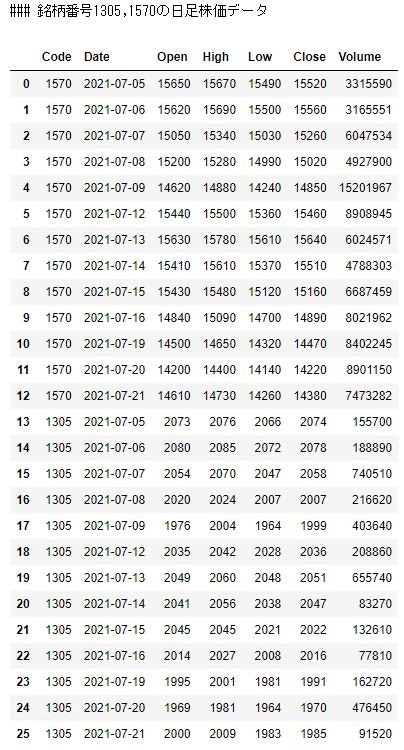
print("### 銘柄番号1305,1570の日足株価データ")
display(df)
def myfunc(x,n):
tmp=x
return tmp.values[-n]
d_ohlcv = {'Open':lambda s: myfunc(s,2),'High': 'max','Low': 'min','Close': 'last','Volume': 'sum'}
df_stock = df.groupby(['Code', pd.Grouper(freq='W', key='Date')]).agg(d_ohlcv) #株価データ(週足)を取得する。
print("#### 銘柄番号1305,1570の週足株価データ")
display(df_stock)
実行結果
2-10 list型配列の要素をn分位分割し、各要素がどの分位に入っているかを算出する
sample.py
import pandas as pd
import numpy as np
#example for .qcut(df.Target, 30).cat.codes
ages = [19, 20, 21, 22, 29, 29, 34, 38, 41, 58]
cats = pd.qcut(ages, 2) #qcut(list,s)はlist型配列listをs分位分割する。
print("### cats ###")
print(cats)
print("### cats.codes ###")
print(cats.codes)
実行結果
print("### cats ###")
[(18.999, 29.0], (18.999, 29.0], (18.999, 29.0], (18.999, 29.0], (18.999, 29.0], (18.999, 29.0], (29.0, 58.0], (29.0, 58.0], (29.0, 58.0], (29.0, 58.0]]
Categories (2, interval[float64, right]): [(18.999, 29.0] < (29.0, 58.0]]
print("### cats.codes ###")
[0 0 0 0 0 0 1 1 1 1]