はじめに
手のポーズを使って人が簡単にゲーム(gym環境)を操作できるコントローラを作成しました。保存したプレイデータは以下の模倣学習や逆強化学習に使用することができます。
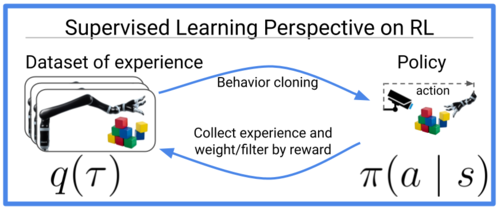
完成したもの
本コントローラを使うと、手のポーズを使って複数の連続値をリアルタイムで入力することができます。
左が強化学習の環境、真ん中が認識結果、右が3次元座標上にプロットした手です。


Githubにコードを公開しています。
人とマシンのインターフェイス
人とマシンのインターフェイスには、連続値と離散値を扱うものがあります。例えばプレイステーションのコントローラでは、連続値の入力にはジョイスティックを、離散値の入力にはボタンを使用しています。車のアクセルやハンドルは連続値の入力です。連続値の場合は入力で微妙な強弱を表現できますが、離散値の場合は0か1だけ、ONかOFFだけの情報になります。
そして、例えば以下のようなDeepmind Control Suiteと呼ばれる環境の操作には多くの連続値の入力が必要となります。そこで、簡単に複数の連続値入力を扱えるように手のポーズを利用します。このコントローラでは、USBカメラで撮影した手のポーズ(各関節の角度)とキーボードを入力として使えます。

構成
手のポーズ認識とキーボードで押されたボタンの認識はそれぞれ別プロセスで処理するようにしてリアルタイム性を担向上させています。マルチプロセス処理には、multiprocessingを、プロセス間通信にはmultiprocessingで提供されている共有メモリ(Array)を使用しました。
また、それぞれの認識結果はopenai gymのWrapper内で、環境に適応させるようにしてコードを再利用しやすいように実装しています。現状はgymのインターフェイスしか用意していませんが、他の環境も需要があれば追加するので、その場合はGithubレポジトリのIssueにコメントをお願いします。
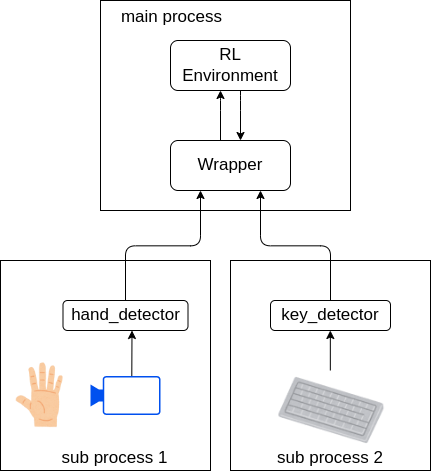
関節角度の計測
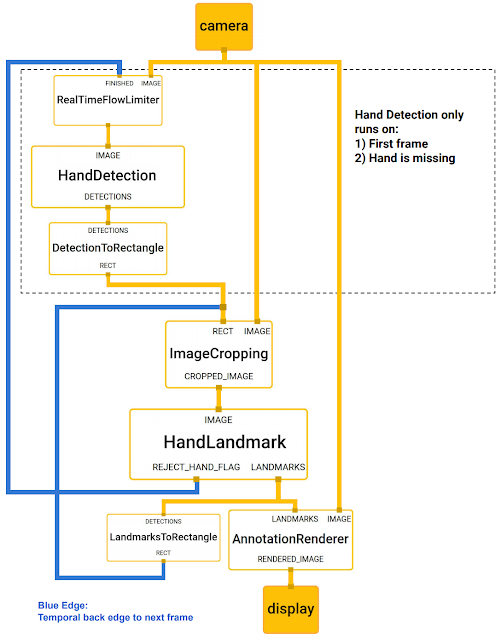
ハンドの認識にはgoogleで開発されたmediapipeを使用しています。
以下のシステム図に書かれているように、手を検出するモデルは毎回実行されているのではなく、最初の1回と手を見失った時だけ実行されるようになっています。そして、それ以外のときには後続で検出される手のランドマーク(関節部)から手の位置を推定して、画像をクロップします。手を見失ったという判定は、ランドマークを検出するネットワークから出力される信頼度に基づいて行われます。このように処理が重い手を検出する部分の実行回数を減らすことで、高速に動作するアルゴリズムを実現しています。
キーボードで押されたキーの認識
スイッチのONとOFFだけの操作など、連続値の入力だけでは扱いにくい環境もあるため、キーボードの入力も扱えるようにしました。pynputを使うことで、非同期処理でキーボード入力を受け取ることができます。これにより、キーボードが押された瞬間と離された瞬間を見張っておき、共有メモリの値を書き換えるという処理を行いました。
最後に
最後まで読んでいただいてありがとうございました。
コードを公開しているので、興味のある方はぜひ自身の環境で試してみて下さい。
参考
敵対的模倣学習の紹介
ML-Agentsで模倣学習(GAIL)を取り入れた強化学習を行う
論文紹介:ドメイン適応模倣学習(前編)