前回は、時間軸に向けての合成をやったが、今回は複数の音声(というか音)を重ね合わせする。Superimposeというやつだ。
とりあえずの目標
以下のとおり、
※リンクされているものは記事にしたものであり、その記事を前提知識として書いて行くので、参照すると理解し易いと思います。
①Scipy環境を作る
・環境の確認
②不確定原理について
・FFT変換・逆変換してみる;時間軸が消える
・STFT変換・逆変換してみる;窓関数について
・wavelet変換・逆変換してみる;スペクトログラムの解釈と不確定原理
③音声や地震データや株価や、。。。とにかく一次元の実時系列データに応用する
音声データ入力編
④FFTからwavelet変換まで簡単にたどってみる(上記以外のちょっと理論)
⑤二次元データに応用してみる
⑥天体観測データに応用してみる
⑦リアルタイムにスペクトログラムしてみる
高速化(バグあり)
高速化完成版
音声分離アプリ
音声合成アプリ
やったこと
・二つの音声を大きさを変えて重ね合わせする
・コード解説
・二つの音声を大きさを変えて重ね合わせする
二つの音声を重ね合わせできれば、複数の音を重ね合わせに拡張するのは容易である。
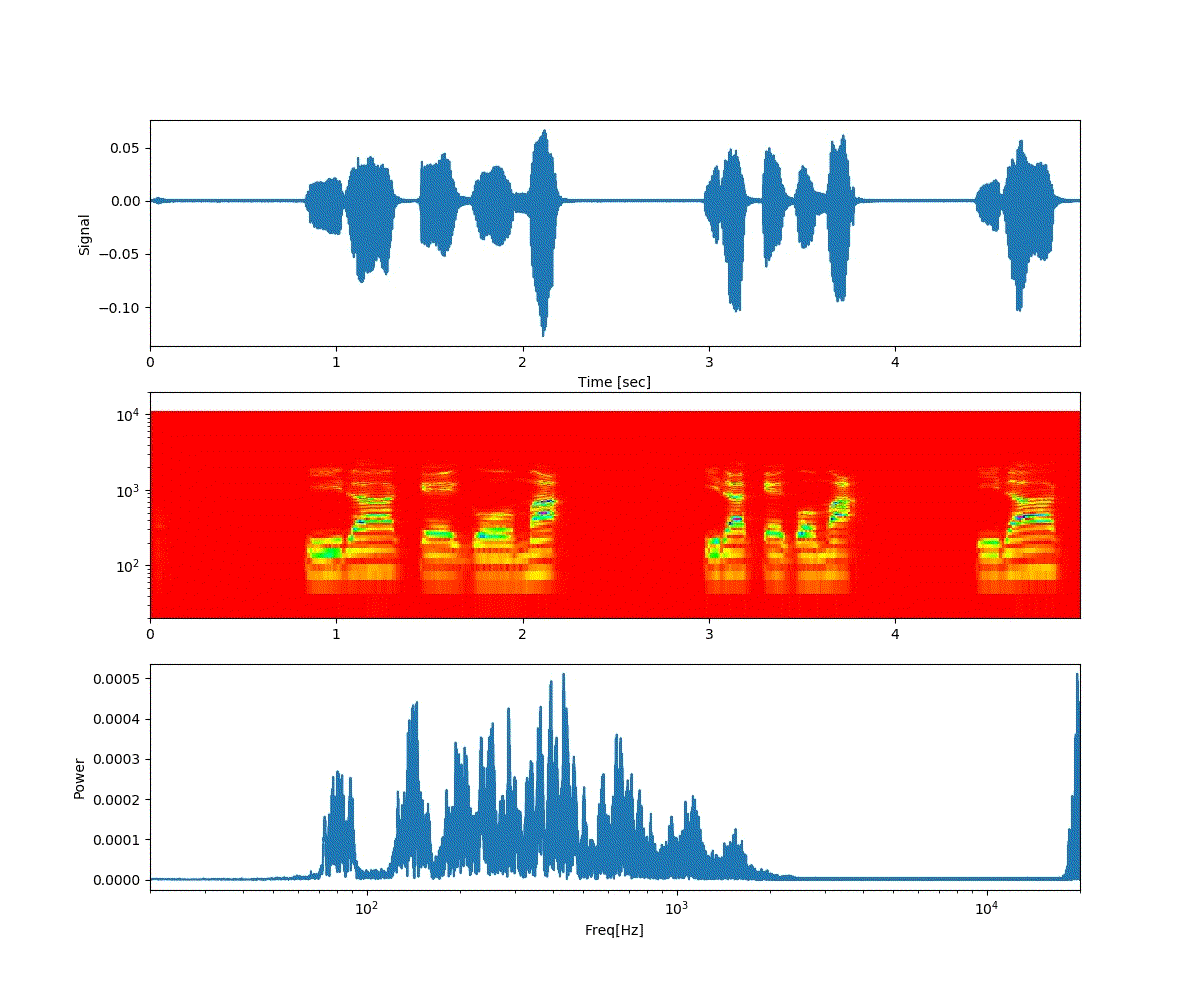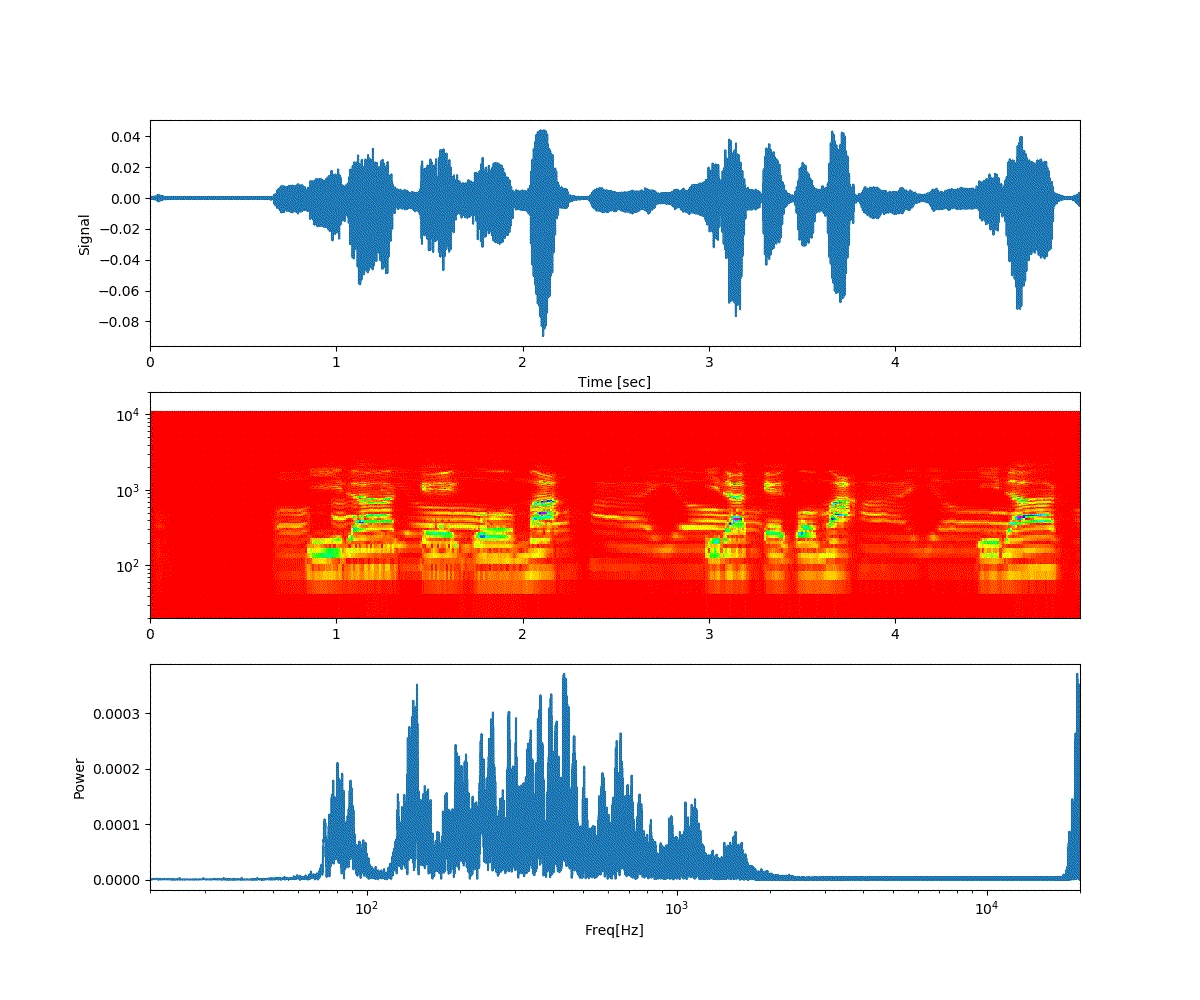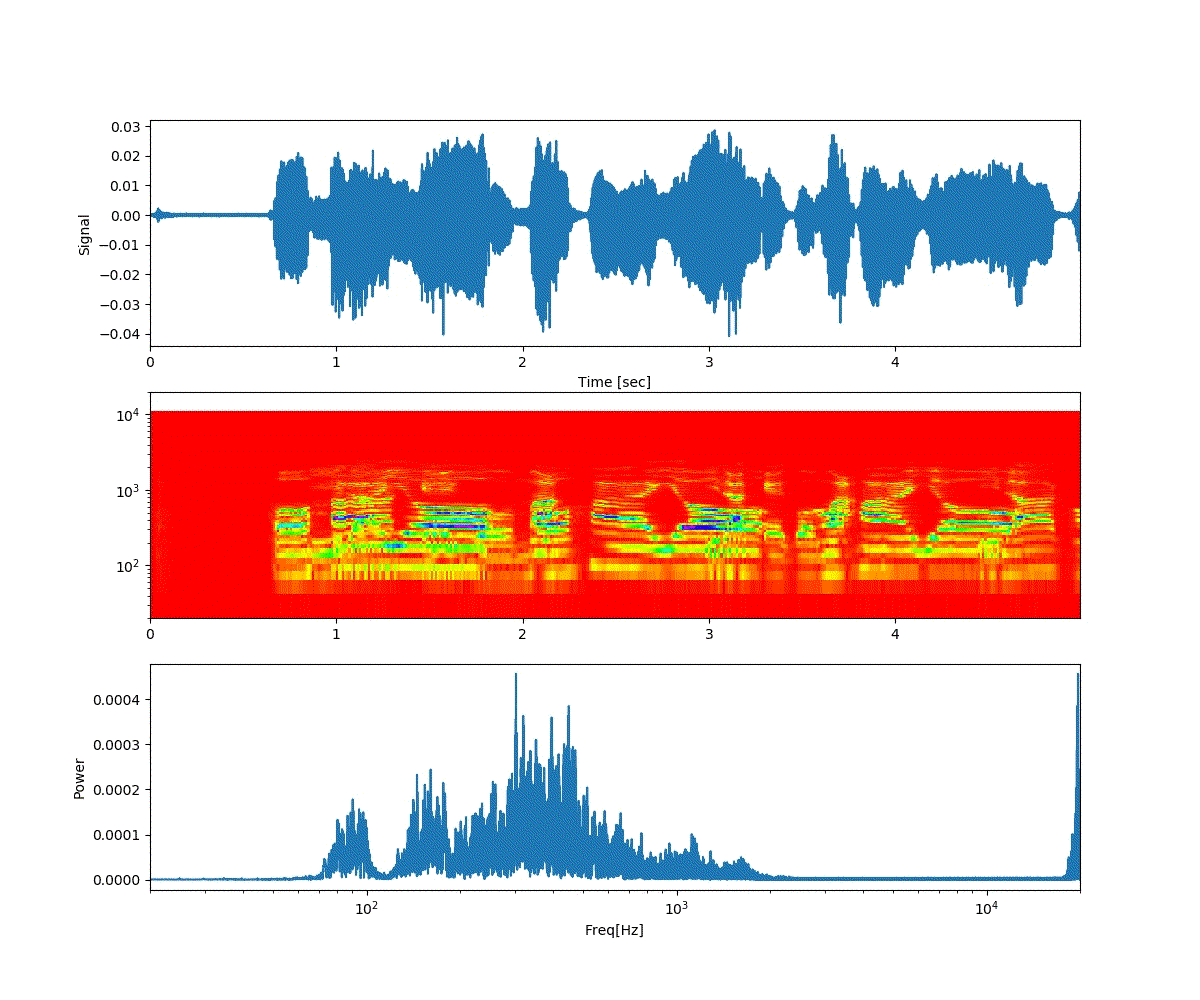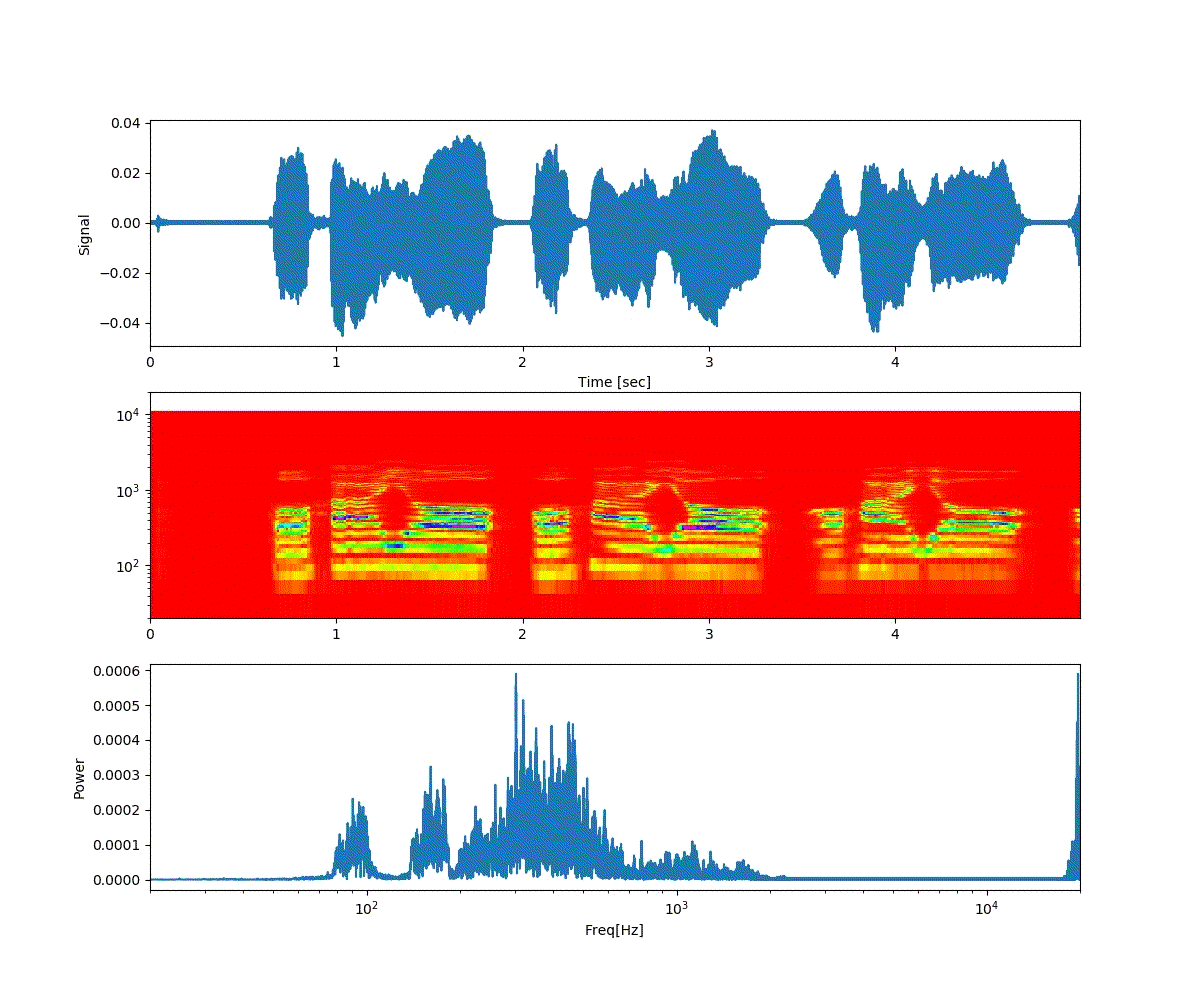
ここでは、「おはよう」と「開けゴマ」を重ね合わせた。
以下は「おはよう」から徐々に「開けゴマ」に音声が変化する。
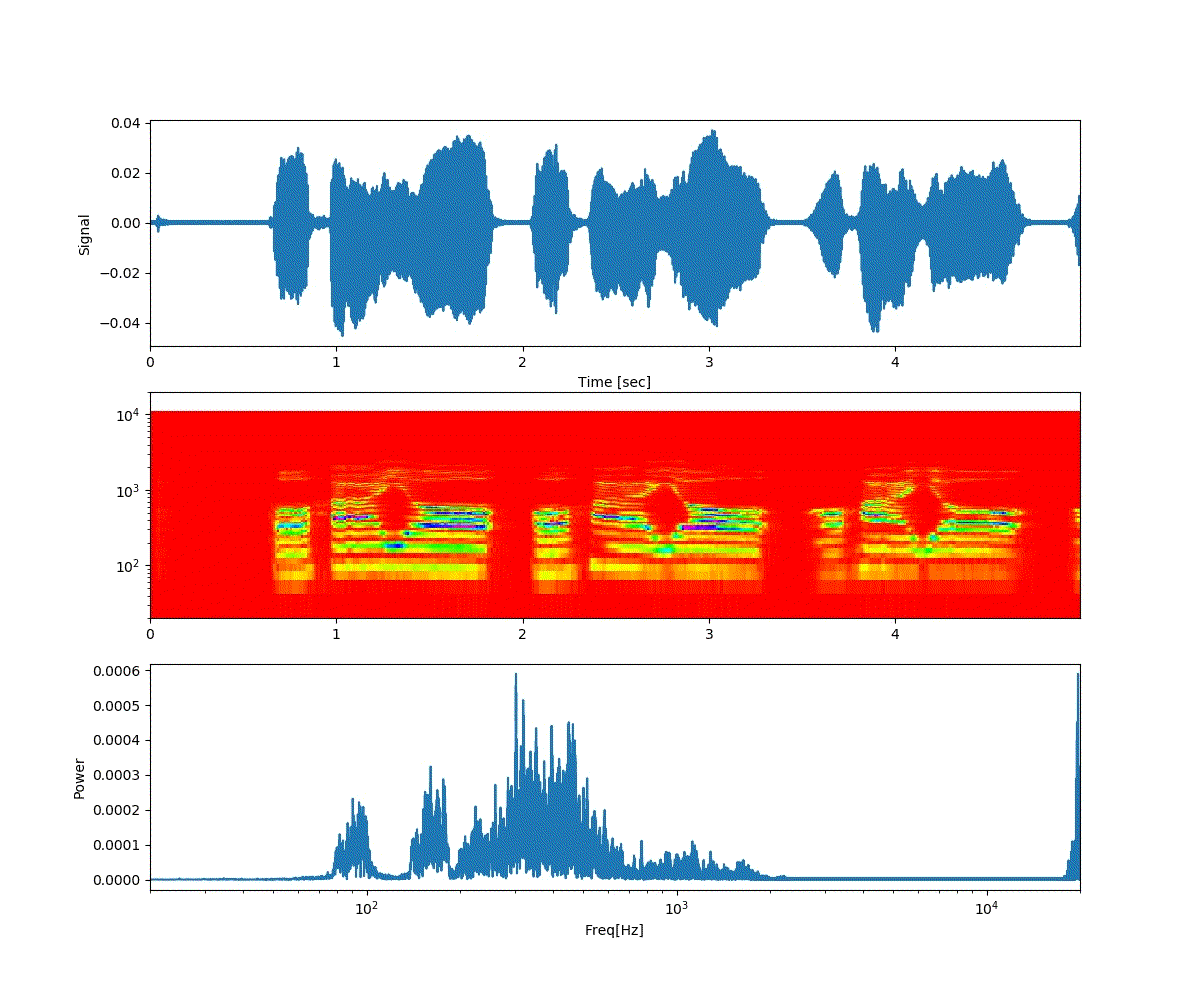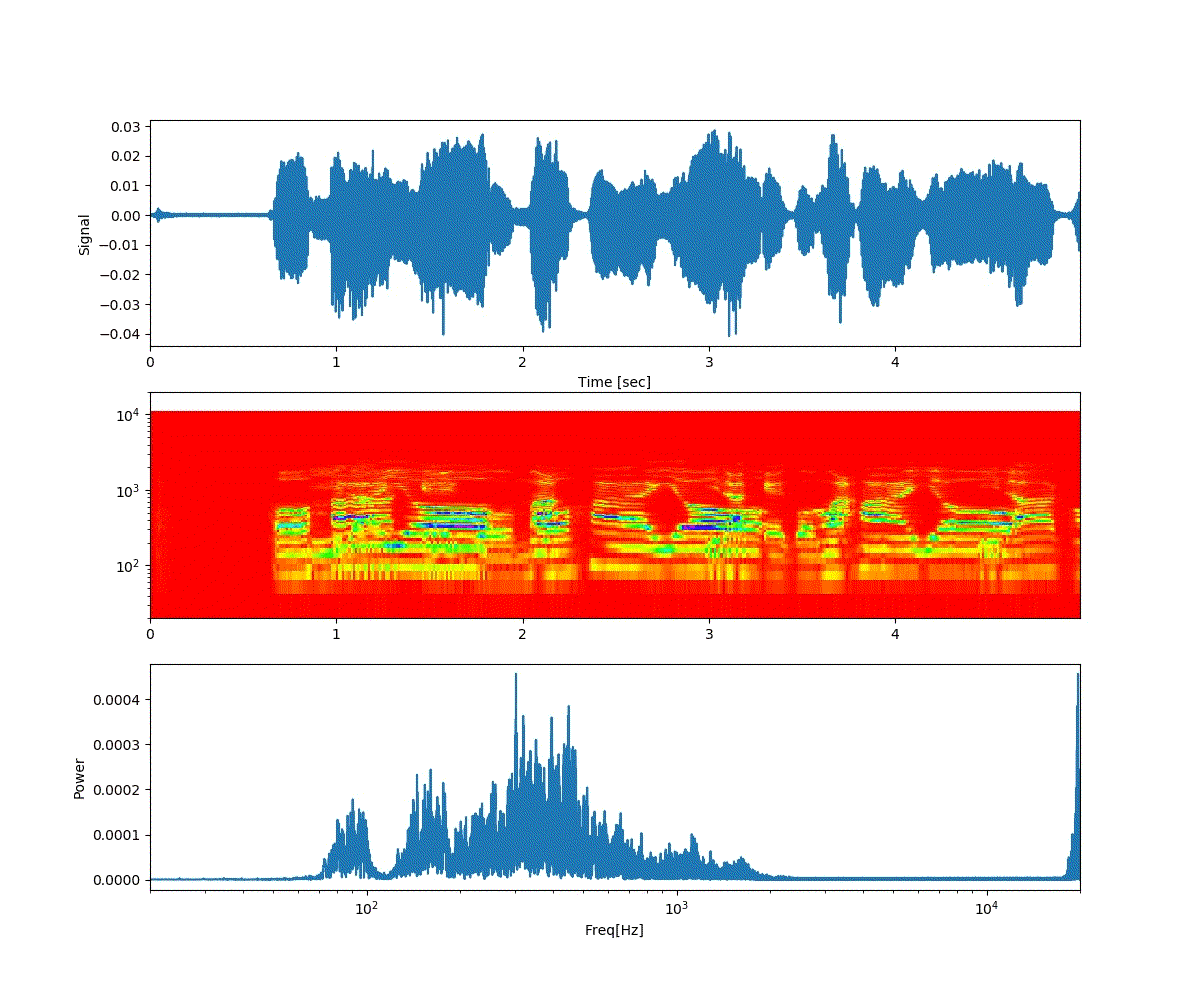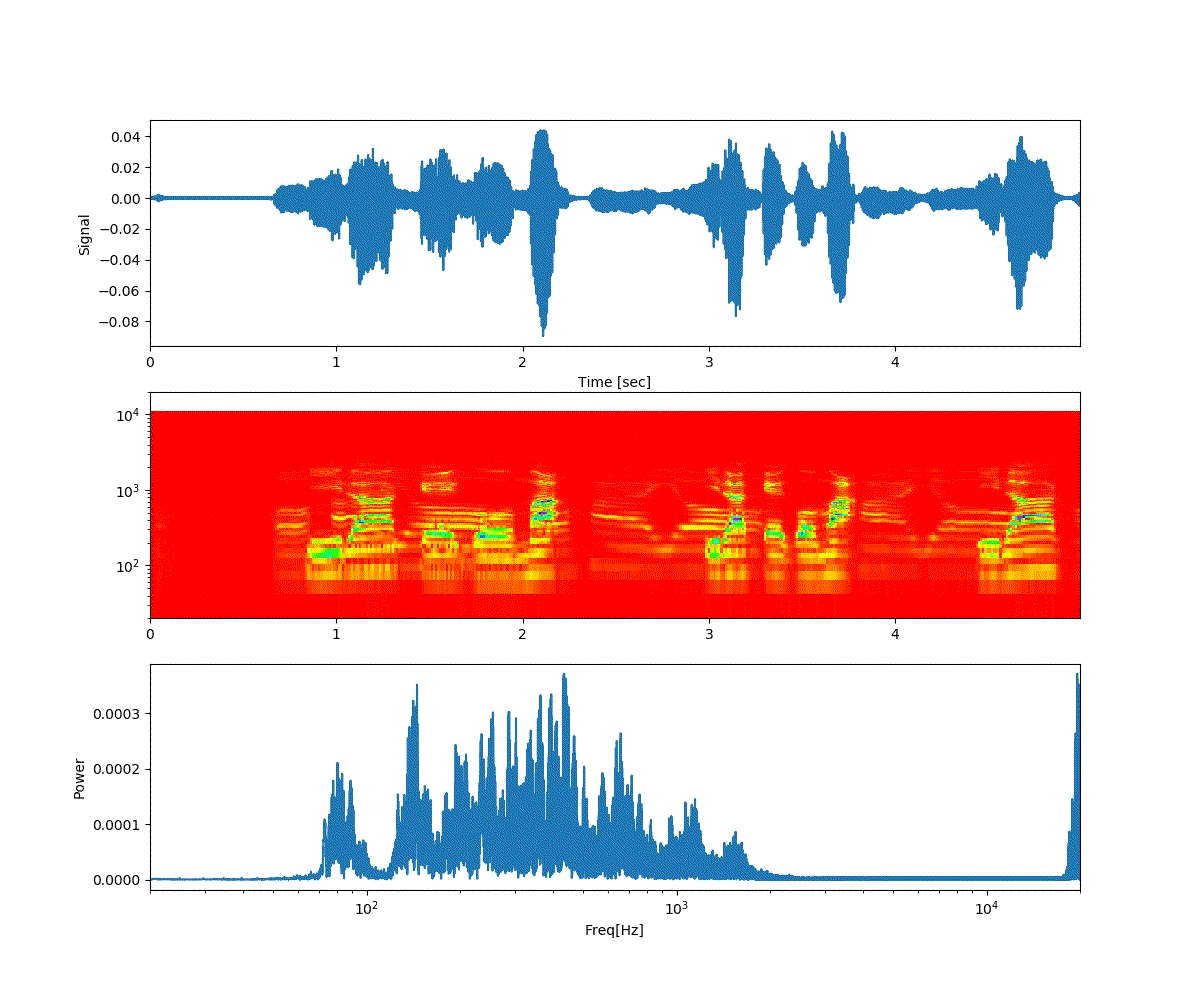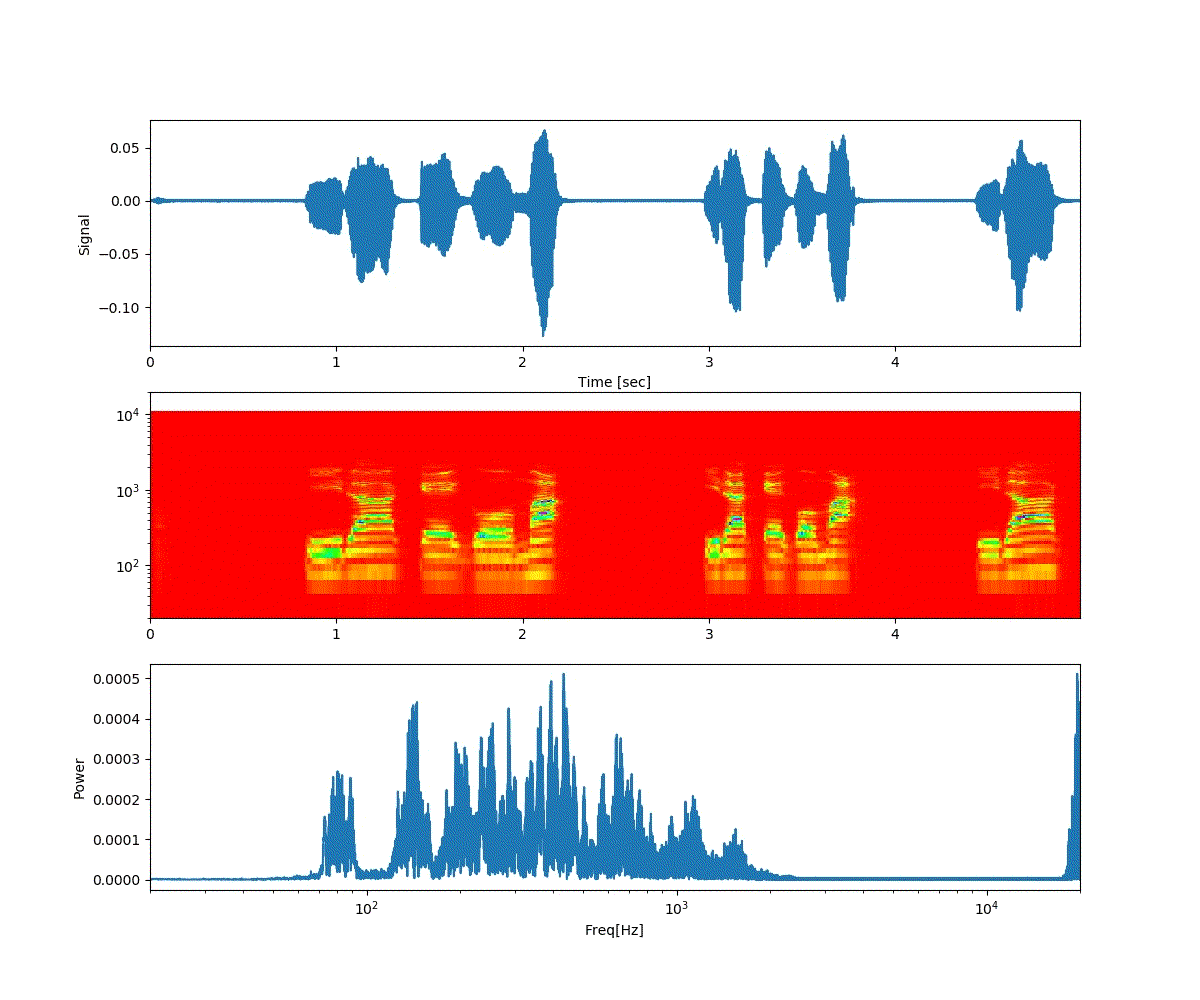
以下は、「開けゴマ」から徐々に「おはよう」に音声が変化する。
・コード解説
コードは、前回とほぼ同じなので、主な変更箇所を記載する。
※全体はリンクを見てほしい。
最初に2つの音声ファイルを読み込む。
if __name__ == '__main__':
filename1=input('input original filename=')
filename2=input('input original filename=')
だんだん二つのWavファイルの割合を変更してその変化を見たいので、while True:で連続することとした。
そして、加算する前に重畳する比率を入力することとした。
while True:
wf1,stream1,fr1,fn1,fs1,width1,CHANNELS1 = fileOpen(filename1)
wf2,stream2,fr2,fn2,fs2,width2,CHANNELS2 = fileOpen(filename2)
fc1=int(input('input factor1='))
fc2=int(input('input factor2='))
加算は同一のfor文内で以下のとおり実施する。
frames = []
for i in range(0, int(fr1 / 1024 *fs1+0.5)):
data1 = wf1.readframes(1024)
data2 = wf2.readframes(1024)
g1 = fc1*np.frombuffer(data1, dtype= "int16") #/32768.0 # -1~1に正規化 #g1は演算できる
g2 = fc2*np.frombuffer(data2, dtype= "int16") #/32768.0 # -1~1に正規化 #g1は演算できる
frames.append(g1+g2)
stream1.write(g1+g2)
以下は、合成したwavファイルを出力する。ここでは加算因子をファイル名に記載することとした。
loff1 = wf1.getnframes()/1024 #215 #len(frames)
loff2 = wf2.getnframes()/1024 #215 #len(frames)
wr = wave.open('wav/'+str(fc1)+filename1+str(fc2)+filename2+'_out.wav', 'wb')
wr.setnchannels(CHANNELS2)
wr.setsampwidth(width2) #width=2 ; 16bit
wr.setframerate(fr2)
s=int((loff1+loff2)*(fs1+fs2)/(fs1+fs2))
wr.writeframes(b''.join(frames[0:s]))
#wr.close()
最後に、合成データ、STFT、そしてFFT画像を出力して、While文に戻る。
fn = wr.getnframes()
fs = float(fn / wr.getframerate())
print(fn,fs)
plot_wav('wav/'+str(fc1)+filename1+str(fc2)+filename2+'_out',0,fs)
ということで、上記のような連続画像が得られた。
予想通り、音声が徐々に変化した。
例えば、このアプリを利用すると、ノイズの効果なども検証可能である。
まとめ
・音声を重畳するアプリを作成した
・「おはよう」と「開けゴマ」を重畳した
・徐々に音声が変化する様子を観察できた
なお、重畳した音声のwavデータは以下に置いた
Scipy-Swan/data/
これはIEでは再生できると思う。また、ダウンロードすれば再生できると思う。
・いよいよ次回は音声認識に挑戦。。。