こんにちは。(株)日立製作所のLumada Data Science Lab./社会システム事業部デジタルイノベーションセンタの本美です。普段は社会インフラのAIシステムの企画から試作、開発を推進する業務に従事しています。
近年IT技術の発展と浸透が進み、世の中のさまざまな情報からAIを活用したサービスが日々登場しています。AIを代表する深層学習の開発では大規模なデータを学習するため、GPUによる長時間の学習が必要となります。GPUを搭載したインスタンスの運用コストは比較的高価ですので、学習時間を短縮する技術は大変有益です。
今回、Tensorコアを活用して学習を高速化する実験をしましたので、共有いたします。
0.対象読者
学習を高速化させたいMLエンジニア
1.はじめに
一般的に最も使用されているGPUはNVIDIA社製です。特に、Volta世代以降の製品では、深層学習に特化したTensorコアを搭載しています。
例として、Tesla V100(PCIe)の演算スペックを掲載します。(引用データ: V100カタログ)
| GPU演算回路 | 演算精度 | 演算性能 | 備考 |
|---|---|---|---|
| CUDAコア | FP32 | 7 TFLOPS | TensorFlowやPyTorchの デフォルト動作 |
| Tensorコア | FP16/32混合 | 112 TFLOPS |
Tensorコアは通常のCUDAコアの16倍の演算性能を持っているようです。
もし学習時間を1/16に短縮できれば、大変すばらしいです。(実際はそうではない)
2.Tensorコアとは
TensorコアとはNVIDIA社が開発した深層学習に特化した演算回路です。1回のクロックで複数の演算を同時に実行することで、演算の高速化を実現します。
Tensor コアの基本情報についてはメーカ公式ページ(Tensor-cores | NVIDIA)をご参照ください。
サポートしている演算精度はGPUアーキテクチャによって異なります。
| アーキテクチャ | 代表GPU製品 | サポート演算精度 |
|---|---|---|
| Volta | Tesla V100 | FP16 |
| Tuning | Tesla T4 | FP16, INT8, INT4, INT1 |
| Ampere | A100 | FP64, TF32, BP16, FP16, INT8, INT4, INT1 |
3. Mixed Precision
Tensorコアを活用した学習演算にMixed Precisionという手法があります。
16bit演算と32bit演算を組み合わせて学習することに由来しています。
Mixed Precisionの演算の流れは以下のように記述されます。
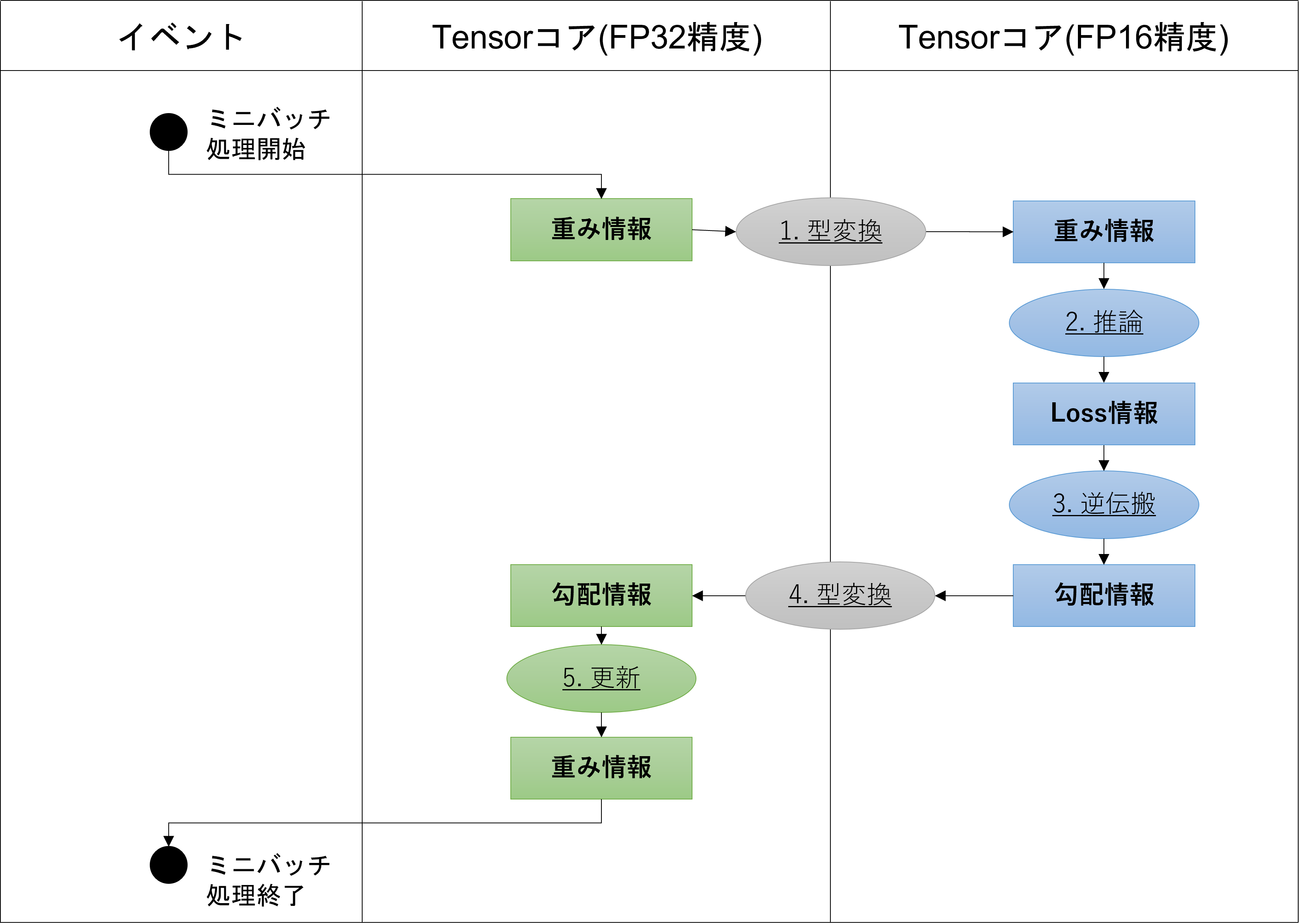
(GTC2018NVIDIA講演資料をもとに作成)
- FP16精度のモデルの重みに変換する。
- FP16精度でモデルの推論を計算し、損失関数を計算する。
- FP16精度で重みの勾配情報を計算する。
- FP16精度の重みの勾配情報をFP32精度にScaleする。
- FP32精度の重みを更新する。(1に戻る)
推論計算~損失計算~勾配計算をFP16で実行することで、学習の高速化を実現します。
また、Mix Precisionで学習したモデルの性能は従来のFP32演算(Single Precision)で学習したモデルと同等であると、NVIDIA開発チームが報告しています。
引用:Mixed-Precision Training of Deep Neural Networks | NVIDIA Developer Blog
Table 1. Top-1 accuracy on ILSVRC12 validation data.
| DNN Model | FP32 (CUDAコア) | Mixed Precision (Tensorコア) |
|---|---|---|
| AlexNet | 56.77% | 56.93% |
| VGG-D | 65.40% | 65.43% |
| GoogLeNet | 68.33% | 68.43% |
| Inception v1 | 70.03% | 70.02% |
| Resnet50 | 71.61% | 73.75% |
Table 2. Mean average precision (mAP) for object detection on PASCAL VOC 2007 test data
| DNN Model | FP32 (CUDAコア) | Mixed Precision (Tensorコア) |
|---|---|---|
| Faster R-CNN | 69.1% | 69.7% |
| Multibox SSD | 76.9% | 77.1% |
4.AWS EC2インスタンス
今回の実験は、誰でも容易に利用できるAmazon SageMakerのEC2インスタンスを利用します。
Amazon SageMakerで利用可能なGPUインスタンスの一覧は以下です。(2022/02/28現在)
| EC2 type | GPU | Single-Precision(FP32) | Mixed Precision (FP16/FP32) |
利用単価 (オンデマンド,東京) |
|---|---|---|---|---|
| P3 | Tesla V100 | 7.00 TFLOPS | 112 TFLOPS | (2xlarge) 5.252 USD/hr |
| G4 | Tesla T4 | 8.10 TFLOPS | 65 TFLOPS | (xlarge) 0.994 USD/hr |
P3は1USDあたり21TFLOPSの演算性能に対して、G4は1USD当たり65TFLOPSの演算性能で利用できるので、G4の方がコスパが良いです。
5. チュートリアルソースコード(Mixed Precision)
Mixed Precisionでの学習を実行するためのソースコードがPyTorchやTensorFlowの公式サイトで公開されています。
| フレームワーク | 公開サイト |
|---|---|
| PyTorch | AUTOMATIC MIXED PRECISION EXAMPLES |
| TensorFlow2/keras | 混合精度 |
PyTorchでの例
PyTorchでは2つのクラスを活用することで、Mixed Precisionでの学習を動作させることが可能です。
-
torch.cuda.amp.autocast: 推論の演算精度を自動で選択する -
torch.cuda.amp.Scaler: 勾配情報をスケーリングしてモデルの重みを更新する
サンプルコードに「★ポイント」を追記しています。
# (c) Copyright 2019, Torch Contributors.
from torch.cuda.amp import autocast, GradScaler
# モデル作成、オプティマイザ定義
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# GradScaler定義
scaler = GradScaler() # ★ポイント1: 勾配情報をスケールするためのScalerを定義する
# 学習実行
for epoch in epochs:
for input, target in data: # ミニバッチloop
# 勾配の初期化
optimizer.zero_grad()
# autocastを使った推論、損失計算
with autocast(): # ★ポイント2: モデルの演算精度を自動選択する
output = model(input)
loss = loss_fn(output, target)
# 損失計算のスケール化、逆誤差伝搬
scaler.scale(loss).backward() # ★ポイント3: スケール化されたlossのbackward関数を使用する
# オプティマイザのstep処理
scaler.step(optimizer) # ★ポイント4: optimizer.step()の代わりに、scaler.step()を使用する
# Scalerの更新
scaler.update() # ★ポイント5: scalerを更新する
TensorFlow2での例
TensorFlow2では、mixed_precisionのPolicyを設定することでMixed Precisionを有効化することができます。
model構築や学習、推論などの処理を変更せずに実行できるため、簡単に試行できます。
# (c) Copyright 2019 The TensorFlow Authors (Apache 2.0 License)
from tensorflow.keras.mixed_precision import experimental as mixed_precision
# ★ポイント: Policy設定 (Policyを設定するだけで、Mixed Precisionを有効化できる)
policy = mixed_precision.Policy('mixed_float16')
mixed_precision.set_policy(policy)
print('Compute dtype: %s' % policy.compute_dtype) # Compute dtype: float16 (演算時のデータ型)
print('Variable dtype: %s' % policy.variable_dtype) # Variable drype: float32 (重み変数のデータ型)
# 以降、基本的なモデル構築~学習~推論の処理を記述
# モデル作成
inputs = keras.Input(shape=(28*28,), name='digits')
h1 = layers.Dense(2048, activation='relu')(inputs)
h2 = layers.Dense(10, activation='sigmoid')(h1)
outputs = layers.Activation('softmax')(h2)
model = tf.keras.Model(inputs, outputs)
# 中間層のデータ型確認
print(h1.dtype.name) # float16 (tensorの型がfloat16になっている)
# Loss/Optimizer設定
model.compile(loss='sparse_categorical_crossentropy',
optimizer=keras.optimizers.RMSprop(),
metrics=['accuracy'])
# 学習
model.fit(x_train, y_train, batch_size=1024, epochs=5, validation_split=0.2)
# 推論
y_pred = model.predict(x_test)
6. 実験
6-1. 動作環境
Amazon SageMakerノートブックインスタンスでg4dn.xlargeを使用しました。
| 環境項目 | 設定値 |
|---|---|
| インスタンス | g4dn.xlarge |
| CPU | Intel Xeon Platinum 8259CL (2.5GHz, 4Cores) |
| GPU | Tesla T4 |
| NVIDIA Drive | 450.142.00 |
| CUDA | 11.0 |
| Python | 3.7 |
| TensorFlow | 2.3.4 |
| keras | 2.4.0 |
6-2. データセット
MNISTのtrainデータ(1000枚分)を使用します。
CNNのモデルの入力が3chのため、1chを3chに拡張しています。
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train[:1000]
y_train = y_train[:1000]
x_train = x_train[:,:,:,np.newaxis]
x_train = np.concatenate([x_train]*3, axis=3) # shape=[1000, 28, 28, 3]
6-3. モデル
代表的なCNNモデル4種類(VGG16、MobileNet、ResNet、EfficientNet)について計測しました。
モデルの構成を図に示します。
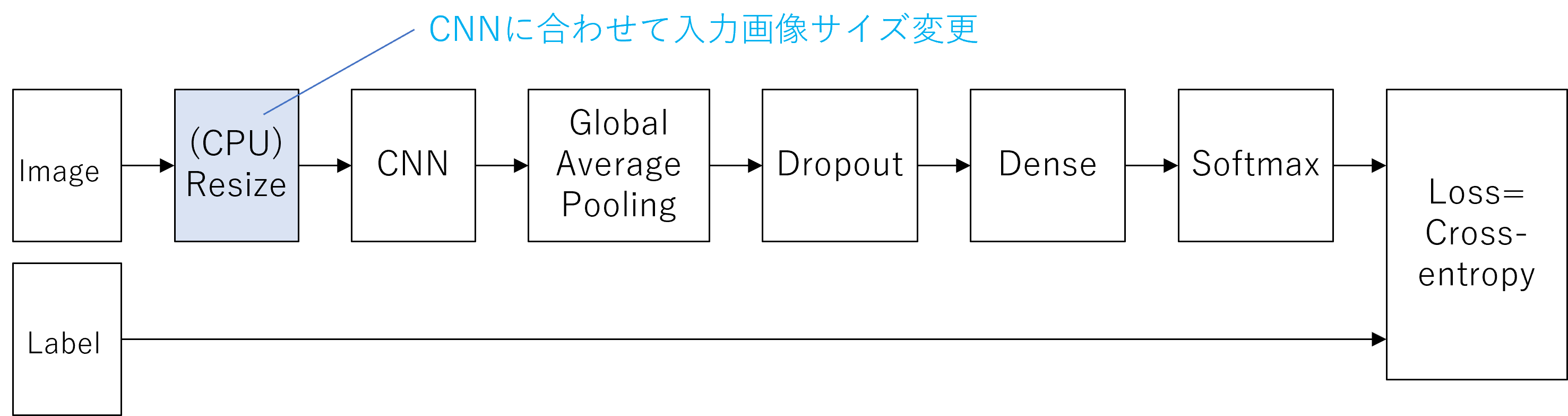
- 画像分類タスクの基本的なモデルです。
- CNN部分のモデルを入れ替えて計測します。
- Resize処理はCNNモデルの学習画像サイズに合わせます。
モデル構築のソースコード
def get_model(cnn_func, n_classes=10, img_size=224, verbose=False):
inp = tf.keras.layers.Input((img_size, img_size, 3))
cnn = cnn_func(
include_top=False,
weights="imagenet",
input_shape=(img_size, img_size, 3) )
x = cnn(inp)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dropout(0.15)(x)
output = tf.keras.layers.Dense(n_classes)(x)
model = tf.keras.Model( inputs=[inp], outputs=[output] )
model.compile(optimizer=tf.keras.optimizers.Adam(lr=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
if verbose:
model.summary()
return model
関数引数のmodel_funcは各CNNのモデルクラスです。
from tensorflow.keras.applications import VGG16, MobileNet, ResNet50, EfficientNetB0
6-4. 前処理
MNISTの画像をリサイズする前処理でデータセットを定義します。
コード中の変数imagesとlabelsは6-2節のデータセットの画像x_trainとy_trainに対応します(numpy.ndarray型)。
# dataset取得関数
def load_dataset( images, labels=None, img_size=224, batch_size=32, stage="train"):
# Resize処理関数(内包関数)
def transform(image, label, img_size=img_size):
image = tf.image.resize(image, size=(img_size, img_size))
return image, label
auto = tf.data.experimental.AUTOTUNE
if stage == "train":
shuffle, repeat, augment = True, True, True
elif stage == "valid":
shuffle, repeat, augment = False, False, False
else: # test
shuffle, repeat, augment = False, False, False
labels = np.zeros((images.shape[0],))
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
if shuffle:
dataset = dataset.shuffle(256)
opt = tf.data.Options()
opt.experimental_deterministic = False
dataset = dataset.with_options(opt)
if repeat:
dataset = dataset.repeat()
if augment:
dataset = dataset.map(transform, num_parallel_calls=auto)
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(auto)
return dataset
6-5. 処理時間計測クラス
処理時間計測クラスを定義します。
import time
from contextlib import contextmanager
@contextmanager
def timer(name):
t0 = time.time()
yield
print(f'[{name}] done in {time.time() - t0:.0f} s')
本クラスはwith構文を使用することで対象関数の処理時間を計測します。
# 計測対象関数
def func():
print("test")
# 計測の記述例
with timer("func"):
func()
# 標準出力で処理時間が表示される.
# [func] done in 0.0 s
6-6. 時間計測処理 (Main処理)
学習時間の計測は次のコードで実行しました。
交差検証のFold数を5として、5回分の処理時間の平均値として取得しました。
from tensorflow.keras.mixed_precision import experimental as mixed_precision
from sklearn.model_selection import KFold
# Mixed Precision有効化
policy = mixed_precision.Policy('mixed_float16')
mixed_precision.set_policy(policy)
# 学習処理関数
def train( images, labels, cnn_func, img_size=224, n_folds=5, epochs=100, batch_size=512):
kf = KFold(n_splits=n_folds)
for fold, (train_index, valid_index) in enumerate(kf.split(labels)):
# 学習データのtrain/valid分割
x_train, y_train = images[train_index], labels[train_index]
x_valid, y_valid = images[valid_index], labels[valid_index]
# 前処理dataset
dataset_train = load_dataset(x_train, y_train, stage="train", img_size=img_size, batch_size=batch_size)
dataset_valid = load_dataset(x_valid, y_valid, stage="valid", img_size=img_size, batch_size=batch_size*2)
# 1epochあたりのstep数を算出
steps_per_epoch = x_train.shape[0] // batch_size
if x_train.shape[0] % batch_size:
steps_per_epoch += 1
# モデル作成
verbose = True if fold == 0 else False # 初めのfoldのみmodel.summary()実行
model = get_model( cnn_func, img_size=img_size, verbose=verbose )
# モデル保存callback
weight_file = f"weight_fold{fold}.h5"
model_ckpt = tf.keras.callbacks.ModelCheckpoint(
weight_file, monitor="val_accuracy", verbose=0, save_best_only=True,
save_weights_only=True, mode="max", save_freq="epoch"
)
# 学習処理
with timer(f"training @ fold{fold}"): # 時間計測
history = model.fit(
dataset_train,
epochs=epochs,
callbacks=[model_ckpt],
steps_per_epoch=steps_per_epoch,
validation_data=dataset_valid,
verbose=0
)
# gpuのリソース開放
del model
gc.collect()
tf.keras.backend.clear_session()
if __name__== "__main__":
# 計測条件
cnns = [VGG16, MobileNet, ResNet50, EfficientNetB0]
image_sizes = [224, 160, 224, 224]
batch_sizes = [8, 16, 16, 16]
# 計測実行
for (cnn, image_size, batch_size) in zip(cnns, image_size, batch_sizes):
train( x_train, y_train, cnn, img_size=image_size, batch_size=batch_size)
6-7. 結果
計測結果をグラフにまとめました。

同様の計測をEfficientNetのB0~B5に対して行いました。
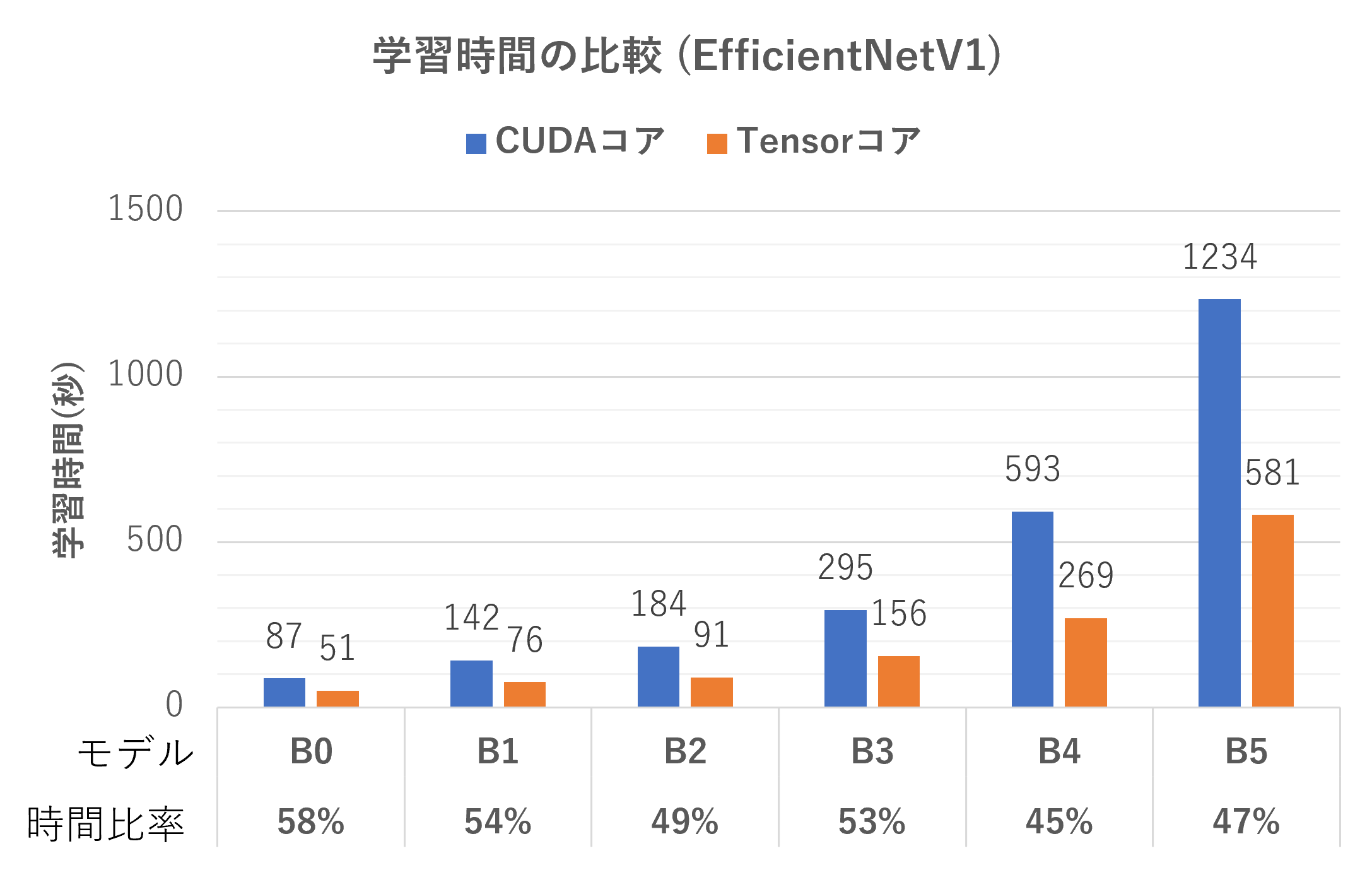
Tensorコアによって学習時間が45%~60%程度に高速化することを確認しました。
7. まとめ
GPUの学習をCUDAコアからTensorコアに切り替えるだけで学習時間が45%~60%程度に高速化することを確認しました。残念ながらカタログ通りに処理時間が1/16倍に短縮されることはありませんでしたが、数行のソースコード変更だけで高速化の恩恵を受けられるため有効な技術であることが分かりました。
8. おわりに
今回は、深層学習モデルの学習を高速化するノウハウとしてTensorコアをご紹介しました。私が所属する「デジタルイノベーションセンタ」は、AIとクラウド技術を専門とする組織です。今後も有益な技術情報を展開していきます。
最後まで読んでいただきありがとうございました。
9. 商標
「SageMaker」はアマゾン テクノロジーズ インコーポレイテッドの登録商標です。
「Xeon」はインテル コーポレーションの登録商標です。
「Tesla」はエヌビディア コーポレーションの登録商標です。
「CUDA」はエヌビディア コーポレーションの登録商標です。