Twitterでは、「設定」>「アカウント」>「Twiterデータ」>「アーカイブをダウンロード」
に、自分の過去のツイートを全てダウンロードする機能が用意してあることはご承知の通りです。
ダウンロードしたファイルには過去のツイート、RTしたツイート、いいねしたツイートの情報、ダイレクトメッセージなどが含まれています。(通常は一緒にダウンロードされるindex.htmlを開くことで閲覧できるようですが、自分の場合にはindex.htmlがダウンロードされませんでした。なんでだろう)
2019/12/15 追記
index.html はそもそもダウンロードされない仕様に変更になっている模様です。
BERTを理解しながら自分のツイートを可視化してみるハンズオン
↑こちらの記事を読んでて気付きました。
↓(参考)
【解決済】twitterの全ツイート履歴がダウンロードできない【方法】
テキストマイニングや何らかの分析を行いたい場合には tweet.json を読むことになると思います。本稿ではこちらのjsonファイルを、形態素解析などに使いやすいようなcsvに加工します。作成するcsvは「タイムスタンプ」と「テキスト本文」の2カラムです。
最終的にできるCSVのイメージ

環境
Python 3.6.5
Mac OS Mojave 10.14.4
pandas==0.23.0
ダウンロードしたjsonを開くとこんな感じになっているとおもいます。
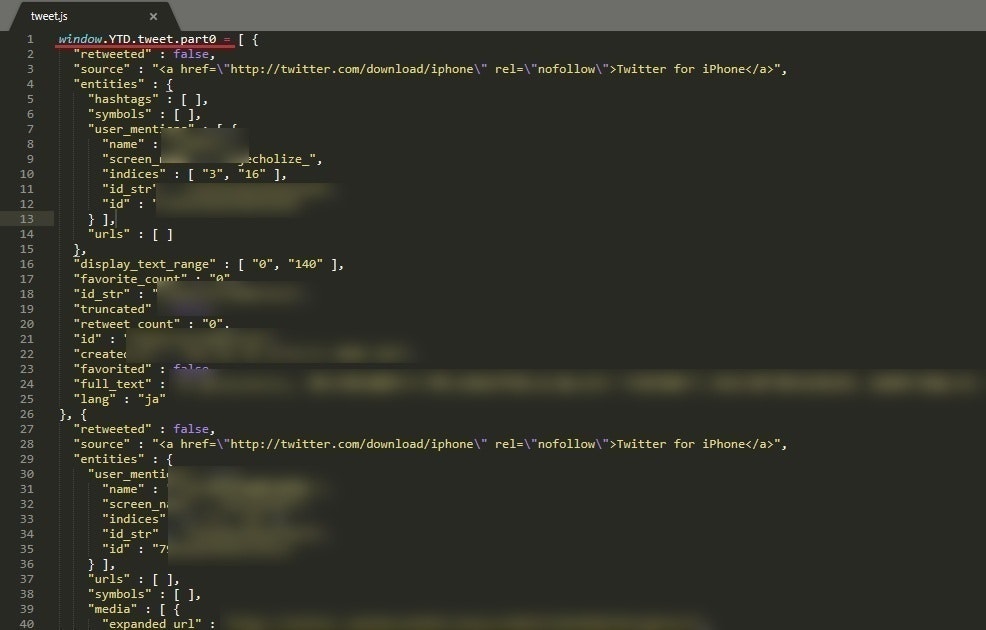
赤いアンダーラインを引いた
window.YTD.tweet.part0 =
は不要ですので消してください。そのうえで拡張子を .txt に変更し、作業するディレクトリに入れてください。
import pandas as pd
import json
tweets_file = open("tweet.txt", "r")
tweet = json.load(tweets_file)
上のスクリプトでpandasのdataframeとしてjsonを開きます。
カラムはたくさんあるのですが、必要なカラムだけを抜き出します。
df = tweet_data_frame.loc[:,["created_at","full_text"]]
csvにしていく際に改行やカンマなどの困った文字が入っているので、これらを除去します。
regex=Trueとしないとうまくいきませんでした。
df = df.replace(['\n',',',' ','\r'],'',regex=True)
また、タイムスタンプの形式が、ソートに使えない形になっているので、これを読みやすい形に直します。pandasのto_datetimeメソッドで一発で変換できました。
df_date = pd.to_datetime(df["created_at"])
df["date_form"] = df_date
df_sorted = df.sort_values("date_form")
df_text_date = df_sorted.loc[:,["date_form","full_text"]]
新しく作ったタイムスタンプでソートしています。
df_text_date.to_csv("df_text_date.csv", header=False, index=False,sep=',',encoding='utf-16')
csvを出力する際のオプションは適宜変更してください(区切りをタブにするなど)。
次記事では作成したcsvから期間ごとのツイート数をグラフに出してみます。