以前書いた記事と被るところがあり、新しく出てきたところは詳しく解説します。
https://qiita.com/MeiByeleth/items/5b210831cd866a7b42cf
画像認識
Inputは画像、Outputは画像が何であるかのデータ[例 cat:0.99,dog:0.01]のものを書きます。
VGG
畳み込み層13層、FC層3層からなる手法。
それなりの性能が出ており、学習済みモデルは今でも使われています。
GoogLeNet
VGG16とは逆で非常に複雑な手法。
・Inception モジュールを使う
・1*1の畳み込みを積極的に使う
の2つが特徴。
MobileNet
高速化を意識した画像認識の手法。
Xceptionなどに用いられた畳み込みの手法を用いて計算量を大幅に削減しました。
Xceptionと異なるのはResNetのようなショートカットを用いない点、depthwise畳み込みとpointwise畳み込みの間にbatch normalizationとReLUを利用している点です。
ResNet
CNNといったらResNetぐらい支配的な手法。
DLは多層にすればするほど性能が上がるといわれていますが、50層以上を超えると性能が下がります。
性能が下がる問題を解決したのがこの手法です。
DenseNet
とにかく精度を上げたいときに用います。
前方にあるすべてのブロックに出力を結合する手法です。
画像の局在化・検知・セグメンテーション
画像のどこに何があるか推定する手法です。

引用:https://pjreddie.com/darknet/yolo/
上のような出力イメージ。
R-CNN(Region with CNN features)
物体らしさを判定し、物体っぽいところだけとり、それを画像認識する手法。
画像検知の基本構造のもととなった手法です。
物体っぽいところを探す手法はSelective Searchといいます。
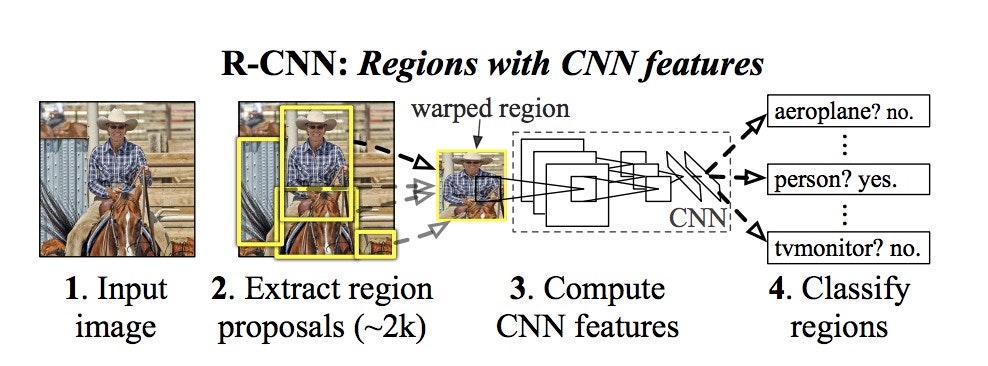
引用:https://blog.negativemind.com/2019/02/06/general-object-recognition-regions-with-cnn-features/
3.で正方形に整えてCNNに入れられるようにしています。
ただGPUを使っても30秒ぐらいかかるほど遅いです。
SPPnet
画像全体でCNNをしてから画像の切り取りをする手法。

引用:http://owatank.hatenablog.com/entry/2017/08/29/182549
Fast-RCNN
画像認識とbounding box(画像の四角い枠)を一括でやる手法。
multi-task lossを導入しました。
R-CNNの200倍、SPPnetの10倍速いです。
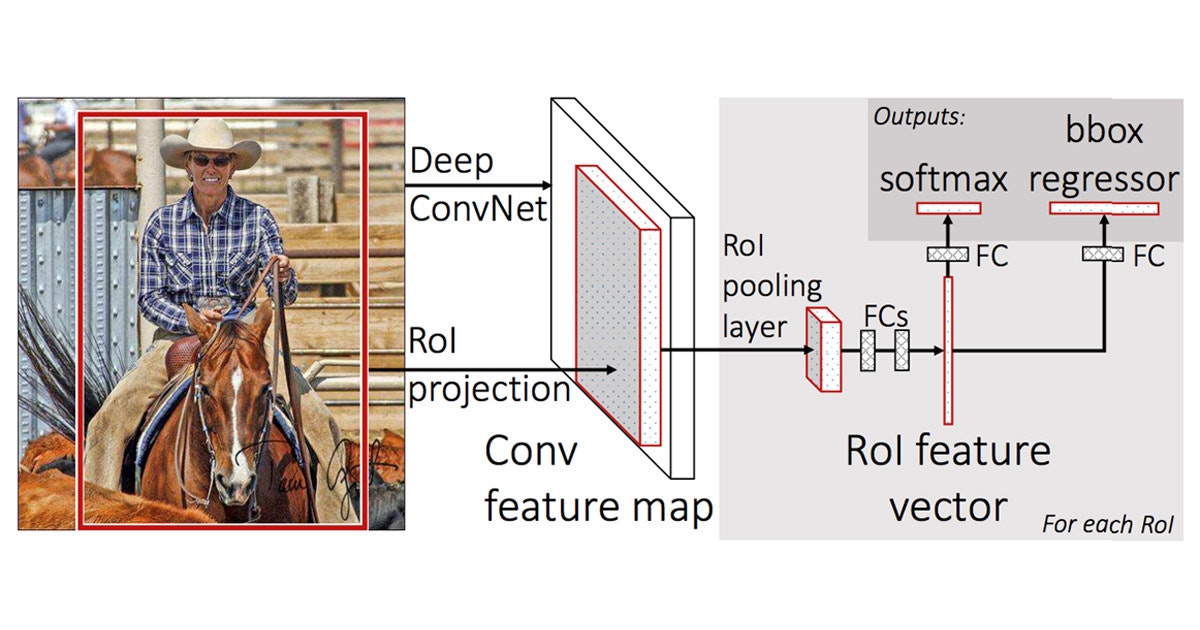
引用:https://news.mynavi.jp/article/cv_future-54/
最後のSoftmaxは物体が何か(画像認識)、bbox regressorは物体がどこにあるか(bounding box)を演算しています。
Multi-task loss
最後の層で分類(画像認識)と回帰(bounding boxの位置)を同時に行っています、この手法を Multi-task lossといいます。
Smooth L1 Loss
学習時、座標のずれの評価手法。
L2を用いると外れるとペナルティが大きく、L1だと0付近に大きなペナルティが課されます。
そこで2つののいいとこどりをした手法がSmooth L1 Lossです。

引用:http://cosine.xyz/2019/09/04/loss-function-l1-l2/
式は
$$
L_1(x) = |x| \\
L_2(x) = x^2 \\
Smooth_{L1}(x) =
\begin{cases}
0.5x^2 & \text{if $|x|$<1} \\
|x|-0.5 & \text{otherwise}
\end{cases}
$$
です。原点付近はL2っぽく、それ以外はL1っぽくなる損失関数です。
Faster-RCNN
Selective Searchを使わず、物体の領域候補の抽出もNNに組み込んだ手法です。
これのおかげでBPが計算できるようになりました(End to Endと呼ぶ)
Fast R-CNNの同僚が考えた手法でGPUで5fpsほど早くなった。
YOLO
抽出と認識を一度に行った手法。One-Shotともいいます。
Faster-RCNNより精度は落ちますが、リアルタイムで検知できます。(60FPS~120FPS)
手法は下図の通り。
1.S*Sにグリッドに分割
2.一方では領域推定(この辺にbounding box囲えそう)
2.一方ではグリッドごとにクラス推定(この辺に何かがいる)
3.2つの結果を合体させ出力。
4.non-maximum suppressionをかけ候補を絞り込む。
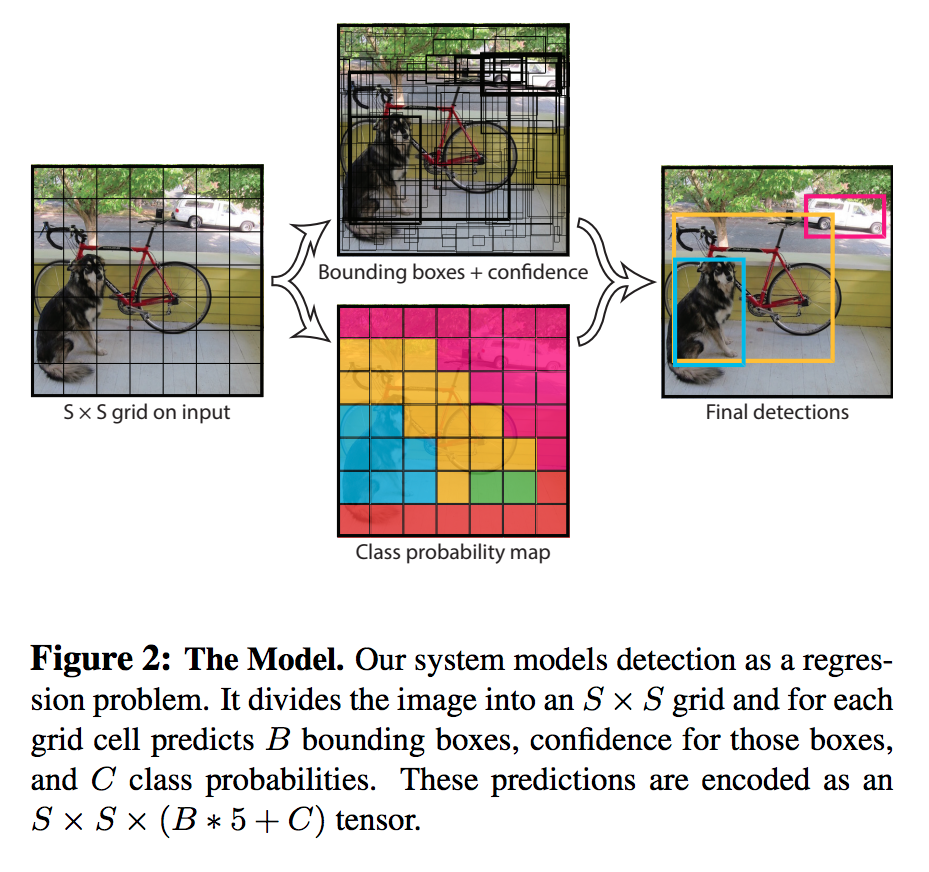
引用:https://yoheitaonishi.com/yolo/
non-maximum suppressionについて解説します。
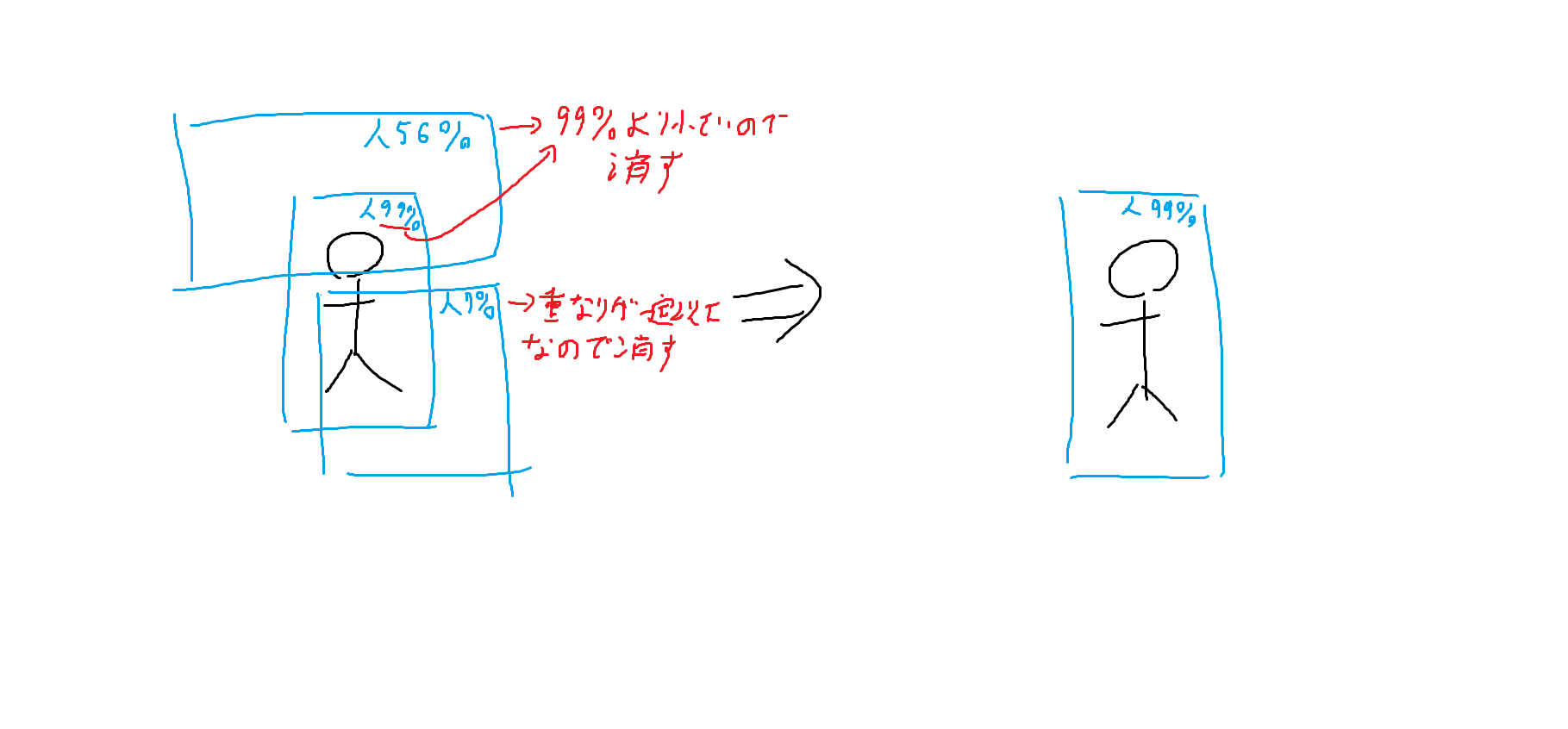
non-maximum suppression
YOLOをする際、グリッドで区切るのでいくつかboundingboxが出てしまいます。
そこでIoUが一定以上の領域同士はスコアの最も高いものだけ残し、他を消します。
IOU(Interception over Union)
領域の一致具合を評価する手法。
正解の領域と完全に重なっていたら1、完全に重なっていなかったら0です。
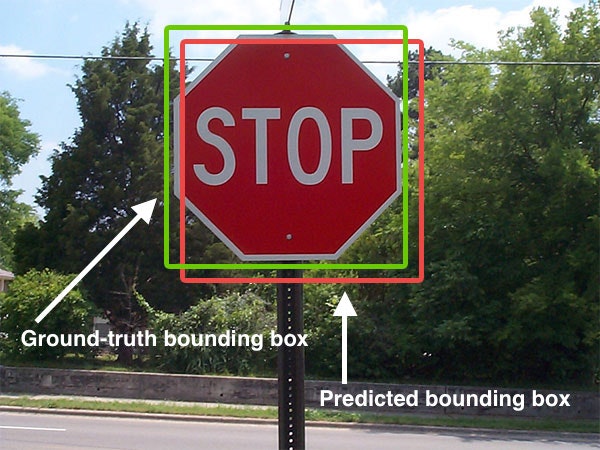
引用:http://kenbo.hatenablog.com/entry/2018/04/27/124749
例えばこのような標識をbounding boxで囲わせたとします。
この時のIOUの式は以下の通り。
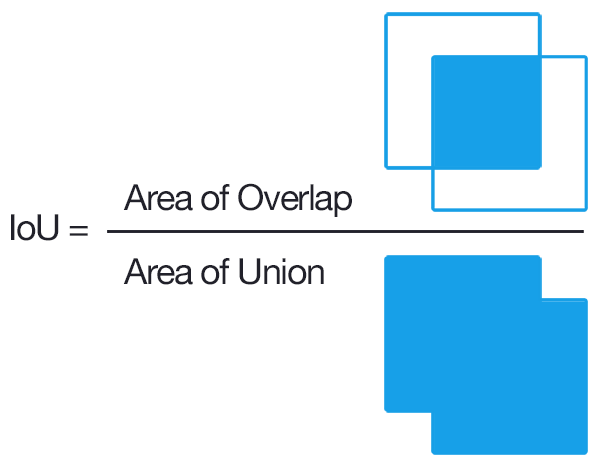
引用:http://kenbo.hatenablog.com/entry/2018/04/27/124749
分母の領域の500pxで分子の領域が450pxだとすればIOUは0.9です。
SSD(Single Shot Detector)
YOLOとほぼ同じですが、bounding boxを仮置き(デフォルトボックス)する手法。
以下の手順です。
1.1セルごとに様々なデフォルトボックスを使う
2.デフォルトボックスを微調整して最終的なbounding boxを決める。
3.段階的に分割数をスケールダウンしてbounding boxをマッチさせる

引用:https://blog.csdn.net/qq_38622495/article/details/82289814
他にも
・前半VGG16を使っている
・Hard Negative mining(負例:正例=3:1になるように調整)
のが特徴。
UNet
セグメンテーションに特化したネットワークを指します。
特徴はInputとOutputの画像の形状が似ている点です。

引用:https://lp-tech.net/articles/5MIeh
画像のように構造がUの字になっているのでこの名前がついています。
参考文献
https://qiita.com/omiita/items/77dadd5a7b16a104df83
https://qiita.com/yu4u/items/7e93c454c9410c4b5427#mobilenet